Scrapy+Mysql+SqlAlchemy爬取招聘网站信息
爬虫目的:
爬取拉勾网站杭州分站的python岗位基本信息和岗位详情,并写入mysql数据库。后附经验总结。
知识点,
1、解析函数多个yield以及多个pipeline的使用
2、Sqlalchemy框架的使用
3、Scrapy FormRequest请求,以及反爬
难点:
岗位详细信息的url不能直接从爬虫返回信息获得,而需要另外构建url。然后通过
request再次请求,以及回调的解析函数处理后交给pipeline入库。即同一个岗位的信息需要两次入库。经尝试,用同一个mysql表格入库容易出现信息缺失,最终的方案是分两个表格入库,然后在mysql里面连接为一个表格。
代码如下:
settings.py
BOT_NAME = 'lagou1'
SPIDER_MODULES = ['lagou1.spiders']
NEWSPIDER_MODULE = 'lagou1.spiders'
MYSQL_CONNECTION='mysql+mysqlconnector://XXX:XXXX@localhost:3306/pydb?charset=utf8'
# Obey robots.txt rules
ROBOTSTXT_OBEY = False #这个改成True,经常会没有结果。
# Configure maximum concurrent requests performed by Scrapy (default: 16)
CONCURRENT_REQUESTS = 2
DOWNLOAD_DELAY = 3
# The download delay setting will honor only one of:
CONCURRENT_REQUESTS_PER_DOMAIN = 3
CONCURRENT_REQUESTS_PER_IP = 3
# Disable cookies (enabled by default)
COOKIES_ENABLED = True
# Disable Telnet Console (enabled by default)
#TELNETCONSOLE_ENABLED = False
# Override the default request headers:
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
}
DOWNLOADER_MIDDLEWARES = {
'lagou1.middlewares.Lagou1DownloaderMiddleware': 400,
# 'lagou1.middlewares.CustomerMiddleware':200
}
MEDIA_ALLOW_REDIRECTS =True #^^^^^^^^^^^^^^^^^^^^^^重要,解决图片无法下载
ITEM_PIPELINES = {
'lagou1.pipelines.Lagou1Pipeline': 300,
'lagou1.pipelines.Lagou1Pipeline2': 310,
# 'lagou1.pipelines.DownloadFile':320,
}
items.py
import scrapy
class Lagou1Item(scrapy.Item):
positionId=scrapy.Field()
positionName=scrapy.Field()
createTime=scrapy.Field()
companyId=scrapy.Field()
companyShortName=scrapy.Field()
companyFullName=scrapy.Field()
city=scrapy.Field()
salary=scrapy.Field()
positionLables=scrapy.Field()
job_trigger=scrapy.Field()
job_description=scrapy.Field()
job_detail_url=scrapy.Field()
lagouspider.py
# -*- coding: utf-8 -*-
import scrapy
from lagou1.items import Lagou1Item
import json
import requests
import time
from bs4 import BeautifulSoup
class LagouspiderSpider(scrapy.Spider):
name = 'lagouspider'
allowed_domains = ['lagou.com']
start_urls = ['https://www.lagou.com/jobs/positionAjax.json?city=%E6%9D%AD%E5%B7%9E&needAddtionalResult=false']#'https://www.lagou.com/jobs/positionAjax.json?needAddtionalResult=false'
proxies={"http":"http://112.111.217.45:9999"}
h1={'User-Agent': 'Opera/9.80 (iPhone; Opera Mini/7.1.32694/27.1407; U; en) Presto/2.8.119 Version/11.10',\
'Referer': 'https://www.lagou.com/jobs/list_python?labelWords=&fromSearch=true&suginput='} #创建不同的headers
h2={'User-Agent': 'Mozilla/5.0 (Linux; U; Android 2.0; en-us; Droid Build/ESD20) AppleWebKit/530.17 (KHTML, like Gecko) Version/4.0 Mobile Safari/530.17',\
'Referer': 'https://www.lagou.com/jobs/list_python?labelWords=&fromSearch=true&suginput='}
h3={'User-Agent': 'Opera/9.80 (iPhone; Opera Mini/7.1.32694/27.1407; U; en) Presto/2.8.119 Version/11.10',\
'Referer': 'https://www.lagou.com/jobs/list_python?labelWords=&fromSearch=true&suginput='}
h4={'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Trident/7.0; rv:11.0) like Gecko'}
def get_Cookies(self,proxies,headers): #构建获得cookies的函数
url = 'https://www.lagou.com/jobs/list_python'
session = requests.session()
session.post(url,headers=headers,proxies=proxies)
cookies = session.cookies
return cookies.get_dict()
def start_requests(self):
for i in range(1,11):
para = {'first': 'true', 'pn': str(i), 'kd': 'python'}
yield scrapy.FormRequest(self.start_urls[0],headers=self.h3,formdata=para,cookies=self.get_Cookies(self.proxies,self.h1),callback=self.parse)#也可以使用如下的request,不过结果不同???
