3.最简单的MR-WordCount
- 程序结构
- map部分
- reduce部分
- 主入口
- 测试
- 运行历史分析
- 下载
程序结构
从这一节开始,我会讲MR任务编写的方方面面,但是仅限在任务编写这块,不会过度涉及HDFS和Yarn调度的深入分析,计算时提也只是为了更好的理解MR任务。对于Mapreduce计算模型会深入介绍,只有了解Mapreduce计算模型计算模型才能真正掌握整个MR任务的编写,对于相关任务的调优和过程划分才会有清洗的认识。这一部分是适合所有人的,先不去管整个hadoop实现的复杂性,适应MR的思维用好hadoop这个工具才是最重要的,对于数据分析员,有必要深入理解MR过程才能优化自己的程序,对于数据开发员,先了解怎么用才能更好的阅读和调整源代码。见过一些数据分析人员,纯写业务不考虑MR的优化,毫无疑问这是可悲的,很多时候一个简单的优化需要数倍成本的硬件才能达到同样的效果;也见过好多hadoop都没用熟的大数据开发,指望他们能改好代码反正我是不信的。
写MR其实很简单,主要考虑的是如何划分map和reduce操作,MapReduce模型固然简单,但是也因为其抽象能力有限,对于复杂任务只能通过多个MR过程组合, 还好有Hive在上层已经帮我们处理了这一问题,hive其实就是把SQL翻译成多个MR过程来执行。最新的如Spark的计算引擎是基于DAG的,因此支持更多类型的操作,组合起来更加多样,这个后续来讲。
本节从最简单的MR任务组成和编写开始,整个MR的过程如下:
- 实现map和reduce逻辑
- 然后在主入口中调整参数和提交执行。
map部分
map通过继承实现Mapper接口,完成map功能,如下。map的模板参数前两个指定输入的Key、Value类型,后两个指定输出的Key、Value类型。
这里输入Key=LongWritable为输入文件每行偏移,Text为对应文本内容,注意这里必须用hadoop提供的这种实现了Writable接口的类型,这是为了数据序列化的考虑,后面会详述。
输出为以每个单词作为Key,次数1作为值的键值对,这样在Reduce中就可以按照Key聚合起来计算每个单词出现的次数。这里提前定义了one和word,主要是为了性能优化的考虑,现在只要记住尽量重用这些结构即可。
public class WordMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 文本按空格分割成<单词,1>组
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
reduce部分
map通过继承实现Reducer接口,完成reduce功能,如下。reduce的模板参数前两个指定输入的Key、Value类型,后两个指定输出的Key、Value类型。
public class WordReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
// <单词,1>组按照单词聚合起来,次数累加
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
主入口
main函数中提交MR任务如下,具体每个步骤代码已经注释很清楚了。
public static void main( String[] args ) throws Exception {
if (args.length!=2){
System.out.println("输入参数个数不正确!");
System.exit(-1);
}
//1.读入配置,可以在此动态修改
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "jimwen_wordcount");
//2.分别设置Jar包路径和对应的map/reduce类
job.setJarByClass(App.class);
job.setMapperClass(WordMapper.class);
job.setReducerClass(WordReducer.class);
//3.设置map/reduce的输入键Key和值Value的类型
// map和reduce输出相同时设置setOutput***即可
// map和reduce不同时,需要用setMapOutput***设置map输出类型
//job.setMapOutputKeyClass(Text.class);
//job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//4.设置输入和输出类型和路径
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
//5.等待任务执行完成
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
测试
如上程序,编译打包后执行如下指令
hadoop jar WordCount-1.0-SNAPSHOT.jar org.jimwen.App /data /output
可以看到console中输出
8/12/23 04:09:00 INFO mapreduce.JobSubmitter: number of splits:1
18/12/23 04:09:00 INFO Configuration.deprecation: yarn.resourcemanager.system-metrics-publisher.enabled is deprecated. Instead, use yarn.system-metrics-publisher.enabled
18/12/23 04:09:00 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1545538254601_0002
18/12/23 04:09:01 INFO impl.YarnClientImpl: Submitted application application_1545538254601_0002
18/12/23 04:09:02 INFO mapreduce.Job: The url to track the job:http://192.168.139.140:8088/proxy/application_1545538254601_0002/
18/12/23 04:09:02 INFO mapreduce.Job: Running job: job_1545538254601_0002
18/12/23 04:09:22 INFO mapreduce.Job: Job job_1545538254601_0002 running in uber mode : false
18/12/23 04:09:22 INFO mapreduce.Job: map 0% reduce 0%
18/12/23 04:10:14 INFO mapreduce.Job: map 100% reduce 0%
18/12/23 04:10:46 INFO mapreduce.Job: map 100% reduce 100%
18/12/23 04:10:51 INFO mapreduce.Job: Job job_1545538254601_0002 completed successfully
18/12/23 04:10:54 INFO mapreduce.Job: Counters: 49
...
