istio流量治理——原理
文章来源于《云原生服务网格istio》,作者读书笔记
流量治理是一个非常宽泛的话题,例如:
◎ 动态修改服务间访问的负载均衡策略,比如根据某个请求特征做会话保持;
◎ 同一个服务有两个版本在线,将一部分流量切到某个版本上;
◎ 对服务进行保护,例如限制并发连接数、限制请求数、隔离故障服务实例等;
◎ 动态修改服务中的内容,或者模拟一个服务运行故障等。
在Istio中实现这些服务治理功能时无须修改任何应用的代码。较之微服务的SDK方式,Istio以一种更 轻便、透明的方式向用户提供了这些功能。用户可以用自己喜欢的任意语言和框架进行开发,专注于自己的业务,完全不用嵌入任何治理逻辑。只要应用运行在Istio的基础设施上,就可以使用这些治理能力。一句话总结 Istio 流量治理的目标:以基础设施的方式提供给用户非侵入的流量治理能力,用户只需关注自己的业务逻辑开发,无须关注服务访问管理。
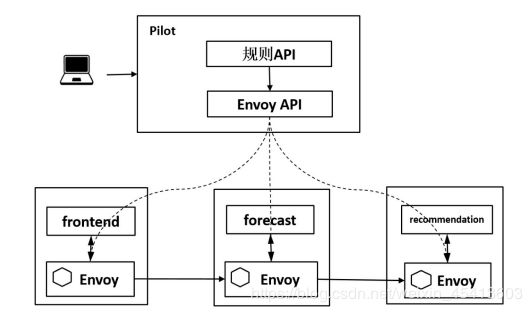
在控制面会经过如下流程:
(1)管理员通过命令行或者API创建流量规则;
(2)Pilot将流量规则转换为Envoy的标准格式;
(3)Pilot将规则下发给Envoy。
在数据面会经过如下流程:
(1)Envoy拦截Pod上本地容器的Inbound流量和Outbound流量;
(2)在流量经过Envoy时执行对应的流量规则,对流量进行治理。
1 负载均衡
(1)服务注册。各服务将服务名和服务实例的对应信息注册到服务注册中心。
(2)服务发现。在客户端发起服务访问时,以同步或者异步的方式从服务注册中心获取服务对应的
实例列表。
(3)负载均衡。根据配置的负载均衡算法从实例列表中选择一个服务实例。
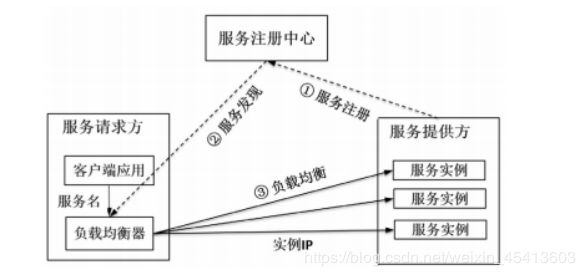
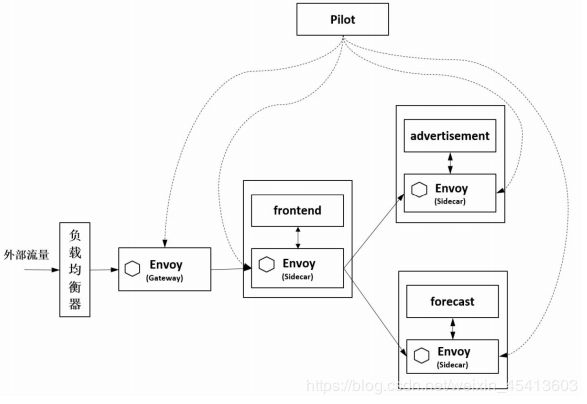
Istio的负载均衡正是其中的一个具体应用。在Istio中,Pilot负责维护服务发现数据。如图 所示为Istio 负载均衡的流程,Pilot将服务发现数据通过 Envoy的标准接口下发给数据面Envoy,Envoy则根据配置的负载均衡策略选择一个实例转发请求。Istio当前支持的主要负载均衡算法包括:轮询、随机和最小连接数算法。

在Kubernetes上支持Service的重要组件Kube-proxy,实际上也是运行在工作节点的一个网络代理和负载均衡器,它实现了Service模型,默认通过轮询等方式把Service访问转发到后端实例Pod上。
