Centos7.3 搭建ELK-6.0.0日志分析平台
Centos7.3 搭建ELK-6.0.0日志分析平台
ElasticSearch + LogStash + Kibana = ELKStack
组件介绍
Elasticsearch是个开源分布式搜索引擎,提供搜集、分析、存储数据三大功能。它的特点有:分布式,零配置,自动发现,索引自动分片,索引副本机制,restful风格接口,多数据源,自动搜索负载等。
Logstash 主要是用来日志的搜集、分析、过滤日志的工具,支持大量的数据获取方式。一般工作方式为c/s架构,client端安装在需要收集日志的主机上,server端负责将收到的各节点日志进行过滤、修改等操作在一并发往elasticsearch上去。
FileBeat是一个轻量级的日志收集处理工具(Agent),Filebeat占用资源少,适合于在各个服务器上搜集日志后传输给Logstash,官方推荐。
Filebeat隶属于Beats,目前Beats包含四种工具:
- Packetbeat(搜集网络流量数据)
- Topbeat(搜集系统、进程和文件系统级别的 CPU 和内存使用情况等数据)
- Filebeat(搜集文件数据)
- Winlogbeat(搜集 Windows 事件日志数据)
系统环境
JDK:1.8.0_45
操作系统: centos7.3
内存:4G
ELK: 6.0.0
下载页面:https://www.elastic.co/downloads/past-releases
elk三个程序,默认启动都是非守护进程的,并不是后台启动,而是直接前台,如果关闭窗口,则进程中断。可以使用screen或者supervisor来管理进程
系统架构
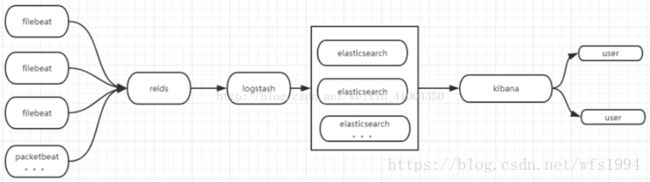
部署 elasticsearch
安装elasticsearch数据存储器。用于数据存储,可以分布式部署。解压后,直接修改配置文件,则可以启动。这里我用了两台主机坐了一个elasticsearch的集群,如果有需求可以根据需求,增加更多的机器用于存储数据,增加elasticsearch的节点。
主机IP分别为: 192.168.20.101 192.168.20.102
elasticsearch需要普通用户启动,修改数据目录,日志目录,包目录为普通用户权限
解压下载好的elasticsearch安装包到/usr/local/elk/内,修改配置文件:
# grep ^[a-z] /usr/local/elk/elasticsearch-6.0.0/config/elasticsearch.yml # 编辑配置文件
cluster.name: ES-Cluster ##设置集群名称,集群内的节点都要设置相同,可自定义
node.name: ES-01 ## 节点名称,自定义,各个节点不可相同
node.master: true ## 是否作为master节点
node.data: true ## 是否作为数据节点
#node.ingest: true ## 是否作为ingest节点,ingest节点则可以对数据进行加工,类似logstash的功能,定义一个管道,在索引数据时,通过指定管道进行过滤,再展示出来
path.data: /data/es-data
path.logs: /var/log/elasticsearch/
network.host: 192.168.20.101 ## 本机IP
http.port: 9200 ## 端口,默认9200
discovery.zen.ping.unicast.hosts: ["192.168.20.101", "192.168.20.102"] ## 此集群内所有节点的IP地址,这里没有使用自动发现,而是指定地址发现,因为规模较小
discovery.zen.minimum_master_nodes: 1 ##设置这个参数来保证集群中的节点可以知道其它N个有master资格的节点,默认为1,推荐设置为集群master节点数/2 +1 。有一定的防止脑裂的功能。
#下面三个参数的配置是解决集群内部超时
discovery.zen.fd.ping_timeout: 120s #超时时间设为2分钟。
discovery.zen.fd.ping_retries: 6 #测试次数为6次,超过6次则认为该节点同master已经脱离了默认是3次。
discovery.zen.fd.ping_interval: 30s #节点每隔30s同master发送1次心跳,默认是1秒太频繁了。按上述配置配置完成所有节点后,启动elasticsearch还是会报错,最常见的报错有如下几种原由,根据日志报错信息可以很容易分辨原由:
1.文件最大打开数没有65536,解决办法:修改系统最大文件打开数
# vim /etc/security/limits.conf ##添加如下两行,保存后重新登陆用户及生效
* soft nofile 65536
* hard nofile 65536 2.vm.mx_map_count 太小,没有262144
# vim /etc/sysctl.conf # 添加下面一行
vm.max_map_count = 262144
# systcl -p ## 加载配置 3.内存不足,elasticsearch默认是使用2G内存,在jvm的配置里可以自定义配置,在上述配置中我没有配置锁定内存,但如果有需要配置锁定内存,则很可能会报错锁定内存不足,解决办法,修改最大锁定内存。
# vim /etc/security/limits.conf ## 添加下面一行,保存退出,重新登陆生效
work - memlock unlimited 启动:分别启动各个节点,查看日志,显示成功启动,选举出master即可。
