Python爬虫学习(三)之Scrapy框架
最近在各个平台上学习python爬虫技术,林林总总接触到了三大类型的爬虫技术——【1】利用urllib3实现,【2】使用Requests库实现,【3】使用Scrapy框架实现。
虽然是按照以上的顺序进行学习的,但是在学习scrapy的过程中问题比较多,所以先从它开始。Python爬虫学习(一)之简单实现、Python爬虫学习(二)之Requests库将先添加至@TO-DO list里。
对于Scrapy的学习采取了阅读文档然后直接上手一个小项目的方式。这个项目的任务是爬取豆瓣电影 Top 250,把250部电影的名字、封面图以及评价数爬下来并储存至文件中。
文章目录
- 一、简介
- 二、安装以及新建项目
- 三、爬虫逻辑编码
- 四、总结
一、简介
Scrapy is a fast high-level web crawling and web scraping framework, used to crawl websites and extract structured data from their pages. It can be used for a wide range of purposes, from data mining to monitoring and automated testing.(https://docs.scrapy.org/)
Scrapy 是高级的、高速的网络爬虫框架,它被应用于爬取网站以及从中提取结构化数据。Scrapy框架应用广泛,适用于从数据挖掘到监控以及自动化测试等场景。
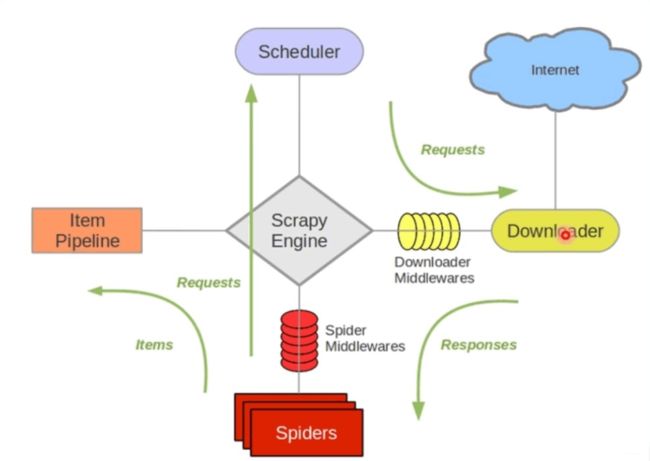
- Scrapy Engine(引擎):用来处理整个系统的数据传递,调度框架的各个部分,类似电脑的cpu。是整个系统的核心部分。
- Scheduler(调度器):用来接受引擎发过来的Request请求, 压入队列中, 并在引擎再次求的时候返回。
- Downloader(下载器):用于引擎发过来的Request请求对应的网页内容, 并将获取到的Responses返回给Spider。
- Item Pipeline(管道):负责处理Spider中获取的实体,对数据进行处理,将数据输出至文件或数据库。
- Middlewares(下载器中间件):主要用于处理Scrapy引擎与下载器之间的请求及响应。
- SpiderMiddlewares(爬虫中间件):主要用于处理Spider的Responses和Requests
从Scrapy的架构图可以看出,这是一个系统化、高集成的爬虫框架。它免去了我们在许多爬取的具体细节上的编码过程,而让我们专注于我们最终的目的。个人认为Scrapy是我接触的这三种爬虫中集成度、自定义程度最高的实现方式。
二、安装以及新建项目
-
安装Scrapy
因为电脑上安装了PyPI,因此采取了最简便的安装方式:
在cmd中输入pip install scrapy,等待流程结束即可。
在cmd中输入pip show scrapy后如果显示版本号等信息就表示安装成功了。 -
新建项目
cmd进到所需目录,然后输入scrapy startproject [-projectname],其中projectname为项目名称。系统会返回如下代码:
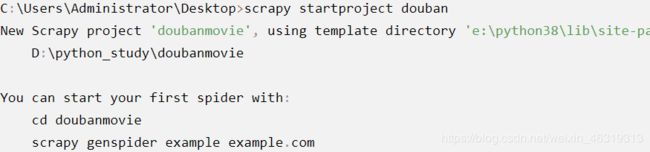
随后按照提示输入cd doubanmovie和
scrapy genspider [spidername] [url](其中spidername是爬虫的名字,url是起始页码),一个基本的爬虫项目就建立成功了。将文件夹导入PyCharm中,项目结构如下图所示:
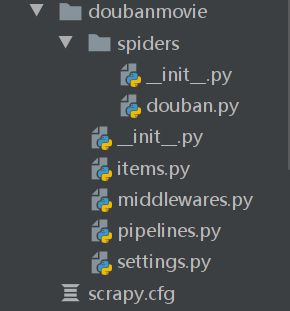
其中,各个文件的功能如下:
- _init_.py:将该目录标识为一个模块,当其它文件导入改文件夹时,会先执行其中的代码。通常将初始化代码至于其中。
- douban.py:最重要的部分,用于定义爬虫的行为,如数据处理、自动翻页、自动鉴权等。
- items.py:类似与一个容器,用于定义你所需数据。可以把它比购物清单,你要买什么事先可以在这里声明。
- middlewares.py(中间件):即Scrapy中下载器中间件的实现,用于处理Scrapy引擎与下载器之间的请求及响应。
- pipelines.py:用于处理从系统中流出的数据,如识别、储存方式等。
- settings.py:系统绝大部分的预置参数设置。
三、爬虫逻辑编码
经过上面的步骤,一个系统缺省的爬虫创建完毕。但是缺省的爬虫只是一个空壳,它不会完成任何实际的任务。我们还需要对它进行编码,让它能够满足我们的需求。
第一步:确定需求
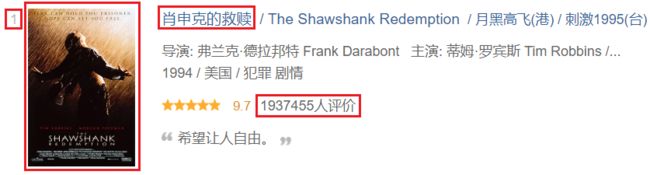
我们创建爬虫的目的是获取网页上的信息,在本项目中我们是要获取250部电影的序号、(中文)名称、图片地址以及评论数,最后按照顺序将他们输出到一个文本文件中。
第二步:设置容器(items.py)
从第一步我们确定了需要①序号、②电影名、③图片地址、④评价数这四个数据。因此,我们先打开items.py文件,定义这四个属性。代码如下:
class DoubanmovieItem(scrapy.Item):
# define the fields for your item here:
em = scrapy.Field() #序号
title = scrapy.Field() #标题
img = scrapy.Field() #图片路径
comment = scrapy.Field() #评论数
第三步:编写爬虫逻辑(douban.py)
在编写爬虫逻辑之前,我们必须先要明白网页上的信息是如何存放的,以及在python中如何解析和定位我们所下载的网页。网页解析有几种方法,Beautiful Soup、Xpath等。BeautifulSoup我放在之前的文章中,这里主要采用Xpath方法来解析并定位网页信息。
了解XPath
XPath 是一门在 XML 文档中查找信息的语言。因为HTML也是一种XML语言,因此Xpath当然可以应用于html页面。
基本语法:
1. 选取节点
XPath 使用路径表达式在 XML 文档中选取节点。节点是通过沿着路径或者 step 来选取的。 下面列出了最有用的路径表达式:
| 表达式 | 描述 |
|---|---|
| nodename | 选取此节点的所有子节点 |
| / | 从根节点选取 |
