Python3.8常用内置库总结
Python3.8常用内置库总结
- String模块总结与举例
- 字符串常量
- 自定义字符串格式化
- 方法一:formatter
- 1. 运用vformat或format来执行格式化:
- 2. 用parse来将字符串分解为文本字面值或替换字段
- 3. get_field
- 4. get_value
- 5. check_unused_args
- 方法二:Template
- 格式字符串语法
- 课外话:字符串内置常用函数
- itertools模块函数分类总结
- 过滤
- 运算和映射
- 合并
- 扩展
- 有限扩展
- 无限扩展
- 分组
- 课外补充
- Iterator,iterable和itertools的联系
- iterator和iterable
- 生成器和迭代器的区别
- 为什么使用生成器?
String模块总结与举例
总结的时候没发现,String模块已经是python2.x之后的过时模块了,很多关于str的方法都已经直接移植到str类里了,所以不推荐使用。。。现在有的几个方法也只是起到对自定义格式化方法的封存作用,用起来没有str类方法简单迅速。
另外,python中import的和标准库里的一般叫做模块,库是参考其他编程语言的说法。
字符串常量
| 序号 | 定义 | 常量 |
|---|---|---|
| 1 | string.ascii_lowercase | ‘abcdefghijklmnopqrstuvwxyz’ |
| 2 | string.ascii_uppercase | ‘ABCDEFGHIJKLMNOPQRSTUVWXYZ’ |
| 3 | string.ascii_letters | 小写所有字母+大写所有字母(序号1常量+序号2常量) |
| 4 | string.digits | ‘0123456789’ |
| 5 | string.hexdigits | ‘0123456789abcdefABCDEF’ |
| 6 | string.octdigits | ‘01234567’ |
| 7 | string.punctuation | C中的标点:’!"#$%&’()*+,-./:;<=>?@[]^_`{ |
| 8 | string.whitespace | 由被视为空白符号的 ASCII 字符组成的字符串 |
| 9 | string.printable | 由被视为可打印符号的 ASCII 字符组成的字符串(数字+小写所有字母+大写所有字母+punctuation+whitespace) |
自定义字符串格式化
方法一:formatter
Formatter是String库下的类,它包含有一系列公用方法。要使用这些方法首先先定义一个formatter:
- formatter = string.Formatter()
下面就是可以在formatter上运用的方法:(i.e.
formatter.method())
1. 运用vformat或format来执行格式化:
-
vformat(format_string, args, kwargs) 或
-
format(format_string,*args,**kwargs)
参数分别意思为:
format_string:需要去格式化的目标字符串(仅限位置参数);
args:位置参数序列;*args表示任意位置参数;
kwargs:关键字参数,字典。**kwargs表示任意关键字参数;
return:字符串
来看如下例子:
format 其实就是一个调用vformat的包装器,例子如下:
vformat: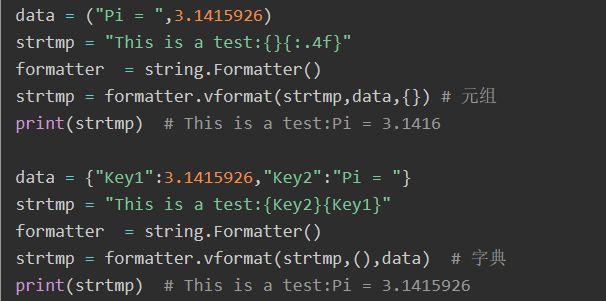
format: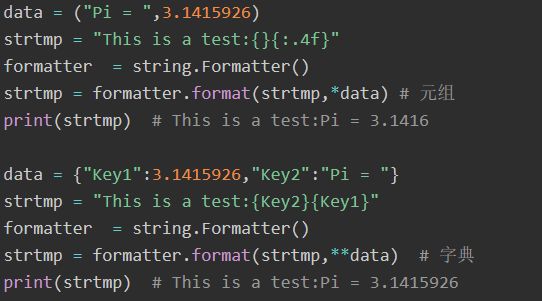
参考:https://www.jianshu.com/p/faaa48f4c511
2. 用parse来将字符串分解为文本字面值或替换字段
- parse(format_string)
循环遍历 format_string 并返回一个由可迭代对象组成的元组 (literal_text, field_name, format_spec, conversion)。如果没有替换字段则后三位为None。
元组元素解释:
literal_text:文本;如果没有就是长度为0的字符串’’;
field_name:替换字段的命名;我理解的是位置参数无命名,所以都是’’;
format_spec: 替换字段格式
conversion:转换类型
例子:
data = ("Pi = ",123.1415926, " is true.")