# /usr/local/elk/elasticsearch-6.0.0/bin/elasticsearch启动之后,可以通过访问IP的9200端口判断elasticsearch是否启动成功,访问返回elasticsearch节点信息则为成功启动。
通过访问http://192.168.20.101:9200/_cluster/health?pretty网址来查看集群状态,成功的话,则会出现集群的名称,节点数量。集群状态可分为绿色,黄色,红色。绿色则为正常运行。
部署kibana
解压下载好的kibana安装包到/usr/local/elk/内,修改配置文件:
# grep ^[a-z] /usr/local/elk/kibana-6.0.0-linux-x86_64/config/kibana.yml
server.port: 5601## kibana默认端口
server.host: "192.168.20.101"## 服务的host,直接填本机IP即可。
elasticsearch.url: "http://192.168.20.101:9200"## elasticsearch的连接地址,集群时,连接其中一台节点即可。启动:
# /usr/local/elk/kibana-6.0.0-linux-x86_64/bin/kibana第一次访问,会要求创建索引,但是因为并没有数据,所以没办法创建,这是正常的,目前暂不用进去,只要能看到界面则OK了,日后完整搭建后,会再提到。
如果单独一台机器做kibana,同样需要在该机器上安装elasticsearch,需要将配置文件中的node.master和node.data修改为false。kibana配置文件中的elasticsearch.url指向本机es地址即可。
node.master: false #主要是这两个地方改成false
node.data: false部署logstash
解压下载好的logstash安装包到/usr/local/elk/内,修改配置文件:
# vim /usr/local/elk/logstash-6.0.0/config/logstash.yml
http.host: "0.0.0.0" ##修改host为0.0.0.0,这样别的电脑就可以连接整个logstash,不然只能本机连接。要启动logstash,还需要一个配置文件,来配置logstash过滤解析日志信息的规则,这个规则的配置文件则是需要自行定义,logstash对于这个规则的插件有很多,常用的有grok,kv,geoip等,这个配置文件需要有一个入口,和一个出口,中间是过滤器,一共三大部分。入口的话,根据我们的架构,是通过redis,将日志信息输入到logstash,所以入口配置为redis即可,而出口则是后面的elasticsearch数据存储器,所以出口也固定了,所以需要根据实际情况自定义的主要就是中间的过滤器filter。
安装完成后测试:标准输入到标准输出
# /usr/local/elk/logstash-6.2.3/bin/logstash -e 'input { stdin{type=>stdin}} output { stdout {codec=>rubydebug}}'
Sending Logstash's logs to /usr/local/elk/logstash-6.2.3/logs which is now configured via log4j2.properties
[2018-04-23T19:22:28,848][INFO ][logstash.modules.scaffold] Initializing module {:module_name=>"fb_apache", :directory=>"/usr/local/elk/logstash-6.2.3/modules/fb_apache/configuration"}
[2018-04-23T19:22:28,878][INFO ][logstash.modules.scaffold] Initializing module {:module_name=>"netflow", :directory=>"/usr/local/elk/logstash-6.2.3/modules/netflow/configuration"}
[2018-04-23T19:22:29,454][WARN ][logstash.config.source.multilocal] Ignoring the 'pipelines.yml' file because modules or command line options are specified
[2018-04-23T19:22:29,498][INFO ][logstash.agent ] No persistent UUID file found. Generating new UUID {:uuid=>"59da1e55-b644-43d0-97e4-e39c51cb57d9", :path=>"/usr/local/elk/logstash-6.2.3/data/uuid"}
