ERNIE时延降低81.3%,飞桨原生推理库Paddle Inference再升级

随着深度学习技术的成熟和人工智能的发展,机器开始变得越来越“聪明”,越来越了解用户的喜好和习惯。
近年来对于NLP的研究也在日新月异的变化,有趣的任务和算法更是层出不穷,百度提出知识增强的语义表示模型 ERNIE就是其中的佼佼者。ERNIE在语言推断、语义相似度、命名实体识别、情感分析、问答匹配等各类NLP中文任务上的模型效果全面超越 Bert,成为NLP中文任务中的主流模型,ERNIE 2.0的论文(https://arxiv.org/abs/1907.12412)也被国际人工智能顶级学术会议AAAI-2020收录。
然而在模型效果大幅度提升的同时,模型的计算复杂性也大大增加,这使得ERNIE在推理部署时出现延时高,推理速度不理想的情况,给产业实践带来了极大的挑战。

飞桨开源框架1.8版本中,Paddle Inference在算子融合、TensorRT子图集成和半精度浮点数(Float 16)加速三个方面对ERNIE模型推理进行了全方位优化。
实验表明,在batch=32, layers=12, head_num=12, size_per_head=64的配置下,英伟达T4 ERNIE运行延时从224ms降至41.90ms,时延降低81.3%;在其他配置不变,batch=1的情况下,时延缩减到 2.72ms。进一步在Bert模型上的扩展实验表明,同样条件下,1.8版本相对Tensortflow也具备明显的推理性能优势。
新来的小伙伴可能会疑惑,啥是Paddle Inference?
Paddle Inference是飞桨深度学习框架的推理引擎,通过对不同平台服务器应用场景的深度适配优化,降低时延,提升部署效率,详情请参考:https://mp.weixin.qq.com/s/DX2pM2H2Nq9MCg2eU4sV7g

ERNIE时延降低81.3%,Paddle Inference如何做到?
提升点一:算子融合优化,在减少模型计算量和调用次数的同时,降低访存开销。
Paddle Inference加载模型后,需要先将模型转换为由算子节点组成的拓扑图,然后再进行模型图分析。在此阶段中,Paddle Inference会根据预先定义的模式对拓扑图进行扫描,如果有子图(由多个节点组成的结构)匹配到某一模式,则会对该子图内的节点进行融合。

接下来我们来看下Paddle Inference中对Ernie模型的算子融合优化。下图是ERNIE模型的网络结构,包括两个部分:模型输入和多个重复的编码结构。
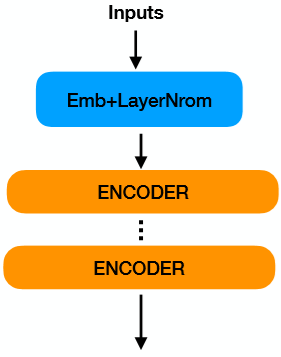
图 ERNIE模型结构示意图
-
模型输入:获取三个输入对应的Embedding,对它们相加并进行了正则化。
-
多个重复的编码结构:每个编码器由self-attention 以及feed-forward操作组成(标准的Ernie模型有12个编码结构)。
对Ernie模型中的算子融合的优化包括模型输入算子融合和编码算子融合。