strtmp = "This
is a test: {}{:.2f}{}"
formatter = string.Formatter()
strtuple = formatter.parse(strtmp)
for i, v in enumerate(strtuple):
print(i, v)
"""0 ('This is a test: ', '', '',
None)
1 ('', '', '.2f', None)
2 ('', '', '', None)"""
3. get_field
- get_field(field_name, args, kwargs)
给定
field_name(parse的返回值),找到要格式化的对象。 返回一个元组 (obj, used_key)。args和kwargs是和vformat的输入一样的。
data2 = {"key2":
"Pi2 = ",
"key1" :
123.1415926,
"key3" :
" 2is true."}
strtmp2 = "This
is a test: {key2}{key1:.2f}{key3}"
ftuple = formatter.get_field("key1",(),data2)
print(ftuple)
"""(123.1415926,
'key1')"""
4. get_value
- get_value(key, args, kwargs)
提取给定的字段值。key
参数将为整数或字符串。 如果是整数,它表示 args 中位置参数的索引;如果是字符串,它表示 kwargs 中的关键字参数名。
data = ("Pi = ",123.1415926, " is true.")
formatter = string.Formatter()
v = formatter.get_value(2,data,{})
print(v)
""" is true."""
5. check_unused_args
- check_unused_args(used_args, args, kwargs)
在必要时实现对未使用参数进行检测,参数都很好懂,used_args就是格式字符串中实际引用的所有参数键的集合(整数表示位置参数,字符串表示名称参数)。
方法二:Template
通过string.Template可以为Python定制字符串模板,是相比于formatter更常用点的方法,语法也更好理解:
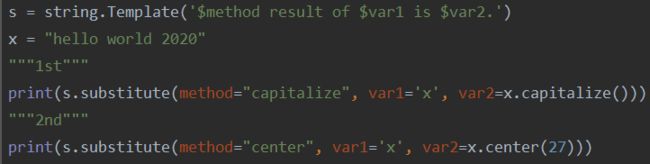
语法相比于formatter更好理解。
格式字符串语法
str.format() 方法和
Formatter 类共享相同的格式字符串语法。值得注意的一点是conversion:
使用 conversion 字段在格式化之前进行类型强制转换。
通常,格式化值的工作由值本身的 format() 方法来完成。
但是,在某些情况下最好强制将类型格式化为一个字符串,覆盖其本身的格式化定义。 通过在调用 format()
之前将值转换为字符串,可以绕过正常的格式化逻辑。 目前支持的转换旗标有三种: ‘!s’ 会对值调用 str(),’!r’ 调用 repr(),而 ‘!a’ 则调用 ascii()。
`"Harold's a clever {0!s}" # Calls str() on the argument first
"Bring out the holy {name!r}" # Calls repr() on the argument first
"More {!a}" # Calls ascii() on the argument first`
课外话:字符串内置常用函数
这和python模块无关,是属于类型内置方法范围了,但是由于和string关联比较大,也在这里总结一下。由此也可以看出类方法可以实现的在字符串上的操作丰富得多,而string模块则显得晦涩难用。这也是python一步步改进后的成果,把更多常用方法对象化,而不需要再引入模块。
-
str.capitalize():大写首字母
-
str.center(width):生成长度为width的字串,其中str居中
-
str.count(char):计算char出现次数
-
str.find(char):找到char出现的index
-
str.partition(char): 把字符串切片并生成元组(char之前,char,char之后)
-
str.replace(old_char,new_char):替换所有old为new
-
str.split(char): 把字符串按char断开,除去char生成list