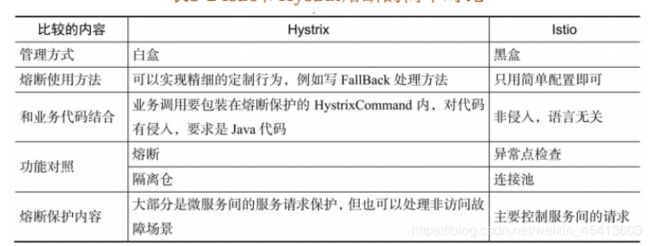
2服务熔断
与Hystrix类似,在Istio中也提供了连接池和故障实例隔离的能力,只是概念术语稍有不同:前者在Istio 的配置中叫作连接池管理,后者叫作异常点检测,分别对应 Envoy的熔断和异常点检测。
(1)在 Istio 中通过限制某个客户端对目标服务的连接数、访问请求数等,避免对一个服务的过量访问,如果超过配置的阈值,则快速断路请求。还会限制重试次数,避免重试次数过多导致系统压力变大并加剧故障的传播;
(2)如果某个服务实例频繁超时或者出错,则将该实例隔离,避免影响整个服务。
Istio 的连接池管理工作机制对 TCP 提供了最大连接数、连接超时时间等管理方式,对HTTP提供了最大请求数、最大等待请求数、最大重试次数、每连接最大请求数等管理方式,它控制客户端对目标服务的连接和访问,在超过配置时快速拒绝。
Istio提供的异常点检查机制动态地将异常实例从负载均衡池中移除,如下图所示,当连续的错误数超过配置的阈值时,后端实例会被移除。异常点检查在实现上对每个上游服务都进行跟踪,对于HTTP服务,如果有主机返回了连续的5xx,则会被踢出服务池;而对于TCP服务,如果到目标服务的连接超时和失败,则都会被记为出错。
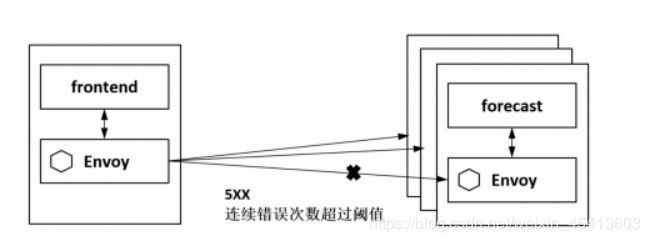
另外,被移除的实例在一段时间之后,还会被加回来再次尝试访问,如果可以访问成功,则认为实例正常;如果访问不成功,则实例不正常,重新被逐出,后面驱逐的时间等于一个基础时间乘以驱逐的次数。这样,如果一个实例经过以上过程的多次尝试访问一直不可用,则下次会被隔离更久的时间。可以看到,Istio 的这个流程也是基于 Martin 的熔断模型设计和实现的,不同之处在于这里没有熔断半开状态,熔断器要打开多长时间取决于失败的次数。
另外,在 Istio 中可以控制驱逐比例,即有多少比例的服务实例在不满足要求时被驱逐。当有太多实例被移除时,就会进入恐慌模式,这时会忽略负载均衡池上实例的健康标记,仍然会向所有实例发送请求,从而保证一个服务的整体可用性。
3 故障注入
对于一个系统,尤其是一个复杂的系统,重要的不是故障会不会发生,而是什么时候发生。故障处理对于开发人员和测试人员来说都特别耗费时间和精力:对于开发人员来说,他们在开发代码时需要用20%的时间写80%的主要逻辑,然后留出80%的时间处理各种非正常场景;对于测试人员来说,除了需要用80%的时间写20%的异常测试项,更要用超过80%的时间执行这些异常测试项,并构造各种故障场景,尤其是那种理论上才出现的故障,让人苦不堪言。