[2018-04-23T19:22:30,208][INFO ][logstash.runner ] Starting Logstash {"logstash.version"=>"6.2.3"}
[2018-04-23T19:22:30,660][INFO ][logstash.agent ] Successfully started Logstash API endpoint {:port=>9600}
[2018-04-23T19:22:33,832][INFO ][logstash.pipeline ] Starting pipeline {:pipeline_id=>"main", "pipeline.workers"=>12, "pipeline.batch.size"=>125, "pipeline.batch.delay"=>50}
[2018-04-23T19:22:34,056][INFO ][logstash.pipeline ] Pipeline started succesfully {:pipeline_id=>"main", :thread=>"#<Thread:0x8cb5633 sleep>"}
The stdin plugin is now waiting for input:
[2018-04-23T19:22:34,132][INFO ][logstash.agent ] Pipelines running {:count=>1, :pipelines=>["main"]}
{
"type" => "stdin",
"message" => "",
"host" => "ELK",
"@version" => "1",
"@timestamp" => 2018-04-23T11:23:18.110Z
}
test
{
"type" => "stdin",
"message" => "test",
"host" => "ELK",
"@version" => "1",
"@timestamp" => 2018-04-23T11:23:24.892Z
}logstash可以同时输出多份,如可以将内容同时输出到es和标准输出中:
# /usr/local/elk/logstash-6.2.3/bin/logstash -e 'input { stdin{ type=>stdin }} output { elasticsearch { hosts => ["192.168.20.100:9200"]} stdout {codec =>rubydebug}}'配置示例:
# cat test.conf
input {
redis {
data_type => "list"
db => "10"
key => "nginx-access"
host => "192.168.20.101"
port => "6379"
}
}
output {
elasticsearch {
hosts => ["192.168.20.101:9200","192.168.20.102:9200"]
index => "nginx-access"
user => "elastic" #elasticsearch 的用户密码,需要安装x-pack才会有
password => "elastic"
}
}部署redis
在这个架构中,redis用来做消息管道,用来缓存储峰值数据等。并不需要特别的设置,直接安装一个redis服务即可。因为知识用来一个管道,所以基本并不消耗redis的内存磁盘的存储资源,就像一个中转站,先放一下,马上就被取走。没有数据或数据量较小的时候哦。在redis中看不到任何数据,要像测试filebeat是否正常输出到redis,就要将logstash关掉,然后启动filebeat,观察redis中指定数据库中的数据,然后再开启logstash,会发现redis中的数据以可观的速度在开始减少,直到刷新不出数据。则验证了filebeat –> redis –> logstash 的管道的连通性。
可以根据需求来调整redis的监听地址,默认监听127.0.0.1
部署 filebeat
filebeat是5.x版本后的采集器beats中的其中一个,用于对日志文件的数据进行采集,简单处理,发送给logstash,elasticsearch,kafka,redis等。这里我们是发送给redis。
下载安装:
# wget https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-6.0.0-x86_64.rpm
# rpm -ivh filebeat-6.0.0-x86_64.rpm配置示例:
# vim /etc/filebeat/filebeat.yml
filebeat.prospectors:
- type: log
enabled: true
paths:
- /var/log/nginx/access_json.log
output.redis:
hosts: ["192.168.20.101"]
port: 6379
key: "nginx-access"
db: "10"启动:
# systemctl start filebeat部署x-pack
x-pack是一个拓展功能集合的插件包,可以实现安全防护,实时监控,生成报告等拓展功能,用的最多的就是安全防护功能,默认的ELK是没有密码认证的,直接就可以登陆的,加载了x-pack后,则可以使用密码认证,证书认证等功能,来实现ELK软件之间的相互认证。