模型输入算子融合的原理如下图所示:
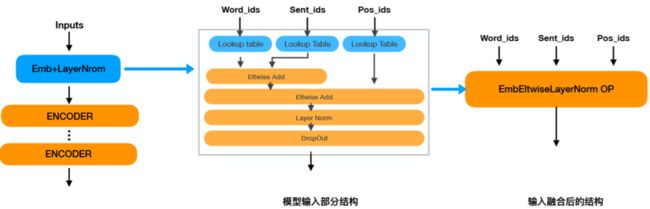
-
模型输入部分结构:ERNIE模型输入部分由7个算子组成。
-
输入融合后的结构:Paddle Inference在图分析阶段对模型输入部分进行算子融合后,输入部分的7个算子融合成了1个EmbEltwiseLayerNorm 算子。
编码部分算子融合的原理如下图所示:
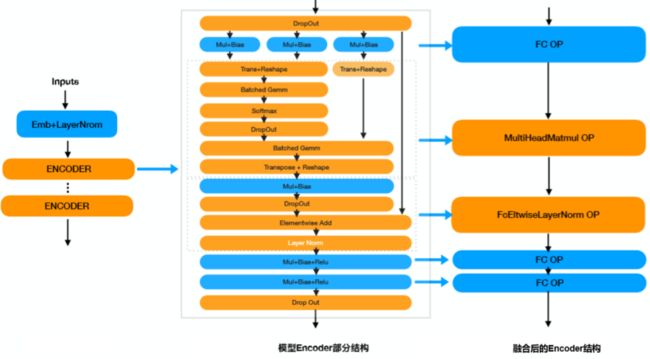
-
模型Encoder部分结构:Ernie的每个模型编码(Encoder)部分由29个算子组成,标准的Ernie总共包含12个编码,由300+个算子组成。
-
融合后的Encoder结构:Paddle Inference将编码部分融合成了由FC、MultiHeadMatmul、FcEltwiseLayerNorm等算子组成的结构。
通过对输入、编码部分进行算子融合,标准的Ernie模型的算子数量从300个以上降到60个左右,给模型推理带来了较大的性能提升,不但减少了模型计算量和计算核(kernel)调用的次数,还大大节省了访存的开销。与此同时,我们对每一个融合的算子针对性的进行了kernel优化,保证了GPU核心高度利用,极大的降低了预测延时。
提升点二:采用TensorRT子图集成,择优自动选择最佳计算内核,提升运算速度
Paddle Inference 采用子图方式集成了TRT,使用一个简单例子展示了这一过程。
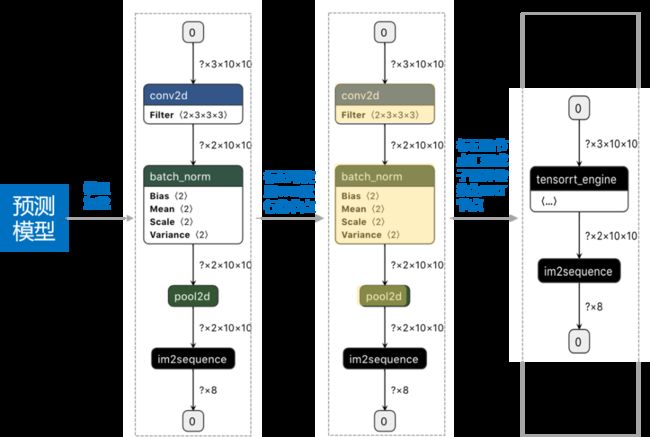
当模型加载后,模型表示为由算子节点组成的拓扑图。如果在运行前指定了TRT子图模式,那在模型图分析阶段,Paddle Inference会找出能够被TRT运行的算子节点,同时将这些互相链接的OP融合成一个子图并用一个TRT 算子代替,运行期间如果遇到TRT 算子,则调用TRT引擎执行。
在Paddle 1.8 版本中,我们对Ernie模型进行了TRT子图的集成,支持动态尺寸的输入功能。预测期间,被TRT 引擎执行的算子会在初始化期间运行所有候选计算内核(kernel),并根据根据输入的尺寸选择出最佳的那一个出来,保证了模型的最佳推理性能。
提升点三:采用半精度浮点数,最大化提升访存和计算效率
Float32对于我们非常熟悉了,那Float16(又称为半精度浮点数)是什么呢?如下图所示,Float16是一种相对较新的浮点类型,在计算机中使用 2 字节(16 位)存储,在 IEEE 754-2008 中,它被称作 binary16。
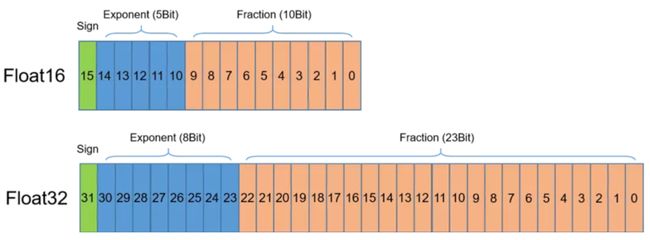
可以看出,Float16的指数位和尾数位的存储单元数目都要少于计算中常用的单精度中的个数,使用 Float16 代替 Float32 来存储数据,不可避免会造成一定的数值精度上的损失。如果将深度学习模型中的参数以及运算从Float32 替换成 Float16,会有什么影响呢?
