python爬虫——用Scrapy框架爬取阳光电影的所有电影
python爬虫——用Scrapy框架爬取阳光电影的所有电影
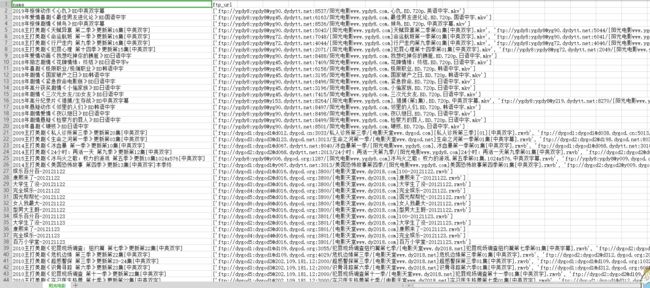
1.附上效果图

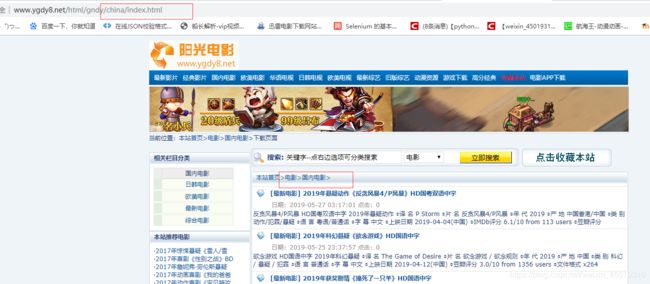
2.阳光电影网址http://www.ygdy8.net/index.html
3.先写好开始的网址
name = 'ygdy8'
allowed_domains = ['ygdy8.net']
start_urls = ['http://www.ygdy8.net/index.html']
4.再写采集规则
#采集规则的集合
rules = (
#具体实现的采集规则
#采集导航页中电影的部分 allow是选择出所有带有index的网址 allow是正则表达式 只要写你想提取的链接的一部分就可以了
#deny是去掉游戏那一栏
Rule(LinkExtractor(allow=r'index.html', deny='game')),
# follow=True 下一次提取网页中如果包含我们需要提取的信息是否还要继续提取
Rule(LinkExtractor(allow=r'list_\d+_\d+.html'),follow=True),
#allow里面提取详情页信息
#callback回调函数将相应交给谁处理
Rule(LinkExtractor(allow=r'/\d+/\d+.html'),callback='parse_item',follow=False),
)
第一个规则是从导航栏那里匹配,匹配除了游戏的其他导航栏
#采集导航页中电影的部分 allow是选择出所有带有index的网址 allow是正则表达式 只要写你想提取的链接的一部分就可以了
#deny是去掉游戏那一栏
Rule(LinkExtractor(allow=r'index.html', deny='game')),
![]()
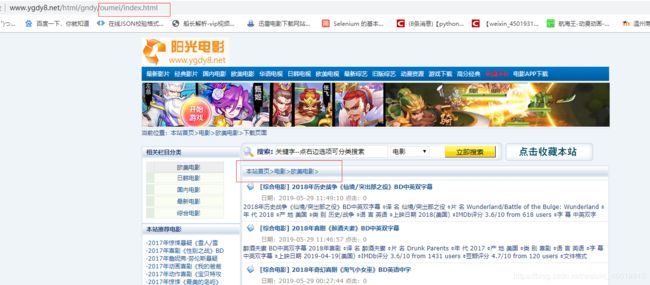
第二个规则是匹配导航栏下每一页的信息,都是由list下划线加2个数字组成,所以就用\d表示数字,follow是为了继续提取才写的,为了下一步获取详情页的信息
# follow=True 下一次提取网页中如果包含我们需要提取的信息是否还要继续提取
Rule(LinkExtractor(allow=r'list_\d+_\d+.html'),follow=True),

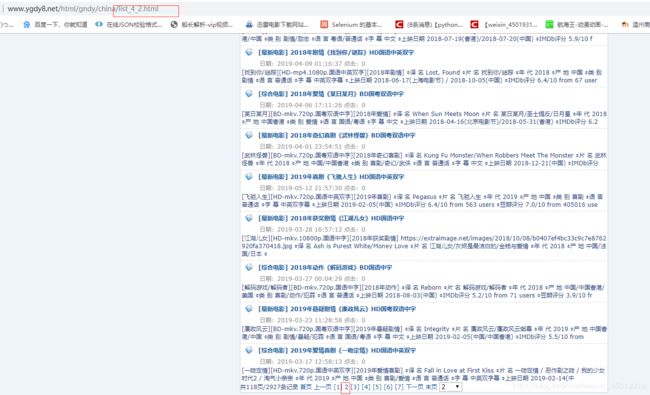
第3个规则是匹配详情页的信息,通过follow匹配每一页的电影详情,每个电影详情页都是由/和数字组成,所以用/\d来匹配,callback回调函数就将数据交给下面的parse_item处理
#allow里面提取详情页信息
#callback回调函数将相应交给谁处理
Rule(LinkExtractor(allow=r'/\d+/\d+.html'),callback='parse_item',follow=False)
5.数据处理的方法
#解析采集回来的数据,response就是得到的响应
def parse_item(self, response):
name = response.xpath('//div[@class="title_all"]/h1/font/text()').get()#获取电影名字
#用get和extract_first都可以
# name = response.xpath('//div[@class="title_all"]/h1/font/text()').extract_first()
ftp_url = re.findall('ftp',response.text)#response.text响应文本
#获取电影的ftp地址
if(name and ftp_url):#如果name和ftp_url都存在生成字典
items = {
'name': name,
'ftp_url': ftp_url
}
yield items#生成器

因为这里的ftp通过浏览器解析的和源码不一样,而且每个格式有点区别,所以我用正则表达式提取
![]()
这2个提取哪一个都可以,我是取前一个,.*?尽可能多的匹配,就是匹配href到下一个>ftp之前的所有字节
ftp_url = re.findall('ftp',response.text)
6.文本存储,这里要用到pipelines管道,我写了json和csv的存储方法,但是也有一点小错误,就是我的脚本运行完之后好像是没有用到close_spider的方法,所以json文件会少一个]右括号
class JsonPipeline(object):
def __init__(self):
self.file = open('阳光电影.json', 'w+',encoding='utf-8')
def open_spider(self, spider):
self.file.write('[')
def process_item(self, item, spider):
line = json.dumps(dict(item),ensure_ascii=False)+",\n"
self.file.write(line)
return item
def close_spider(self, spider):
self.file.seek(-1, os.SEEK_END)
self.file.truncate()
self.file.write(']')
self.file.close()
class CsvPipeline(object):
def __init__(self):
self.f = open("阳光电影.csv", "w",newline='')
self.writer = csv.writer(self.f)
self.writer.writerow(['name','ftp_url'])
def process_item(self, item, spider):
yangguang_list = [item['name'], item['ftp_url']]
self.writer.writerow(yangguang_list)
return item
在pipelines写完之后还要在settings中设置,给他们开一个通道
ITEM_PIPELINES = {
'ygdy8Spider.pipelines.JsonPipeline': 300,
'ygdy8Spider.pipelines.CsvPipeline': 301,
}
7.完整代码
ygdy8
# -*- coding: utf-8 -*-
import scrapy
import re
from scrapy.linkextractors import LinkExtractor #链接提取器
from scrapy.spiders import CrawlSpider, Rule #导入全站爬虫和采集规则
class Ygdy8Spider(CrawlSpider):
name = 'ygdy8'
allowed_domains = ['ygdy8.net']
start_urls = ['http://www.ygdy8.net/index.html']
#采集规则的集合
rules = (
#具体实现的采集规则
#采集导航页中电影的部分 allow是选择出所有带有index的网址 allow是正则表达式 只要写你想提取的链接的一部分就可以了
Rule(LinkExtractor(allow=r'index.html', deny='game')),
# follow=True 下一次提取网页中如果包含我们需要提取的信息是否还要继续提取
Rule(LinkExtractor(allow=r'list_\d+_\d+.html'),follow=True),
#allow里面提取详情页信息
#callback回调函数将相应交给谁处理
Rule(LinkExtractor(allow=r'/\d+/\d+.html'),callback='parse_item',follow=False)
)
#解析采集回来的数据,response就是得到的响应
def parse_item(self, response):
name = response.xpath('//div[@class="title_all"]/h1/font/text()').get()#获取电影名字
# name = response.xpath('//div[@class="title_all"]/h1/font/text()').extract_first()
ftp_url = re.findall('ftp',response.text)#response.text响应文本
#获取电影的ftp地址
if(name and ftp_url):#如果name和ftp_url都存在生成字典
items = {
'name': name,
'ftp_url': ftp_url
}
yield items
pipelines
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
import json
import csv
import os
# class Ygdy8SpiderPipeline(object):
# def process_item(self, item, spider):
# return item
class JsonPipeline(object):
def __init__(self):
self.file = open('阳光电影.json', 'w+',encoding='utf-8')
def open_spider(self, spider):
self.file.write('[')
def process_item(self, item, spider):
line = json.dumps(dict(item),ensure_ascii=False)+",\n"
self.file.write(line)
return item
def close_spider(self, spider):
self.file.seek(-1, os.SEEK_END)
self.file.truncate()
self.file.write(']')
self.file.close()
class CsvPipeline(object):
def __init__(self):
self.f = open("阳光电影.csv", "w",newline='')
self.writer = csv.writer(self.f)
self.writer.writerow(['name','ftp_url'])
def process_item(self, item, spider):
yangguang_list = [item['name'], item['ftp_url']]
self.writer.writerow(yangguang_list)
return item
settings
ITEM_PIPELINES = {
'ygdy8Spider.pipelines.JsonPipeline': 300,
'ygdy8Spider.pipelines.CsvPipeline': 301,
}