Python网络爬虫实战:爬取知乎话题下 18934 条回答数据
好久没有更爬虫了,因为马上要毕业了,最近在准备毕设的项目,没时间搞这个了,不好意西了大家。
事情是这样的,上周末,我一单身单身单身的好哥儿们找我,拜托我个事儿。。。我这个单身单身单身的好哥们喜欢逛知乎,尤其喜欢看一些情感类型的话题,寄希望于这个来解决单身的烦恼。某天,他看到了知乎上这样一个问题:
你的择偶标准是怎样的?
这个问题下的回答数竟有有一万八千多条,然后这家伙忍不住了,来找我帮忙,看能不能用爬虫爬一下,看看到底都是些什么人在评论,回答的人里面到底是小哥哥们多还是小姐姐们多呢?
单身单身单身的好哥们求助,肯定要帮嘛是吧!毕设先放一边也要帮嘛!
所以我们这次来爬知乎!
一、首先明确需求,爬什么数据?
通过一番交流,最终我们确认要爬的数据是:知乎网站上 “你的择偶标准是怎样的?”问题下回答的用户的数据,包括
- 用户的 ID
- 用户的昵称
- 用户的性别
- 用户回答的赞同数
- 用户回答的评论数
经过初步查看,这些信息在不登陆的情况下,在网页中都可以查看到(传说中,知乎的反爬机制几乎没有,是爬虫爱好者最喜欢爬的网站之一)。
接下来,我们只需要分析网页源码,看看这些数据都藏在哪里就好了。
二、分析网站源码,找到数据存放位置
老规矩,打开目标网站,按 F12 ,召唤出开发者工具,查看源码,以及监控网络请求。
逛网页版知乎的时候,我发现(其实大家都能发现),回答数虽有一万多条,但是网站并不会全部显示出来,而且也没有翻页按钮,在我们向下滚动页面到底的时候,后面的回答才会动态的加载出来。
这不就是我们特别喜欢的 Ajax 动态加载的技术嘛?
这种加载方式的原理,简单通俗点讲就是,我服务器上有很多数据,一下子也发不过去,发过去你也看不完,所以干脆我分批给你发,你看完一批,然后跟我讲,我给你发下一批。浏览器就是这样,每次检测到你进度条快到底了,赶紧给服务器发个消息,把下一批数据拿过来加载上去。
所以我们应付 ajax 的方法也很简单,截获浏览器发给服务器的请求,然后分析出请求的规律,然后我们用爬虫伪装成浏览器不断向服务器发送请求,这样就可以获取源源不断的数据了。
1. 将开发者工具切换到 Network 窗口,清空其中的内容(主要是为了防止干扰),然后不断的向下拖动页面的滑动条(让浏览器多向服务器发送一些请求,方便我们查找)。

2. 上图中便是我筛查到的请求(截图里我是做了筛选的,实际上接获到的请求是相当多的,需要花点功夫去从里面筛选的),可能有人会疑惑,我怎么知道哪个请求才是我要的呢?这里有几个筛选小技巧。
a. 请求的类型基本都是 XHR 这一类型的,过滤器中选择这个,可以帮我们过滤到大量的图片,脚本,以及网页样式文件等等。

b. 点击请求之后,出现详情页,然后切换到 Preview 选项卡,可以预览该请求返回的内容。我们需要找的请求,返回的内容一般是 json 格式的数据,其中包含了关于知乎回答的一些信息。
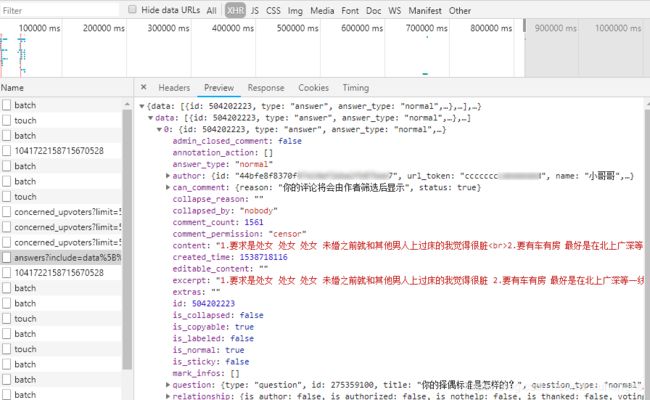
c. 根据以上两条,基本上稍微花点功夫,很快就可以找到所要找的请求。
3. 分析请求头的格式(找规律),找到请求头构成的一般规律,然后我们根据这些规律,构造出剩余所有的回答数据的请求头。
第一页:https://www.zhihu.com/api/v4/questions/275359100/answers?include=data%5B%2A%5D.is_normal%2Cadmin_closed_comment%2Creward_info%2Cis_collapsed%2Cannotation_action%2Cannotation_detail%2Ccollapse_reason%2Cis_sticky%2Ccollapsed_by%2Csuggest_edit%2Ccomment_count%2Ccan_comment%2Ccontent%2Ceditable_content%2Cvoteup_count%2Creshipment_settings%2Ccomment_permission%2Ccreated_time%2Cupdated_time%2Creview_info%2Crelevant_info%2Cquestion%2Cexcerpt%2Crelationship.is_authorized%2Cis_author%2Cvoting%2Cis_thanked%2Cis_nothelp%2Cis_labeled%3Bdata%5B%2A%5D.mark_infos%5B%2A%5D.url%3Bdata%5B%2A%5D.author.follower_count%2Cbadge%5B%2A%5D.topics&limit=5&offset=0&platform=desktop&sort_by=default
