淘宝用户行为数据分析
淘宝用户行为数据分析
- 一 、分析背景
- 1. 数据集介绍
- 2. 字段含义
- 二、提出问题
- 三、数据清洗
- 1、数据选取
- 2、缺失值处理
- 3、删除重复值
- 4、异常值处理
- 5、一致化处理
- 四、构建模型
- 1.用户在使用淘宝的活跃时段,了解用户的行为时间模式;
- 2.通过观察平台的流量情况、用户从浏览到最终购买整个过程的流失情况,构造漏斗模型,确定夹点位置;
- 3.通过RFM模型,分析高价值用户特征;
- 4.二八理论分析淘宝产品;
- 五、结论与建议
一 、分析背景
电子商务已成为我们生活中不可或缺的一部分,随着生活水平的提高,淘宝成交量在逐年上升。本文获取了部分淘宝用户行为数据进行分析,希望能得到一些有价值的信息以便为用户提供更好的网购体验。
1. 数据集介绍
本数据集包含了2017年11月25日至2017年12月3日之间,约一百万随机用户的所有行为 (行为包括点击、购买、加购、收藏)。数据集的每一行表示一条用户行为,由用户ID、商品 ID、商品类目ID、行为类型和时间戳组成,并以逗号分隔。由于数据集有1亿条数据记录,数据量较大,本次分析只抽取200万条记录进行分析。
数据来源:
User Behavior Data from Taobao for Recommendation-数据集-阿里云天池
2. 字段含义
user_id:用户身份
item_id:商品ID
category_id:品类ID(商品所属的品类)
timestamp:用户行为发生的时间
behavior_type:用户行为类型,包含以下4种类型
pv:点击
fav:收藏
cart:加购物车
buy:购买
二、提出问题
1.用户在使用淘宝的活跃时段,了解用户的行为时间模式;
2.通过观察平台的流量情况、用户从浏览到最终购买整个过程的流失情况,构造漏斗模型,确定夹点位置;
3.通过RFM模型,分析高价值用户特征;
4.二八理论分析淘宝产品;
三、数据清洗
1、数据选取
原数据集有1亿多条数据,数据量比较大,因此此次分析只选取其中的200万条数据,将其保存到’MyUserBehavior.csv‘中,数据结构展示如下。
import pandas as pd
df=pd.read_csv(r'./MyUserBehavior.csv')
df.head()

2、缺失值处理
missing_data=df.isnull().sum()

结果显示无缺失数据,可进行下一步处理。
3、删除重复值
通过展示原数据信息可知,原数据集中共有2000000条数据

去重后数据集信息展示如下,共有2000000条数据

通过两次对比可知,数据集中不存在重复数据。
4、异常值处理
df.describe()

过观察数据集的总数,平均值,方差等,四分位数等,发现数据集中时间戳存在异常。该数据正常的时间戳范围是(1511539200,1512316800),因此删除该时间范围以外的数据。
df=df[df.timestamp<1512316800]
df=df[df.timestamp>1511539200]
5、一致化处理
新增日期类型三列,将原数据中时间戳格式的列timestamp,转换为时间日期格式。
df['date']=df['timestamp'].map(lambda x:time.strftime("%Y-%m-%d", time.localtime(x)))
df['hour']=df['timestamp'].map(lambda x:time.strftime("%H", time.localtime(x)))
查看df数据集数据类型:
df.dtypes

发现date列应该转化为日期类数据类型,hour列应该是字符串数据类型。
df['date']=pd.to_datetime(df['date'])
df['hour']=df['hour'].astype('int64')
四、构建模型
1.用户在使用淘宝的活跃时段,了解用户的行为时间模式;
- pv和uv分析
PV(访问量):即Page View, 具体是指网站的页面浏览量或者点击量,页面被刷新一次就计算一次。
UV(独立访客):即Unique Visitor,访问网站的一台电脑客户端为一个访客。
1)日访问量分析
pv_d=df.groupby('date')['user_id'].count().reset_index().rename(columns={'user_id':'pv'})
uv_d=df.groupby('date')['user_id'].apply(lambda x:x.drop_duplicates().count()).reset_index().rename(columns={'user_id':'uv'})
import matplotlib.pyplot as plt
%matplotlib inline
fig,axes=plt.subplots(2,1,sharex=True)
pv_d.plot(x='date_show',y='pv',ax=axes[0],color='red')
uv_d.plot(x='date_show',y='uv',ax=axes[1])
plt.xticks(rotation=60)
axes[0].set_title('pv_daily')
axes[1].set_title('uv_daily')

12.2和12.3的行为流量有明显的增加,看日期是周末,休息日人们会有更多的时间来进行购物,所以流量增加;但发现11.25和11.26同样也是周末,增加却并不明显;考虑是临近双12,商家进行了双12促销活动预热所带来的流量增加。
2)小时访问量分析
pv_hour=df.groupby('hour')['user_id'].count().reset_index().rename(columns={'user_id':'pv'})
uv_hour=df.groupby('hour')['user_id'].apply(lambda x:x.drop_duplicates().count()).reset_index().rename(columns={'user_id':'uv'})
fig,axes=plt.subplots(2,1,sharex=True)
pv_hour.plot(x='hour',y='pv',ax=axes[0],color='red')
uv_hour.plot(x='hour',y='uv',ax=axes[1])
axes[0].set_title('pv_hour')
axes[1].set_title('uv_hour')

