Python爬虫-图片篇(1)初学乍练
文章目录
- 1. python爬虫基本功
- 1.1 requests
- 1.2 lxml(lxml.etree.HTML().xpath)
- 1.3 tqdm
- 1.4 os 路径、文件操作
- 2. 爬虫程序分析
- 3.知识点总结
- 4. troubleshooting
- 4.1 xpath不会写怎么办
1. python爬虫基本功
- 图片爬虫是学习其他爬虫的基础,如果掌握了一下几个常用库,和下面图片爬虫的实战程序,就可以轻松搭建其它更加复杂的爬虫任务。当然,如果你只是想爬取整个网站的所有图片,直接复制本文程序,也可以不用任何修改,获取到大量图片数据,以供后续研究学习使用。
- 以后补充如下几个工具包的使用方法,和相关链接。如果已经有相关基础的读者可以直接跳过,阅读第二部分
1.1 requests
1.2 lxml(lxml.etree.HTML().xpath)
XPath 是一门在 XML 文档中查找信息的语言。XPath 可用来在 XML 文档中对元素和属性进行遍历。本文作为图片爬虫,只使用到lxml中最基本的方法,利用xpath定位。下面几个教程可以用来学习xpath
- W3School中Xpath教程
1.3 tqdm
Tqdm 是一个快速,可扩展的Python进度条,可以在 Python 长循环中添加一个进度提示信息,用户只需要封装任意的迭代器 tqdm(iterator)。
总之,它是用来显示进度条的,很漂亮,使用很直观(在循环体里边加个tqdm),而且基本不影响原程序效率。名副其实的“太强太美”了!这样在写运行时间很长的程序时,是该多么舒服啊!
- tqdm官方网站
- GitHub仓库
使用方法
from tqdm import tqdm
import time
# 直接对数据进行操作
for i in tqdm(range(10000)):
time.sleep(0.1)
urls= ['A','B','C','D','F']
pbar = tqdm(urls)
for url in pbar:
pbar.set_description("Processing %s" % url)
time.sleep(1)
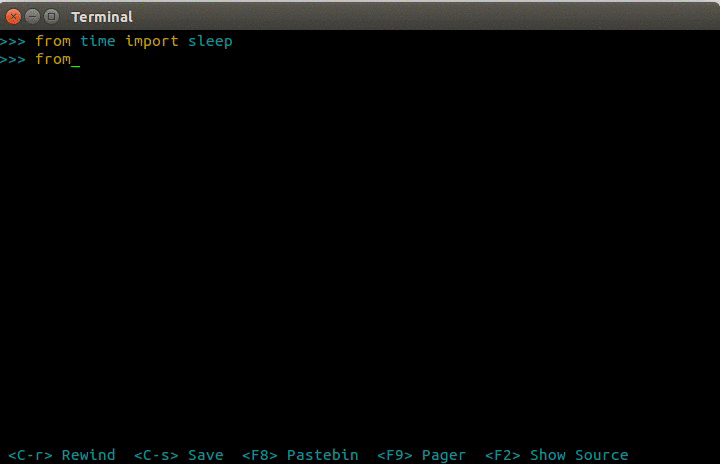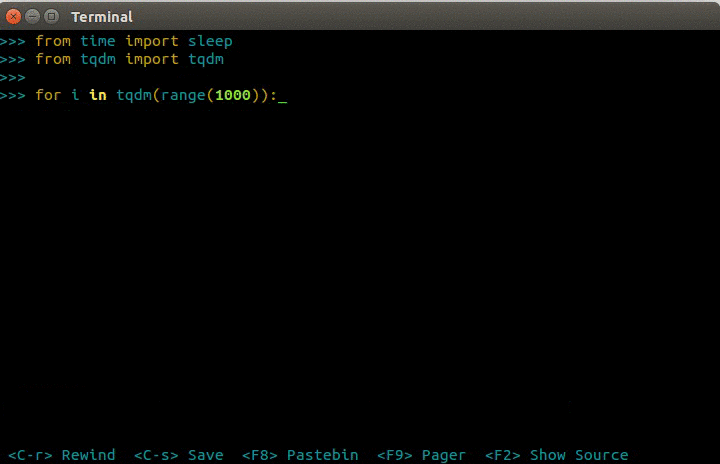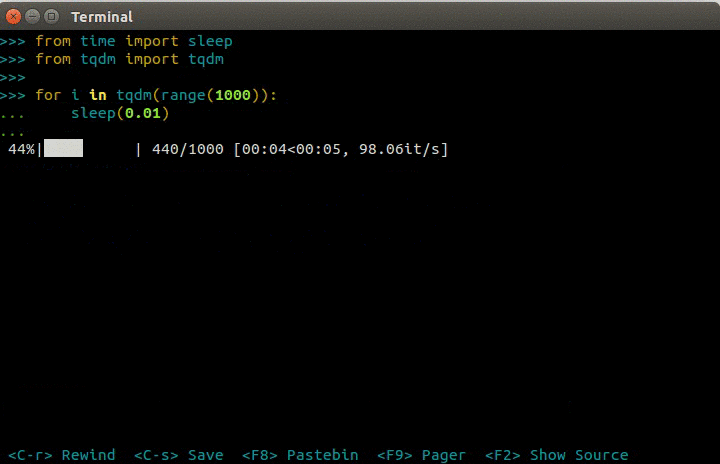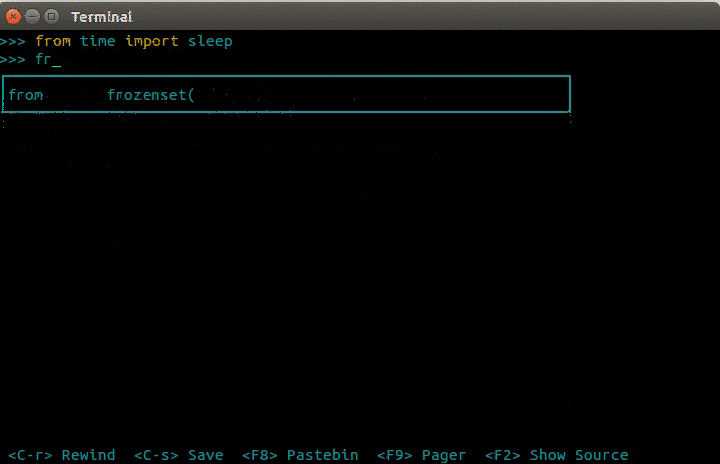
更多使用方法请移步官方网站
1.4 os 路径、文件操作
2. 爬虫程序分析
先给出程序源码,程序可以在没有任何修改的情况下,直接复制使用。
#!usr/bin/env python
#-*- coding:utf-8 -*-
"""
@author:CHERN
@file: spider_goddess.py
@time: 2020/04/27
"""
