直播实录|百度大脑EasyDL·NVIDIA专场 产品介绍及AI端计算技术架构解析
EasyDL—Jetson产品介绍及AI端计算技术架构解析
时间:
2020年5月27日
讲师:
百度AI技术生态部高级产品经理 子季
NVIDIA开发者关系经理 李雨倩
百度AI开发平台部资深研发工程师 陈老师
【直播回放】
EasyDL-NVIDIA Jetson产品介绍及AI端计算技术架构解析:https://www.bilibili.com/video/BV1Zp4y1Q7ub
【课程笔记】
本次课程将会包括EasyDL的最新产品介绍,包括最新推出的EasyData简介、NVIDIA Jetson全系产品及生态应用介绍、EasyEdge端计算技术架构解析。帮助开发者快速了解EasyDL和Jetson系列产品,从技术层面更好地理解EasyEdge。

EasyDL-Jetson系列软硬一体方案目前已全新上架,包括:EasyDL-Jetson Nano软硬一体方案、EasyDL-Jetson TX2软硬一体方案和EasyDL-Jetson AGX Xavier软硬一体方案。这三款方案目前在百度AI市场处于优惠活动中,限量直降,全网最低价,无论你是高校师生、入门级开发者或是企业级开发者,都可以在这三款产品中找到能最好满足你的需求的最优惠的产品!对本系列软硬一体方案感兴趣的小伙伴,可以扫描屏幕下方的二维码进行详细了解。

【EasyDL平台整体介绍、场景、案例介绍】
EasyDL是基于飞桨深度学习平台推出的面向企业打造的零门槛AI开发平台,可为各行业有AI模型开发需求的企业及开发者,提供从数据管理与标注、模型训练、服务部署的全流程支持,模型训练效果好、训练效率高,并且有完善安全的数据服务,支持端、云、软硬一体等多种灵活的部署方式。目前,EasyDL已拥有包括专业版、零售版和经典版在内的三款产品,面向不同人群、不同需求,提供高效进行AI模型开发部署的平台产品。

零算法的人群可以使用EasyDL经典版定制高精度AI模型,如果掌握一定编程经验可以使用EasyDL专业版,可以编程深度开发AI模型。针对零售行业,快消场景也推出了EasyDL零售版,专注解决定制货架巡检商品检测的行业难题。
EasyDL核心技术特性
EasyDL是端到端一站式AI开发平台,预置了飞桨Master模式支持用少量数据训练高精度AI模型,提供智能数据服务EasyData,还有便捷易用的端云结合的部署方案,让企业可以快速集成在自己已有的业务系统中。

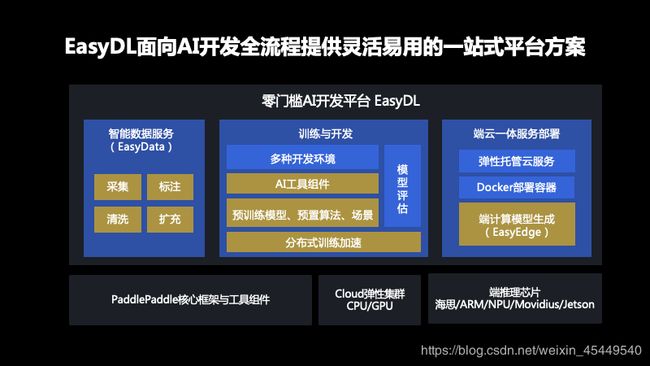
零门槛AI开发平台EasyDL包含了在AI开发过程中三大流程,一个是数据服务,一个是训练与开发流程,一个是模型部署的流程。在数据服务环节目前是由EasyDL全新推出的产品EasyData来承载的,EasyData包含了数据采集、数据清洗、数据标注等丰富的智能服务。在训练和开发环境里,提供了灵活开发环境与多种开发方式,同时也提供了丰富的AI工具组件,同时为了让各类场景和各类企业和开发者在使用EasyDL获得更好的训练效果,也提供了预训练模型的支持,并支持分布式加速。服务部署环节上,提供了稳定支持高并发的API云服务,同时支持EasyEdge离线服务部署的能力。
智能数据服务。大家做AI开发过程中,开发者或者企业用户往往会面临三个核心痛点,第一个是数据采集比较困难,比如视频监控场景,需要尽可能实地部署获取原始监控场景数据,从采集硬件的选择、部署到原始数据的存储与清洗,操作繁琐成本较高。第二个问题是在标注成本上,需要投入大量的人力去标注数据,以求实现更好的模型效果。第三是模型效果的迭代和升级经常是一个长期的过程,在这个过程中就需要反复做数据采集与标注。百度大脑在4月30号正式上线了EasyData智能数据服务,包含了数据采集、管理、清洗、标注、安全等模块,并且在模型训练部署以后,可以通过云服务授权完成数据回流,针对性地做难例挖掘,让数据获得更多有助于模型效果提升的高质量数据。
在EasyData数据采集方案上,目前EasyData在业内首家推出了软硬一体、端云协同的自动数据采集方案,目前通过EasyData 数据采集SDK之后,可以支持定时拍照,视频抽帧等方式,并且实时统计到云端,目前在采集设备上也在百度AI市场推出了推荐选型,数据采集效率从周提升到小时级。采集到的原始数据,像视频抽帧就会存在低质问题,模糊问题,偏差和错误问题。EasyData提供了完善的数据清洗方案,比如支持相似度去重、去模糊、旋转、裁剪、镜像等选项,可以通过各种各样策略快速过滤掉低质量的数据图片。在数据标注方案上,EasyData提供了行业里最全面的智能标注方案,支持物体检测、图像分割、文本分类的智能标注,同时在EasyData提供的智能标注方案中,我们提供了行业首发的Hard Sample主动学习挖掘的算法,通过人机交互的策略,完成高效的智能标注,我们也测评了目前在线上使用智能标注的几个经典案例,整体的数据标注量平均可以减少70%,这个流程大家都可以在EasyData平台上体验。像中科立业智能云秤就是基于EasyData快速处理和清洗,实现更高质量数据的清洗并借助EasyDL完成模型的训练与部署上线。