取官网下载对应版本的x-pack的插件包,然后利用本地文件安装,官网上是写的自动用网络下载安装,但由于下载速度奇慢,其x-pack较大,每个都自动安装则要重复下载多次。这里用文件本地安装:
# wget https://artifacts.elastic.co/downloads/packs/x-pack/x-pack-6.0.0.zip
# /usr/local/elk/elasticsearch-6.0.0/bin/elasticsearch-plugin install file:///usr/local/src/x-pack-6.0.0.zip
# /usr/local/elk/logstash-6.0.0/bin/logstash-plugin install file:///usr/local/src/x-pack-6.0.0.zip
# /usr/local/elk/kibana-6.0.0-linux-x86_64/bin/kibana-plugin install file:///usr/local/src/x-pack-6.0.0.zip如果是集群架构,则每一台新机器都需要安装插件
安装后,默认的用户密码为: user:elastic password:changeme
为elastic, kibana, and logstash_system users设置新的密码:
# bin/x-pack/setup-passwords interactive如果登录失败的话可以添加内置角色,登陆成功后在修改密码
/usr/local/elk/elasticsearch-6.0.0/bin/x-pack/users useradd root -p 123456 -r superuserx-pack有很多内置角色,具体可以看官方说明superuser是最高权限,详见: https://www.elastic.co/guide/en/x-pack/current/built-in-roles.html
修改配置:
需要修改配置,添加免密认证,才能正常的让logstash连接到elasticsearch,kibana连接elasticsearch。
修改kiban配置,新增下面两行配置,然后重启:
# vim /usr/local/elk/kibana-6.0.0-linux-x86_64/config/kibana.yml
elasticsearch.username: "elastic"
elasticsearch.password: "elastic"修改logstash的配置,新增下面三行,然后重启:
# vim /usr/local/elk/logstash-6.0.0/config/logstash.yml
xpack.monitoring.elasticsearch.url: "http://192.168.20.101:9200"
xpack.monitoring.elasticsearch.username: "logstash_system"
xpack.monitoring.elasticsearch.password: "elastic" 修改logstash指定运行的自定义过滤规则的配置文件,在输出到elasticsearch时需要添加用户密码验证。
# vim /root/test.conf output {
elasticsearch {
hosts => ["192.168.20.101:9200","192.168.20.102:9200"]
index => "nginx-access"
user => "elastic"
password => "elastic"
}
} 如果想取消登录验证,则在elasticsearch和kibana、logstash的配置里分别加入
xpack.security.enabled: false至此,ELK日志分析平台部署完成。通过一个简单的日志收集看一下效果:
以nginx日志为例:(json格式)

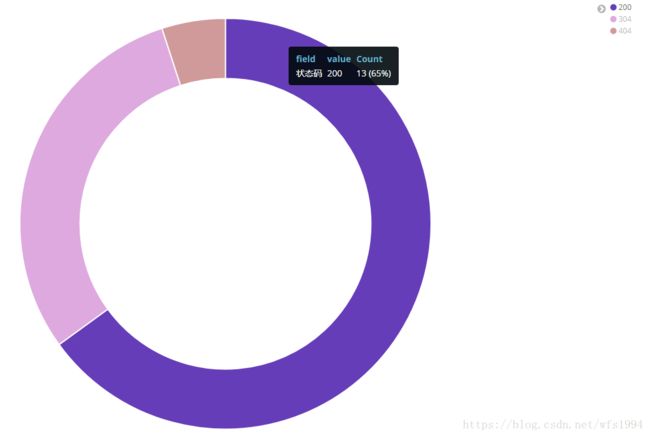
filebea和logstash配置如下:
#filebeat
# vim /etc/filebeat/filebeat.yml
filebeat.prospectors:
- type: log
enabled: true
paths:
- /var/log/nginx/access_json.log
output.redis:
hosts: ["192.168.20.101"]
port: 6379
key: "nginx-access"
db: "10"
#logstash
# cat test.conf
input {
redis {
data_type => "list"
db => "10"
key => "nginx-access"
host => "192.168.20.101"
port => "6379"
}
}
filter {
json {
source => "message"
remove_field => ["beat","message"]
}
}
output {
elasticsearch {
hosts => ["192.168.20.101:9200","192.168.20.102:9200"]
index => "nginx-access"
user => "elastic" #elasticsearch 的用户密码,需要安装x-pack才会有
password => "elastic"
}
}