图表显示:pv和uv在凌晨0-5点期间波动情况相同,都呈下降趋势,访问量都比较小,在晚上18:00左右,pv波动情况比较剧烈,相比来看uv不太明显,因此晚上18:00以后是淘宝用户访问活跃时间段。
3)不同行为类型用户pv分析
pv_detail=df.groupby(['behavior_type','hour'])['user_id'].count().reset_index().rename(columns={'user_id':'total_pv'})
fig,axes=plt.subplots(2,1,sharex=True)
sns.pointplot(x='hour',y='total_pv',hue='behavior_type',data=pv_detail,ax=axes[0])
sns.pointplot(x='hour',y='total_pv',hue='behavior_type',data=pv_detail[pv_detail.behavior_type!='pv'],ax=axes[1])
axes[0].set_title('不同行为类型用户')
axes[1].set_title('不同行为类型用户(不含pv)')
axes[0].set_xlabel('')

图表显示:点击这一用户行为相比较于其他三类用户行为,pv访问量较高,同时四种用户行为的波动情况基本一致,因此晚上这一时间段不管哪一种用户行为,pv访问量都是最高的。从图2可以看出,加入购物车这一用户行为的pv总量高于收藏的总量,因此在后续漏斗流失分析中,用户类型cart应该在fav之前分析。
2.通过观察平台的流量情况、用户从浏览到最终购买整个过程的流失情况,构造漏斗模型,确定夹点位置;
- 用户行为转化漏斗
df_count=df.groupby(['behavior_type']).count().rename(columns={'user_id':"total"}).drop(['item_id','category_id','timestamp','date','hour'],axis=1)
df_count=df_count.sort_values(["total"],ascending=False)
temp1 = np.array(df_count["total"][1:])
temp2 = np.array(df_count["total"][0:-1])
single_convs = temp1 / temp2
single_convs = list(single_convs)
single_convs.insert(0,1)
single_convs = [round(x,4) for x in single_convs]
df_count['single_convs'] = single_convs
t1=np.array(df_count['total'])
t2=np.ones(len(df_count['total'])) *df_count['total'][0]
total_convs = t1 / t2
total_convs = list(total_convs)
total_convs = [round(x,4) for x in total_convs]
df_count['total_convs'] = total_convs
df_count=df_count.reset_index()
df_count

from pyecharts import options as opts
from pyecharts.charts import Funnel
from pyecharts.faker import Collector
attrs=df_count['behavior_type'].values.tolist()
attr_value=(np.array(df_count['total_convs'])*100).tolist()
attr_value = [round(x,4) for x in attr_value]
from pyecharts import options as opts
from pyecharts.charts import Funnel
total_funel=[]
for i in range(len(attrs)):
p=[]
p.append(attrs[i])
p.append(attr_value[i])
total_funel.append(p)
Funnel().add("total_convs_funnel", total_funnel,label_opts=opts.LabelOpts(formatter='{c}'+'%')).set_global_opts(legend_opts=opts.LegendOpts(orient='orient',pos_top='bottom',pos_right='100'),tooltip_opts=opts.TooltipOpts(formatter="{a} {b}: {c}"+'%'),title_opts=opts.TitleOpts(title="总体转化漏斗图",pos_left='center')).render("total_convs_funnel.html")

attrs=df_count['behavior_type'].values.tolist()
attr_value=(np.array(df_count['single_convs'])*100).tolist()
attr_value = [round(x,4) for x in attr_value]
single_funnel=[]
for i in range(len(attrs)):
p=[]
p.append(attrs[i])
p.append(attr_value[i])
single_funnel.append(p)
Funnel().add("single_convs_funnel", single_funnel,label_opts=opts.LabelOpts(formatter='{c}'+'%')).set_global_opts(legend_opts=opts.LegendOpts(orient='orient',pos_top='bottom',pos_right='100'),tooltip_opts=opts.TooltipOpts(formatter="{a} {b}: {c}"+'%'),title_opts=opts.TitleOpts(title="单一转化漏斗图",pos_left='center')).render("single_convs_funnel.html")