数据问题解决好以后,在训练与开发环节,EasyDL也做了大量的工作。首先EasyDL内置了丰富的训练机制,EasyDL是基于飞桨深度学习平台构建而成,在此基础上,采用了Transfer Learning迁移学习的技术,采用AutoDL自动搜索最优网络及超参数,以及自动超参调优和分布式训练加速等丰富的训练机制。可能有些开发者之前会问到,使用EasyDL使用同样的数据训练,在模型效果上比自己在本地训练效果更好,这个主要是归功于EasyDL预置了飞桨Master模式。飞桨Master是一个更深度轻便的开发模式,开放了集成百度自有大规模数据和支持产业级的预训练模型,再结合迁移学习的工具,就能获得更高精度的训练效果,目前EasyDL专业版预置了ERNIE 2.0模型,在CV方向接入了百度超大规模的视觉预训练模型,整体的平均精度在线下测算中提升了**2%到26%**的效果,这也可以在EasyDL的专业版上率先体验。

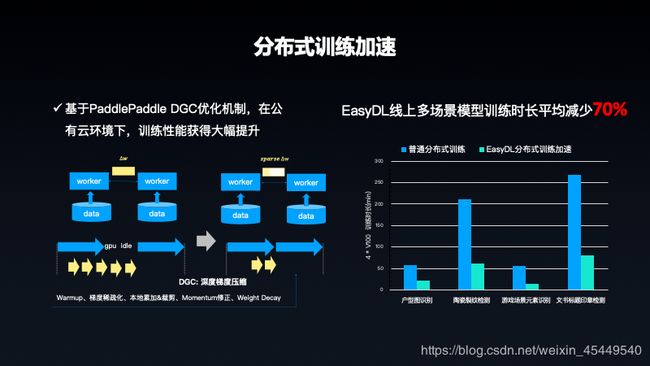
关于自动数据增强与自动超参搜索,通过增加数据数量和多样性能够提升模型的效果和能力,线下我们去采集大规模的数据不是简单的事情,所以自动数据增强可以解决这个问题。目前CV方向平台开放了超过40种算子可以进行灵活配置,准确度的提升非常明显。自动超强搜索也是EasyDL创新基于随机微分方程的调优的算法,同时支持大规模并行搜索调参,对比人工调参,效率更高,耗费人力更少。目前也统计了线上多场景的平均精度,可以提升10%以上。分布式训练机制上,EasyDL基于Paddle Fleet分布式训练API及内建的DGC优化机制,训练时长平均减少70%,大幅提升训练效率。瀚才猎头借助EasyDL智能标注和预训练模型ERNIE,整体达到了95%以上的效率,整体效率提升了200倍。

最后讲到模型部署流程中,目前EasyDL支持了公有云API,本地服务器部署,设备端SDK,软硬一体产品。其中在公有云API支持高可用云服务,本地服务器部署支持一键打包,终身授权,设备端SDK适配最广泛, 包括15+芯片类型;软硬一体产品上,支持6款方案,并有专项的适配方案。

同时在EasyDL软硬一体产品矩阵方案中,提供了六款软硬一体方案,覆盖超高性能,高性能和低成本小功耗三种不同形态,在本次与NVIDIA Jetson合作的方案中,本次推出三款不同性价比的软硬一体产品产品,我们也做了相关性能评测,在常见网络模型中,大家可以看到整体的耗时还是很短的,包括Xavier上最快的时延降低到4毫秒,在高性价比的Nano也能跑到20到33毫秒。


在端能力上,偲睿科技基于EasyDL的端能力实现公共空间能效的智能管理的系统,自动的识别办公室的人数统计,窗帘是否开关这样的场景,结合飞桨Master模式整体识别率达到了91%,结合EasyEdge服务设备端集成效率提升了20倍。目前已经在工业、农业、交通和政务上实现快速落地,使用EasyDL解决了企业在实际落地应用中遇到的难题。
【NVIDIA Jetson全系产品及生态应用介绍】
NVIDIA是一个全球领先的人工智能平台公司,打造面向AI落地的产品,从图中可以看到NVIDIA打造的不同形态的硬件产品,它是根据不同的大小以及不同功率,针对客户,面向各种各样应用的案例,使我们能够快速部署AI算法。从学习到企业部署,一开始的训练到后面真正的落地,到嵌入式或者汽车上的这些产品,NVIDIA全部都覆盖了。在软件方面,从训练到推理,从数据中心到边缘,我们提供了全套完整的解决方案,其实这些最终的解决方案,我们都可以看到是依赖我们统一的一套底层软件架构——CUDA。