# yield scrapy.Request(self.start_urls[0],method=POST,headers=self.h3,body=json.dumps(para),cookies=self.cookies,callback=self.parse) #功能同上条Formrequest,不过要增加method参数,formdata改成body,且接受json数据
def parse(self, response):
# print(response.text) #查看请求结果
# with open('e:/testlagou1.txt','w') as fp1:
# fp1.write(response.text)
# with open('e:/testlagou2.txt','wb') as fp2:
# fp2.write(response.body)
item= Lagou1Item()
t=json.loads(response.body_as_unicode())#注意loads函数的使用
positionId_list=[]
positionName_list=[]
createTime_list=[]
companyId_list=[]
companyShortName_list=[]
companyFullName_list=[]
city_list=[]
salary_list=[]
positionLables_list=[]
job_detail_url_list=[]
for results in t['content']['positionResult']['result']:
positionId=results['positionId']
positionName = results['positionName']
createTime = results['createTime']
companyShortName =results['companyShortName']
# workYear = results['workYear']
city = results['city']
salary = results['salary']
companyId=results['companyId']
companyFullName=results['companyFullName']
positionLables = results['positionLables']
positionLables= ','.join(positionLables)
# positionAdvantage = results['positionAdvantage']
job_detail_url = 'https://www.lagou.com/jobs/' + str(positionId) + '.html'
# companyLogo=results['companyLogo']
# print(positionName,companyShortName,workYear,city,salary,positionLables,positionAdvantage,companyLogo) #查看是否顺利爬取数据
positionId_list.append(positionId)
positionName_list.append(positionName)
createTime_list.append(createTime)
companyId_list.append(companyId)
companyShortName_list.append(companyShortName)
companyFullName_list.append(companyFullName)
positionLables_list.append(positionLables)
city_list.append(city)
salary_list.append(salary)
job_detail_url_list.append(job_detail_url)
item['positionId']=positionId_list
item['positionName']=positionName_list
item['createTime']=createTime_list
item['companyShortName']=companyShortName_list
item['companyFullName']=companyFullName_list
item['city']= city_list
item['companyId']=companyId_list
item['salary']=salary_list
item['positionLables']= positionLables_list
item['job_detail_url']=job_detail_url_list
yield item 返回岗位基本信息供pipeline入库。
for i in item['job_detail_url']: #请求岗位详细信息url,回调函数parse_job_detail继续解析
yield scrapy.Request(i,headers=self.h4,cookies=self.get_Cookies(self.proxies,self.h4),callback=self.parse_job_details) #此处cookies很重要,否则反爬起作用,得不到结果
#
#
def parse_job_details(self,response): #用来获取详细的职位描述,以及职位编号,用来和parse函数获取的信息进行匹配。
soup=BeautifulSoup(response.body_as_unicode(),'lxml')
item=Lagou1Item()
positionId=response.url.split('/')[-1].split('.')[0].strip()
# job_trigger=response.xpath('//*[@id="job_detail"]/dd[1]/p/text()').extract()
# job_description =response.xpath('//*[@id="job_detail"]/dd[2]/div/text()').extract().strip()
try: #beatifulsoup解析
job_trigger=soup.select_one('#job_detail > dd.job-advantage >p').text.strip()
job_description = soup.select_one('#job_detail > dd.job_bt > div').text.strip()
except Exception as e:
print(e)
# 以下是测试时面临反爬,无法得到结果时尝试的xpath方式,后来解决反爬的为,也就用不到了。 job_description=response.xpath('//*@id="job_detail"]/dd[2]/div/text()').extract()
# job_trigger=response.xpath('//*[@id="job_detail"]/dd[1]/p/text()').extract()
# job_description=''.join(job_description)
# job_trigger=''.join(job_trigger)
# for i in range(3):
# print(response.body)
# print('I am in parsejobdetals:',e)
item['positionId']=positionId
item['job_description'] =job_description
item['job_trigger']=job_trigger
return item
pipelines.py
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
from scrapy.pipelines.images import ImagesPipeline
#from scrapy.pipelines.files import FilesPipeline
from scrapy import Request
from scrapy.exceptions import DropItem
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column,Integer,String,DateTime
from sqlalchemy.orm import sessionmaker
import mysql.connector #注意格式
