elasticsearch ingest-attachment 对于 word、pdf等文件内容的索引
【转】ElasticSearch 全文检索实战
【转】ElasticSearch 5.3 载入PDF数据
1.简介
ElasticSearch只能处理文本,不能直接处理文档。要实现 ElasticSearch 的附件导入需要以下两个步骤:
一、对多种主流格式的文档进行文本抽取。
二、将抽取出来的文本内容导入 ElasticSearch。
Ingest-Attachment是一个开箱即用的插件,替代了较早版本的Mapper-Attachment插件,使用它可以实现对(PDF,DOC等)主流格式文件的文本抽取及自动导入。
Elasticsearch5.x 新增一个新的特性 Ingest Node,此功能支持定义命名处理器管道 pipeline,pipeline中可以定义多个处理器,在数据插入 ElasticSearch 之前进行预处理。而 Ingest Attachment Processor Plugin 提供了关键的预处理器 attachment,支持自动对入库文档的指定字段作为文档文件进行文本抽取,并将抽取后得到的文本内容和相关元数据加入原始入库文档。
由于 ElasticSearch 是基于 JSON 格式的文档数据库,所以附件文档在插入 ElasticSearch 之前必须进行 Base64 编码。
以下使用 REST API 调用方式。
2.环境
ElasticSearch 5.3.0
ElasticSearch-head-master插件 (安装指路 Elasticsearch学习--elasticsearch-head插件安装)
Ingest-attachment插件 (官方介绍 Ingest Attachment Processor Plugin)
Cygwin (curl+perl)
3.实现步骤
3.1 建立自己的文本抽取管道pipeline
curl -X PUT "localhost:9200/_ingest/pipeline/attachment" -d '{
"description" : "Extract attachment information",
"processors":[
{
"attachment":{
"field":"data",
"indexed_chars" : -1,
"ignore_missing":true
}
},
{
"remove":{"field":"data"}
}]}'3.2 创建新的索引
此处索引名为estest。
curl -X PUT “localhost:9200/estest” -d’{
“settings”:{
“index”:{
“number_of_shards”:1,
“number_of_replicas”:0
}}}’
3.3 载入数据
方法一:直接载入base64源码
首先要确定base64编码正确,否则因为乱码可能无法正确生成attachment。
可在 http://encode.urih.com/ 和 http://decode.urih.com/ 先进行编解码测试。
这里: index-pdftest type-pdf id-1 皆为自定义
curl -X PUT "localhost:9200/pdftest/pdf/1?pipeline=attachment" -d '
{
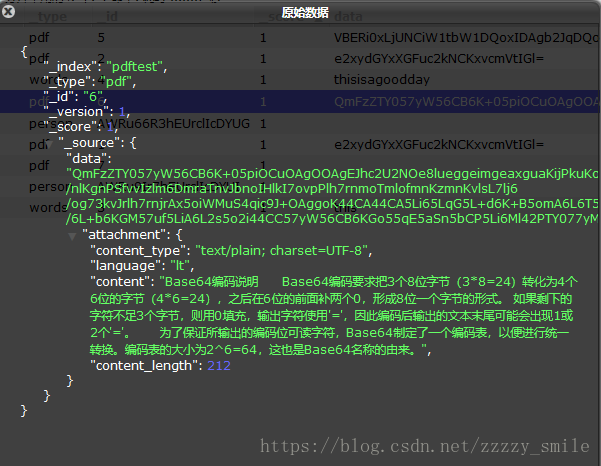
"data":"QmFzZTY057yW56CB6K+05piOCuOAgOOAgEJhc2U2NOe8lueggeimgeaxguaKijPkuKo45L2N5a2X6IqC77yIMyo4PTI077yJ6L2s5YyW5Li6NOS4qjbkvY3nmoTlrZfoioLvvIg0KjY9MjTvvInvvIzkuYvlkI7lnKg25L2N55qE5YmN6Z2i6KGl5Lik5LiqMO+8jOW9ouaIkDjkvY3kuIDkuKrlrZfoioLnmoTlvaLlvI/jgIIg5aaC5p6c5Ymp5LiL55qE5a2X56ym5LiN6LazM+S4quWtl+iKgu+8jOWImeeUqDDloavlhYXvvIzovpPlh7rlrZfnrKbkvb/nlKgnPSfvvIzlm6DmraTnvJbnoIHlkI7ovpPlh7rnmoTmlofmnKzmnKvlsL7lj6/og73kvJrlh7rnjrAx5oiWMuS4qic9J+OAggoK44CA44CA5Li65LqG5L+d6K+B5omA6L6T5Ye655qE57yW56CB5L2N5Y+v6K+75a2X56ym77yMQmFzZTY05Yi25a6a5LqG5LiA5Liq57yW56CB6KGo77yM5Lul5L6/6L+b6KGM57uf5LiA6L2s5o2i44CC57yW56CB6KGo55qE5aSn5bCP5Li6Ml42PTY077yM6L+Z5Lmf5pivQmFzZTY05ZCN56ew55qE55Sx5p2l44CC"