所有小伙伴们应该都遇到过一个难题,开发时最大的痛点和成本,就是算法的迁徙,比如一开始在工作站上做的一些算法或者产品,你可能会使用到Windows或者Linux操作系统,接下来你在做嵌入式开发时候会用到单片机或者ARM芯片,这时候可能会用到安卓系统,两边软件开发起来完全不一样。我接下来的介绍大家可以看到,从NVIDIA的角度,我们希望打造一层软件的隔离层,这对所有开发者来讲,未来开发销量的产品,在不同的产品和平台上就可以进行非常平顺的迁徙。
这一页我们看一下在Jetson整个软件架构。在上面有一套操作系统BSP,可向上支撑所有加速的模块,这些加速模块包括最下面的CUDA加速库以及上层的CUDNN都有,我们有这么完善的加速库,是面向不同需求的开发者。比如你是比较资深的开发者,可以直接用CUDA对硬件进行操作;如果你是研究者,可能不太关心硬件底层到底是什么样,你就可以直接用TensorRT,把你的模型喂给它,在GPU上可以快速跑出很好的效果。时间会大大缩短开发的时间,比如上午训练了一个模型,中午就可以放到嵌入式Jetson平台上,再放到机器人或者车上,再看一下实际的物体检测情况到底是怎么样的。

Jetson的产品到现在已经有好几年的时间了,应用领域非常广泛,我们是第一款具有AI功能的嵌入式系统,而且从整个生态领域来讲,第一它非常方便的做算法的验证,第二就是算法迁徙成本非常非常低,这个对于人工智能来讲,有各种各样不同的应用场景,你会发现所有的想法和算法完全是不一样的,从一开始比如说你开发阶段,你算法和模型可能非常复杂或者非常庞大,但随着产品应用和部署,这些算法往往变得更复杂或者简单化一些,或者是组合上都会发生一些变化,Jetson在这一点上也有一个非常重要的特性,当你的设备和产品部署出去以后,你可以非常轻松进行升级和迭代,这样就可以帮助你在未来很长时间里应用客户不同的想法或者一些新的需求,或者希望你的算法怎么改及适应一些新的想法和市场的需求。我们从图中可以看到,在AI落地的先行者都在用我们的产品,像机器人里的FANUC ABB,建筑里的小松建筑机械,其次在农业,包括零售、物流、交通以及智慧城市里都有相应的应用实例。
到现在为止Jetson成员有以下这些,TX2有1.33T算力,Xavier发布三年时间,它是非常高算力的,可达到32T INT8,尺寸也比较大,一般我们会认为它是全功能的小车或者是低速机器人的解决方案,最左边是我们的Jetson Nano,它的算力比较小,0.5T,尺寸也特别小,适用于入门级开发者或高校老师做开发用的,企业级的开发者,在实际业务场景中实现离线预测,更推荐使用Jetson TX2或Jetson Xavier,现在EasyDL-Jetson的软硬一体方案,中Jetson的硬件产品与EasyDL定制模型深度适配,在实现定制AI离线计算上非常容易。

对于所有的硬件平台,NVIDIA有统一的支持,统一版本的JetPack支持我们上面看到的不同产品。如果你在开发一款应用或者算法的时候,初期应用的是Xavier,到后期你发现可以支持同样的路数或功能可以放到TX2或者Nano上,你只要重新编译到不同的硬件,你的算法本身和应用程序是不需要做任何代码级改动,可以进行非常完整平顺应用的迁徙。

接下来可以看一下最新上市,5月14号刚上市的Jetson Xavier NX,这个版本性能非常强,有21T,尺寸也非常小,接下来我会跟大家继续介绍一下这个NX的产品性能。

