数据挖掘
数据挖掘
- 一、数据挖掘概念
- 数据挖掘的技术定义
- 数据挖掘的商业定义
- 数据挖掘的系统分类
- 数据挖掘技术
- 数据挖掘的主要方法
- 二、数据预处理
- 数据预处理的形式
- 描述性数据汇总
- 度量数据的中心趋势
- 度量数据的离散程度
- 基本描述数据汇总的图形显示
- 数据清理
- 填充缺失值
- 光滑噪声并识别离群点
- 数据清理作为一个过程
- 数据集成和变换
- 数据集成
- 数据变换
- 数据归约
- 三、关联规则挖掘
- 相关概念
- 关联规则挖掘的过程
- Apriori算法
- 算法过程
- 伪代码
- FP-growth算法
- 四、分类与预测
- 分类
- 有/无指导学习
- 预测
- 准备分类和预测的数据
- 比较分类方法
- 用判定树归纳分类
- 判定树归纳
- 属性选择度量:信息增益
- 树剪枝
- 由判定树提取分类规则
- 对基本判定树归纳的加强
- 判定树归纳的可伸缩性
- 贝叶斯分类
- 贝叶斯定理
- 五、聚类分析
- 聚类分析所处理的数据类型
- 聚类方法
- 划分方法
- k-means方法:用簇中心代表簇
- k-medoids方法:用簇内位于最中心位置的数据对象代表簇
- 层次方法
- 凝聚的层次聚类方法
- 基于密度的方法
- DBSCAN
- 基于网格的方法
- 基于模型的方法
一、数据挖掘概念
数据挖掘–从大量数据中寻找其规律的技术,是统计学、数据库技术和人工智能技术的综合。
数据挖掘是从数据中自动地抽取模式、关联、变化、异常和有意义的结构;
数据挖掘大部分的价值在于利用数据挖掘技术改善预测模型。
数据挖掘的技术定义
数据挖掘(Data Mining)就是从大量的、不完全的、有噪声的、模糊的、随机的实际应用数据中,提取隐含在其中的、人们事先不知道的、但又是潜在有用的信息和知识的过程。
数据挖掘的商业定义
按企业既定业务目标,对大量的企业数据进行探索和分析,揭示隐藏的、未知的或验证已知的规律性,并进一步将其模型化的先进有效的方法。数据挖掘是从海量数据中提取隐含在其中的有用信息和知识的过程。它可以帮助企业对数据进行微观、中观乃至宏观的统计、分析、综合和推理,从而利用已有数据预测未来,帮助企业赢得竞争优势。
数据挖掘的系统分类
数据挖掘是一个交叉学科邻域,受多个学科影响,包括数据库系统、统计学、机器学习、可视化和信息科学。
数据挖掘技术
技术分类:
- 预言(Predication):用历史预测未来。
- 描述(Description):了解数据中潜在的规律
数据挖掘技术:
- 关联分析
- 分类(预言)
- 聚集
- 异常检测
数据挖掘的主要方法
- 分类(Classification)
- 聚类(Clustering)
- 相关规则(Association Rule)
- 回归(Regression)
- 其他
二、数据预处理
数据预处理的形式
- 数据清理:补充缺失数据、平滑噪声数据、识别或删除离群点,解决不一致
- 数据集成:集成多个数据库、数据立方或文件
- 数据变换:规范化和聚集
- 数据归约:简化数据、但产生同样或相似的结果
描述性数据汇总
描述性数据汇总技术可以用来识别数据的典型性质,突显哪些数据值应当视为噪声或离群点。(更好的理解数据)
主要内容:
- 度量数据的中心趋势
- 度量数据的离散程度
- 描述数据汇总的图形显示
度量数据的中心趋势
- 算数平均值(最常用)
- 分布式度量:可以通过如下方法计算度量(即函数):将数据集划分成较小的子集,计算每个子集的度量,然后合并计算结果,得到原(整个)数据集的度量值。
1、sum()
2、count()
3、min()
4、max() - 代数度量:可以通过应用一个代数函数于一个或多个分布度量计算的度量
1、mean():即平均数
2、中列数:最大值加最小值除以2 - 整体度量:必须对整个数据集计算的度量
1、中位数
2、众数
度量数据的离散程度
- 极差:最大值和最小值之差
- 四分位数
- 离群点:与数据的一般行为或模型不一致的数据对象
- 方差、标准差:反映了每个数与均值相比平均相差的数值
- 盒图boxplot,也称箱线图:
1、从下到上五条线分别表示最小值、下四分位数Q1、中位数、上四分位数Q3和最大值
2、盒的长度等于IRQ
3、中位数用盒内的横线表示
4、盒外的两条线(胡须)分别延伸到最小和最大观测值
基本描述数据汇总的图形显示
- 直方图:
概括给定属性分布的图形方法
每个矩形等宽
- 分位数图:
观察单变量数据分布的简单有效方法
- 散布图:
直接观察是否存在簇,离群点等
每个点对应一个坐标对
- 局部回归曲线:
添加一条光滑曲线到散布图
数据清理
现实世界的数据一般是不完整的、有噪声的和不一致的。
数据清理的任务:
- 填充缺失的值
- 光滑噪声并识别离群点
- 纠正数据中的不一致
填充缺失值
- 忽略元组
- 人工填写空缺值
- 使用一个全局常量填充空缺值
- 使用属性的平均值填充空缺值
- 使用与给定元组属同一类的所有样本的平均值
- 使用最可能的值填充空缺值
光滑噪声并识别离群点
操作:
- 分箱:通过考察数据的“近邻”来光滑有序数据的值。局部光滑。
(1)划分:等频、等宽
(2)光滑:用箱均值、用箱中位数、用箱边界,去替换箱中的每个数据。 - 回归:用一个(多元)线性回归函数拟合数据来光滑数据。

