linux文本处理三剑客之awk命令
linux文本处理三剑客之awk命令
- 1. awk–“样式扫描和处理语言”
- 2. awk模式匹配
- 3. 记录和域
- 4. 指定分隔符
- 4.1 -F "" 指定分隔符
- 4.2 FS="" 指定分隔符
- 5. 关系和布尔运算值
- 6. 表达式
- 7. 系统变量
- 8. 格式化输出
- 9. 内置字符串函数
- 9.1 gsub函数
- 9.2 index
- 9.3 length
1. awk–“样式扫描和处理语言”
awk其名称得自于它的创始人 Alfred Aho 、Peter Weinberger 和 Brian Kernighan 姓氏的首个字母。实际上 AWK 的确拥有自己的语言: AWK 程序设计语言 , 三位创建者已将它正式定义为“样式扫描和处理语言”。
它允许您创建简短的程序,这些程序读取输入文件、为数据排序、处理数据、对输入执行计算以及生成报表,还有无数其他的功能。
awk 是一种很棒的语言,它适合文本处理和报表生成,其语法较为常见,借鉴了某些语言的一些精华,如 C 语言等。在 linux 系统日常处理工作中,发挥很重要的作用,掌握了 awk将会使你的工作变的高大上。 awk 是三剑客的老大,利剑出鞘,必会不同凡响。
awk程序由一个主输入循环维持,主输入循环反复执行,直到条件被触发,主输入循环无须由程序员去写,awk已经搭好主输入循环的框架。
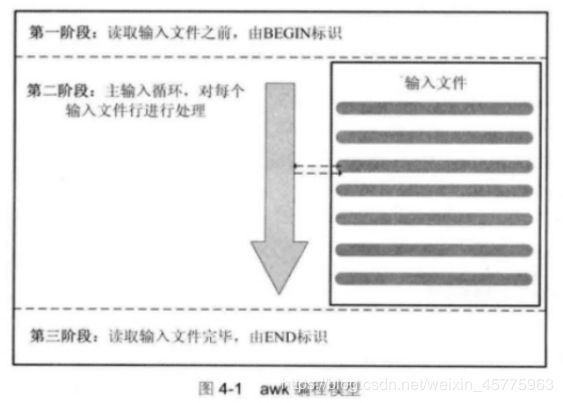
2. awk模式匹配
任何awk语句都由模式(pattern)和动作(action)组成。
模式是由一组用于测试输入行是否需要执行过程的规则;
动作是包含语句,函数和表达式的执行过程。
简单来说,模式决定动作何时触发和触发时间,动作执行对输入行的处理
例1:使用awk命令,将空白行都输出成指定内容
awk '/^$/{print "This is a blank line."}' input


例2:将要执行的动作写入文件中
awk -f scr.awk input

例3:可将文件作为脚本文件直接使用
chmod +x scr.awk
./scr.awk input
注意:脚本文件的第一行必须写#!/usr/bin/awk -f


3. 记录和域
awk认为输入文件是结构化的,awk将每个输入文件行定义为记录,行中的每个字符串定义为域,域之间用空格、Tab键或其他符号进行分隔,分隔域的符号就叫做分隔符。
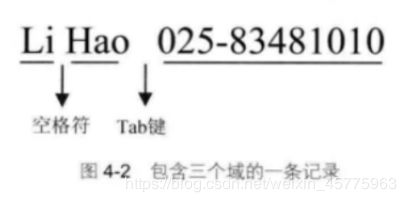
awk定义操作符$来指定执行动作的域,域操作符$后面跟数字或变量来标示域的位置。每条记录的域从1开始编号,$1表示第一个域;$0表示所有域
注意:默认以多个空格为分隔符,Tab也被默认为多个空格
awk '{print $2,$1,$4,$3}' stucode #输出第2,1,4,3域
awk '{print $0}' stucode #输出所有域
awk 'BEGIN {one=1;two=2} {print $(one+two)}' stucode #输出第3域



4. 指定分隔符
4.1 -F “” 指定分隔符
-F "" 指定分隔符
例:-F "\t" 此处指定一个tab键为分隔符
awk -F "\t" '{print $3}' stucode
awk -F "\t" '{print $1}' stucode
awk -F "\t" '{print $2}' stucode ##这里就会出现问题,如果文件中有多个tab,系统就会把多的tab当作多个域


解决方法:应用正则表达式 -F “\t+” 表示指定一个或多个tab为分隔符
awk -F "\t+" '{print $2}' stucode

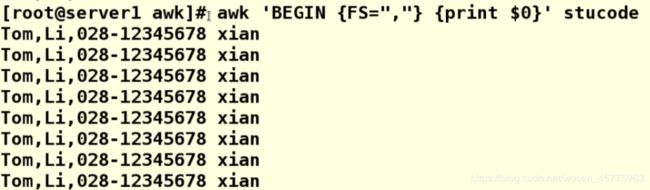
4.2 FS="" 指定分隔符
FS="" 指定分隔符
例:此处指定,为分隔符
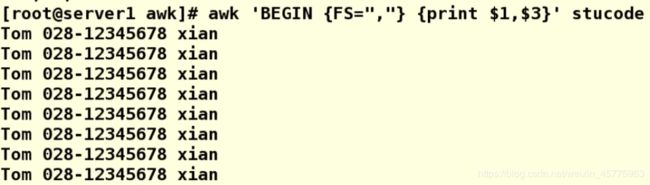
awk 'BEGIN {FS=","} {print $0}' stucode
awk 'BEGIN {FS=","} {print $1,$3}' stucode