下面我给大家介绍一下,在5月14号上市的Jetson Xavier NX,这款产品的第一个特性就是非常非常的小,大概跟我们的名片尺寸差不多,但其实它的算力很强,有21T的算力,功耗也降了很多,有10W和15W的模式。Xavier是30W的模式,NX在功耗方面下降了很多,但是算力还是有非常不错的表现。这是我们Xavier NX 10W和15W具体的对比,主要是软件层面的差异,10W是一个比较低功耗的情况下,还有比较高的性能输出。15W就是给大家一个全功能的输出,主要的区别是在主频的差异上,10W主频低一些,不管是GPU还是CPU主频都会低一些,这些信息在官网上都有。其次我们可以看到,NX上可以做到14路1080P30帧的编码,也可以做32路1080P的解码,这是两个不同硬件的加速器,所以可以一边做解码,一边编码,因为它有自己独立的buffer和独立的运算资源,大家随后感兴趣的话可以进行进一步的验证。NX也支持非常多的显示输出,包括HDMI等,同时支持3路不同的输出,2路不同的显示,可以满足大家不同的硬件需求的接入。
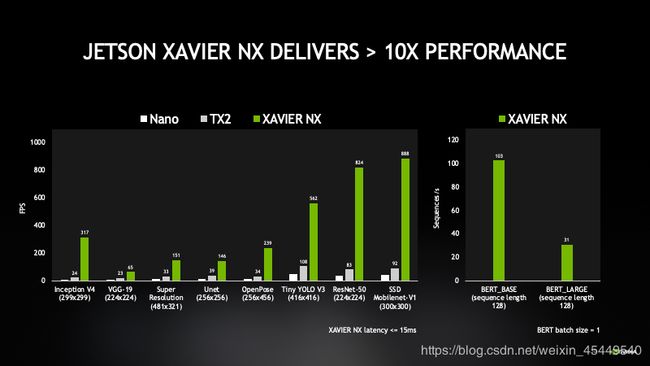
这一页可以看到Nano、TX2和Nano,图中各个模型性能指标也可以作为开发者的参考。
下面我们讲一下Jetson平台在边缘端的应用,提到大数据计算或者云计算或者边缘端的词汇,首先想到就是数据中心或者云,另外就是边缘端的设备,我们可以把它想到是sensor汇总,可以把不同传感器信息汇聚,传输到云里进行分析,再做各种各样的决策和下发指令发送到边缘端。比如常见的例子,大家经常骑的共享单车就是这样的用例,当你扫码的时候,车辆的ID信息和支付的信息都会上传到云端,计算完以后根据你上传的信息下发指令到车,这样就完成一个完整的计算环节和交付环节。前几年我们在边缘端做的事情比较少,主要原因是因为边缘端的设备在前几年成本比较低,算力也比较低,所做的事情比较受限。但是随着人工智能来了以后,你会发现如果你还用刚才这种方式,你的时延是无法完全保障的。比如在工厂里,你在机器人上看到了一个箱子,是流水线上的残次品,你想搬出来,如果按照传统的模型思路,你会发现延时是很长的,也是无法保障的,而且在一些应用的地方,可能完全没有网络或者网络的带宽也是完全受限的。还有一些应用场景,像工厂医院,希望有一些信息不上报,存在本地,这时候会造成比较大的困难,所以这两年盘的比较多的就是边缘端的计算部署。
Jetson整个平台其实是做了一个多种传感器汇聚的功能,它可以看成一个本地化部署的节点,之前介绍到Jetson各种算力产品可以应对大家不同需求的场景需求,比如举个例子Nano 0.5T算力,可以放到咖啡馆或者图书馆进行人员统计,它还有多余的算力,可以做一些附加的功能。比方说Xavier可以放到工厂或车间里做安全帽检测,工作流程检测,放火防盗路径规划等等。还有一些合作伙伴会做一些边缘计算,像联想做一些边缘计算盒子,带WIFI和5G模块,可以在工厂里部署,对相机和传感器做分析。
介绍了这么多,下面给大家看一个视频的DEMO。这就是我们的云原生技术,也就是CLOUD NATIVE在Jetson平台上的DEMO,可以看到,这里面所有的应用都是在Jetson本地上运行的,这个DEMO里包括了四个容器,这四个容器里分别跑了四个独立的应用,容器的好处就是每一个应用可以独立的开发部署和优化。NVIDIA提供了非常好的Container base的解决方案,也就是我们的NGC,感兴趣同学可以到我们的官网上看一下,这部分也是完全开源的。这四个DEMO里一共跑了并且加速了七个神经网络,每个应用可以满足单独机器人的需求。比如左上角这款应用,就是一个People Detection,检测人流量,右边是Natural Language Processing,可以做非常好的人机互动的交互。左下角是Pose Detection,从这个DEMO里可以看到,对整体视频流的处理是非常非常流畅的。右下角是我们的Gaze Detection,也就是眼球检测,这里一共用到了三个模型,首先定位人脸,然后定位你的眼睛,然后定位你看向哪里,这都是人机交互里非常重要的应用。