故障注入是一种评估系统可靠性的有效方法,最早在硬件场景下将电路板短路来其观察对系统的影响,在软件场景下也是使用一种手段故意在待测试的系统中引入故障,从而测试其健壮性和应对故障的能力,例如异常处理、故障恢复等。只有当系统的所有服务都经过故障测试且具备容错能力时,整个应用才健壮可靠。
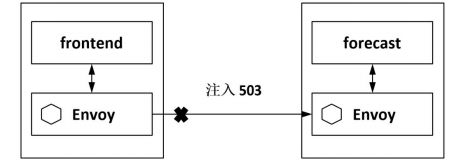
故障注入从方法上来说有编译期故障注入和运行期故障注入,前者要通过修改代码来模拟故障,后者在运行阶段触发故障。在分布式系统中,比较常用的方法是在网络协议栈中注入对应协议的故障,干预服务间的调用,不用修改业务代码。Istio的故障注入就是这样一种机制的实现,但不是在底层网络层破坏数据包,而是在网格中对特定的应用层协议进行故障注入,虽然在网络访问阶段进行注入,但其作用于应用层。这样,基于 Istio 的故障注入就可以模拟出应用的故障场景了。如图所示,可以对某种请求注入一个指定的HTTP Code,这样,对于访问的客户端来说,就跟服务端发生异常一样。
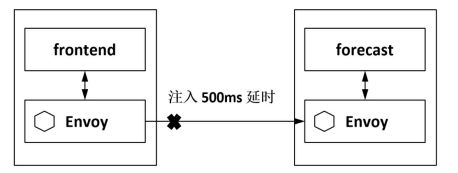
还可以注入一个指定的延时,这样客户端看到的就跟服务端真的响应慢一样,我们无须为了达到这 种效果在服务端的代码里添一段sleep(500),如图所示。
实际上,在 Istio 的故障注入中可以对故障的条件进行各种设置,例如只对某种特定请求注入故障,其他请求仍然正常。
4发布方式
(1)蓝绿发布
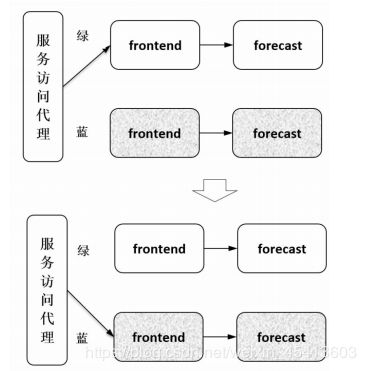
蓝绿发布的主要思路如图所示,让新版本部署在另一套独立的资源上,在新版本可用后将所有流量都从老版本切到新版本上来。当新版本工作正常时,删除老版本;当新版本工作有问题时,快速切回到老版本,因此蓝绿发布看上去更像一种热部署方式。在新老版本都可用时,升级切换和回退的速度都可以非常快,但快速切换的代价是要配置冗余的资源,即有两倍的原有资源,分别部署新老版本。另外,由于流量是全量切换的,所以如果新版本有问题,则所有用户都受影响,但比蛮力发布在一套资源上重新安装新版本导致用户的访问全部中断,效果要好很多。
(2)AB测试
AB测试的场景比较明确,就是同时在线上部署A和B两个对等的版本来接收流量,如图所示,按一定的目标选取策略让一部分用户使用 A 版本,让一部分用户使用 B版本,收集这两部分用户的使用反馈,即对用户采样后做相关比较,通过分析数据来最终决定采用哪个版本。