# https://tw.kissgoddess.com/
# requests应该就可以直接爬
import requests
import os
from lxml import etree
import json
from tqdm import tqdm
import random
import time
'''
这个网站的内容爬取自.现在域名为
该网站爬虫技术不过关,导致挂在网上的图片有一些就是父网站防止盗链的图片如https://tw.kissgoddess.com/album/32711.html
'''
# 获取一个连接(图片集)中所有页url,也包含它本身-
def get_all_pages_url(url):
print("Getting all page urls of album...")
urlset = set([])
while True:
urlsetlen = len(urlset)
r = requests.get(url)
page = etree.HTML(r.text)
urls = page.xpath('//*[@id="pages"]/a/@href')
urls = urls[0:-1] #urls最后一项是当前页,包含在其中,所以删掉
for u in urls:
urlset.add(u)
url = 'https://tw.kissgoddess.com'+urls[-1]
if urlsetlen == len(urlset):
print("There exists " + str(len(urlset)) + ' pages in this album.')
return list(urlset)
# 下载给定页面中的所有图片,输入时一个URL,和指定路径
def download_image_in_page(url,path):
# 首先获取到页面重所有图片的URL
r = requests.get(url)
page = etree.HTML(r.text)
img_urls = page.xpath('//*[@id="td-outer-wrap"]/div[2]/div/div[2]/div/div/article/div[2]/img/@src')
entry_title = page.xpath('//*[@id="td-outer-wrap"]/div[2]/div/div[2]/div/div/article/div[1]/header/h1/text()')
for img_url in img_urls:
dir = path + str(entry_title[-1].replace('?',' ').replace('|',' '))
# 判断需要下载的图片是否存在,如果存在就进入下一张图片url
if os.path.exists(dir + '/' + img_url.split('/')[-1]):
continue
if not os.path.exists(dir):
print('Creating folder...')