- 聚类:将类似的值聚集为簇。检测离群点。

- 其他:如数据归约、离散化和概念分层。
数据清理作为一个过程
- 偏差检测:
1、使用“元数据”
2、编码使用的不一致、数据表示的不一致、字段过载等
3、一些规则:唯一性规则、连续性规则、空值规则。
4、商业工具:数据清洗工具、数据审计工具 - 数据变换(纠正偏差):
1、数据迁移工具
2、提取/变换/载入(ETL)工具 - 加强交互性:
1、数据清理工具:Potter’s Wheel
2、开发数据变换操作规范说明语言
数据集成和变换
数据集成合并多个数据源中的数据,存放在一个一致的数据库中。
源数据可能包括多个数据库,数据立方体或一般文件。
数据变换将数据转换或统一成适合于挖掘的形式。
数据集成
- 实体识别:元数据可帮助避免错误
- 属性冗余:相关分析
- 数据重复(元组冗余)
- 数据值冲突的检测与处理:表示、比例或编码不同
数据变换
- 平滑:去掉数据中的噪声。技术包括分箱、回归、聚类。
- 聚集:对数据进行汇总或聚集
- 数据泛化(概化):使用概念分层,用高层概念替换低层或“原始”数据。
- 规范化:将属性数据按比例缩放,使之落入一个小的特定区间。
1、最小-最大规范化:
将原始数据v(v有原始的最小和最大值,v为此区间内的值)经线性变换映射到新区间[new_minA , new_maxA]。(对离群点敏感)
2、Z-Score规范化(零均值规范化):
属性A的值基于A的平均值和标准差规范化。(对离群点不敏感)

3、按小数定标规范化。 - 属性构造(特征构造):由给定的属性构造新的属性并添加到属性集中,以帮助挖掘过程。可以帮助提高准确率和对高维数据结构的理解
数据归约
数据归约技术可以用来得到数据集的归约表示,它小得多,但仍接近保持原数据的完整性。
对归约后的数据集挖掘将更有效,并产生相同(或几乎相同)的结果。
数据归约策略:
- 数据立方体聚集:
数据立方体存储多维聚集信息,提供对预计算的汇总数据进行快速访问。
- 属性子集选择:
检测并删除不相关、弱相关或冗余的属性或维,减小数据集。
其目的是找出最小属性集,使得数据类的概率分布尽可能地接近使用所有属性得到的原分布。
通常采用压缩搜索空间的启发式算法。如贪心算法:从局部最优到全局最优。 - 维度归约:
删除不重要的属性。
维度归约使用数据编码或变换,以便得到原数据的归约或“压缩”表示。分为无损和有损两种。
1、串压缩:无损,但只允许有限的数据操作。
2、小波变换:有损,适合高维数据。
3、主成分分析:有损,能更好地处理稀疏数据。 - 数值归约:
用规模较小的数据表示、替换或估计原始数据,来减少数据量。
1、参数方法:回归和对数线性模型
2、非参数方法:直方图、聚类、抽样。 - 离散化和概念分层产生:
数据离散化技术用少数区间标记替换连续属性的数值,从而减少和简化了原来的数据。
可以对一个属性递归地进行离散化,产生属性值的分层或多分辨率划分,称作概念分层。用较高层的概念替换较低层的概念。
三、关联规则挖掘
一个关联规则的例子:70%购买了牛奶的顾客将倾向于同时购买面包。
发现这样的关联规则可以为市场预测、决策和策划等方面提供依据。
相关概念
设 I = {i1, i2, … ,im}是由m个不同项目构成的集合
- 项目
其中的每个 ik。 - 项集
项目的集合 I。 - 交易
每笔交易T是项集I上的一个子集,每一个交易有一个唯一的标识——交易号,记作TID。 - 交易集
交易的全体。记作D。 - 项集的支持度
项集X的支持度support(X)就是项集X在交易集D中出现的概率,能够反映X的重要性。

