一文带你看懂多路复用与多路分解
写在前面:这里是小王成长日志,一名普通在校大学生,想成学习之余将自己的学习笔记分享出来,记录自己的成长轨迹,帮助可能需要的人,平时博客内容主要是一些系统的学习笔记,项目实战笔记,一些技术的探究和自己的一些思考。欢迎大家关注,你们的每一个评论点赞关注我都会仔仔细细去看的。有任何问题欢迎交流,我会尽我所能帮助大家的,共创CSDN美好环境。
最近在看计算机网络,这算是学习笔记吧,因为是自学,水平有限,不一定很有深度,但保证发出来的东西一定是自己思考整理过后的,每句话都经过了查证,欢迎大佬指导,若有错,请轻喷。
文章目录
- 前置知识
- 进程如何取得来自网络的数据
- 运输层报文结构
- 概述
- 多路分解
- 多路复用
- 举个栗子
- UDP和TCP中的多路复用和多路分解有何不同
- UDP套接字-无连接的多路分解与多路复用
- TCP套接字-面向连接的多路复用与多路分解
- Web服务器与TCP
前置知识
进程如何取得来自网络的数据
首先我们了解进程从网络中接收数据的过程:
在目的主机,运输层需要从其下层的网络层接收报文段。
而运输层则负责将这些报文段中的数据交付给目标进程的指定套接字(而一个进程可能有多个套接字)
因此套接字(Socket)充当从进程向网络传递数据和从进程向网络传递数据的门户。
如下图
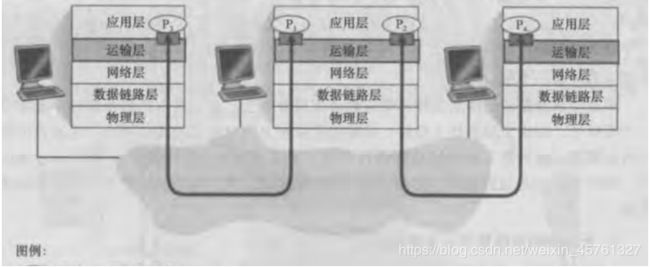
运输层报文结构

如上我们可见 每个运输层报文中都有两个首部字段-源端口号和目的端口号。
而在主机上,每个套接字都对应着一个进程,而每个套接字都能够分配一个端口号。
所以当报文段到达主机时,运输层检查报文段中的目的端口号,并将其定向到相应的套接字 (多路分解),然后报文段中的数据通过套接字进人其所连接的进程。
概述
多路分解
每个运输层报文段中具有几个字段(就是指上面的源端口号和目的端口号)。在接收端,运输层检查这些字段,标识出接收套接字并与套接字的标识信息进行比对,如果符合则将报文段定向到该套接字。
多路复用
在源主机从不同套接字中收集数据块,并为每个数据块封装上首部信息(封装源端口号和目的端口号,这将在以后用于分解)从而生成报文段,然后将报文段传递到网络层。
举个栗子
我们用书上的一个栗子来形象地说明一下什么是多路分解和多路复用:
在这个栗子中总共有两个家庭(两个端系统),每个家庭有7个孩子(进程),每个家庭的孩子每周会互相写一封信,例如老大给老大写,老二给老而写(信以及信封上的字符象征应用层报文)。
我们让第一家的小B和第二家的老A负责家庭内部的邮件收发(运输层从IP层接收报文并传递给相应的进程)。明显外部的邮政系统则充当了两个端系统之间的信息传输通道。
每一个孩子通过他们的名字来标识。当 小B 从邮递员( IP 层)处收到一批信件,并通过查看收信人名字(报文上的目的端口号)而将信件亲手交付给他的兄弟姐妹们(进程)时,他执行的就是一个分解操作。