我们知道,深度学习本身对精度不是太敏感,尤其是在预测场景下,因为不会涉及参数的微调,很多时候采用低精度的存储以及运算对模型的最终结果不会造成太大的影响。使用Paddle Inference上对Ernie模型进行Float 16测试,模型输出数值精度和Float32相比,误差在1e-3~1e-4之间,这样的数值精度损失对模型的准确率几乎无影响,完全可接受。
在深度学习模型预测期间,采用Float16代替Float32,在节省存储空间的同时,还能节省访存的开销,尤其是能够提升预测的性能。特别地,当我们使用Volta 架构的GPU时候,使用Float16可以充分利用Tensor core的性能加速,最大限度的提升访存和计算效率。
实践出真知,让我们动手试试看
讲了这么多Paddle Inference关于ERNIE的优化点,小伙伴们是不是也跃跃欲试了呢?Paddle Inference提供了简单灵活的C++和Python接口,下面我们以Python接口为例,演示一下ERNIE模型推理的具体操作方法,只需要完成如下三个步骤。(小秘密:没有GPU的小伙伴别担心,可以在AI Studio上蹭个算力试试手:))
第一步:环境准备
# 拉取镜像,该镜像预装Paddle 1.8 Python环境,并包含c++的预编译库,lib存放在默认用户目录 ~/ 下。
docker pull hub.baidubce.com/paddlepaddle/paddle:1.8.0-gpu-cuda10.0-cudnn7-trt6
export CUDA_SO="$(\ls /usr/lib64/libcuda* | xargs -I{} echo '-v {}:{}') $(\ls /usr/lib64/libnvidia* | xargs -I{} echo '-v {}:{}')"
export DEVICES=$(\ls /dev/nvidia* | xargs -I{} echo '--device {}:{}')
export NVIDIA_SMI="-v /usr/bin/nvidia-smi:/usr/bin/nvidia-smi"
docker run $CUDA_SO $DEVICES $NVIDIA_SMI --name test_ernie --privileged --security-opt seccomp=unconfined --net=host -v $PWD:/paddle -it hub.baidubce.com/paddlepaddle/paddle:1.8.0-gpu-cuda10.0-cudnn7-trt6 /bin/bash
# 下载Ernie预测模型
wget https://paddle-inference-dist.bj.bcebos.com/inference_demo/Ernie_inference_model.gz
第二步:创建AnalysisPredictor
AnalysisPredictor是Paddle Inference提供的推理引擎,它根据AnalysisConfig配置对象进行构造。因此我们首先要创建AnalysisConfig对象,并设置一些推理引擎参数,这些参数包括模型的路径、设备硬件类型,是否开启显存以及TensorRT子图优化等。
def create_predictor():
# 配置模型路径
config = AnalysisConfig('./ernie/model', ./ernie/params)
config.switch_use_feed_fetch_ops(False)
# 设置开启内存/显存复用
config.enable_memory_optim()
# 设置开启GPU
config.enable_use_gpu(100, 0)
# 设置使用TensorRT子图,关于TensorRT子图的更多信息请访问:
# https://paddle-inference.readthedocs.io/en/latest/optimize/paddle_trt.html
config.enable_tensorrt_engine(workspace_size = 1<<30,
max_batch_size=1, min_subgraph_size=5,
precision_mode=AnalysisConfig.Precision.Half, # 开启FP16
use_static=False, use_calib_mode=False)
head_number = 12
names = ["placeholder_0", "placeholder_1", "placeholder_2", "stack_0.tmp_0"]
min_input_shape = [1, 1, 1]
max_input_shape = [100, 128, 1]
opt_input_shape = [1, 128, 1]
# 设置TensorRT动态shape运行模式,需要提供输入的最小,最大,最优shape
# 最优 shape处于最小最大shape之间,在预测初始化期间,会根据最优shape对OP选择最优的kernel
config.set_trt_dynamic_shape_info(
{names[0]:min_input_shape, names[1]:min_input_shape, names[2]:min_input_shape, names[3] : [1, head_number, 1, 1]},