#sqlalchemy映射数据表
Base=declarative_base()
class Lagoujob(Base): #这个参数父类名
__tablename__='lagoujob' #存储岗位基本信息的数据表
id=Column(Integer,primary_key=True)
positionId=Column(String(50),unique=True)
positionName=Column(String(50))
createTime=Column(DateTime)
companyId=Column(String(50))
companyShortName=Column(String(100))
companyFullName=Column(String(100)) #公司简称的长度超过想象,所以数值要大些
city=Column(String(50))
salary=Column(String(30))
positionLables=Column(String(100))
job_detail_url=Column(String(100))
class Lagoudetails(Base):
__tablename__='lagoudetails' #存储岗位详细信息的数据表
id=Column(Integer,primary_key=True)
positionId=Column(String(50),unique=True)
job_trigger=Column(String(100))
job_description=Column(String(1000))
class Lagou1Pipeline(object):
def __init__(self):
connection='mysql+mysqlconnector://pyuser:888888@localhost:3306/pydb?charset=utf8' #UTF8MB4
engine=create_engine(connection,echo=True) #数据库连接
DBSession=sessionmaker(bind=engine) #创建会话对象,用于数据表的操作
self.Sqlsession=DBSession()
Base.metadata.create_all(engine) #创建数据表
def process_item(self, item, spider):
if 'job_trigger' not in item.keys(): 两个pipeline处理
for i in range(0,len(item['positionId'])): #这里不能用len(item),因为只有10个字段,只能存入前10条记录
try:
jobs=Lagoujob(positionId=item['positionId'][i],positionName=item['positionName'][i],createTime=item['createTime'][i],companyId=item['companyId'][i],companyShortName=item['companyShortName'][i],companyFullName=item['companyFullName'][i],city=item['city'][i],salary=item['salary'][i],positionLables=item['positionLables'][i],job_detail_url=item['job_detail_url'][i])
self.Sqlsession.add(jobs)
self.Sqlsession.commit()
except Exception as e:
self.Sqlsession.rollback() #如果需要执行异常语句,此句不可少!
# pass
print(e)
return item
#以下需要另外做一个类
class Lagou1Pipeline2(object):
def __init__(self):
connection='mysql+mysqlconnector://XXX:XXXXXlocalhost:3306/pydb?charset=utf8' #UTF8MB4
engine=create_engine(connection,echo=True) #数据库连接
DBSession=sessionmaker(bind=engine) #创建会话对象,用于数据表的操作
self.Sqlsession2=DBSession()
Base.metadata.create_all(engine) #创建数据表
def process_item(self, item, spider):
if 'job_trigger' in item: jobdetails=Lagoudetails(positionId=item['positionId'],job_trigger=item['job_trigger'], job_description=item['job_description'])
try:
self.Sqlsession2.add(jobdetails)
self.Sqlsession2.commit()
except Exception as e:
print(e)
# self.Sqlsession2.rollback()
return item
class DownloadFile(ImagesPipeline): #爬取图片pipeline未使用。
def get_media_requests(self,item,info):
for url,filename in zip(item['FileUrl'],item['FileName']):
cookies={'X_HTTP_TOKEN': '42daf4b72327b2815637417751bf5e71415983ed09', 'user_trace_token': '20191224082925-308fab45-3629-4198-be34-cbb2eb78a270', 'JSESSIONID': 'ABAAABAAAGGABCB228791B35A6AD371A8A3D1C8FF1D6C88', 'SEARCH_ID': 'fd50d5fe208f4940a22a2bd69d76a576'}
h3={'User-Agent': 'Opera/9.80 (iPhone; Opera Mini/7.1.32694/27.1407; U; en) Presto/2.8.119 Version/11.10',\
'Referer': 'https://www.lagou.com/jobs/list_python?labelWords=&fromSearch=true&suginput='}
yield Request(url,headers=h3,cookies=cookies,meta={'name':filename})
def file_path(self,request,response=None,info=None):
file_name='E:\\scrapypro\\lagou1\\pic\\'+(request.meta['name'])+'.jpg'
return file_name
def item_completed(self, results, item, info):
image_path = [x['path'] for ok, x in results if ok]
if not image_path:
raise DropItem('Item contains no images')
item['image_paths'] = image_path
return item
爬取结果:
lagoujob表格

lagoudetails
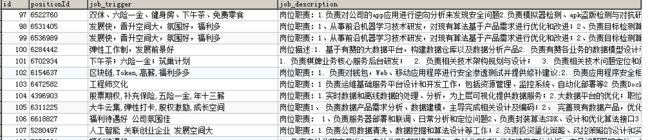
最后通过Mysql的 inner join语句将两个表格连接成一个新的表格。
create table lagoujobinfo(select lagoujob.*,lagoudetails.job_trigger,lagoudetails.job_description from lagoujob
LEFT JOIN lagoudetails on lagoujob.positionId=lagoudetails.positionId);

经验:
1、得不到预期结果,可以在代码相应环节中增加print信息,查看问题所在。
2、很多时候是反爬导致了运行出错,并非代码有问题。所以需要解决反爬的问题。
3、尝试了使用一个数据表的操作,发现总有信息遗漏,最后稳妥起价,干脆分两个表格,然后连接成一个。
4、一开始数据数据一直没有入库,后来找到原因是映射数据表的时候字段长度设置太保守,爬取的信息过
长,写不下导致的。