最后我介绍一下Jetson平台整个生态圈,可以看到我们分为三个部分,首先是供应商,接下来是软件的合作伙伴,还有一些硬件和传感器的合作伙伴。从我们的角度来看,打造一款合适的产品很重要,但是合作伙伴也很重要,我觉得没有任何一家公司可以把一个产品里所有的元器件都制造出来,更何况是在嵌入式的场景里,我们要求非常多,方向也不确定的情况下,合作伙伴更重要,也保障给开发者提供最完备的软硬件的开发环境。
【EasyDL-EasyEdgeAI端计算技术架构解析】
首先EasyDL和EasyEdge在AI端计算上做了什么工作呢?无论你是在EasyDL还是直接使用框架训练好了模型,在模型部署阶段你需要解决很多问题,一个问题就是你使用的深度学习的框架如何在端上进行Infer的过程,你应该选择什么样的硬件,以及在硬件上如何最大化芯片的能力,都是技术上的难点。EasyEdge就是帮大家解决这些问题的。使用EasyEdge可以减少90%的开发时间,配套使用EasyDL-EasyEdge的端计算组件,模型推理速度最高提升10倍以上。我们只需要3步,最快2分钟就可以生成端计算服务,满足大家的需求。
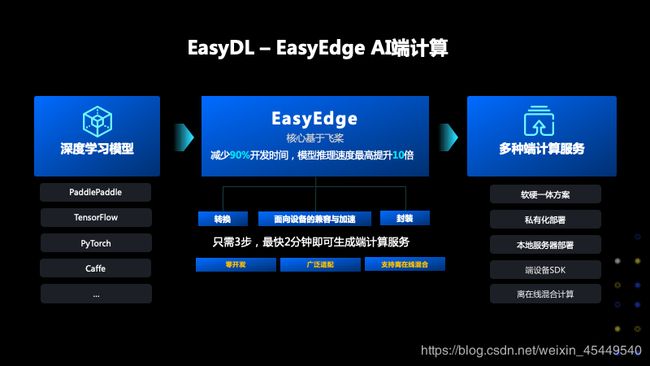
首先我们看看EasyDL、EasyEdge在端计算都支持哪些框架和网络,我们原生支持PaddlePaddle飞桨,其他的像Tensorflow、Pytorch,Caffe,我们通过转换为飞桨模型的办法来支持,另外即将支持mxnet,onnx。右边是我们支持的网络情况,首先我们是支持自定义网络的,主要是分类和检测两个类型。而经典的网络中,从原始的Alexnet、VGG,到现在用的比较多的SSD和YOLO我们都支持,我们会把学术界最新的网络逐渐加入到我们支持的列表中,我这里列出了RetinaNet以及MaskRCNN分割的网络,都在我们即将发布支持。
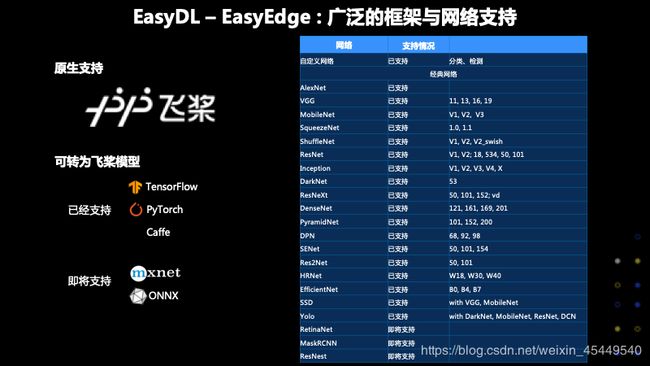
EasyEdge除了有广泛的框架和网络支持,还有非常广泛的软硬件的支持,支持十类芯片和四大操作系统,安卓、iOS,Linux和Windows,对于芯片,我们支持CPU类别的ARM和Intel x86平台。对于本次的主题GPU,Edge能够很好地支持NVIDIA GPU相关的平台,比如说在x86的大卡和以及Jetson系列的小卡,包括Nano和Xavier。除此之外我们还支持各种各样的ASIC芯片,比如像华为海思的NPU平台,华为去年发布的面向高性能服务端的场景的昇腾系列,此外还有Intel的VPU,包括Intel的神经计算帮的一代和二代,以及百度自研EdgeBoard VMX,具体我就不一一念了。这里我需要说一下,后面也支持百度自研的昆仑芯片,以及瑞芯微的RK NPU芯片,包括1808,以及1806,这些都可以通过EasyDL-EasyEdge进行使用。

刚说了这么多EasyEdge和EasyDL的支持情况,我们看一看,EasyEdge到底做了哪些工作,才将所有的框架网络以及芯片支持起来。这是EasyEdge的整体架构,我们看一下,首先有一个EasyEdgeWeb和EasyEdgeAPI,大家使用的EasyDL和EasyEdge的控制台的业务端就在这里。中间是一些负责优化的模块,包括基于图的优化,里面会做一些多步骤的模型转换,还有基于Layer的优化,还有定点量化,模型剪枝等等。而芯片相关的优化,我们会针对不同的芯片选择不同的优化方法,其中会包括一些Kernel选择、内存优化等等。
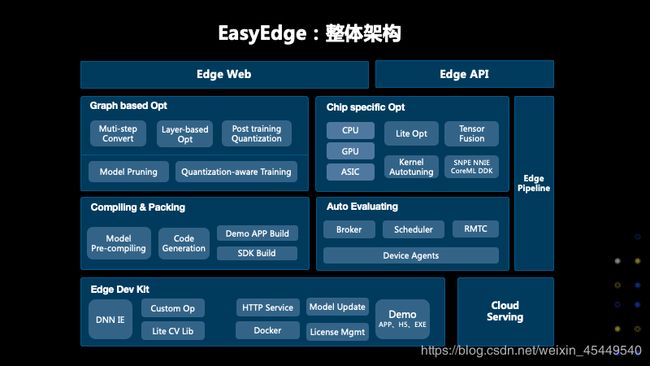
除了图和芯片相关优化,我们会做一些打包和编译工作,大家如果在EasyDL或者EasyEdge平台部署模型的时候,这边会生成二维码,扫一下二维码就可以下载一个App看到模型的效果,这个模型就是在这里通过编译和打包生成的,这里还有一些模型预编译的工作,有一些模型如coreml为了最大化运行速度,在端上有一个编译的过程,我们把这个预编译的工作放到云端,大家在使用的时候就可以快速运行这个模型了。最后还有一个评估模块,拿到用户模型以后,我们加速优化完成之后,会下发到不同的设备上,通过不同的Agent很快得到模型在不同设备上的精度和速度,而整个流程都是自动完成的。
最底层就是大家使用EasyEdge开发者套件里包含的内容,里面会有高效的深度学习Infer运行时,里面包括一些轻量版的CV库等。同时,套件里还包含了模型的升级、管理和各种各样DEMO的应用。此外,我们还提供了一个云端Serving模块,你的模型会同时生成一个API服务,方便大家进行离在线混合调用。
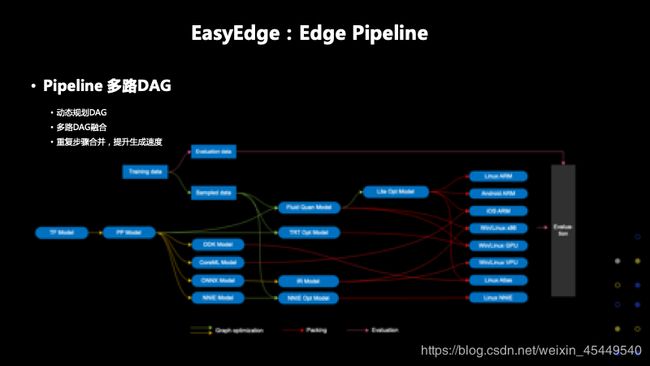
看了整体的架构,大家可以发现,整个过程步骤非常多,模型优化、芯片芯片、打包和编译,评估和serving,整个流程像DAG一样。我们通过pipeline的技术,动态规划DAG,把多路DAG融合,将重复的步骤合并,提升生成速度。这就是为什么,只需几分钟就可以生成最终模型的重要原因。
接下来看看EasyEdge到底在模型和芯片上给大家做了哪些具体优化。定点量化,了解深度学习的同学应该陌生,随着深度学习的发展,为了提升精度,模型变得越来越大,常见的ResNe50t以及精度比较好的SE-ResNet,152层的,参数量有255MB,对芯片来说需要的计算非常多。而大多数芯片的特性,相比fp32,是能够在更短的时钟周期内完成对int8的计算的,所以如果能将操作量化,就可以大大提升模型的计算速度,以及降低模型的大小。很多DNN模型,有大量的计算步骤是在卷积等常见算子上,所以EasyEdge会对部分算子做一个量化的优化。我们使用了混合量化,这里有一个图,是以常见的二维卷积为例,比如输入是一个fp32的数据,插入量化算子,卷积之后,再插入反量化的算子,输出还是fp32的数据。这样就可以提升运行的速度,减少模型大小。