| // | 从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置 |
| . | 选取当前节点 |
| … | 选取当前节点的父节点 |
| @ | 选取属性 |
更高级的XPath语法可以去参考网上内容。
2.定位资源
在了解过XPath后,我们就可以在网页上精确地定位各类资源的位置了。
先打开豆瓣电影Top250网站, 页面空白处右键,选择“检查”。定位到每部电影的列表项处,应该是下面界面:
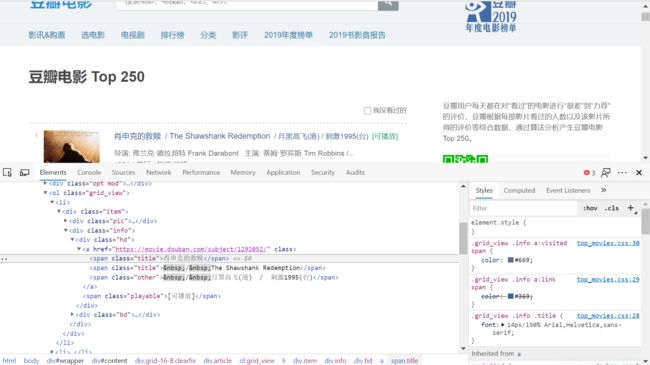
我们可以按照XPath语法,确定各项资源的路径。
如果xpath路径不太会写或者想节省时间,我们可以在浏览器的“检查”界面中,右键需要选取的资源,在“复制”子菜单中选择“复制XPath路径”。这样我们就可以方便地找到资源对应的XPath路径了。
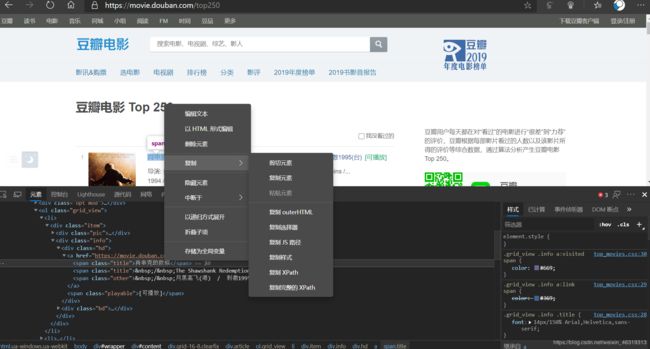
确定item中元素的XPath路径
这一步主要任务是赋予每个在前面item.py中定义的变量对应在HTML中的路径。我们打开douban.py文件,可以看见系统已经自动生成了类似于下面的代码框架:
# -*- coding: utf-8 -*-
import scrapy
from lxml import etree
from doubanmovie.items import DoubanmovieItem
class DoubanSpider(scrapy.Spider):
name = 'douban'
allowed_domains = ['movie.douban.com/top250']
start_urls = ['http://movie.douban.com/top250']
def parse(self, response):
pass
自动生成的代码中:
‘parse’函数的response参数是downloader模块传来的,里面包含了下载器下载下来的内容。我们就是在这里对这些内容进行操作。
name变量是表示这个爬虫的名称;
allowed_domains定义了爬虫爬取的范围,不属于这个域名下的页面不会被爬取;
start_urls定义了爬虫起始页面,爬虫从这个页面开始爬取。
在这里我们将allowed_domains设置为 ‘movie.douban.com/top250’,即从Top250的第一页开始。
设置好后,我们用一个变量接收response的文本数据。在这个过程中,response.text返回的是网页内容的字符串,因此,我们利用lxml包中的etree方法将response.text返回的字符串转换为带节点的html格式。
这是etree.HTML方法的说明:
HTML(text, parser=None, base_url=None)
Parses an HTML document from a string constant. Returns the root node (or the result returned by a parser target). This function can be used to embed “HTML literals” in Python code.