(count为交易集D中包含X的交易的数量。) - 项集的最小支持度
用于发现关联规则的项集必须满足的最小支持度的阈值,称为项集的最小支持度,记为supmin。 - 项集的频繁集
支持度大于或等于supmin的项集称为频繁项集,反之称为非频繁集。 - 关联规则

衡量的标准为,关联规则的支持度和可信度。 - 关联规则的支持度
X和Y中所含项在交易集中同时出现的频率。
关联规则的最小支持度,记为supmin - 关联规则的可信度
如果交易中包含X,则交易中同时出现Y的概率。
关联规则的最小可信度,记为confmin - 强关联规则

关联规则挖掘的过程
- 找出所有频繁集
- 由频繁集产生强关联规则
Apriori算法
Apriori算法通过多次扫描数据集,找出(通过迭代来穷举出)所有频繁集,然后用这些频繁集产生强关联规则。
算法过程
- 产生1-频繁集L1
- 在L1上通过连接和修剪产生2-频繁集L2
- 依次类推,直到无法产生新的频繁集为止。
伪代码



FP-growth算法
FP-growth算法在扫描两遍数据集之后,利用一棵频繁模式树(FP-tree)来表示频繁集,进而再确定相应的强关联规则。
四、分类与预测
分类
1、建立分类模型:描述数据中的类
- 每个元组 / 样本都属于由其类标识所确定的类
- 用于构建模型的数据集被称为训练数据集
- 模型的表现形式有分类规则,判定树,和数学公式
2、使用模型进行分类:将未知类标识的数据分类
评估模型的预测准确率
- 将模型预测的测试样本的类与测试样本的类标识进行比较
- 模型的预测准确率等于被模型正确分类的测试样本在测试数据集中所占的比例
- 测试数据集应该与训练数据集相互独立,否则会产生过拟合问题
如果模型的预测准确率可以接受,就可用模型对未知类标识的数据对象进行分类
有/无指导学习
指导:训练数据(度量、观察)带有类标识,即训练数据集中的每个数据对象所属的类已知
有指导的学习:分类
无指导的学习:聚类(训练数据的类标识未知;对给定的一组观察数据或度量数据,识别数据中存在的类或簇)
预测
预测:
- 构造模型,并使用模型评估无标号样本类,或评估给定样本可能具有的属性值或值区间
- 分类:预测离散或标称值
- 回归:预测连续或有序值
用预测法预测类标号为分类,用预测法预测连续值为预测
准备分类和预测的数据
- 数据清理:消除或减少数据中的噪音,处理空缺值
- 相关性分析(特征选择):删除学习过程中不相关的或冗余的属性
- 数据变换:概化数据;规范化数据
比较分类方法
- 预测的准确率:模型正确地预测新的或先前未见过的数据的类标号的能力
- 速度:
构建模型所需的时间(训练时间)
模型分类/预测新数据所需的时间(分类/预测时间) - 强壮性:给定数据带有噪声或空缺值时,模型正确预测的能力
- 可伸缩性:训练数据集较大时,有效构造模型的能力
- 可解释性:模型是否是可理解的,是否提供了对数据内在特征的描述
- 其他度量:如,判定树的大小
用判定树归纳分类
判定树归纳
- 基本算法(贪心算法):
采用自顶向下递归地分而治之的方式构建树
开始时,所有训练数据都在根节点
属性值都是分类类型数据(若为连续值,则事先将其离散化)
使用选择的属性,递归地将数据分割
使用启发信息或统计度量选择判定属性(如,信息增益) - 划分停止的条件:
当前节点内的所有数据都属于同一个类
没有剩余属性可以用来进一步划分数据——使用多数表决法标注节点的类别
节点内不包含数据
属性选择度量:信息增益
在树的每个节点上,选择具有最高信息增益(或最大熵压缩)的属性作为测试属性(该属性使得对划分结果中的样本分类所需的信息量最小)
对某个样本分类所需的期望信息为:

根据值域为{a1,a2,…,av}的属性A划分得到的子集的熵为:
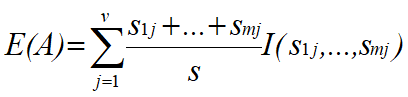
使用属性A划分数据产生的信息增益(熵的期望压缩)为:
树剪枝
过拟合:
- 太多分支,一些分支可能是由噪音或孤立点产生的
- 对新样本的预测准确率降低
避免过拟合的两个方法:
- 先剪枝:提前停止树的构造——如果增益度量小于某个阈值,则不分裂节点
- 后剪枝:对“完全生长”的树剪枝——产生一组逐渐被剪枝的树(使用一个与训练数据集独立的测试数据集评估被剪枝的树,选取最佳的树)
由判定树提取分类规则
对基本判定树归纳的加强
- 处理连续值属性:产生两个分支的划分
- 处理属性的空缺值:将属性中出现最频繁的值赋给此空缺值
- 属性构造:
基于现有属性构造新的属性
可以减少碎片、重复和复制问题
判定树归纳的可伸缩性
可伸缩性:以合理的速度分类包含百万条记录和几百个属性的数据集
可伸缩的判定树算法:SLIQ、SPRINT、RainForest
贝叶斯分类
- 贝叶斯分类:预测类成员关系的可能性,如给定样本属于一个特定类的概率
- 朴素贝叶斯分类:类条件独立:假定一个属性值对给定类的影响独立于其他属性的值
- 贝叶斯信念网络:
图形模型
能表示属性子集间的依赖
贝叶斯定理
五、聚类分析
聚类分析所处理的数据类型
- 区间标度变量
- 二元变量
- 标称型、序数型和比例标度型变量
- 混合类型
聚类方法
分为5类:
- 划分方法:
将对象划分为k个簇,使得数据对象到簇中心的距离的平方和最小 - 层次方法:
使用某种准则对对象集合进行层次分解 - 基于密度的方法:
基于空间中数据分布的密度进行聚类 - 基于网格的方法:
将对象空间量化为有限数目的单元,形成网格结构 - 基于模型的方法
为每个簇假定一个模型,寻找数据对给定模型的最佳拟合
划分方法
k-means方法:用簇中心代表簇
算法:
- 任意选择k个对象作为初始的簇中心
- 计算每个数据对象与当前每个簇中心之间的距离,将其赋给离它最近的簇中心所代表的簇
- 计算在当前划分下,每个簇的中心(簇内所有数据的平均值)
- 回到第二步,当簇中心或划分不再改变时,算法停止
优点:
计算复杂度较小,快速高效
缺点:
仅适用于可以计算均值的数据,无法处理分类类型的数据
需要指定簇的数目k
对噪音与孤立点敏感
仅适于发现大小相近的球形簇
k-medoids方法:用簇内位于最中心位置的数据对象代表簇
三种算法:PAM、CLARA、CLARANS
层次方法
根据数据之间的距离,透过一种层次架构方式,反复将数据进行聚合,创建一个层次以分解给定的数据集。常用于一维数据的自动分组。
分为两类:凝聚的和分裂的层次聚类
绝大多数层次聚类方法属于凝聚的层次聚类
凝聚的层次聚类方法
优点:不需要预先制定聚类数,对于距离度量标准的选择并不敏感,可以发现类的层次关系
缺点:效率低,可伸缩性较差,已做的处理不能被撤销
改进:与其他的聚类技术进行集成。(BIRCH、CURE、CHAMELEON)
基于密度的方法
将簇看作是数据空间中被低密度区域分隔开的高密度对象区域
几种算法:DBSCAN、OPTICS、DENCLUE、CLIQUE
DBSCAN
优点:聚类速度快,对噪声点不敏感,能发现任意形状的簇,不需要输入要划分的聚类个数,聚类簇的形状没有偏倚
缺点:数据量大时,需要较大的内存和计算时间,对两个参数的设置敏感,算法效果依赖距离公式选择
基于网格的方法
三种算法:STING、WaveCluster、CLIQUE
优点:速度快
缺点:参数敏感、无法处理不规则分布的数据
基于模型的方法
三类方法:
- 统计方法:EM、AutoClass
- 机器学习方法:CONWEB、CLASSIT
- 神经网络:SOM
优点:对”类“的划分不那么”坚硬“,而是以概率形式表现,每一类的特征也可以用参数来表达
缺点:执行效率不高