-
str.splitlines():按行断开(“\n”)
-
str.strip(str2):去掉头和尾包含有str2的字符,到第一个非str2里的char为止
-
str.join():把str和str结合(eg:
s1.join(s2)意思是每个s2的元素都被s1隔开:s1=‘abc’,s2=‘123’,s1.join(s2)=‘1abc2abc3’
)或者str和str类型的list/tuple/dictionary交叉结合为一个新的字符串。(字典key必须为string类型)
例子:

结果如下:
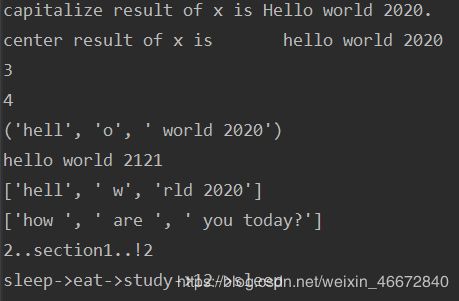
(另附一个小技巧:把一个字符串逆向print)
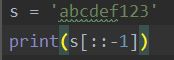
![]()
itertools模块函数分类总结
为高效循环而创建迭代器的函数。这些函数返回的都是迭代器对象,用list()可以变为列表。
过滤
根据输入的元素按条件过滤提取出一部分元素。
| 函数 | 定义 | 例子 |
|---|---|---|
| dropwhile(pred, seq) | 把 seq 中的各个元素传给 pred 【布尔函数】,产出第一个 | |
| pred(item)==false的元素及之后的元素(之后不再检查) | dropwhile(lambda x: x<5, [1,4,6,4,1]) --> 6 4 1 | |
| filterfalse(pred, seq) | 返回seq中pred(x)为假值的元素,x是seq中的元素。 | filterfalse(lambda x: x%2, range(10)) --> 0 2 4 6 8 |
| islice(seq, [start,] stop [, step]) | seq[start:stop:step]中的元素(start,stop,step必须是正整数) | islice(‘ABCDEFG’, 2, None) --> C D E F G |
| takewhile(pred, seq) | 返回pred(x)==true的元素,直到pred真值测试失败(之后不再检查) | takewhile(lambda x: x<5, [1,4,6,4,1]) --> 1 4 |
| compress(data, selectors) | 并行处理两个可迭代的对象;如果selectors 中的元素是真值,产出data 中对应的元素 | compress(‘ABCDEF’, [1,0,1,0,1,1]) --> A C E F |
运算和映射
在输入的元素上进行运算或映射后产出结果。
| 函数 | 定义 | 例子 |
|---|---|---|
| accumulate(p [,func]); func=无(默认求和)/min/max/operator.mul(乘积) | 产出累积的总和; 如果提供了func,那么返回func(x, | |
| x+1)结果并把这个结果传给下个元素,以此类推,最后产出结果 | accumulate([1,2,3,4,5]) --> 1 3 6 10 15; accumulate([1,2,3,4,5],min) --> 1 1 1 1 1 | |
| starmap(func, seq) | 把seq里每个元素传给func,对应产出一个结果 | starmap(pow, [(2,5), (3,2), (10,3)]) --> 32 9 1000 |
合并
输入多个可迭代对象,产出一个合并的可迭代对象。chain 和 chain.from_iterable 按顺序(一个接一个)处理输入的可迭代对象;product和 zip_longest 并行处理输入的各个可迭代对象。
| 函数 | 定义 | 例子 |
|---|---|---|
| chain(p,q…) | 分解p,q…中单个元素并合并 | chain(‘ABC’, ‘DEF’) --> A B C D E F |
| chain.from_iterable(iterable) | 可迭代对象iterable中各个元素分解合并 | chain.from_iterable([‘ABC’, ‘DEF’]) --> A B C D E F |
| product(p, q, … [repeat=1]) | 笛卡尔积,相当于嵌套的for循环 | product(‘ABCD’, repeat=2) --> AA AB AC AD BA BB BC BD CA CB CC CD DA DB DC DD (repeat=2相当于product(‘ABCD’, ‘ABCD’)= ‘ABCD’ X ‘ABCD’) |