具体的代码如下:
def parse(self, response):
# print(response.text.encode('unco'))
html_text = etree.HTML(response.text)
li_list = html_text.xpath("//ol[@class='grid_view']/li")
for li in li_list:
item = DoubanmovieItem()
# em = title = img = comment
item['em'] = li.xpath(".//em/text()")[0]
item['title'] = li.xpath(".//span[@class='title']/text()")[0]
item['img'] = li.xpath(".//img/@src")[0]
item['comment'] = li.xpath(".//div[@class='star']/span/text()")[-1]
# yield返回当前电影的数据
# print("--item--", item)
yield item
【注】这里必须使用yield而不能使用return,因为框架必须获得每次爬取的item,这样最后才能拼接成一个完整的结果。
第四步:设置自动翻页
首先我们必须知道下一页的链接,它有可能是利用现有的链接进行拼接,因此我们要针对具体情况来分析。
我们在“后页”按钮上右键检查,可以看到后页的链接是本页链接加上一个"?start=XX&filter="。这样我们就可以得到下一页的链接:next_page = html_text.xpath("//span[@class='next']/a/@href")[0]
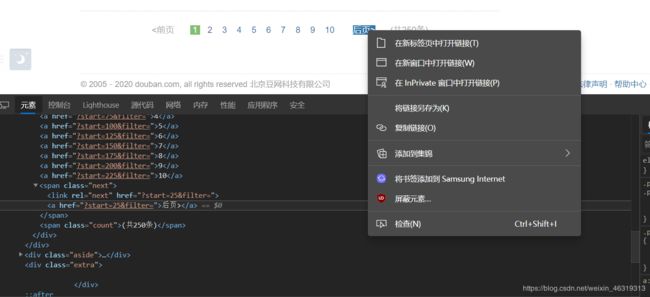
在知道下一页链接后,我们要手动发送请求,让爬虫去解析下一页的数据:
if self.next_page:
# 手动发送请求,让爬虫去解析下一页的数据
yield scrapy.Request('http://movie.douban.com/top250' + self.next_page,callback=self.parse,dont_filter=True)
【注意】scrapy.Request的参数中,dont_filter=True表示取消地址过滤。在我运行过程中,如果不加这个参数,爬虫在爬取下一页时,将会报
DEBUG: Filtered offsite request to ‘movie.douban.com’:
起初每次爬虫爬取完第一页后,就报这个错误,并且爬虫也停止爬取。因为提示不是ERROR,所以我并没有特别注意它,后来在网上一搜,发现这个是因为过滤器把下一页给过滤了,所以才导致爬完第一页就暂停了。
解决办法也很简单,就是在调用scrapy.Request时,加上dont_filter=True参数。
最后是douban.py的完整代码:
#douban.py
# -*- coding: utf-8 -*-
import scrapy
from lxml import etree
from doubanmovie.items import DoubanmovieItem
class DoubanSpider(scrapy.Spider):
name = 'douban'
allowed_domains = ['movie.douban.com/top250']
start_urls = ['http://movie.douban.com/top250']
next_page = ''
def parse(self, response):
# print(response.text.encode('unco'))
html_text = etree.HTML(response.text)
li_list = html_text.xpath("//ol[@class='grid_view']/li")
for li in li_list:
item = DoubanmovieItem()
# em = title = img = comment
item['em'] = li.xpath(".//em/text()")[0]
item['title'] = li.xpath(".//span[@class='title']/text()")[0]
item['img'] = li.xpath(".//img/@src")[0]
item['comment'] = li.xpath(".//div[@class='star']/span/text()")[-1]
# yield返回当前电影的数据
yield item
# 获取后页超链接的值 (xpath返回的是list)
self.next_page = html_text.xpath("//span[@class='next']/a/@href")[0]
print("--next_page--:" + self.next_page)
if self.next_page:
# 手动发送请求,让爬虫去解析下一页的数据
yield scrapy.Request('http://movie.douban.com/top250' + self.next_page, callback=self.parse,dont_filter=True)
第五步:设置输出方式