}'载入结果显示:(这一版data数据尚未删除)
方法二:载入PDF的同时进行转码导入
首先跳转至指定文件目录
这里我的文件ABC.pdf放在目录D:\ElasticSearch\File下
cd D:/ElasticSearch/File
使用perl脚本的解码功能:
“’base64 -w 0 ABC.pdf | perl -pe's/\n/\\n/g'‘”
完整代码:
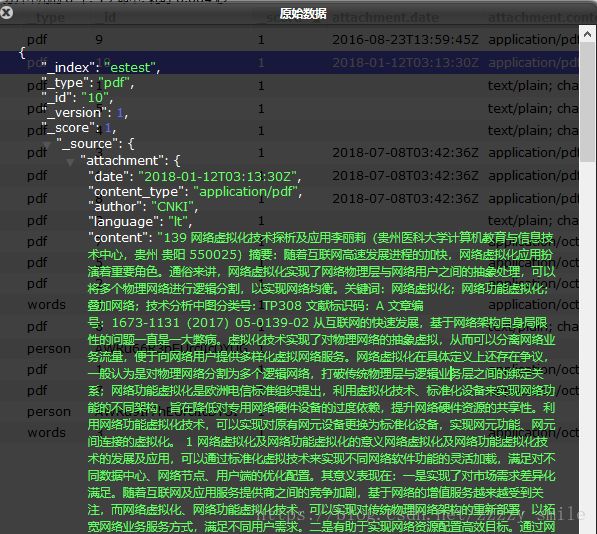
curl -X PUT "localhost:9200/estest/pdf/10?pipeline=attachment" -d '
{
"data":" '`base64 -w 0 ABC.pdf | perl -pe's/\n/\\n/g'`' "
}'结果如图,可以导入成功:
全文索引,查询指定字段
注意查询字段名称,这个真的纠结了我太久……
curl -X POST "localhost:9200/pdftest/pdf/_search?pretty" -d '{
"query":{
"match":{
"attachment.content":"编码"
}}}'查询结果:
total=1 意为找到一个,由此验证字段可查询。
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"failed" : 0
},
"hits" : {
"total" : 1,
"max_score" : 1.0446626,
"hits" : [
{
"_index" : "pdftest",
"_type" : "pdf",
"_id" : "6",
"_score" : 1.0446626,
"_source" : {
"data" : "QmFzZTY057yW56CB6K+05piOCuOAgOOAgEJhc2U2NOe8lueggeimgeaxguaKijPkuKo45L2N5a2X6IqC77yIMyo4PTI077yJ6L2s5YyW5Li6NOS4qjbkvY3nmoTlrZfoioLvvIg0KjY9MjTvvInvvIzkuYvlkI7lnKg25L2N55qE5YmN6Z2i6KGl5Lik5LiqMO+8jOW9ouaIkDjkvY3kuIDkuKrlrZfoioLnmoTlvaLlvI/jgIIg5aaC5p6c5Ymp5LiL55qE5a2X56ym5LiN6LazM+S4quWtl+iKgu+8jOWImeeUqDDloavlhYXvvIzovpPlh7rlrZfnrKbkvb/nlKgnPSfvvIzlm6DmraTnvJbnoIHlkI7ovpPlh7rnmoTmlofmnKzmnKvlsL7lj6/og73kvJrlh7rnjrAx5oiWMuS4qic9J+OAggoK44CA44CA5Li65LqG5L+d6K+B5omA6L6T5Ye655qE57yW56CB5L2N5Y+v6K+75a2X56ym77yMQmFzZTY05Yi25a6a5LqG5LiA5Liq57yW56CB6KGo77yM5Lul5L6/6L+b6KGM57uf5LiA6L2s5o2i44CC57yW56CB6KGo55qE5aSn5bCP5Li6Ml42PTY077yM6L+Z5Lmf5pivQmFzZTY05ZCN56ew55qE55Sx5p2l44CC",
"attachment" : {
"content_type" : "text/plain; charset=UTF-8",
"language" : "lt",
"content" : "Base64编码说明\n Base64编码要求把3个8位字节(3*8=24)转化为4个6位的字节(4*6=24),之后在6位的前面补两个0,形成8位一个字节的形式。 如果剩下的字符不足3个字节,则用0填充,输出字符使用'=',因此编码后输出的文本末尾可能会出现1或2个'='。\n\n 为了保证所输出的编码位可读字符,Base64制定了一个编码表,以便进行统一转换。编码表的大小为2^6=64,这也是Base64名称的由来。",