| zip_longest(p, q, …) | (p[0], q[0]), (p[1], q[1]), … | zip_longest(‘ABCD’,‘xy’, fillvalue=’-’) --> Ax By C- D- |
扩展
从一个元素中衍生出一系列元素的函数。
有限扩展
| 函数 | 定义 | 例子 |
|---|---|---|
| permutations(p,[r]) | 从p的所有元素中选取r个不同元素组成新的元素合集 | permutations(‘ABCD’,2) --> AB AC AD BA BC BD CA CB CD DA DB DC |
| combinations(p,r) | 从p的所有元素中选取r个不同元素组成新的元素合集,有序(从左往右),无重复元素 | combinations(‘ABCD’, 2) --> AB AC AD BC BD CD |
| combinations_with_replacement(p,r) | 和上面不同的只有可重复选取同一个元素r次 | combinations_with_replacement(‘ABCD’, 2)–>AA AB AC AD BB BC BD CC CD DD |
无限扩展
| 函数 | 定义 | 例子 |
|---|---|---|
| count(start,[step]) | 从start开始每次增进1(或step)的无穷数列 | count(10)–>10 11 12 13 14… |
| cycle§ | 无限循环输入的每个单个元素 | cycle(‘ABCD’) -->A B C D A B C D… |
| repeat(elem,[n]) | 无限(或有限n次)循环elem | repeat(10,3)–>10 10 10 |
分组
| 函数 | 定义 | 例子 |
|---|---|---|
| groupby(iter,[key]) | 根据key分组iter(或将连续相同的元素分为一组) | [k for k, g in groupby(‘AAAABBBCCDAABBB’)] --> A B C D A B; [list(g) for k, g in groupby(‘AAAABBBCCD’)] --> AAAA BBB CC D |
课外补充
Iterator,iterable和itertools的联系
iterator和iterable
迭代器和可被迭代,是两个不同的概念。Python中 list,truple,str,dict这些都可以被迭代,但他们并不是迭代器。因为迭代器可以被迭代无数次,我们不知道有多少个元素,而这些数据大小都是有限的。我们可以用isinstance来判断:
from collections import Iterable
isinstance({},Iterable) -->True
isinstance({}, Iterator) -->False iterable用for循环,iterator用next(),而iterable可以通过iter()函数转化成Iterator对象,for的本质也是用next实现的:先通过iter()函数获取可迭代对象Iterable的迭代器,然后对获取到的迭代器不断调用next()方法来获取下一个值并将其赋值给item,当遇到StopIteration的异常后循环结束。
生成器和迭代器的区别
迭代器适用于迭代操作的对象,它像列表一样可以迭代获取其中的每一个元素,但与列表不同的是,构建迭代器的时候它不是把所有元素一次性加载到内存,而是用一种延迟计算(调用next()才会返回)的方式返回元素,对内存很友好。
生成器是一种特殊的迭代器,有着一样的特性(按需调用),但只能遍历一次,在实现方式上更加简洁。
分类:
1.生成器函数:使用 def 定义函数,但是,使用yield而不是return语句返回结果。yield语句一次返回一个结果,在每个结果中间,挂起函数的状态,以便下次从它离开的地方继续执行。
2. 生成器表达式:类似于列表推导,只不过是把一对大括号[]变换为一对小括号()。但是,生成器表达式是按需产生一个生成器结果对象,要想拿到每一个元素,就需要循环遍历。
为什么使用生成器?
因为效率。
使用生成器表达式取代列表推导式可以同时节省 cpu 和 内存(RAM)。
如果你构造一个列表(list)的目的仅仅是传递给别的函数,比如 传递给tuple()或者set(), 就可以用生成器表达式替代。
data=[2,3,4,5]
k=tuple(a for a in data)
print(k)
#结果是:
(2, 3, 4, 5)