第二页:https://www.zhihu.com/api/v4/questions/275359100/answers?include=data%5B%2A%5D.is_normal%2Cadmin_closed_comment%2Creward_info%2Cis_collapsed%2Cannotation_action%2Cannotation_detail%2Ccollapse_reason%2Cis_sticky%2Ccollapsed_by%2Csuggest_edit%2Ccomment_count%2Ccan_comment%2Ccontent%2Ceditable_content%2Cvoteup_count%2Creshipment_settings%2Ccomment_permission%2Ccreated_time%2Cupdated_time%2Creview_info%2Crelevant_info%2Cquestion%2Cexcerpt%2Crelationship.is_authorized%2Cis_author%2Cvoting%2Cis_thanked%2Cis_nothelp%2Cis_labeled%3Bdata%5B%2A%5D.mark_infos%5B%2A%5D.url%3Bdata%5B%2A%5D.author.follower_count%2Cbadge%5B%2A%5D.topics&limit=5&offset=5&platform=desktop&sort_by=default
第三页:https://www.zhihu.com/api/v4/questions/275359100/answers?include=data%5B%2A%5D.is_normal%2Cadmin_closed_comment%2Creward_info%2Cis_collapsed%2Cannotation_action%2Cannotation_detail%2Ccollapse_reason%2Cis_sticky%2Ccollapsed_by%2Csuggest_edit%2Ccomment_count%2Ccan_comment%2Ccontent%2Ceditable_content%2Cvoteup_count%2Creshipment_settings%2Ccomment_permission%2Ccreated_time%2Cupdated_time%2Creview_info%2Crelevant_info%2Cquestion%2Cexcerpt%2Crelationship.is_authorized%2Cis_author%2Cvoting%2Cis_thanked%2Cis_nothelp%2Cis_labeled%3Bdata%5B%2A%5D.mark_infos%5B%2A%5D.url%3Bdata%5B%2A%5D.author.follower_count%2Cbadge%5B%2A%5D.topics&limit=5&offset=10&platform=desktop&sort_by=default仔细观察可以发现,三者除了最后 offset 参数不一致外,其余构成完全一样,而且 offset 的值还很有规律,每次数字增加 5。然后联想到请求返回的 json 数据可知,每次请求返回 5 条数据。

4. 思路一下子清晰了,offset 是一个偏移量,表示从第几条回答开始获取,每次获取5条回答,所以下次获取时 offset 就要加 5 啦。所以我们编写爬虫时,用一个循环,让 offset 的值从零开始,每次加 5,一直到总回答数为止,这样就可以获取到所有的回答数据了。
三、动手撸代码,写爬虫
爬虫我们之前写过很多遍了,思路都差不多,而且知乎网站对爬虫真的很友好,完全不设反爬机制,我都没有用到 代理IP和动态UA,甚至没有写延迟函数,近两万条数据,直接就顺利的跑完了。
全部源码献上,关于代码的解释,可以参考我的其他爬虫文章,已经讲的很详细了,这里就不再赘述了,如果还有问题,可以私信或者评论问我。
import requests
import json
import time
import re
import datetime
import pandas as pd
def get_data(url):
'''
功能:访问 url 的网页,获取网页内容并返回
参数:
url :目标网页的 url
返回:目标网页的 html 内容
'''
headers = {
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36',
}
try:
r = requests.get(url, headers=headers)
r.raise_for_status()
return r.text
except requests.HTTPError as e:
print(e)
print("HTTPError")
except requests.RequestException as e:
print(e)
except:
print("Unknown Error !")
def parse_data(html):
'''
功能:提取 html 页面信息中的关键信息,并整合一个数组并返回
参数:html 根据 url 获取到的网页内容
返回:存储有 html 中提取出的关键信息的数组
'''
json_data = json.loads(html)['data']
comments = []
try:
for item in json_data:
comment = []
comment.append(item['author']['name']) # 姓名
comment.append(item['author']['gender']) # 性别
#comment.append(item['author']['url']) # 个人主页
comment.append(item['voteup_count']) # 点赞数
comment.append(item['comment_count']) # 评论数
#comment.append(item['url']) # 回答链接
comments.append(comment)
return comments
except Exception as e:
print(comment)
print(e)
def save_data(comments):
'''
功能:将comments中的信息输出到文件中/或数据库中。
参数:comments 将要保存的数据
'''
filename = 'Data/comments.csv'
dataframe = pd.DataFrame(comments)
dataframe.to_csv(filename, mode='a', index=False, sep=',', header=False)
#dataframe.to_csv(filename, mode='a', index=False, sep=',', header=['name','gender','user_url','voteup','cmt_count','url'])
def main():
url = 'https://www.zhihu.com/api/v4/questions/275359100/answers?include=data%5B%2A%5D.is_normal%2Cadmin_closed_comment%2Creward_info%2Cis_collapsed%2Cannotation_action%2Cannotation_detail%2Ccollapse_reason%2Cis_sticky%2Ccollapsed_by%2Csuggest_edit%2Ccomment_count%2Ccan_comment%2Ccontent%2Ceditable_content%2Cvoteup_count%2Creshipment_settings%2Ccomment_permission%2Ccreated_time%2Cupdated_time%2Creview_info%2Crelevant_info%2Cquestion%2Cexcerpt%2Crelationship.is_authorized%2Cis_author%2Cvoting%2Cis_thanked%2Cis_nothelp%2Cis_labeled%3Bdata%5B%2A%5D.mark_infos%5B%2A%5D.url%3Bdata%5B%2A%5D.author.follower_count%2Cbadge%5B%2A%5D.topics&limit=5&offset=5&platform=desktop&sort_by=default'
# get total cmts number
html = get_data(url)
totals = json.loads(html)['paging']['totals']
print(totals)
print('---'*10)
page = 0
while(page < totals):
url = 'https://www.zhihu.com/api/v4/questions/275359100/answers?include=data%5B%2A%5D.is_normal%2Cadmin_closed_comment%2Creward_info%2Cis_collapsed%2Cannotation_action%2Cannotation_detail%2Ccollapse_reason%2Cis_sticky%2Ccollapsed_by%2Csuggest_edit%2Ccomment_count%2Ccan_comment%2Ccontent%2Ceditable_content%2Cvoteup_count%2Creshipment_settings%2Ccomment_permission%2Ccreated_time%2Cupdated_time%2Creview_info%2Crelevant_info%2Cquestion%2Cexcerpt%2Crelationship.is_authorized%2Cis_author%2Cvoting%2Cis_thanked%2Cis_nothelp%2Cis_labeled%3Bdata%5B%2A%5D.mark_infos%5B%2A%5D.url%3Bdata%5B%2A%5D.author.follower_count%2Cbadge%5B%2A%5D.topics&limit=5&offset='+ str(page) +'&platform=desktop&sort_by=default'
html = get_data(url)
comments = parse_data(html)
save_data(comments)
print(page)
page += 5
if __name__ == '__main__':
main()
print("完成!!")
四、简单分析数据
简单的整理了一下数据,结果如下:
- 一共爬取了 18934 条数据,其中 10555 个是小哥哥,3806 个是小姐姐,还有 4573 个性别未知;
- 这些回答中,有 8390 个用户是匿名回答;
- 点赞数排名前100的回答中,有 52 个小姐姐,有 38 个小哥哥,10 个性别未知;
- 评论数排名前100的回答中,有 42 个小姐姐,有 51 个小哥哥,7 个性别未知;
基于上述数据,我们可以得出一些结论:
- 此话题下,回答的男生人数是女生人数的 2.77 倍,可以得知,男性对于择偶标准这个话题更加关注,也更加愿意去分享自己的择偶标准(其实就是变相地在相亲嘛,我这个单身单身单身的好哥儿们不也是冲着这个来的嘛!)
- 毕竟这个话题还是有点涉及隐私,难以启齿的,所以 44.3% 的用户选择了匿名回答。
- 论评论数,男生的回答要略优于女生,而论点赞数,小姐姐们的回答则会更高。可能是男生的回答多有抖机灵幽默,比较容易有交流讨论的话题性,而女生喜欢贴美美哒照片,引得小哥哥们纷纷点赞收藏罢。
后记
我把爬到的数据结果发给我的单身单身单身的好哥儿们看了之后,好哥儿们感到非常诧异,
因为他看回答前几个都是妹子,还以为这个话题下的妹子会更多一点呢!
原来在网络上,也改变不了狼多肉少的局面。
如果文章中有哪里没有讲明白,或者讲解有误的地方,欢迎在评论区批评指正,或者扫描下面的二维码,加我微信,大家一起学习交流,共同进步。