5. 关系和布尔运算值
awk定义了一组关系运算符用于awk模式匹配
| 运算符 | 说明 |
|---|---|
| < | 小于 |
| > | 大于 |
| <= | 小于或等于 |
| >= | 大于或等于 |
| == | 等于 |
| != | 不等于 |
| ~ | 匹配正则表达式 |
| !~ | 不匹配正则表达式 |
例1:~ 匹配正则表达式 !~ 不匹配正则表达式
awk 'BEGIN {FS=":"} $1~/root/' passwd #找到文件中第一域匹配root的部分输出该行
awk 'BEGIN {FS=":"} $0~/root/' passwd #找到文件中全部域匹配root的部分输出该行
awk 'BEGIN {FS=":"} $0!~/nologin/' passwd #找到文件中全部域不匹配nologin的部分输出该行
![]()

例2:精确匹配
awk 'BEGIN {FS=":"} {if ($3<$4) print$0}' passwd
awk 'BEGIN {FS=":"} {if ($3==1||$4==10) print$0}' passwd

6. 表达式
跟其他编程语言一样,awk表达式用于存储、操作和获取数据。一个awk表达式可由数值、字符常量、变量、操作符、函数和正则表达式自由组合而成
变量是一个值的标识符,定义awk变量非常方便,只需要定义一个变量名并将值赋给它即可
注意:
- 1.变量名只能包含字母、数字和下划线,而且不能以数字开头
- 2.定义awk变量无须声明变量类型,每个变量有两种类型的值:字符串值和数值
- 3.awk根据表达式上下文来确定使用哪个值
- 4.变量的默认数值为0,默认字符串值为空
awk '/^$/{print x++}' input #先输出x再+1
awk '/^$/{print ++x}' input #先+1再输出x,即输出空白行行号



7. 系统变量
awk定义了很多的内建变量用于建设环境信息,我们称它为系统变量。
这些系统变量可分为:
第一种用于改变awk的默认值,如域分隔符;
第二种用于定义系统值,在处理文本时可以读取这些系统值。如记录中的域数量,当前记录数、文件名等。
NF:记录的域数量NR:显示当前的记录数,该值根据读取输入文件的进度而变化。读取第一条记录 时,NR=1;读取到末尾时,NR为包含该文件所包含的记录数$0:打印记录的所有域FILENAME:表示当前的输入文件名
awk ' BEGIN {FS=","} {print NF,NR,$0} END{print FILENAME}' stucode

8. 格式化输出
前面的例子只涉及awk如何输入文件进行处理,对于输入的格式并未规定。
而awk的一大主要功能是产生报表,报表就是要求按照一定的格式输出。awk借鉴C语言的语法,定义了printf输出语句,它可以规定输出的格式。
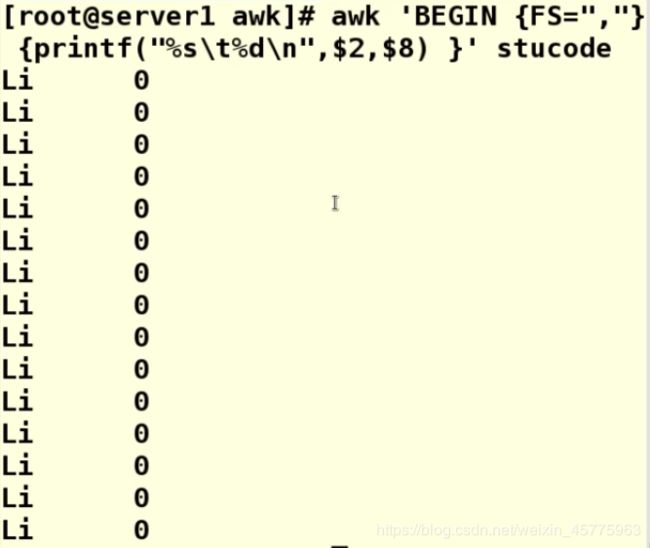
awk 'BEGIN {FS=","} {printf("%s\t%d\n",$2,$8)}' stucode
awk 'BEGIN {printf("%c\n",65)}'
awk 'BEGIN {printf("%f\n",2020)}'
awk 'BEGIN {printf("%.3f\n",2020.4141214)}'
awk 'BEGIN {FS=":"} {printf("%-15s\t%s\n",$1,$3)}' stucode



9. 内置字符串函数
awk提供了强大的内置字符串函数,用于实现文本的字符串替换,查找以及分割等功能。
9.1 gsub函数
gsub函数执行字符串替换功能,将第一个字符串替换为第二个字符串
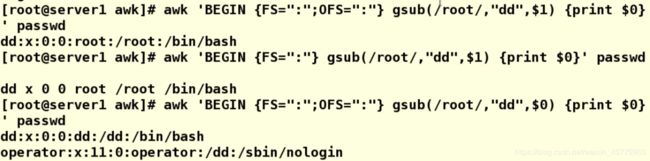
awk 'BEGIN {FS=":";OFS=":"} gsub(/root/,"dd",$1) {print $0}' passwd #此处的OFS表示输出指定分隔符
awk 'BEGIN {FS=":"} gsub(/root/,"dd",$1) {print $0}' passwd #不指定PFS的话默认以空格为分隔符输出
awk 'BEGIN {FS=":"} gsub(/root/,"dd",$0) {print $0}' passwd #替换所有的域
9.2 index
index返回第二个字符串在第一个字符串出现的首位置
awk 'BEGIN {print index("gridsphere","ph")}'
![]()
9.3 length
length返回字符串长度
awk 'BEGIN {print length("gridsphere")}'
![]()