os.makedirs(dir)
img = requests.get(img_url).content
with open(dir + '/' + img_url.split('/')[-1], 'wb+') as f:
f.write(img)
return dir + '/'
# 给出一个相册集的URL,下载该URL对应作品集album中所有图片
# 传入的url需要是绝对路径
def download_all_image_by_album(url,path):
print("="*30)
print("Downloading album.. URL: " + url)
urls = get_all_pages_url(url)
pbar = tqdm(urls)
for url in pbar:
pbar.set_description("Processing %s" % url)
result = download_image_in_page("https://tw.kissgoddess.com/"+url, path)
print("Download album successfully. Go to folder:"+ result)
return result
# 给出一个人的主页面https://tw.kissgoddess.com/people/li-yan-xi.html,下载它的所有作品,即所有albums中的所有图片,每个albums一个文件夹
def download_all_image_by_mainpage(url,path):
page = etree.HTML(requests.get(url).text)
# 可以在此处解析其他信息,如本站排名,体重,出生日期,星座等
albums = page.xpath('// *[ @ id = "divAlbum"] / div / div / a/@href')
print(url.split('/')[-1][0:-5]+"一共有"+str(len(albums))+"照片集")
for album in albums:
url = 'https://tw.kissgoddess.com' + album
result = download_all_image_by_album(url,path)
# 没有找到获取所有任务主页的方法
def get_all_mainpages():
pass
# http://tw.kissgoddess.com/gallery/ 获取所有album的url.注意这是相对路径,不可以直接get().需要拼接https://tw.kissgoddess.com
# 可以获得900个url,以供下载。每个album大小为6MB左右。全部下载预计5.27GB
# range(1,31)是测试数据,内容可能会随着网站更新而变大
def get_all_albums_url():
albums = []
for i in tqdm(range(1,31)):
url = "http://tw.kissgoddess.com/gallery/" + str(i) + ".html"
page = etree.HTML(requests.get(url).text)
alb = page.xpath('//*[@id="td-outer-wrap"]/div[2]/div/div/div[2]/div/div/article/div[1]/div[3]/div/div/div/a/@href')
albums = albums + alb
return albums
domain = 'https://tw.kissgoddess.com'
if __name__ == '__main__':
# 下载单个相册测试
# urls = ["https://tw.kissgoddess.com/album/32321.html"]
# for url in urls:
# download_all_image_by_album(url,'F:/imagedownload/goddess/')
# 下载个人所有相册测试
# people_mainpage = "https://tw.kissgoddess.com/people/park-soo-neul.html"
# download_all_image_by_mainpage(people_mainpage,'F:/imagedownload/goddess/')
# 下载所有相册测试
# 下面程序段,需要运行很长时间,取消注释请谨慎...
print("-" * 30)
print("Downloading all albums' url..")
albums = get_all_albums_url()
print("FBI warning: So many albums need to be downloaded...: " + str(len(albums)) + " items")
print("Continue downloading and we will assume that you have understood the operation")
print("-"*30)
print('Downloading all albums...')
for album in albums:
download_all_image_by_album(domain+album, 'F:/imagedownload/godd/')
| **download_image_in_page()函数讲解** |
r = requests.get(url)
page = etree.HTML(r.text)
接下来我们就可以通过xpath获取页面重的制定元素,标签,属性等。xpath需要一个xpath语法的字符串来提取页面中制定内容。xpath语法教程可以在上面提供的连接中学习。如果对xpath不熟悉,也可以通过浏览器F12功能键,直接复制得到。下面通过查看网页内容,获取图片url列表,和标题(用作文件夹名)
img_urls = page.xpath('//*[@id="td-outer-wrap"]/div[2]/div/div[2]/div/div/article/div[2]/img/@src')
entry_title = page.xpath('//*[@id="td-outer-wrap"]/div[2]/div/div[2]/div/div/article/div[1]/header/h1/text()')
获取到图片url之后,我们就可以再次使用requests.get()方法,把图片下载到本地了。
for img_url in img_urls:
# 获取到的标题中可能包含某些特殊字符(?,|,等),在Windows操作系统下无法新建文件夹
# 这里是直接替换为空格处理
dir = path + str(entry_title[-1].replace('?',' ').replace('|',' '))
# 判断需要下载的图片是否存在,如果存在就进入下一张图片url
if os.path.exists(dir + '/' + img_url.split('/')[-1]):
continue
# 判断存放图片的文件夹是否存在,如果不存在,就直接创建
# 注意,使用os.makedirs()是为了防止其父文件夹不存在
if not os.path.exists(dir):
print('Creating folder...')