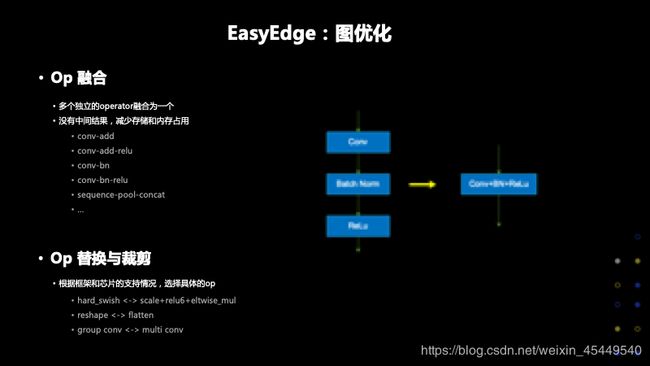
除了常见的定点量化,EasyEdge做了很多其他的优化,比如Op融合的技术,将多个独立的operator融合为一个,没有中间结果,减少存储和内存占用。比如包括卷积和add,还有卷积和bn等等,对于符合一定规则的Op都会做融合操作。我们还会做Op替换和裁剪工作,会根据具体的框架和芯片的支持情况选择具体的Op,比如有一些芯片不支持relu6,我们可以替换成支持relu,比如hard_swish这样激活函数,如果不支持,我们会展开为scale+relu+eltwise_mul的操作,从数学逻辑上讲达到的效果是类似的。比如组卷积不支持,我们还可以进行卷积的展开,reshape不支持,可以想办法去掉或者替换为flatten等等等等。
除了在图上做了优化,EasyEdge还在端上针对芯片做了优化,包括这次的主题NVIDIA GPU,EasyEdge在上面做了深度的优化。一个图片在使用EasyEdge组件进行推理的过程中,是端到端使用GPU的,就是说图片从预处理到推理到部分后处理,整个过程都是在NVIDIA GPU上运行的。这里列出了一个深度学习模型的常见的预处理的操作,包括resize操作,减均值,scale的操作,都会在GPU上运行,从而减少图片在GPU和内存来回搬运的过程,减少消耗。对于特殊的算子,通过子图或者自定义算子方法实现。另外在ARM,我们也有很多优化方法,比如支持NEON优化。右边列出了一个加和计算的代码,简单的翻译成汇编指令,可以达到性能提升三分之一的效果,如果根据具体的CPU情况,将流水线进行重排,性能可以提升一倍甚至以上的效果。对于其他ASIC,我们会利用子图或者一些native的框架看来加速,如CoreML、SNPE等等。此外,在内存上也会有一些优化工作,如在ARM上,程序会分析整个图使用的变量以及生命周期,计算整个内存的分配表,对没有Overlap的内存进行复用,整个计算过程就可以不需要的内存申请和释放,最大化提升模型运行的速度。

经过前面这么多优化以后,我们可以拿到一个优化好的模型和相关SDK。SDK提供了统一完善的基础接口,方便进行二次开发。在这个SDK基础之上,我们还提供了很多Demo。比如对于手机,有一个二维码,在手机上扫一下就可以拿到,如果在PC上,我们会提供HTPP服务,大家把网页打开就可以看到效果,在Windows上还可以提供一个exe程序,双击可以打开,很方便的看到效果,后面有其他老师会给大家具体做演示。右边有一个表,显示了一个模型,经过这么多优化以后,在不同芯片上运行的效果,我这里重点提一下本次的重点NVIDIAGPU,在P4卡上推理速度可以达到3毫秒,在Xavier上也是10毫秒以内,如果讲batch提升,平均单张图的识别速度可以在1毫秒以内,这个速度是相当之快了,可以满足绝大多数实际生产的需求。在其他芯片上包括在Intel或者华为芯片的速度这里我不展开了,如果有兴趣可以在官网上看看具体的情况。