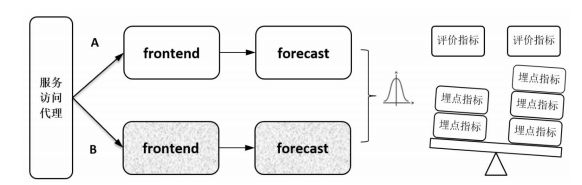
对于有一定用户规模的产品,在上线新特性时都比较谨慎,一般都需要经过一轮 AB测试。在AB测试里面比较重要的是对评价的规划:要规划什么样的用户访问,采集什么样的访问指标,尤其是,指标的选取是与业务强相关的复杂过程,所以一般都有一个平台在支撑,包括业务指标埋点、收集和评价。
(3)金丝雀发布
金丝雀发布就比较直接,如图所示,上线一个新版本,从老版本中切分一部分线上流量到新版 本来判定新版本在生产环境中的实际表现。就像把一个金丝雀塞到瓦斯井里面一样,探测这个新版本在环境中是否可用。先让一小部分用户尝试新版本,在观察到新版本没有问题后再增加切换的比例,直到全部切换完成,是一个渐变、尝试的过程。
蓝绿发布、AB 测试和金丝雀发布的差别比较细微,有时只有金丝雀才被称为灰度发布,这里不用太纠缠这些划分,只需关注其共同的需求,就是要支持对流量的管理。能否提供灵活的流量策略是判断基础设施灰度发布支持能力的重要指标。
灰度发布技术上的核心要求是要提供一种机制满足多不版本同时在线,并能够灵活配置规则给不同的版本分配流量
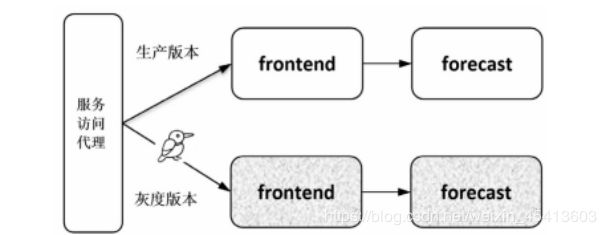
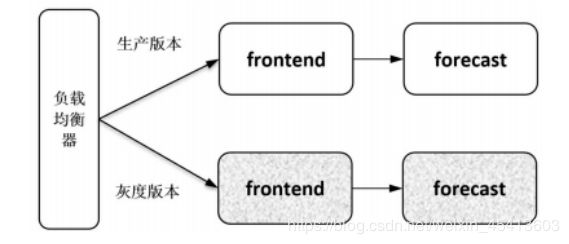
(4)基于负载均衡器的灰度发布
比较传统的灰度发布方式是在入口的负载均衡器上配置流量策略,这种方式要求负载均衡器必须支持相应的流量策略,并且只能对入口的服务做灰度发布,不支持对后端服务单独做灰度发布。如图3-16所示,可以在负载均衡器上配置流量规则对frontend服务进行灰度发布,但是没有地方给 forecast 服务配置分流策略,因此无法对 forecast 服务做灰度发布。
(5)基于Kubernetes的灰度发布
在Kubernetes环境下可以基于Pod的数量比例分配流量。如图所示,forecast服务的两个版本v2和v1分别有两个和3个实例,当流量被均衡地分发到每个实例上时,前者可以得到40%的流量,后者可以得到60%的流量,从而达到流量在两个版本间分配的效果。
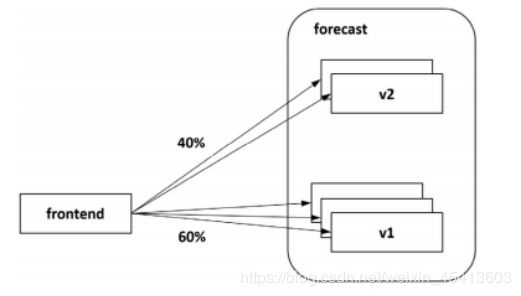
通过更改pod新旧版本的数量来做一个负载的分发调度,也可以用一个svc管理2个depoy的方式来做新旧版本的更替
(6)基于Istio的灰度发布