os.makedirs(dir)
# requests.get()获取图片内容,然后写入文件中
img = requests.get(img_url).content
with open(dir + '/' + img_url.split('/')[-1], 'wb+') as f:
f.write(img)
| **get_all_pages_url()函数讲解** |

有了上面两个函数,接下来的思路就比较清晰了。我们可以封装一个函数,传入相册集首页地址,把该相册集所有图片都下载下来,也就是函数download_all_image_by_album()
| download_all_image_by_album() |
urls = get_all_pages_url(url)
for url in urls:
result = download_image_in_page("https://tw.kissgoddess.com/"+url, path)
封装的层次越来越高了。我们现在下载图片,可以通过调用download_all_image_by_album()函数来实现,这个函数实现之后,就可以把一个album看作是最小单位。我们以后下载任何图片,都调用这个函数。
网站上,有个人主页的页面,例如https://tw.kissgoddess.com/people/duan-xiao-hui.html,在这个页面中,有她所有相册集,通过之前的学习,可不可以解析她所有的相册集,然后下载呢?答案是可以。也就是下面的函数。download_all_image_by_mainpage()
| download_all_image_by_mainpage() |
def download_all_image_by_mainpage(url,path):
page = etree.HTML(requests.get(url).text)
# 可以在此处解析其他信息,如本站排名,体重,出生日期,星座等
albums = page.xpath('// *[ @ id = "divAlbum"] / div / div / a/@href')
for album in albums:
url = 'https://tw.kissgoddess.com' + album
download_all_image_by_album(url,path)
能够下载单个人所有相册集了,我们可以获取到网站上所有人的主页吗?这个网站我也没有仔细研究过,所以没办法回答。这个就当是给观众留个作业。感兴趣的可以试一试,看看哪个入口可以提取。
该网站的资源其实是获取自nvshens.net,所以它只提供了排行榜在前900的相册集页面(不清楚这是不是网站的全部家底,应该不是)。我们下面解析这个页面,获取这900个相册集的URL
| get_all_albums_url() |
# http://tw.kissgoddess.com/gallery/ 获取所有album的url.
# 注意这是相对路径,不可以直接get().需要拼接https://tw.kissgoddess.com
# 可以获得900个url,以供下载。每个album大小为6MB左右。全部下载预计5.27GB
# range(1,31)是测试数据,内容可能会随着网站更新而变大
def get_all_albums_url():
albums = []
for i in tqdm(range(1,31)):
url = "http://tw.kissgoddess.com/gallery/" + str(i) + ".html"
page = etree.HTML(requests.get(url).text)
alb = page.xpath('//*[@id="td-outer-wrap"]/div[2]/div/div/div[2]/div/div/article/div[1]/div[3]/div/div/div/a/@href')
albums = albums + alb
return albums
以上就是一个完整的图片爬虫基本框架。如果要提高速度,可以通过多线程等方式实现。这篇文章就不扩展了。主要是怕稀释爬虫技术知识,分不清主次。读者可以自行学习多线程知识,在此基础上进行扩展。
3.知识点总结
- 列表
list()内容可以重复,set([])表示集合对象,内容可以去重- 获取标签属性内容,可以通过xpath
//*[@id="pages"]/a/@href来获取html中属性内容,即www.baidu.com- 获取标签内容,可以通过xpath
//*[@id="pages"]/a/text()来获取- 创建文件夹通过
os.mkdir("c:\father\son")时,需要保证c:\father已经存在,才能成功创建son子文件夹,否则会报错。如果无法保证father文件夹存在,可以使用os.makedirs("c:\father\son")来完成。函数的功能是,如果路径不存在,就创建路径,并创建最后的文件夹- 这个网站的数据来源是
,由于上述网站爬虫封锁,该爬虫会下载到防盗链图片,这和程序无关。为了验证,可以把爬到的url放到浏览器中查看,依然是盗链图片 - 程序没有实现多线程
- 程序由于网络环境等问题,会出现下载缓慢的情况
4. troubleshooting
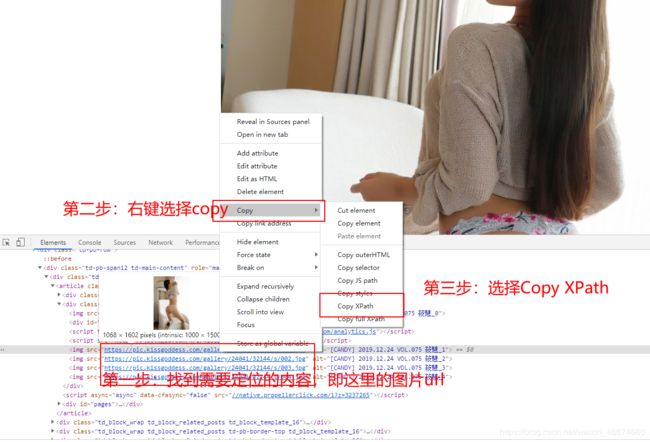
4.1 xpath不会写怎么办
在浏览器中打开网页,如http://www.xinhuanet.com/politics/leaders/xijinping/index.htm,按F12进入开发者模式

鼠标悬停在相关element上,网页上会显示其在页面中显示范围

右键,复制,复制xpath即可