【Q&A】
Q:如何配置JetsonNano。
A:Jetson所有的硬件产品都是需要自己进行刷机的,大家在我们的官网上注册以后,下载NVIDIA的SDK Manager,用这个NVIDIA SDK Manager对你所使用的Jetson的产品进行JetPack的刷机,现在最新支持到JetPack 4.4,建议大家用最新版本进行刷机,进行整体环境的配置。
Q:TX2是需要自己配环境吗?
A:Nano和TX2和Xavier和XavierNX按照这个步骤都可以刷机。
在官网上可以搜NVIDIA SDK Manager,就是经理这样一个软件,不管用Nano还是TX2还是Xavier,选择自己的目标直接刷机就可以了,官网上也有非常详细的步骤。如果刷机过程中也可以问一下。
Q:训练模型是在云端吗,端云一体是怎么做到的,能看到代码还是黑盒子?
A:我解答第一个问题,我们的训练过程目前是在云端的,也就是说你只需要把数据上传在云端平台,可以使用云端开发环境和开发工具进行开发。端云一体呢,指的是我们在接下来的产品规划上,我们即将上线端云协同的管理方式,现在我们做离线部署的时候,我们往往需要在云端把模型下载下来再到端上把模型完成安装和集成,同时本身模型面临高频迭代的场景,特别是当端的量比较高的时候,模型部署的流程变得非常烦琐,端云协同的方案就可以支持在云端直接下发模型,并且在联网状态下在云端监控模型在端上的运行的情况,可以更方便快捷完成模型的迭代更新和状态监控的过程。
Q:飞桨模型是用Python还是C++?
A:这个都是有的。
Q:DEMO中怎么定位眼球看到哪个方向?
A:那个DEMO呢,眼球目光追踪用到了三个模型,第一个是先定位到人脸,然后再定位到你的眼睛,下一步最后个模型定位你看向哪里,这三个模型输入的数据肯定是不一样的,所以最后这三个模型才能统一的结合到一起,才能做出你看向哪里的动作,所以这不是一个模型完成的。
Q:TX2可以用工业相机吗,指的是网络接口的相机?
A:TX2开发者套件是不支持工业相机,刚才我也把所有的Jetson产品支持的硬件和接口,传感器接口也发到了群里,如果其他同学有问题,比如除了TX2,其他Jetson产品的疑问,想看看自己的传感器是否支持,可以直接到官网上,所有产品的硬件接口信息都有非常详细的说明。其次,如果对于工业相机有需求,我们会有一些合作伙伴,可以针对Jetson的产品定制一些盒子,来满足大家在其他场景下的应用。后续如果感兴趣,也可以联系NVIDIA这边,可以一起看看怎么帮你解决这个方案。
Q:计算量指的是什么,是一次处理的次数吗?
A:也可以认为是一次图片输入进来到输入完成总共进行了多少次计算,如何度量有不同的方法。
Q:飞桨模型比TensorFlow Pytorch速度提升了多少,有没有具体的案例?
A:提升速度要看不同的情况,目前整个飞桨深度学习平台在端上的运行是非常广,我刚才提到很多种硬件,如果某个模型提升多少比例,还要看你的网络和硬件的情况,也不好一概而论。总的来说,比没有端上加速的处理快很多。
Q:量化以后如何进行程序呢?
A:量化过程如果使用EasyDL、EasyEdge用户是不可见拿到都是帮大家优化好的模型,不需要再进行重新训练。
Q:EasyEdge现在是免费吗?
A:现在EasyEdge有一个独立的平台,可以支持输入非PaddlePaddle网络模型进行端计算的转化和适配,常见的模型都可以,这个独立的平台是免费的。EasyEdge本身的子模块是直接集成在EasyDL里的,EasyDL是一站式的端到端开发平台,目前是限量免费的原则,对设备端和服务端我们都有一个月的免费试用的有效期,如果长期使用需要付费,付费的价格可以在官网上看到,大家可以在官网了解EasyDL部署模型的价格。
Q:自己生成的模型,能申请自己的专利吗?
A:现在EasyDL有经典版和专业版两种开发的环境和机制,我也看到了有开发者也在直播间咨询,经典版和专业版有什么区别,这里解释一下。经典版它是一个黑盒式的开发,我们把大量复杂模型设计和网络选型都在后端集成,用户在前端感知不到。对于经典版训练的开发方式上,专利上可能不太合适,因为有一些算法上用户是不可感知的。
在专业版上目前支持Notebook,脚本调参两种方式,Notebook上个月刚上线的灵活性比较强的开发环境,可以支持大家直接只用自己设计的网络模型借用这个算力完成模型开发,这个是大家自己开发和设计的网络申请专利为主。
Q:EasyDL模型都能部署到Jetson吗?
A:目前EasyDL支持部署在Jetson上的主要是图像分类和物体检测的模型,可以在使用图像分类和物体检测之后的模型可以发布为Jetson的SDK。
A:对的,绝大多数EasyDL专业版和普遍版分类和检测模型可以发布在Jetson平台上。
Q:本次推广的EasyDL和Nano的授权是永久的吗?
A:是永久的。
Q:Jetson在车载上用的多吗?