不同于前面介绍的熔断、故障注入、负载均衡等功能,Istio本身并没有关于灰度发布的规则定义,灰度发布只是流量治理规则的一种典型应用,在进行灰度发布时,只要写个简单的流量规则配置即可。
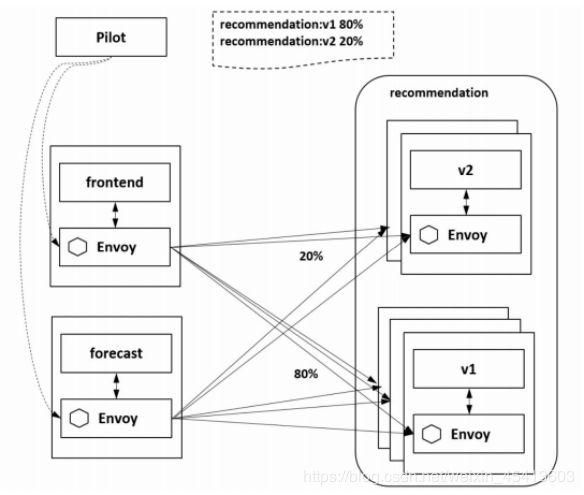
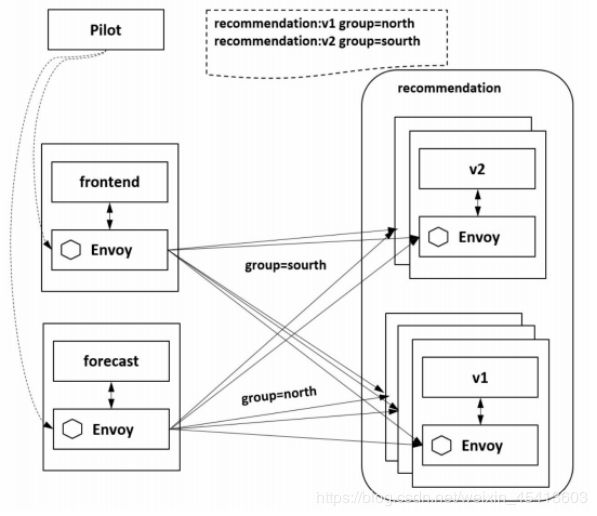
Istio在每个Pod里都注入了一个Envoy,因而只要在控制面配置分流策略,对目标服务发起访问的每
个Envoy便都可以执行流量策略,完成灰度发布功能。如图所示为对recommendation服务进行灰度发布,配置20%的流量到v2版本,保留80%的流量在v1版本。通过Istio控制面Pilot下发配置到数据面的各个Envoy,调用recommendation 服务的两个服务frontend 和 forecast 都会执行同样的策略,对recommendation服务发起的请求会被各自的Envoy拦截并执行同样的分流策略。
在 Istio 中除了支持这种基于流量比例的策略,还支持非常灵活的基于请求内容的灰度策略。比如某个特性是专门为Mac操作系统开发的,则在该版本的流量策略中需要匹配请求方的操作系统。浏览器、请求的Headers等请求内容在Istio中都可以作为灰度发布的特征条件。如图所示为根据Header的内容将请求分发到不同的版本上。
5 服务访问入口
一组服务组合在一起可以完成一个独立的业务功能,一般都会有一个入口服务,从外部可以访问,主要是接收外部的请求并将其转发到后端的服务,有时还可以定义通用的过滤器在入口处做权限、限流等功能,如图所示。
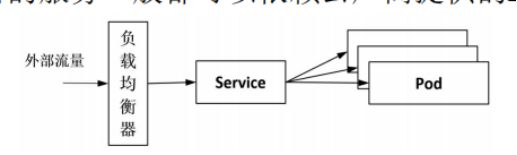
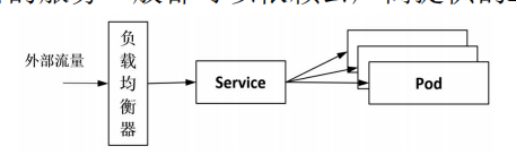
(1)Kuberntes服务的访问入口
在 Kubernetes 中可以将服务发布成 Loadbalancer 类型的 Service,通过一个外部端口就能访问到集群中的指定服务,如图所示,从外部进来的流量不用经过过滤和多余处理,就被转发到服务上。这种方式直接、简单,在云平台上部署的服务一般都可以依赖云厂商提供的Loadbalancer来实现。
Kubernetes支持的另一种Ingress方式专门针对七层协议。Ingress作为一个总的入口,根据七层协议中的路径将服务指向不同的后端服务,如图所示,在“weather.com”这个域名下可以发布两个服务,forecast 服务被发布在“weather.com/forecast”上,advertisement服务被发布在“weather.com/advertisement”上,这时只需用到一个外部地址。