"content_length" : 212 }
}
}
]
}
}5.参考目录
convert the file into base64 in elasticsearch for attachment
ElasticSearch 全文检索实战
elasticsearch使用附件进行中文检索,无法查询中文的问题
Getting error while parsing documents
Sending Attachments: Unexpected end-of-input in VALUE_STRING
How to index a pdf file in Elasticsearch 5.0.0 with ingest-attachment plugin?
6.想法
其实流程走下来还挺简单,但当时小白入门,我还是困扰了挺久的,查阅各路资料最终成功导入。虽然也不厉害,但还是记录一下,缕清整个流程,希望能帮到大家 。^_^
一、概述
Elasticsearch 是一个分布式的 RESTful 风格的搜索和数据分析引擎,它基于 Lucene 实现了强大的全文检索功能。本文针对一个通用的应用场景,讲解如何利用 ElasticSearch 快速实现对关系型数据库文本和常见文档格式附件的全文检索。
二、应用场景
描述
数字图书馆有一套基于 MySQL 的电子书管理系统,电子书的基本信息保存在数据库表中,书的数字内容以多种常见的文档格式(PDF、Word、PPT、RTF、TXT、CHM、EPUB等)保存在存储系统中。现在需要利用 ElasticSearch 实现一套全文检索系统,以便用户可以通过对电子书的基本信息和数字内容进行模糊查询,快速找到相关书籍。
数据结构
数据库表 BOOK 结构:
CREATE TABLE book (
id varchar(100) NOT NULL,
title varchar(50) DEFAULT NULL,
desc varchar(1000) DEFAULT NULL,
path varchar(200) DEFAULT NULL,
create_time datetime DEFAULT NULL,
update_time datetime DEFAULT NULL,
PRIMARY KEY (id)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
字段 意义
id 主键
title 书名
desc 介绍
path 存储路径
create_time 创建时间
update_time 更新时间
逻辑约束:创建书籍记录时,create_time 等于 update_time,即当前时间,每次更新书籍时,更新 update_time 时间。全文检索系统根据 update_time 时间更新书籍索引。
三、技术方案
示意图
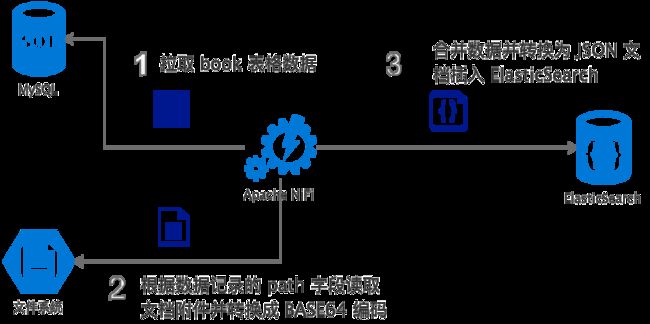
基本思路就是:
- 定期扫描 MySQL 中的 book 表,根据字段 update_time 批量抓取最新的电子书数据。
- 从 path 字段获取电子书数字内容的文档存储路径。从存储系统中抓取电子书文档并进行 BASE64编码。
- 将从 book 表批量抓取的数据转换为 JSON 文档,并将 BASE64编码后的电子书文档合并入 JSON,一同写入 ElasticSearch,利用 ElasticSearch 的插件 Ingest Attachment Processor Plugin 对电子书文档进行文本抽取,并进行持久化,建立全文索引。
本文采用开源数据处理工具 Apache NiFi http://nifi.apache.org 来实现上述流程,具体使用方法后续实施过程会详细讲解。如果读者不了解 Apache NiFi ,也可以使用 Logstash、Kettle 等工具或者使用自己熟悉的编程语言开发应用来完成上述流程。
四、安装并初始化 ElasticSearch
安装 ElasticSearch
访问ElasticSearch官网,根据操作系统选择下载软件包,并安装
https://www.elastic.co/downloads/elasticsearch
当前最新版本是 v6.2.4
Linux/Unix 下运行 bin/elasticsearch (在windows操作系统下运行 bin\elasticsearch.bat )