A:用的还是比较多的,刚才我一开始介绍,在各个行业领域应用非常多,我们的嵌入式的解决方案就是面向量产的AI产品,所以在很多地方都有应用,有一些成功的用例或者开发者社区,大家做的比较有意思的,基于Jetson的项目,在整个官网上都有一些开源的资源,感兴趣可以上去看一下。如果大家对Jetson各种案例感兴趣,可以在NVIDIA官网上进行查看。
Q:有同学问TX2可以使用CCD的工业相机吗?
A:TX2上应该是可以使用的。
Q:有同学问Nano是带了Python2.7版本的语言吗?
A:Nano的环境不是本身自带的,而是根据自身的环境,像C++和Python都是支持的。
Q:TX2和Nano的计算能力实质相差多少?
A:这个和网络模型有关系,不同网络模型的差异性能不是线性比例,这一部分在我们官网的Deepstream的SDK下面有一些应用实例,在网络平台上有跑相同网络的性能的表,这个是给开发者做benchmark用的,比如你用到这个网络,性能参数远远低于这个,你可以回看一下这个模型是否有一些需要优化的地方,建议大家都可以到NVIDIA的官网上看一下。
Q:有同学问飞桨的环境如何配置到Jetson上?
A:如何配置可能一句话说不完,具体可以去飞桨官网上看一下,有相关的DEMO和教程。
Q:EasyDL的SDK经典版和专业版有什么区别?
A:如果是SDK的话,在使用上区别不大,后台有一些模型上有一些不一样。
Q:有同学问Nano的专用芯片有单独卖吗?
A:这个后续需要我确认一下,到时候我在群里跟大家说。
Q:EasyDL模型如何部署在TX2上?
A:在TX2以及Nano部署都是类似的,明天我们也会有老师给大家演示,如何从训练到部署的整个流程,可以关注一下。
如果大家对EasyDL的模型如何部署到Jetson的各类硬件上感兴趣,可以关注一下我们的直播,为大家演示如何部署,一步一步带大家操作,可以看到哪一步的问题,还可以看到自己需要注意什么。
A:关于特定场景的案例,我解答一下EasyDL这边,如果大家对EasyDL案例比较感兴趣,可以到EasyDL的官网上,通过banner-经典案例回放,可以看到EasyDL在各行各业成功落地的案例,如果是Jetson这边,经典案例在Jetson的开发者社区都可以找到,可以找到NVIDIA的官网,点进去点到开发者的社区里,接下来选择硬件的平台,就可以看到所有的资源。
Q:好的。有同学问Jetson支持PaddleLite吗?
A:也是支持的,我刚才提到了EasyDL的端计算组件中封装了PaddleLite的功能,如果大家想直接使用PaddleLite跑自己的模型,也可以到官网看一下相关的文档,有相关的介绍。
Q:有同学问EasyDL训练后的模型能够导出吗?
A:现在EasyDL经典版的模型和专业版的脚本调参开发模型是不支持,如果使用专业版Notebook里的模型可以下载导出的
Q:视觉模型怎么部署,如果是部署的问题,明天可以看我们的直播。有同学问如何更新边缘的端模型,边缘设备比较多怎么办?
A:当边缘设备比较多的情况下,也是刚才提到的端云协同的解决方案,端云设备比较多的方案我们支持云端支持模型,一键下发,可以让多个端上的模型可以自动更新。
Q:有同学问VMX和Nano对比,Nano有什么优势?
A:我觉得这个例子不太好一句话来说,这是根据实体的应用强相关的,所以这一部分要看到您这边的应用实例是怎么样的,比如对CPU和GPU整体的算力和占比的考量,这个要根据案例分析。
A:想补充一下VMX是加速卡,它是需要宿主机,可能和JetsonNano功能上有一些区别。
A:对,Nano可以直接作为单独计算载体。
Q:如果大家想了解VMX,可以搜索一下,对比一下Nano,到底是需要哪个,可以在业务中发挥作用。有人问EasyDL支持多视频流吗?
A:目前EasyDLSDK职工的API只有单图,但是多视频流也会在后续SDK推出,第三节课会有老师讲到EasyDL和Deepstream结合,是视频流的一个例子。
目前,EasyDL与NVIDIA的Jetson系列合作推出的软硬一体方案已经强势上架百度AI市场,并处于限量优惠,全网最低价的活动中,目前已经推出EasyDL-Jetson Nano软硬一体方案、EasyDL-Jetson TX2软硬一体方案和EasyDL-Jetson Xavier软硬一体方案。覆盖了高校师生、入门级开发者、企业级开发者的需求。Jetson的三款硬件与EasyDL的定制模型深度适配,可以帮助你轻松实现定制AI离线计算。


在下周的课程中,来到了百度AI快车道-EasyDL产业应用系列:领域信息处理专场。在6月2日-6月3日,内容覆盖CV与NLP,会有来自百度的高级产品经理、来自武汉大学的外科博士现身直播间,为大家从技术解析到实战应用,深度解析AI产业应用的痛点难点!
想要快速提升自己,转型AI应用专家的小伙伴,一定不要错过哦!下周课程海报:
