SpringBoot--Elasticsearch
-------------------------------------------------------聚沙成塔,每天进步一点-------------------------------------------------------
上篇博客使用命令操作ES,本文则使用代码操作,使用的是SpringBoot封装好的启动包。
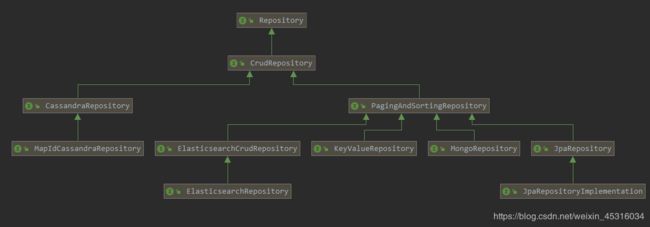
Spring Data Elasticsearch是SpringData下面的一个项目,所有Spring Data项目都有一个共同的并且非常重要的接口,就是存储库抽象中的中央接口Repository。你会发现无论是JpaRepository、MongoRepository还是ElasticsearchRepository都是其子类,因此他们的用法也及其相似,因为方法大部分都是来自父接口,如果你已经掌握了JPA,那么学习Elasticsearch成本将非常低,反之一样。
1、环境准备
首先ElasticSearch服务要装好,我是使用虚拟机安装的docker镜像,虚拟机是CentOS7,安装可以看ES安装,需要注意的就是版本问题,下面是Spring官方给出的版本匹配建议,这里的Spring Data Elasticsearch版本不是SpringBoot启动包的版本,具体下面再说。

2、使用
2.1 版本依赖
SpringBoot版本是2.1.6.RELEASE
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.1.6.RELEASE</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
ES依赖,这个是主要依赖,其他依赖自行添加
org.springframework.boot
spring-boot-starter-data-elasticsearch
查看该版本启动包的依赖关系,可以看到Spring Data Elasticsearch版本是3.1.9.RELEASE,ES的版本是6.4.3,根据Spring官方的建议对照表可以看到兼容的版本范围是3.0.x—6.8.1,所以安装的ES版本主要在这个范围都可以,这里选择较高版本的6.7.0,因为kibana增强了对中文的支持,用着舒服点,安装见上篇博客Docker–Elasticsearch、Kibana 、Logstash安装

注意:版本的不兼容会导致很多问题,而且不容易排查,因为报的错误五花八门,很难定位。
2.2 确定实体映射关系
@TableName(value = "oc_b_order")
@Data
@Document(indexName = "index_order",type = "type_order",shards =3,replicas =1)
public class OcOrder {
@JSONField(name = "ID")
@TableField(fill = FieldFill.INSERT)
@TableId(value = "id", type = IdType.INPUT)
@Field(type = FieldType.Long)
private Long id;
@JSONField(name = "BILL_NO")
@Field(type = FieldType.Keyword)
private String billNo;
@JSONField(name = "SOURCE_CODE")
@Field(type = FieldType.Keyword)
private String sourceCode;
@JSONField(name = "CP_C_SHOP_ID")
@Field(type = FieldType.Long)
private Long cpCShopId;
@JSONField(name = "CP_C_SHOP_TITLE")
@Field(type = FieldType.Keyword)
private String cpCShopTitle;
@JSONField(name = "CP_C_STORE_ID")
@Field(type = FieldType.Long)
private Long cpCStoreId;
@JSONField(name = "CP_C_STORE_ECODE")
@Field(type = FieldType.Keyword)
private String cpCStoreEcode;
@JSONField(name = "CP_C_STORE_ENAME")
@Field(type = FieldType.Keyword)
private String cpCStoreEname;
@JSONField(name = "CP_C_PHY_WAREHOUSE_ID")