{names[0]:max_input_shape, names[1]:max_input_shape, names[2]:max_input_shape, names[3] : [100, head_number, 128, 128]},
{names[0]:opt_input_shape, names[1]:opt_input_shape, names[2]:opt_input_shape, names[3] : [args.batch, head_number, 128, 128]});
# 创建predictor
predictor = create_paddle_predictor(config)
return predictor
上述的代码中,我们根据Ernie模型需要的参数配置创建了predictor。
第三步:准备数据输入,运行模型预测,获取模型输出
# 运行预测,其中data表示输入的数据
def run(predictor, data):
# copy data to input tensor
input_names = predictor.get_input_names()
# 将data数据设置到输入tensor中
for i, name in enumerate(input_names):
input_tensor = predictor.get_input_tensor(name)
input_tensor.reshape(data[i].shape)
input_tensor.copy_from_cpu(data[i].copy())
# 运行预测
predictor.zero_copy_run()
results = []
# 获取输出数据
output_names = predictor.get_output_names()
for i, name in enumerate(output_names):
output_tensor = predictor.get_output_tensor(name)
output_data = output_tensor.copy_to_cpu()
results.append(output_data)
return results
pred = create_predictor()
# 使用数值为1的数据进行测试
in1 = np.ones((1, 128, 1)).astype(np.int64)
in2 = np.ones((1, 128, 1)).astype(np.int64)
in3 = np.ones((1, 128, 1)).astype(np.int64)
in4 = np.ones((1, 128, 1)).astype(np.float32)
results = run(pred, [in1, in2, in3, in4])
在这部分里我们使用了全1的数据作为模型的输入进行测试,不到20行代码完成了预测过程,是不是很简单呢?如果您还想了解更多关于Paddle Inference的 API信息和操作指导,请参考文档:
https://paddle-inference.readthedocs.io/en/latest/index.html
为了验证Paddle Inference的升级效果,我们选取了NLP领域中的两个代表模型ERNIE和BERT,在英伟达T4卡上进行了性能测试。
ERNIE测试结果:
在`batch=32, layers=12, head_num=12, size_per_head=64`的配置下, ERNIE模型运行延时从224ms降至41.90ms,时延降低81.3%;在其他配置不变,batch=1的情况下,时延缩减到 2.72ms。(测试期间先预热 100次,然后计算循环预测1000次的平均时间)
BERT测试结果:
同时我们在Bert模型(该模型的预测结构同ERNIE整体上比较接近)下同Tensorflow在T4卡上进行了性能对比(针对每种测试情况我们选取了TF,TF-XLA,TF-TRT FP16中的最佳性能)。从下图中可以看到,在batch和seq_len较小的时候,飞桨的单位时间吞吐量为TensorFlow的2-4倍,即使在batch和seq_len较大时(32, 128),飞桨的性能也比TensorFlow快20%-30%。
- Bert on T4 (layers=12, head_num=12, size_per_head=64)
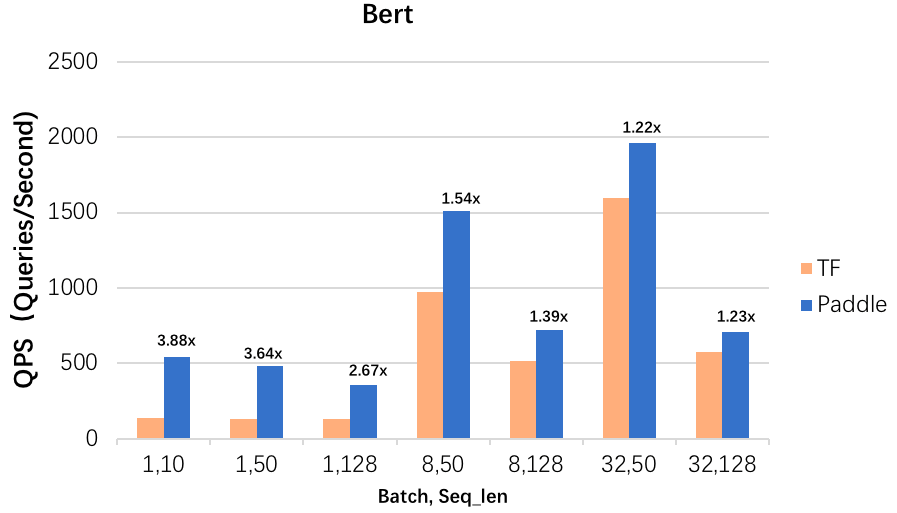
以上就是飞桨1.8版本,Paddle Inference针对ERNIE模型推理效率的提升开发的关键能力。当然,这些技术不仅仅针对ERNIE模型,transformer类的网络结构都会受益,欢迎感兴趣的伙伴试用,如果您还有其他新颖的实践,欢迎随时和飞桨的伙伴联系。
如在使用过程中有问题,可加入飞桨官方QQ群进行交流:703252161。
如果您想详细了解更多飞桨的相关内容,请参阅以下文档。
Paddle Inference demo:
https://github.com/PaddlePaddle/Paddle-Inference-Demo
官网地址:
https://www.paddlepaddle.org.cn
飞桨开源框架项目地址:
GitHub:
https://github.com/PaddlePaddle/Paddle
Gitee:
https://gitee.com/paddlepaddle/Paddle
END