用户流失率最高的是点击—加购物车这一环节,而用户将产品加购收藏到购买的转化率为69.96%,说明用户的大部分行为都是在浏览商品上,寻找符合自己要求的商品,因此需要优化商品的搜索以及推荐等功能,便于用户快速找到合适商品,提高购买转化。
3.通过RFM模型,分析高价值用户特征;
- RFM的含义:
R(Recency):客户最近一次交易时间的间隔。R值越大,表示客户交易发生的日期越久,反之则表示客户交易发生的日期越近。
F(Frequency):客户在最近一段时间内交易的次数。F值越大,表示客户交易越频繁,反之则表示客户交易不够活跃。
M(Monetary):客户在最近一段时间内交易的金额。M值越大,表示客户价值越高,反之则表示客户价值越低。
RFM分析就是根据客户活跃程度和交易金额的贡献,进行客户价值细分的一种方法。
由于数据缺少M(消费金额)列,暂且通过R(最近一次购买时间)和F(消费频率)的数据对客户价值进行判断
from datetime import datetime
datenow=datetime(2017,12,6)
#每位用户最近购买时间
recent_buy_time=df[df.behavior_type=='buy'].groupby('user_id').date.apply(lambda x:datenow - x.sort_values(ascending=False).iloc[0]).reset_index().rename(columns={'date':'recent'})
recent_buy_time
recent_buy_time['recent']=recent_buy_time['recent'].map(lambda x:x.days)
recent_buy_time.head()

buy_freq =df[df.behavior_type=='buy'].groupby('user_id').item_id.count().reset_index().rename(columns={'item_id':"freq"})
rfm=pd.merge(recent_buy_time,buy_freq,left_on='user_id',right_on='user_id',how='outer')
rfm['recent_value']=pd.qcut(rfm.recent,2,labels=['2','1'])
rfm['freq_value']=pd.qcut(rfm.freq,2,labels=['1','2'])
rfm['rfm']=rfm['recent_value'].str.cat(rfm['freq_value'])
rfm.head()

rfm_r=rfm.groupby('rfm')['user_id'].apply(lambda x:x.count()/len(rfm)).reset_index().rename(columns={'user_id':'ratio'})

import matplotlib
matplotlib.rcParams["font.sans-serif"]=["SimHei"]
matplotlib.rcParams["axes.unicode_minus"]=False
a=rfm_r['ratio'].tolist()
b=['潜在用户','保持用户','发展用户','价值用户']
plt.pie(a,labels=b,autopct="%3.1f%%")
plt.title("不同类型价值用户占比")
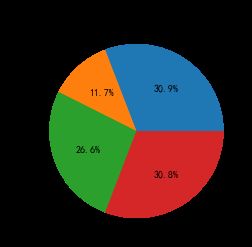
因为本数据集没有提供消费金额,因此只能R和F进行用户价值分析,通过RF用户价值分析,对于价值用户,为重点用户需要关注;对于发展用户这类忠诚度高而购买能力不足的,可以适当给点折扣或捆绑销售来增加用户的购买频率。对于保持用户这类忠诚度不高而购买能力强的,需要关注他们的购物习性做精准化营销。
4.二八理论分析淘宝产品;
二八定律:在任何一组东西中,最重要的只占其中一小部分,约20%,其余80%尽管是多数,却是次要的,因此又称二八定律。
data_category=df[df.behavior_type!="fav"].groupby(['category_id','behavior_type']).user_id.count().unstack(1).rename(columns={'pv':'点击量','cart':'加入购物车量','buy':'购买量'}).fillna(0)
data_category=data_category[data_category['购买量']>0]
value_8=data_category['购买量'].sum()*0.8
value_10=data_category['购买量'].sum()
data_category=data_category.sort_values(by='购买量',ascending=False)
data_category['累计购买量']=data_category['购买量'].cumsum()
data_category['分类']=data_category['累计购买量'].map(lambda x:'前80%' if x<=value_8 else '后20%')
data_category.head()

data_category.groupby('分类')['分类'].count()/data_category['分类'].count()

图表显示:前80%销量有20%左右的商品品类承包,接近二八原则。
对于传统零售行业,因为成本高,因此只能局限于这前20%的商品提供利润;
对于电子商务,空间成本吉减少乃至为0,使后80%的商品也可以销售出去,因此将长尾部分的商品优化推荐好,能够给企业带来更大的收益。
五、结论与建议
用户行为转化夹点位置在点击-加购环节,转换率仅为6.2%,说明用户花费了大量时间搜索以及挑选产品;
同时独立访客从点击到购买转化率为69%,说明用户购买意愿很强。针对该情况,平台可以优化筛选、搜索,加入精准推荐这个功能,以便用户能够更快更精准的找到自己心仪的商品,增强商品转化。
2017年11月25日-12月1日的日活跃用户数基本一致,12月2日和3日的活跃用户数明显增加,12.2和12.3是周末休息日,人们会有更多的时间来进行购物,但11.25和11.26同样也是周末,增加却并不明显。通过搜索2017年双12发现,淘宝双12活动从12月1日开始预热,由于数据范围较小,推测为预热活动所带来的流量增加。
每日2点到6点用户活跃度快速降低,降到一天中的行低谷,7点到10点用户活跃度开始上升,10点到18点用户活跃度较平稳,17点到0点用户活跃度快速上升,达到一天中的峰值。可针对峰值时段加大推广促销活动,提高购买转化率。
对于高价值用户,需要重视,提高服务满意度防止流失
对于发展用户,需要换醒,通过折扣、捆绑销售提高购买频率
对于保持用户,需要维护,分析其偏好,更精准的推送商品
对于潜在用户,需要推广,发放优惠劵、短信互动等方式唤回
用户喜好商品类别里并没有出现购买次数非常集中的商品,说明店铺主要依靠长尾商品的累积效应。