@Field(type = FieldType.Long)
private Long cpCPhyWarehouseId;
@JSONField(name = "CP_C_PHY_WAREHOUSE_ECODE")
@Field(type = FieldType.Keyword)
private String cpCPhyWarehouseEcode;
@JSONField(name = "USER_NICK")
@Field(type = FieldType.Keyword)
private String userNick;
@JSONField(name = "ORDER_TYPE")
@Field(type = FieldType.Integer)
private Integer orderType;
@JSONField(name = "ORDER_STATUS")
@Field(type = FieldType.Integer)
private Integer orderStatus;
@JSONField(name = "OCCUPY_STATUS")
@Field(type = FieldType.Integer)
private Integer occupyStatus;
@JSONField(name = "WMS_STATUS")
@Field(type = FieldType.Integer)
private Integer wmsStatus;
@JSONField(name = "ORDER_SOURCE")
@Field(type = FieldType.Keyword)
private String orderSource;
}
下面简单说下实体上的注解,没说到的就不是ES的注解,可以忽略:
@Document
作用在类上,标记实体类为文档对象,属性比较多

| 属性 | 类型 | 说明 | 默认值 |
|---|---|---|---|
| indexName | String | 索引库名 | |
| type | String | 对应在索引库中的类型 | " " |
| useServerConfiguration | boolean | 是否使用服务配置 | false |
| shards | short | 分片数量 | 5 |
| replicas | short | 副本数量 | 1 |
| refreshInterval | String | 刷新间隔 | “1s” |
| indexStoreType | String | 索引文件存储类型 | "fs " |
| createIndex | boolean | 新增数据时,如果没有索引是否创建 | true |
@Id 加在主见上,标记一个字段作为id主键;
@Field 作用在字段上,标记为文档的字段,并指定字段映射属性:
@Field默认是可以不加的,默认所有属性都会添加到ES中。加上@Field之后,@document默认把所有字段加上索引失效,只有@Field 才会被索引(同时也看设置索引的属性是否为no)

| 属性 | 类型 | 说明 | 默认值 |
|---|---|---|---|
| type | FieldType | 字段类型,Text分词,Keyword不分词 | FieldType.Auto(自动检测) |
| index | boolean | 是否索引 | true |
| format | DateFormat | 日期格式化 | DateFormat.none(不格式化) |
| pattern | String | 格式模板,和format一起使用 | " " |
| store | boolean | 是否单独存储一份 | false |
| fielddata | boolean | 存储在内存中的查询时数据结构 | false |
| searchAnalyzer | String | 指定字段搜索时使用的分词器 | " " |
| analyzer | String | 分词器名称,比如中文分词器 ik_max_word | " " |
| normalizer | String | 应用规范化器 | " " |
| ignoreFields | String[] | 忽略的字段组 | {} |
| includeInParent | boolean | 字段是否包括在父类字段中 | false |
| copyTo | String[] | 将当前字段的值复制到该属性指定的字段中 | {} |
keyword和text区别:
keyword:会被当做一个词条,不会再进行分词。可以被用来检索过滤、排序和聚合。keyword 类型字段只能用本身来进行检索。
text:可以进行分词,可以用来索引长文本,将文本分析后进行分词并给分词后的词条建立索引,text 数据类型不能用来排序和聚合。
2.3 application.properties配置文件
server.port=9009