ElasticSearch的默认服务端口是 9200,所有 API 都可以通过 REST 方式调用。
关于JVM内存:ElasticSearch是基于Java开发,部署需要配置合理的JVM Heap内存,官方建议分配内存不高于本机物理内存的二分之一,最好不要超过32G。具体配置方法如下:
设置环境变量 ES_HEAP_SIZE,ElasticSearch启动时会读取这个环境变量。 在命令行运行如下:
export ES_HEAP_SIZE=8g
安装中文分词插件
IK Analysis for Elasticsearch 是开源社区比较流行的中文分词插件
官网:https://github.com/medcl/elasticsearch-analysis-ik
安装方法:
在安装目录下运行
./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v6.2.4/elasticsearch-analysis-ik-6.2.4.zip
运行结果:
➜ elasticsearch-6.2.4 ./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v6.2.4/elasticsearch-analysis-ik-6.2.4.zip
-> Downloading https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v6.2.4/elasticsearch-analysis-ik-6.2.4.zip
[=================================================] 100%
-> Installed analysis-ik
安装成功后,在 plugin 文件夹下可以看到出现了 analysis-ik 文件夹。
安装附件文本抽取插件
ElasticSearch 官方提供插件:
Ingest Attachment Processor Plugin
https://www.elastic.co/guide/en/elasticsearch/plugins/current/ingest-attachment.html#ingest-attachment
此插件开箱即用,用于实现常见格式文档的文本抽取,它基于另一个开源的文本抽取工具库 Apache Tika http://tika.apache.org 实现。
安装方法:
在安装目录下运行
./bin/elasticsearch-plugin install ingest-attachment
安装过程中提示此插件需要一些额外的权限,输入y回车,继续安装即可,运行结果:
-> Downloading ingest-attachment from elastic
[=================================================] 100%
@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
@ WARNING: plugin requires additional permissions @
@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
* java.lang.RuntimePermission accessDeclaredMembers
* java.lang.RuntimePermission getClassLoader
* java.lang.reflect.ReflectPermission suppressAccessChecks
* java.security.SecurityPermission createAccessControlContext
* java.security.SecurityPermission insertProvider
* java.security.SecurityPermission putProviderProperty.BC
See http://docs.oracle.com/javase/8/docs/technotes/guides/security/permissions.html
for descriptions of what these permissions allow and the associated risks.
Continue with installation? [y/N]y
-> Installed ingest-attachment
安装成功后,在 plugin 文件夹下可以看到出现了 ingest-attachment 文件夹。
重新启动 ElasticSearch
所有插件安装完成后重新启动 ElasticSearch
五、文档附件的文本抽取
解决方式
ElasticSearch只能处理文本,不能直接处理二进制文档。要利用 ElasticSearch 实现附件文档的全文检索需要 2 个步骤:
- 对多种主流格式的文档进行文本抽取。
- 将抽取出来的文本内容导入 ElasticSearch ,利用 ElasticSearch强大的分词和全文索引能力。
上文安装的 Ingest Attachment Processor Plugin 是一个开箱即用的插件,使用它可以帮助 ElasticSearch 自动完成这 2 个步骤。
基本原理是利用 ElasticSearch 的 Ingest Node 功能,此功能支持定义命名处理器管道 pipeline,pipeline中可以定义多个处理器,在数据插入 ElasticSearch 之前进行预处理。而 Ingest Attachment Processor Plugin 提供了关键的预处理器 attachment,支持自动对入库文档的指定字段作为文档文件进行文本抽取,并将抽取后得到的文本内容和相关元数据加入原始入库文档。
因为 ElasticSearch 是基于 JSON 格式的文档数据库,所以附件文档在插入 ElasticSearch 之前必须进行 Base64 编码。
当然,Attachment Processor Plugin 不是唯一方案。如果需要深入定制文档抽取功能,或基于功能解耦等考量,完全可以利用 Apache Tika http://tika.apache.org 实现独立的文档抽取应用。
建立文本抽取管道
ElasticSearch 支持 REST API,我们可以用 cURL、Postman 等工具调用。为方便查看,本文使用如下这种表示方式来展示 REST 调用,请注意,它并不是可执行代码。
PUT http://localhost:9200/_ingest/pipeline/attachment
{
“description”: “Extract attachment information”,
“processors”: [
{
“attachment”: {
“field”: “data”,
“ignore_missing”: true
}
},
{
“remove”: {
“field”: “data”
}
}
]
}
以上,我们建立了 1 个命名 pipeline 即 “attachment”,其中定义了 2 个预处理器 “attachment” 和 “remove” ,它们按定义顺序对入库数据进行预处理。
“attachment” 预处理器即上文安装的插件 “Ingest Attachment Processor Plugin” 提供,将入库文档字段 “data” 视为文档附件进行文本抽取。要求入库文档必须将文档附件进行 BASE64编码写入 “data” 字段。
文本抽取后, 后续不再需要保留 BASE64 编码的文档附件,将其持久化到 ElasticSearch 中没有意义,”remove” 预处理器用于将其从源文档中删除。
如何使用 pipeline
按照 ElasticSearch 的 API 定义,插入文档时可以在请求地址末尾加
?pipeline=attachment 的形式指定使用上文建立的 “attachment” 命名 pipeline。
六、建立文档结构映射
ElasticSearch 是文档型数据库,以 JSON 文档为处理对象。文档结构以 mapping 形式定义,相当于关系型数据库建立表结构。以下,我们建立 MySQL 的 book 表在 ElasticSearch 中的文档结构映射。
PUT http://localhost:9200/book
{
"mappings": {
"idx": {
"properties": {
"id": {
"type": "keyword"
},
"title": {
"type": "text",
"analyzer": "ik_max_word"
},
"desc": {
"type": "text",
"analyzer": "ik_max_word"
},
"path": {
"type": "keyword"
},
"create_time": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis"
},
"update_time": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis"
},
"attachment": {
"properties": {
"content": {
"type": "text",
"analyzer": "ik_max_word"