当老A从兄弟姐妹们(进程)那里收集信件并将它们交给邮递员(IP层)时,她执行的就是一个多路复用操作。
UDP和TCP中的多路复用和多路分解有何不同
主要是scoket的不同:
UDP套接字-无连接的多路分解与多路复用
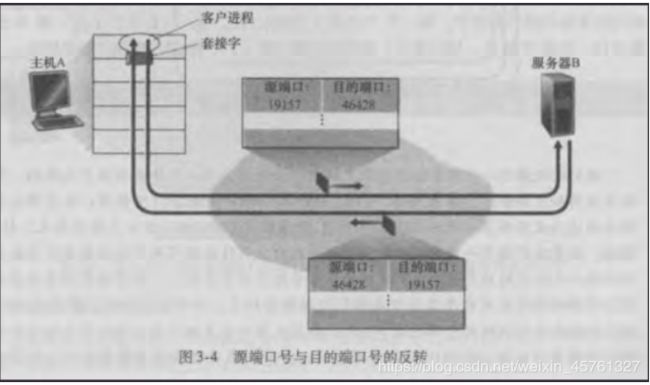
当我们创建一个UDP套接字时,运输层会自动或者我们人为为套接字绑定一个1024 - 65535之间的端口(其余端口是周知端口,留给一些周知应用层协议)。
UDP套接字由二元组来进行全面标识的
-
该二元组包含一个目的IP地址和一个目的端口号。
因此,如果两个UDP报文段有不同的源IP地址或源端口号,但具有相同的目的IP地址和目的端口号,那么这两个报文段将通过相同的目的套接字被定向到相同的目的进程。(多路分解)
-
源端口号用作“返回地址”的一部分填充到回复报文的目的端口,这很明显
TCP套接字-面向连接的多路复用与多路分解
而TCP套接字接字和UDP套接字之间有一个细微差别:TCP套接字由一个四元组(源IP地址,源端口号,目的IP地址,目的端口号)来进行标识。
因此因为使用了四个值来进行套接字的定位,所以来自不同IP但源端口相同的两个TCP报文段将被定向到两个不同的套接字,反之亦然。(多路分解)
服务器主机可以支持很多并行的TCP套接字,每个套接字与一个进程相联系,并由其四元组来标识每个套接字。当一个TCP报文段到达主机时,所有4个字段(源P地址,源端口,目的P地址,目的端口)被用来报文段定向(分解)到相应的套接字。
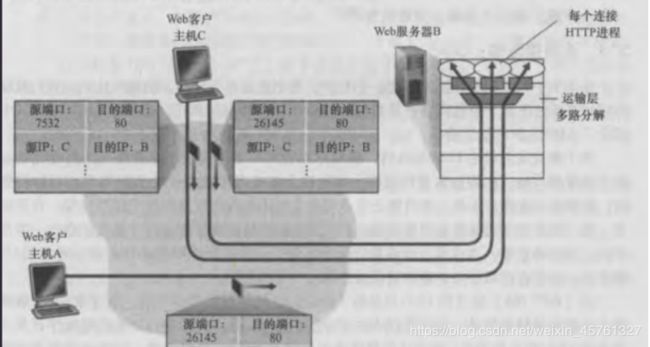
Web服务器与TCP
还是看上面的图。
上面的图显示了一台服务器为每条连接生成一个新进程 。 如图所示,每个这样的进程都有自己的连接套接字,通过这些套接字可以收到HTTP 请求和发送 HTTP 响应
- 连接套接字与进程之间并非总是有着一 一对应的关系 。
- 当今的高性能 Web 服务器通常只使用一个进程,但是为每个新的客户连接创建一个具有新连接套接字的新线程 。 (线程可被看作是一个轻量级的子进程 。 )
- 如果客户与服务器使用持续 HTTP ,则在整条连接持续期间,客户与服务器之间经由同一个服务器套接字交换 HTTP 报文 。 然而,如果客户与服务器使用非持续连接,则对每一对请求/响应都创建一个新的 TCP 连接并在随后关闭,因此对每一对请求/响应创建一个新的套接字并在随后关闭 。 这种套接字的频繁创建与关闭会严重地影响一个繁忙的 Web服务器的性能(虽然有许多操作系统技巧可用来减轻这个问题的影响) 。
都看到这里了,各位哥哥姐姐叔叔阿姨给小王点个赞 关个注 留个言吧,和小王一起成长吧,你们的关注是对我最大的支持。
有事没事,进来看看吧 : 小王博客目录索引,进来看看吧,说不定有你想要的呢
如果以上内容有任何不准确或遗漏之处,或者你有更好的意见,就在下面留个言让我知道吧-我会尽我所能来回答。