###########数据库连接信息###############
spring.datasource.url=jdbc:mysql://localhost:3306/test?serverTimezone=UTC&characterEncoding=utf-8
spring.datasource.username=root
spring.datasource.password=123456
##########es主要配置#########
spring.data.elasticsearch.cluster-name=docker-cluster
spring.data.elasticsearch.cluster-nodes=192.168.153.129:9300
注意:
1、这里的cluster-name要和/usr/share/elasticsearch/config/elasticsearch.yml文件中的要一致,也可以浏览器访问 ip:9200查看;
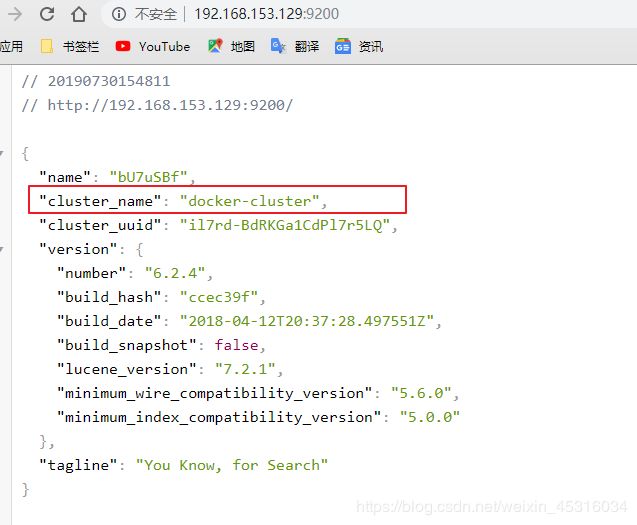
2、端口是9300,而不是9200,9300 是 Java 客户端的端口。9200是支持 Restful HTTP的端口;
2.4 创建接口
创建一个接口,继承ElasticsearchRepository,泛型参数一个是实体,一个是实体主键类型。这样就可以直接使用父接口中的很多基本方法了。
public interface OcOrderRepository extends ElasticsearchRepository<OcOrder, Long> {
}
这里有个坑点,如果要和MybatisPlus一起使用,而MybatisPlus也需要继承一个接口BaseMapper< OcOrder>,并加上@Mapper注解,同一个接口同时继承使用会冲突,重复注入,所以只能写两个接口分别继承了。
@Mapper
public interface OcOrderMapper extends BaseMapper<OcOrder> {
}
2.5 测试
两种方式,要么使用ElasticsearchTemplate,要么使用刚才定义的接口。
2.5.1 索引操作
基本没用,因为新增数据的时候就自动创建了。
@RunWith(SpringRunner.class)
@SpringBootTest(classes = ElasticSearchApplication.class)
public class ElasticSearchApplicationTests {
@Autowired
private ElasticsearchTemplate elasticsearchTemplate;
@Autowired
private OcOrderRepository ocOrderRepository;
@Autowired
private OcOrderMapper ocOrderMapper;
@Test
public void test01() {
//创建索引
elasticsearchTemplate.createIndex(OcOrder.class);
//建立映射关系
elasticsearchTemplate.putMapping(OcOrder.class);
//删除索引
//elasticsearchTemplate.delete(new DeleteQuery(),OcOrder.class);
}
2.5.2 文档操作
2.5.2.1 新增和修改
修改和新增是同一个接口,根据id区分,存在就是修改,不存在就是新增。
//修改和新增是同一个接口,根据id区分
//新增文档数据
OcOrder ocOrder = ocOrderMapper.selectById(9952L);
ocOrder.setOrderDate(new Date());
ocOrderRepository.save(ocOrder);
//批量新增
List<OcOrder> ocOrders = ocOrderMapper.selectList(null);
ocOrderRepository.saveAll(ocOrders);
//删除文档数据
ocOrderRepository.delete(ocOrder);
2.5.2.2 查询
基本查询
//根据id查询
Optional<OcOrder> order = ocOrderRepository.findById(10L);
//查询所有
Iterable<OcOrder> all = ocOrderRepository.findAll();
//根据id排序查询
Iterable<OcOrder> repositoryAll = ocOrderRepository.findAll(Sort.by(Sort.Direction.DESC, "id"));
//根据约定方法名称查询,会根据名称自动识别
List<OcOrder> orders = ocOrderRepository.findByWmsCancelStatusBetween(1L, 6L);
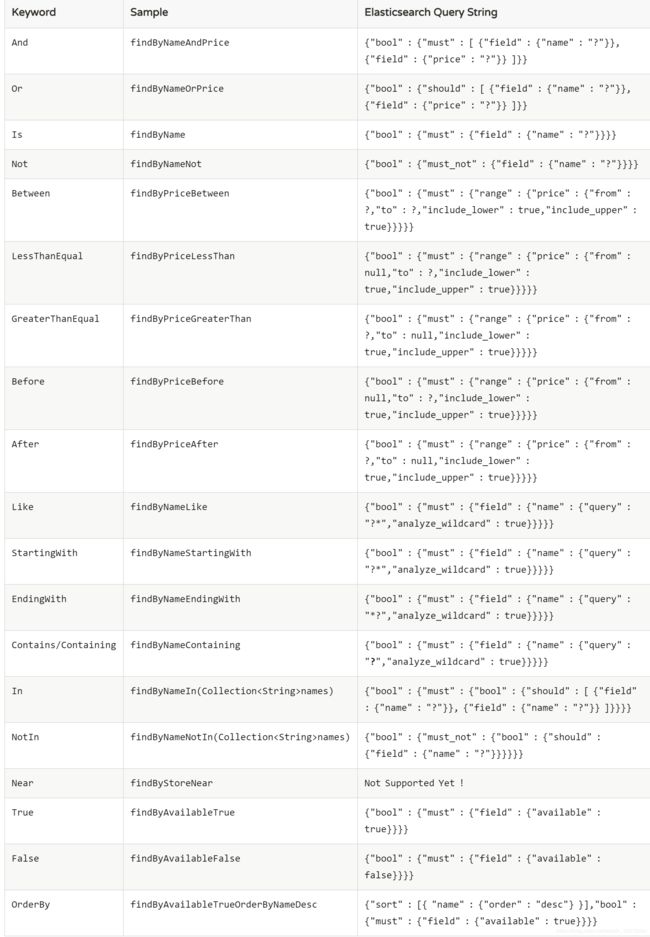
规则方法名自动实现
SpringData系列都有这么规则,比如JPA,ES也一样,按照一定的规则命名方法即可自动实现相关功能。
示例,查询WmsCancel状态在两个值之间的文档数据:
public interface OcOrderRepository extends ElasticsearchRepository<OcOrder, Long> {
//约定方法名称
List<OcOrder> findByWmsCancelStatusBetween(Long value1, Long value2);
}
以下是Spring官网的截图,列举了部分示例:
条件查询
Spring Data Elasticsearch提供了一个两个对象用于条件查询,QueryBuilders和NativeSearchQueryBuilder。QueryBuilders以静态方法的形式提供了常用的条件查询,而NativeSearchQueryBuilder对象用于构造复杂查询的条件,类似与MyBatis-Plus 的QueryWrapper构造器。
QueryBuilders示例:
//查询全部
MatchAllQueryBuilder queryBuilder = QueryBuilders.matchAllQuery();
Iterable<OcOrder> allOrders = ocOrderRepository.search(queryBuilder);
allOrders.forEach(System.out::println);
//字段匹配查询
TermsQueryBuilder userNick = QueryBuilders.termsQuery("user_nick", "0(淘宝测试店铺)");
Iterable<OcOrder> search = ocOrderRepository.search(userNick);
search.forEach(System.out::println);
NativeSearchQueryBuilder示例:
//构建查询对象
NativeSearchQueryBuilder nativeSearchQueryBuilder = new NativeSearchQueryBuilder();
//链式拼接查询条件
nativeSearchQueryBuilder.withQuery(QueryBuilders.matchQuery("userNick", "0(淘宝测试店铺)")).withQuery(QueryBuilders.matchQuery("cpCStoreEcode", "789"));
//加载查询条件
Page<OcOrder> ocOrderPage = ocOrderRepository.search(nativeSearchQueryBuilder.build());
ocOrderPage.forEach(System.out::println);
使用NativeSearchQueryBuilder可以构建各种复杂的查询条件,如排序、分页等,这里不演示了。
** @Query注解查询**
如果觉得条件构造过于难用或者复杂,也可以使用Kibana的查询命令结合注解查询,类似于Mybatis的@select,可以直接将sql语句放进去查询,但是这里只有一个查询注解,没有新增、修改、删除。具体使用如下:
一、Kibana命令
GET index_order/type_order/_search
{
"query": {
"bool": {
"must": [
{"match": {
"cpCShopTitle": "淘宝测试店铺"
}},
{
"match": {
"cpCStoreId": "3254"
}
}
]
}
}
}
二、将"query"中的全部内容copy至注解的value内,如下:
public interface OcOrderRepository extends ElasticsearchRepository<OcOrder, Long> {
@Query("{\n" +
" \"bool\": {\n" +
" \"must\": [\n" +
" {\"match\": {\n" +
" \"cpCShopTitle\": \"?0\"\n" +
" }},\n" +
" {\n" +
" \"match\": {\n" +
" \"cpCStoreId\": \"?1\"\n" +
" }\n" +
" }\n" +
" ]\n" +
" }\n" +
" }")
List<OcOrder> queryByAnnotation(String cpCShopTitle, Long cpCStoreId);
}
其中?0代表参数占位,?是占位符,数字是第几个参数,从0开始。