}
}
}
}
}
}
}除了 book 表中的原有字段外,我们在 ElasticSearch 中增加了 “attachment” 字段,这个字段是 “attachment” 命名 pipeline 抽取文档附件中文本后自动附加的字段。这是一个嵌套字段,其包含多个子字段,包括抽取文本 content 和一些文档信息元数据。
在本文的应用场景中,我们需要对 book 的 title、desc 和 attachment.content 进行全文检索,所以在建立 mapping 时,我们为这 3 个字段指定分析器 “analyzer” 为 “ik_max_word”,以让 ElasticSearch 在建立全文索引时对它们进行中文分词。
七、安装并配置 Apache NiFi
Apache NiFi (http://nifi.apache.org) 是一个易用、强大、可靠的数据处理、分发系统。本文使用它来完成数据流转处理,如果读者使用其它工具或者自行编程开发应用,请忽略本章。
本文不是专门的 Apache NiFi 教程,只针对相关应用场景介绍如何使用 Apache NiFi。
安装 Apache NiFi
在 Apache NiFi 官网下载并解压到本地,本文当前最新版本为 1.6.0
下载地址:http://nifi.apache.org/download.html
Apache NiFi 基于 java 开发,要求运行环境为 JDK 8.0 以上。
常用配置在 conf 目录下的 nifi.properties 和 bootstrap.conf 文件中,详见:NiFi System Administrator’s Guide
其中,web 控制台端口在 nifi.proerties 文件中的 nifi.web.http.port 参数修改,默认值 8080。JVM启动参数在 bootstrap.conf 文件中,内存分配在 # JVM memory settings 段,默认 -Xms512m -Xmx512m。
下载 MySQL Connector/J
因为 NiFi 需要连接 MySQL 抓取数据,请到 MySQL 官网下载 MySQL Connector/J
https://dev.mysql.com/downloads/connector/j/
本文当前最新版本 5.1.46, 将 mysql-connector-java-5.1.46-bin.jar 拷贝到 NiFi 安装目录备用。
启动 Apache NiFi
命令行进入 Apache NiFi 目录,运行命令 ./bin/nifi.sh start
Apache NiFi 的常用命令:
命令 说明
run 交互式启动
start 后台启动
stop 停止
status 查看服务状态
Apache NiFi 提供图形化的 Web 管理控制台,内置丰富的功能组件,通过拖拽的方式即可建立数据处理流程, 启动以后访问 http://localhost:8080/nifi ,控制台如下图:
NiFi控制台
配置数据处理流程
篇幅有限,本文不详细讲解 Apache NiFi,如果读者有兴趣,请前往阅读官方文档:
http://nifi.apache.org/docs.html
导入模板
Apache NiFi 支持将配置好的流程保存为模板,鼓励社区开发者之间分享模板。本章及使用的流程模板已上传至开源项目:
https://gitee.com/streamone/full-text-search-in-action
模板文件在 /nifi/FullText-mysql.xml
下载模板文件 FullText-mysql.xml ,然后点击控制台左侧 “Operate” 操作栏里的 “Upload Template” 上传模板。
上传模板
应用模板
拖拽控制台顶部一排组件图标中的 “Template” 到空白网格区域,在弹出的 “Add Template” 窗口中选择刚刚上传的模板 “FullText-mysql”,点击 “Add”。空白网格区域将出现如下下图的 “process group”,它是一组 “processor” 的集合,我们的处理流程就是由这组 “processor” 按照数据处理逻辑有序组合而成。
NiFi模板
双击此 “process group” 进入,将看到完整的流程配置,如下图:
NiFi process group
运行这个流程之前需要完成几个配置项:
配置并启动数据库连接池
在空白网格处点击鼠标右键,在弹出菜单中点击 “configure”,在弹出的 “FullText-mysql Configuration” 窗口中打开 “controller services” 标签页如下图,点击表格中 “DBCPConnectionPool” 右侧 “Configure” 图标,进行数据库连接池配置。 NiFi controller services
在弹出的 “Configure Controller Service” 窗口中打开 “PROPERTIES” 标签页,在表格中填写 MySQL数据库相关信息,如下图: 配置数据库连接池