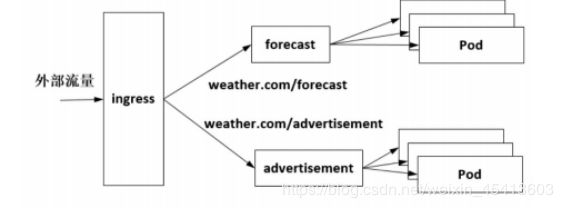
Ingress是一套规则定义,将描述某个域名的特定路径的请求转发到集群指定的Service后端
上。Ingress Controller作为Kubernetes的一个控制器,监听Kube-apiserver的Ingress对应的后端服务,实时获取后端Service和Endpoints等的变化,结合Ingress配置的规则动态更新负载均衡器的路由配置。
(2)Istio服务的访问入口
如图所示,在Istio中通过Gateway访问网格内的服务。这个Gateway和其他网格内的Sidecar一样,也是一个Envoy,从Istio的控制面接收配置,统一执行配置的规则。Gateway一般被发布为Loadbalancer类型的Service,接收外部访问,执行治理、TLS终止等管理逻辑,并将请求转发给内部的服务。
网格入口的配置通过定义一个Gateway的资源对象描述,定义将一个外部访问映射到一组内部服务上。在 Istio 0.8版本之前正是使用本节介绍的 Kubernetes的 Ingress来描述服务访问入口的,因为Ingress七层的功能限制,Istio在0.8版本的V1alpha3流量规则中引入了Gateway资源对象,只定义接入点。Gateway只做四层到六层的端口、TLS配置等基本功能,VirtualService则定义七层路由等丰富内容。就这样复用了VirtualService,外部及内部的访问规则都使用VirtualService来描述。
6 外部接入服务治理
在Pilot中创建一个ServiceEntry,配置后端数据库服务的访问信息,在Istio的服务发现
上就会维护这个服务的记录,并对该服务配置规则进行治理,从forecast服务向数据库发起的访问在经过Envoy时就会被拦截并进行治理。
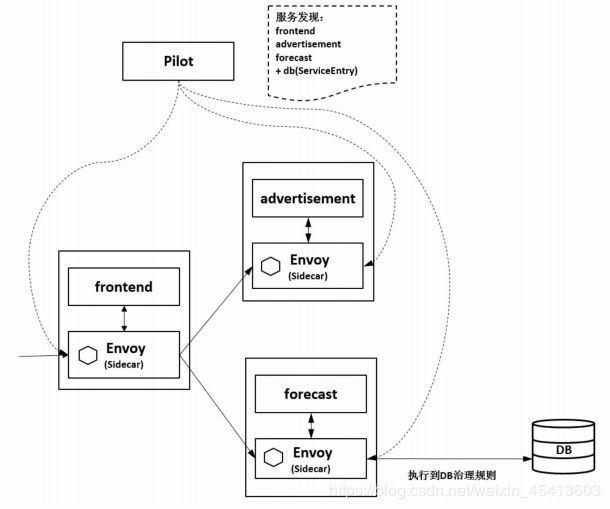
在大多数时候,在访问网格外的服务时,通过网格内服务的 Sidecar 就可以执行治理功能,但有时需要有一个专门的Egress Gateway来支持,如上面的例子所示。出于对安全或者网络规划的考虑,要求网格内所有外发的流量都必须经过这样一组专用节点,需要定义一个Egress Gateway并分配Egress节点,将所有的出口流量都转发到Gateway上进行管理。