可以看到整个的执行过程,
- 首先划分切片
number of splits:1 - 然后申请一个运行
JobID=job_1545538254601_0002 - 再接着提交应用
application_1545538254601_0002,可以url跟踪和查看执行进度和状态 - 执行过程中会输出map/reduce进度
- 执行完成,输出完成状态,并显示过程中的一系列统计值
查看hdfs输出目录,结果如下:
wenzhou@ubuntu:~$ hadoop fs -ls /output
Found 2 items
-rw-r--r-- 1 wenzhou supergroup 0 2018-12-27 23:01 /output/_SUCCESS
-rw-r--r-- 1 wenzhou supergroup 28 2018-12-27 23:01 /output/part-r-00000
wenzhou@ubuntu:~$ hadoop fs -cat /output/part-r-00000
hello 5
jim 4
wen 3
world 2
运行成功,输出目录会写入_SUCCESS标记,实际应用中后续任务可通过检测此标记判断任务是否运行完成。实际输出数据在part-r-00000中,这里part的序号数和reduce数保持一致。
运行历史分析
如上,程序运行时会输出track url,即
http://192.168.139.140:8088/proxy/application_1545538254601_0002/
然而,实际访问我们会发现,跳转后的运行历史地址不存在
http://192.168.139.140:19888/jobhistory/job/job_1545980170732_0001
实际需要开启日志服务才行,进入脚本sbin目录,执行如下命令:
mr-jobhistory-daemon.sh start historyserver
此时显示任务运行历史,如下:
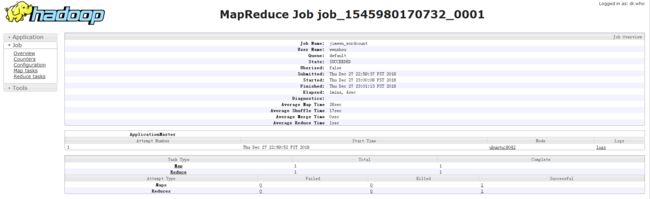
可以看到,任务运行的各个阶段耗时、map/reduce任务执行状况、各节点日志等。任务运行历史对任务调优非常重要,后面会详细讲解。
实际任务运行日志保存在本地,也可以通过开启聚合功能将日志保存在HDFS中,减少NodeManager的压力。常用的日志相关配置如下:
配置 mapred-site.xml
1.mapreduce.jobhistory.address
参数说明:JobHistory服务器IPC 主机:端口
默认值:0.0.0.0:10020
2.mapreduce.jobhistory.webapp.address
参数说明:History服务器Web UI地址,用户可根据该地址查看Hadoop历史作业情况
默认值:0.0.0.0:19888
配置 yarn-site.xml
- 日志相关的一般配置项
1.yarn.nodemanager.log-dirs
参数说明:容器还在执行中时, 容器日志在节点上的存储位置(可配置多个目录)
默认值:${yarn.log.dir}/userlogs
2.yarn.log-aggregation-enable
参数说明:是否启用日志聚合功能,日志聚合开启后保存到HDFS上
默认值:false
- 日志聚合启用后的相关配置
1.yarn.log-aggregation.retain-seconds
参数说明:聚合后的日志在HDFS上保存多长时间,单位为s。
默认值:-1(不启用日志聚合),例如设置为86400,24小时
2.yarn.log-aggregation.retain-check-interval-seconds
参数说明:删除任务在HDFS上执行的间隔,执行时候将满足条件的日志删除(超过参数2设置的时间的日志),如果是0或者负数,则为参数2设置值的1/10,上例值在此处为8640s。
默认值:-1
3.yarn.nodemanager.remote-app-log-dir
参数说明:当应用程序运行结束后,日志被转移到的HDFS目录(启用日志聚集功能时有效),修改为保存的日志文件夹。
默认值:/tmp/logs
4.yarn.nodemanager.remote-app-log-dir-suffix
参数说明:远程日志目录子目录名称(启用日志聚集功能时有效)。
默认值:logs 日志将被转移到目录${yarn.nodemanager.remote-app-log-dir}/${user}/${thisParam}下
5.yarn.log.server.url
参数说明:一旦一个应用结束, NMs 会将网页访问自动跳转到聚合日志的地址, 执行过程中它指向的是 MapReduce 的 JobHistory
- 日志聚合未启用的相关配置
1.yarn.nodemanager.log.retain-seconds
参数说明:当不启用日志聚合此参数生效,日志文件保存在本地的时间,单位为s
默认值:10800
下载
源码下载地址
原创,转载请注明来自
- 博客https://blog.csdn.net/wenzhou1219
- 个人网站http://jimwen.net/
日志配置参考