Java JUC并发编程笔记
1. volatile
volatile是一个Java的修饰符,用volatile修饰的变量有三个特性:保证可见性、不保证原子性、禁止指令重排。
JMM,Java Memory model。Java内存模型,Java内存模型规定所有的变量都是存在主存当中,每个线程都有自己的工作内存。线程对变量的所有操作都必须在工作内存中进行,而不能直接对主存进行操作。并且每个线程不能访问其他线程的工作内存。所以线程对变量的操作时,首先将变量从主内存拷贝到自己的工作内存空间,然后对其操作,操作完成后再将变量写回主内存。
1.1 保证可见性
即一个线程修改了某个变量的值,这新值对其他线程来说是立即可见的。
而普通的共享变量不能保证可见性,因为普通共享变量被修改之后,什么时候被写入主存是不确定的,当其他线程去读取时,此时内存中可能还是原来的旧值,因此无法保证可见性。
可见性代码说明,在下面的代码中,如果number不加volatile关键字时,执行程序后ti线程将number的值改为60,但是在main线程中number的值还是0,会一直陷在循环中出不来,而加上volatile关键字后,main线程就会得到number值已经被修改的通知,结束循环。
package concurrent;
import java.util.concurrent.atomic.AtomicInteger;
class Data{
volatile int number=0;
public void change(){
number = 60;
}
}
public class VolatileTest {
public static void main(String[] args) throws InterruptedException {
Data data = new Data();
new Thread(()->{
System.out.println(Thread.currentThread().getName() + "线程启动了");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
data.change();
System.out.println(Thread.currentThread().getName() + "线程结束了");
},"t1").start();
while(data.number == 0);
System.out.println("data.number = " + data.number);
}
}
1.2 不保证原子性
原子性是指不可分割,完整性。一段操作要么被全部执行成功,要么都不执行,中间不可以被加塞或打断。
= 右边有变量的操作都不是原子操作。
i=9 是一个原子操作, i++不是一个原子操作。因为i++有三个步骤:
1)读取i的值,
2)i = i +1
3)将i的值写回主内存
在执行i++操作时,中间可能被加塞。如果有两个线程同时执行i++操作,假设原来i的值为0,两个线程都将i=0读取到各自的工作内存,然后将i的值修改为1,最后两个线程都将1写回到主内存的i中,这时虽然执行了两次i++操作,但i的值还是1.
代码说明,新建20个线程分别执行1000次number++操作,最后number的值小于20000
package concurrent;
import java.util.concurrent.atomic.AtomicInteger;
class Data{
volatile int number=0;
public void add(){
number++;
}
}
public class VolatileTest {
public static void main(String[] args) throws InterruptedException {
Data data = new Data();
for (int i = 0; i < 20; i++) {
new Thread(()->{
for (int j = 0; j < 1000; j++) {
data.add();
}
},String.valueOf(i)).start();
}
while(Thread.activeCount()>2){
Thread.yield();
}
System.out.println("data.number = " + data.an.get());
}
}
1.3 禁止指令重排
指令重排:计算机在执行程序时,为了提高性能,处理器和编译器会对指令重新排序,重排序的前提是数据之间没有依赖性,保证单线程环境中程序的最终执行结果一致。
但是在多线程环境中,由于指令重排,变量的执行顺序是否保持一致无法预测。如下面这段代码,如果分别用两个线程执行两个方法,可能得到不一样的结果。
int a =0;
boolean flag = false;
public void method1(){
a = 1;
flag = true;
}
public void method2(){
if(flag){
a = a + 5;
}
}
volatile关键字禁止指令重排序有两层意思:
1)当程序执行到volatile变量的读操作或者写操作时,在其前面的操作的更改肯定全部已经进行,且结果已经对后面的操作可见;在其后面的操作肯定还没有进行;
2)在进行指令优化时,不能将在对volatile变量访问的语句放在其后面执行,也不能把volatile变量后面的语句放到其前面执行。
1.4 volatile的原理和实现机制
下面这段话摘自《深入理解Java虚拟机》:
“观察加入volatile关键字和没有加入volatile关键字时所生成的汇编代码发现,加入volatile关键字时,会多出一个lock前缀指令”
lock前缀指令实际上相当于一个内存屏障(也成内存栅栏),内存屏障会提供3个功能:
1)它确保指令重排序时不会把其后面的指令排到内存屏障之前的位置,也不会把前面的指令排到内存屏障的后面;即在执行到内存屏障这句指令时,在它前面的操作已经全部完成;
2)它会强制将对缓存的修改操作立即写入主存;
3)如果是写操作,它会导致其他CPU中对应的缓存行无效。
1.5 用volatile修饰的单例模式
1)DCL(Double Check Lock)双端检索机制:
用了两次判断instance == null。
因为在第一次创建实例的时候如果两个线程都进入了第一次判断,线程一先拿到锁创建一个实例,然后释放锁,此时线程二拿到锁,如果不进行判断,就会再一次创建一个实例。
2)volatile关键字修饰instance
但是由于指令重排的原因,双端检索机制不一定线程安全。
原因在于某一个线程执行到第一次检测,读取到的 instance不为null时,instance的引用对象可能没有完成初始化。
instance = new Singleton();可以分为以下3步完成(伪代码)
memory = allocate(); //1.分配对象内存空间
instance(memory); //2.初始化对象
instance = memory; /3设置 instance指向刚分配的内存地址,此时 instance!=null
步骤2和步骤3不存在数据依赖关系,而且无论重排前还是重排后程序的执行结果在单线程中并没有改变,因此这种重排优化是允许的。
但如果第三条指令发生在第二条指令之前
memory = allocate(); //1.分配对象内存空间
instance = memory; /3设置 instance指向刚分配的内存地址,此时 instance!=null,但是对象初始化还没有完成
instance(memory); //2.初始化对象
但是指令重排只会保证串行语义的执行的一致性(单线程),但并不会关心多线程间的语义一致性所以当一条线程访问 Instance不为null时,由于 instance实例未必已初始化完成,也就造成了线程安全问题。
因此需要加volatile关键字禁止指令重排
package concurrent;
public class Singleton {
private static volatile Singleton instance = null;
private Singleton(){
}
public static Singleton getInstance(){
if (instance == null){
synchronized (Singleton.class){
if (instance == null){
instance = new Singleton();
}
}
}
return instance;
}
}
2 CAS 比较并交换
CAS的全称为Compare And Swap,它是一条CPU并发原语。
它的功能是判断内存某个位置的值是否为预期值,如果是则更改为新的值,这个过程是原子的。
CAS并发原语体现在JAVA语言中就是sun.misc.Unsafe类中的各个方法。调用 Unsafe类中的CAS方法,JVM会帮我们实现出CAS汇编指这是一种完全依赖于硬件的功能,通过它实现了原子操作。再次强调,由于CAS是一种系统原语,原语属于操作系统用语范畴,是由若干条指令组成的,用于完成某个功能的一个过程,并且原语的执行必须是连续的,在执行过程中不允许被中断,也就是说CAS是一条CPU的原子指令,不会造成所谓的数据不一致问题。
Unsafe是CAS的核心类,由于Java方法无法直接访问底层系统,需要通过本地(native)方法来访问, Unsafe相当于一个后门,基于该类可以直接操作特定内存的数据。Unsafe类存在于sun.misc包中,其内部方法操作可以像C的指针一样直接操作内存,因为Java中CAS操作的执行依赖于Unsafe类的方法。
注意Unsafe类中的所有方法都是native修饰的,也就是说Unsafe类中的方法都直接调用操作系统底层资源执行相应任务。
2.1 原理和实现机制
由于volatile只能保证可见性,无法保证原子性,在并发的情况下执行自增操作的时候,我们无法获得想要的结果。那么,应该怎么解决这个问题了?
- 用synchronized修饰,但这样性能会下降。
- 使用Java并发包原子操作类(Atomic开头)。
将number改为AtomicInteger原子整型类后,可以解决上面volatile不发保证原子性的操作。
分析AtomicInteger的自增方法getAndIncrement()后发现:


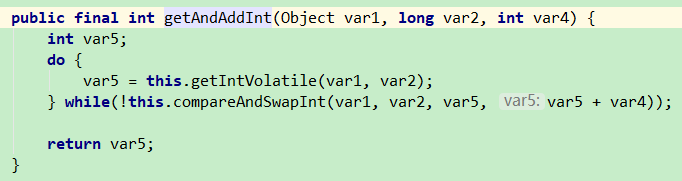
当执行getAndAddInt()操作时,会拿到内存位置的最新值var5,使用CAS尝试修将内存位置的值修改为目标值var5+var4,如果修改失败,则重新获取该内存位置的新值var5,然后继续尝试,直至修改成功。
2.2 CAS存在的问题
- 循环时间长开销大
- 只能保证一个共享变量的原子操作
- ABA问题
ABA问题是指一个线程将变量值从A修改为B,然后再将B修改A,另一个线程执行CAS的之后发现变量值还是A,他不知道这中间变量的值被改变过。
Java并发包为了解决这个问题,提供了一个带有标记的原子引用类“AtomicStampedReference”,它可以通过控制变量值的版本来保证CAS的正确性。因此,在使用CAS前要考虑清楚“ABA”问题是否会影响程序并发的正确性,如果需要解决ABA问题,改用传统的互斥同步可能会比原子类更高效。
3 线程安全的集合类
3.1 CopyOnWrite
写时复制, 在往集合中添加数据的时候,先拷贝存储的数组,然后添加元素到拷贝好的数组中,然后用现在的数组去替换原来的数组。
实现类:CopyOnWriteArrayList、CopyOnWriteArraySet 。其中CopyOnWriteArraySet底层使用CopyOnWriteArrayList实现的。
3.2 ConcurrentHashMap
多线程环境下,使用HashMap的put()方法可能会引起死循环,因此可以使用ConcurrentHashMap
jdk1.8之前采用Segment分段锁方法解决,jdk1.8开始采用CAS + synchronized解决。
参考链接:
https://www.jianshu.com/p/d0b37b927c48
https://blog.csdn.net/tp7309/article/details/76532366
4 锁
4.1 公平锁和非公平锁
公平锁:多个线程按照申请锁的顺序获得锁,先到先得。
非公平锁:多个线程并不一定按照申请锁的顺序获得锁。
synchronized是一种非公平锁,ReentrantLock可以在构造时选择公平锁或者非公平锁,默认是非公平锁。
4.2 可重入锁/递归锁
指的是同一线程外层函数获得锁之后,内层递归函数仍然能获取该锁的代码,在同一个线程在外层方法获取锁的时候,在进入内层方法会自动获取锁。
也即是说,线程可以进入任何一个它己经拥有的锁所同步着的代码块。
4.3 自旋锁
是指尝试获取锁的线程不会立即阻塞,而是采用循环的方式去尝试获取锁,这样的好处是减少线程上下文切换的消耗,缺点是循环会消耗CPU。
自旋锁例子,线程执行顺序
1,线程t1 调用lock方法,将spinLock对象本身赋值给变量ar,并开始2秒的sleep()
2,线程t2 开始1秒后尝试调用lock方法失败,并不断尝试
3,线程t1 sleep()两秒后调用unlock方法,将变量ar赋值为null
4,线程t2 调用lock()方法成功,将spinLock对象本身赋值给变量ar
5,线程t1 调用unlock方法
执行结果显示在1秒内线程二尝试了84660252次。
package concurrent;
import java.util.concurrent.atomic.AtomicReference;
public class SpinLock {
AtomicReference<SpinLock> ar = new AtomicReference<>();
int count = 0;
public void lock(){
System.out.println(Thread.currentThread().getName() + " come in");
while(! ar.compareAndSet(null,this)){
// System.out.println(Thread.currentThread().getName() + "正在尝试获得锁");
count++;
}
System.out.println(Thread.currentThread().getName() + " lock");
System.out.println("count = " + count);
}
public void unLock(){
ar.compareAndSet(this,null);
System.out.println(Thread.currentThread().getName() + " unlock");
}
public static void main(String[] args) {
SpinLock spinLock = new SpinLock();
new Thread(()->{
spinLock.lock();
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
spinLock.unLock();
},"t1").start();
new Thread(()->{
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
spinLock.lock();
spinLock.unLock();
},"t2").start();
}
}
执行结果:
t1 come in
t1 lock
count = 0
t2 come in
t1 unlock
t2 lock
count = 84660252
t2 unlock
4.4 独占锁(写锁)/ 共享锁(读锁)/ 互斥锁
独占锁:指该锁一次只能被一个线程所持有。对 Reentrantlock和 Synchronized而言都是独占锁
共享锁:指该锁可被多个线程所持有。对 ReentrantReadWriteLock其读锁是共享锁,其写锁是独占锁
读锁的共享锁可保证并发读是非常高效的,读写、写读、写写的过程是互斥的。
实现:ReenTrantReadWriteLock的读锁和写锁
5 并发线程通信
5.1 CountDownLatch
CountDownLatch倒计时计数器,当计数器数值减为0时,所有受其影响而等待的线程将会被激活,这样保证模拟并发请求的真实性。可以用来线程通信。
类中有三个主要方法:
//调用await()方法的线程会被挂起,它会等待直到count值为0才继续执行
public void await() throws InterruptedException { };
//和await()类似,只不过等待一定的时间后count值还没变为0的话就会继续执行
public boolean await(long timeout, TimeUnit unit) throws InterruptedException { };
//将count值减1
public void countDown() { };
CountDownLatch的用法
1、多个子线程执行完毕后主线程再执行。每当一个任务线程执行完毕时,就调用 countdownLatch.countDown()方法,将计数器减1。当计数器的值变为0时,在CountDownLatch上await()的主线程就会被唤醒。一个典型应用场景就是启动一个服务时,主线程需要等待多个组件加载完毕,之后再继续执行。
2、实现多个线程开始执行任务的最大并行性。注意是并行性,不是并发,强调的是多个线程在某一时刻同时开始执行。类似于赛跑,将多个线程放到起点,等待发令枪响,然后同时开跑。做法是初始化一个共享的CountDownLatch(1),将其计算器初始化为1,多个线程在开始执行任务前首先countdownlatch.await(),当主线程调用countDown()时,计数器变为0,多个线程同时被唤醒。
缺点
不能复用,构造之后无法设置count的值。
5.2 CyclicBarrier
循环栅栏(屏障),当一组线程到达栅栏时会被阻塞,直到所有线程都到达时栅栏才会打开,线程继续执行。可以用于多线程共同计算数据,合并计算结果。
下面代码来自:https://www.jianshu.com/p/333fd8faa56e
public class CyclicBarrierDemo {
static class TaskThread extends Thread {
CyclicBarrier barrier;
public TaskThread(CyclicBarrier barrier) {
this.barrier = barrier;
}
@Override
public void run() {
try {
Thread.sleep(1000);
System.out.println(getName() + " 到达栅栏 A");
barrier.await();
System.out.println(getName() + " 冲破栅栏 A");
Thread.sleep(2000);
System.out.println(getName() + " 到达栅栏 B");
barrier.await();
System.out.println(getName() + " 冲破栅栏 B");
} catch (Exception e) {
e.printStackTrace();
}
}
}
public static void main(String[] args) {
int threadNum = 5;
CyclicBarrier barrier = new CyclicBarrier(threadNum, new Runnable() {
@Override
public void run() {
System.out.println(Thread.currentThread().getName() + " 完成最后任务");
}
});
for(int i = 0; i < threadNum; i++) {
new TaskThread(barrier).start();
}
}
}
执行结果:
Thread-1 到达栅栏 A
Thread-3 到达栅栏 A
Thread-0 到达栅栏 A
Thread-4 到达栅栏 A
Thread-2 到达栅栏 A
Thread-2 完成最后任务
Thread-2 冲破栅栏 A
Thread-1 冲破栅栏 A
Thread-3 冲破栅栏 A
Thread-4 冲破栅栏 A
Thread-0 冲破栅栏 A
Thread-4 到达栅栏 B
Thread-0 到达栅栏 B
Thread-3 到达栅栏 B
Thread-2 到达栅栏 B
Thread-1 到达栅栏 B
Thread-1 完成最后任务
Thread-1 冲破栅栏 B
Thread-0 冲破栅栏 B
Thread-4 冲破栅栏 B
Thread-2 冲破栅栏 B
Thread-3 冲破栅栏 B
5.3 Semaphore
多个线程争抢多个资源,可用于秒杀活动。
核心方法:
//创建具有给定数量的信号量,设置为非公平
public Semaphore(int permits)
//形参fair,设置为公平或非公平
public Semaphore(int permits, boolean fair)
//当前线程获取一个资源
public void acquire()
//当前线程获取多个资源
public void acquire(int permits)
//释放一个资源
public void release()
//释放多个资源
public void release(int permits)
6 阻塞队列
6.1 阻塞队列的种类
ArrayBlockingQueue:由数组结构组成的有界阻塞队列。
LinkedBlockingQueue:由链表结构组成的有界(但大小默认值为 Intege.MAX_VALUE)阻塞队列。
PriorityBlockingQueue:支持优先级排序的无界阻塞队列。DelayQueue:使用优先级队列实现的延迟无界阻塞队列。SynchronousQueue:不存储元素的阻塞队列,也即单个元素的队列。
LinkedTransferQueue:由链表结构组成的无界阻塞队列。LinkedBlockingDeque:由链表结构组成的双向阻塞队列。
6.2 阻塞队列常用方法
public boolean offer(E e): 将给定的元素设置到队列中,如果设置成功返回true, 否则返回false. e的值不能为空,否则抛出空指针异常。
public boolean offer(E e, long timeout, TimeUnit unit):将给定元素在给定的时间内设置到队列中,如果设置成功返回true, 否则返回false。
public E poll():从队列中获取值,如果没有取到会抛出异常。
public E poll(long timeout, TimeUnit unit):在给定的时间里,从队列中获取值,如果没有取到会抛出异常。
public E peek():获取队列首元素。
public boolean add(E e)::将给定元素设置到队列中,如果设置成功返回true, 否则抛出异常。如果是往限定了长度的队列中设置值,推荐使用offer()方法。
public void put(E e): 将元素设置到队列中,如果队列中没有多余的空间,该方法会一直阻塞,直到队列中有多余的空间。
public E take()::从队列中获取值,如果队列中没有值,线程会一直阻塞,直到队列中有值,并且该方法取得了该值。
7 线程池
阿里巴巴Java开发手册中强制要求:
线程池不允许使用 Executors去创建,而是通过 ThreadPoolExecutor 的方式,这样的处理方式让写的同学更加明确线程池的运行规则,规避资源耗尽的风险。
说明: Executors返回的线程池对象的弊端如下:
1)FixedThreadPool 和 SinglePool:
允许的请求队列长度为 Integer.MAX_VALUE,可能会堆积大量的请求,从而导致OOM。
2)CachedThreadPool:允许的创建线程数量为Integer.MAX_VALUE,可能会创建大量的线程,从而导致OOM。
ExecutorService threadPool = new ThreadPoolExecutor(6,
10,
1l,
TimeUnit.SECONDS,
new LinkedBlockingQueue<Runnable>(),
Executors.defaultThreadFactory(),
new ThreadPoolExecutor.AbortPolicy());
7.1 构造器
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler)
一共有七个参数:
1,corePoolSize:核心池的大小,常驻线程的数量
2,maximumPoolSize:线程池中最大线程数
3,keepAliveTime:线程池的非常驻线程闲置时长,超过这个时间将被销毁
4,TimeUnit unit:上一个参数的时间单位
5,BlockingQueue workQueue:线程池的阻塞队列
6,ThreadFactory threadFactory:线程工厂
7,RejectedExecutionHandler handler:拒绝策略,有四种。
7.2 四种拒绝策略
默认策略是ThreadPoolExecutor.AbortPolicy
1,ThreadPoolExecutor.AbortPolicy:丢弃任务并抛出RejectedExecutionException异常阻止系统正常运行
2,ThreadPoolExecutor.CallerRunsPolicy:该策略既不会抛出异常,也不会抛弃任务,而是将任务回退给调用线程
3,ThreadPoolExecutor.DiscardPolicy:直接丢弃任务,不予任何处理也不会抛出异常。如果允许任务丢失这是最好的策略
4,ThreadPoolExecutor.DiscardOldestPolicy:抛弃队列中等待最久的任务,然后把当前任务加入队列并再次尝试提交任务
参考文献
https://www.bilibili.com/video/BV1zb411M7NQ?p=18
https://www.cnblogs.com/dolphin0520/p/3920373.html
https://blog.csdn.net/v123411739/article/details/79561458
https://www.jianshu.com/p/e233bb37d2e6
https://www.cnblogs.com/Lee_xy_z/p/10470181.html
https://www.jianshu.com/p/50fffbf21b39