我们把爬虫逻辑编写好后,爬虫就可以按照我们的要求工作。但是我们通常需要把爬虫爬取的结果进行处理或保存,就像炼油厂把石油炼制后,要将石油装桶一样。这个步骤我们需要在pipelines.py中完成。
在官方文档中是这样描述pipelines.py用途的:
Typical uses of item pipelines are:
- cleansing HTML data
- validating scraped data (checking that the items contain certain fields)
- checking for duplicates (and dropping them)
- storing the scraped item in a database
item pipelines的常规用途为:
- 清理HTML数据
- 验证说爬取到的数据(确认items包含指定域)
- 验证数据重复性(并移除重复数据)
- 将爬取到的项目存入数据库
我们打开项目中的pipelines.py文件,可以发现在类下面有process_item(self, item, spider)方法,这个方法将会被每一个pipeline组建调用。其中item参数为(本次)爬取到的项,spider参数为当前爬虫。
在本项目中,我准备将每部电影的序号、标题、封面链接以及评论数依次写入一个文本文档,并将文本文档的名称设置为“豆瓣Top250”加上当前日期。
我们首先要引入time包,之后再获取当前时间并与“豆瓣Top250”拼接起来,最后再将item中的每个项目依次写入文件中。注意,write方法默认是不会换行的,数据将会紧接着之前的数据写入,因此我们要在每一部电影最好写入一个换行符“\n”。
这部分完整代码如下:
#pipelines.py
import time
class DoubanmoviePipeline(object):
def process_item(self, item, spider):
now = time.strftime('%Y-%m-%d', time.localtime())
fileName = '豆瓣250' + now + '.txt'
with open(fileName, 'a', encoding='utf-8') as fp:
fp.write(item['em']+': ')
fp.write(item['title']+' ')
fp.write(item['img']+' ')
fp.write(item['comment'])
fp.write('\n')
return item
第六步:相关设置
至此,我们已经几乎完成了一个爬虫的定义,我们最后要做的就是对爬虫进行最后的设置。设置主要有三部分:1,设置user-agent,让爬虫能够伪装成正常的访问请求;2,打开pipelines通道;3,选择是否遵循robots协议。
1. 设置user-agent
有些网站为了减少网站负担或其它原因,会设置反爬措施。如果监测到本次访问是非人类正常访问,可能会禁止本次访问或者设置真人验证。避免反爬的最基本的措施是设置一个普通的user-agent,这样让网站认为这次访问是由一个普通浏览器发出的。
打开“settings.py”,在里面找到DEFAULT_REQUEST_HEADERS字段,取消其注释状态,把它改为:
DEFAULT_REQUEST_HEADERS = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/82.0.4080.0 ' \
'Safari/537.36 Edg/82.0.453.2',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8,en-US;q=0.7',
'Cookie': 'bid="HgstQtgjnX8"; ap_v=0,6.0',
}
里面’User-Agent’是必须的,其余可选。
2. 打开pipeline通道
我们设置了pipelines.py后,还必须在settings.py中将ITEM_PIPELINES进行如下修改:
ITEM_PIPELINES = {
'myproject.pipelines.PricePipeline': 300
}
这样我们在pipelines.py中设置的操作才能实现。这个设置项的具体意义可以参考文档
3. 选择是否遵守robots协议
robots协议是网站在其根目录下放置的一个文本文件,其中规定了爬虫可以爬取的范围。一般来说,如果爬虫爬取速度与人类访问的速度没有特别大的差异的情况下,可以把这种爬虫视作人类行为。此时,我们可以选择不遵守robots规则。但如果爬虫是有商业目的或可能对网站造成过大的访问量,此时我们应该遵循网址的robots声明。如果不遵循robots声明可能会有法律风险。
我们在settings.py文件中的ROBOTSTXT_OBEY字段可以设置是否遵守网站robots协议,此项默认是False,即不遵守。
四、总结
本文首先简单介绍了Scrapy及其框架结构,随后安装配置Scrapy,最后针对豆瓣Top250网站进行实践。包含了user_agent伪装、pipeline输出、Xpath介绍以及自动翻页等特点,按照这个流程可以对一些基本的网站进行爬取。之后会继续对IP伪装、自动登陆、验证码绕过等特性进行学习。
写这篇文章的目的是为了记录学习Scrapy框架的过程中的感想以及一些要点,目前来说还是处于入门阶段,对Scrapy的使用也是十分基础的。欢迎各位大佬提出意见与建议,也欢迎像我一样的初学者共同学习进步。