其中的 “Database Driver Location(s)” 填写我们下载的 “mysql-connector-java-5.1.46-bin.jar” 路径。 配置好数据库连接池以后点击 “APPLY” 回到 “controller services” 标签页,点击表格中 “DBCPConnectionPool” 右侧 “Enable” 图标启动数据库连接池。
修改变量
在空白网格处点击鼠标右键,在弹出菜单中点击 “variables”,打开 “Variables” 窗口,修改表格中的 “elasticSearchServer” 参数值为 ElasticSearch 服务地址,修改表格中的 “rootPath” 参数为电子书数字文档在文件系统中的根路径。
回到 “process group” 流程页面,在空白网格处点击鼠标右键,在弹出菜单中点击 “start” 菜单,启动流程。
至此,我们完成了本文应用场景中 Apache NiFi 的流程配置。Apache NiFi 每隔 10 秒扫描 MySQL 的 book 表,抓取最新的电子书数据,处理后导入 ElasticSearch。
八、全文检索查询
完成以上内容,我们应该已经将 MySQL 数据库中的电子书信息导入 ElasticSearch,并建立了全文索引。
本章应用场景中,我们想要对电子书的 “title”、”desc”、”attachment.content” (抽取文本) 进行全文检索,帮助用户快速找到关键词为 “计算” 的全部电子书。
ElasticSearch 提供 REST API,各种编程语言都可以很方便地实现客户端调用,官方提供了多种语言的 client :
https://www.elastic.co/guide/en/elasticsearch/client/index.html
本章沿用前述方式展示全文检索请求结构:
POST http://localhost:9200/book/idx/_search
{
“query”: {
“multi_match”: {
“query”: “计算”,
“fields”: [“title”, “desc”, “attachment.content”]
}
},
“_source”: {
“excludes”: [“attachment.content”]
},
“from”: 0, “size”: 200,
“highlight”: {
“encoder”: “html”,
“pre_tags”: [““],
“post_tags”: [““],
“fields”: {
“title”: {},
“desc”: {},
“attachment.content”: {}
}
}
}
我们采用 “multi_match” 进行跨多字段查询。
关于 “multi_match” 的更多信息,请前往 https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl-multi-match-query.html
“_source” 用于从返回结果中将 “attachment.conent” 字段过滤掉,因为此字段是从电子书中抽取的文本,内容太大,我们不希望在列表查询中显示它。
ElasticSearch 默认是分页查询,以 “from” 和 “size” 分别表示偏移量和每页记录数。
“highlight” 是高亮配置,其中 “fields” 属性中配置的字段高亮信息都会被查询结果返回。”encoder” 是在对关键词加高亮标签之前对原文转义的方式。”pre_tags” 和 “post_tags” 是关键词高亮标签。
关于 “highlight” 的更多信息,请前往 https://www.elastic.co/guide/en/elasticsearch/reference/current/search-request-highlighting.html
请注意,这段不是可执行程序,这样写仅仅是为了方便查看。以下为对应的 cURL 调用命令:
curl -X POST \
http://localhost:9200/book/idx/_search \
-H ‘Cache-Control: no-cache’ \
-H ‘Content-Type: application/json’ \
-d ‘{
“query”: {
“multi_match”: {
“query”: “计算”,
“fields”: [“title”, “desc”, “attachment.content”]
}
},
“_source”: {
“excludes”: [“attachment.content”]
},
“from”: 0, “size”: 200,
“highlight”: {
“encoder”: “html”,
“pre_tags”: [““],
“post_tags”: [““],
“fields”: {
“title”: {},
“desc”: {},
“attachment.content”: {}
}
}
}’