深度进化网络结构表示:利用进化计算自动设计人工神经网络

文章来源:ATYUN AI平台
深度进化网络结构表示(DENSER)是一种利用进化计算自动设计人工神经网络(ANNs)的新方法。该算法不仅搜索最优的网络拓扑(network topology),而且还对超参数(如学习或数据扩充参数)进行调优。自动设计是通过一个具有两个不同层次的表示来实现的,外部层对网络的一般结构进行编码,内部层编码与每个层相关联的参数。被认可的层和超参数值范围是由人类可读的上下文无关文法(Context-Free Grammar)定义的。这项工作的主要贡献是:
- 深度进化网络结构表示是一个基于进化原理的通用框架,它自动搜索有不同层类型和/或层目标的大型深度网络的适当结构;
- 一个自动生成的、没有任何先验知识的卷积神经网络(CNN)对于CIFAR-10数据集的分类是有效的,平均准确率为94.27%;
- 这是人工神经网络的进化过程变得更加密集的一种证明。在具体的情况下,CIFAR-10数据集的平均准确率为78.75%,这个数据是通过一个进化成CIFAR-10数据集的网络拓扑获得的。据我们所知,这是通过自动设计卷积神经网络的方法报告了CIFAR-10数据集的最佳结果。
受过最好训练的模型可以在右边链接中找到:https://git.io/vntyv
建议的方法:深度进化网络结构表示
为了促进结构和参数的进化,我们提出了深度进化网络结构表示。它聚集了遗传算法(GA)和动态结构语法进化(DSGE)的基本思想。
表示(representation)
每个解决方案通过一组有序的前馈层和各自的参数对人工神经网络进行编码;其他任何超参数都可以被编码到每个个体的编码中。候选解决方案的表示是在两个不同的级别上进行的:
- GA级别:对网络的宏观结构进行编码,并负责表示层的序列,这些层随后作为语法起始符号的指示符。它需要对网络允许的结构进行定义,即:层的有效序列。
- DSGE级别:编码与一个层相关的参数。参数及其允许的值或范围被编码到必须由用户定义的语法中。
交叉(crossover)
根据不同的基因水平,提出了两种交叉算子(crossover operator)。在当前的工作环境中,一个模块不支持一组可以多次复制的层,而是属于同一GA结构索引的一组层。
考虑到所有的个体都有相同的模块(可能有不同的层数),第一个交叉算子是一个单点交叉,它在同一个模块内改变了两个个体之间的层。
第二个交叉算子是一个统一的交叉,它改变了两个个体之间的整个模块。
突变(Mutation)
我们开发了一组突变算子,专门用于促进人工神经网络的进化。在GA级别上,突变的目标是操纵网络的结构:
- 添加层:一个新的层是根据被放置层的模块的起始符可能性而生成的
- 复制层:一个层被随机选择,并复制到模块的另一个有效位置。副本由引用(reference)制成,即:如果一个参数在层中被改变,所有的副本都会被修改
- 移除图层:从指定的模块中选择和删除一个图层
上述突变算子仅在网络的一般结构上起作用;为了改变这些层的参数,以下的DSGE突变被使用:
- 语法突变:一个扩展可能性被另一个取代
- 整数突变:生成一个新的整数值(在允许范围内)
- 浮动突变:在给定的float value中应用高斯摄动
实验结果
为了测试这种方法,我们对卷积神经网络的生成进行了实验,以进行CIFAR-10数据集基准的分类。CIFAR-10数据集是由60000个实例组成的,每一个实例都是32×32 RGB的彩色图像。深度进化网络结构表示的解决方案被映射到keras模型,这样它们的性能就可以被度量。任务的目标是对目标识别任务的准确性进行最大化。
为了分析进化的拓扑结构的普遍化和可伸缩性能力,我们采用了最好的卷积神经网络拓扑,并在CIFAR-10基准的分类上对它们进行了测试。
卷积神经网络在CIFAR-10数据集上的进化
我们在卷积神经网络的生成上进行了10次进化运行,以进行CIFAR-10数据集的分类。对于生成的网络,我们分析它们的适应性(例如:在分类任务上的准确性),以及隐藏层的数量。
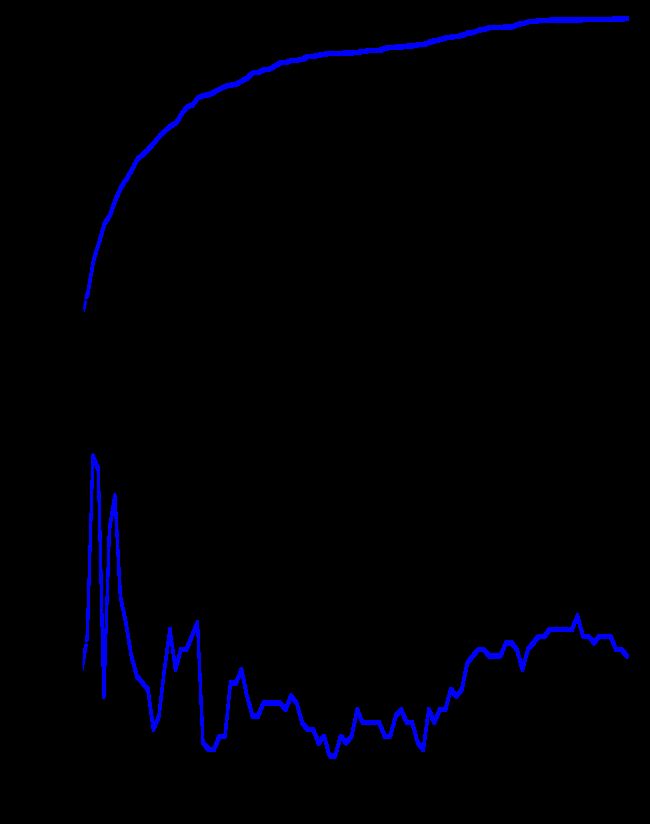
图1:适应度(fitness)的进化(上图)和隐藏层的数量(下图)
对结果的简要分析表明,进化正在发生,而解决方案趋向于在第80代(generation)周围聚集。两种不同的、相互矛盾的行为是可以观察到的。从进化的开始直到大约第60代的性能增加,层数会不断地减少;从第60代到最后一代,在性能提升之后,最好的网络的隐藏层数量也在增加。这一分析揭示了一个明显的矛盾,即在第一代随机生成的解决方案中有大量的层,这些层的参数是随机设置的。

图2:深度进化网络结构表示找到的最好的网络拓扑结构
图2展示了在进化过程中发现的最适当的网络(在验证精度方面)。进化的网络最令人费解的特征是在拓扑学结束时使用的密集层的重要性和数量。据我们所知,大量密集层的连续使用是前所未有的,并且人类永远不会想到这样的拓扑学(使进化的结果变得显著)。
一旦进化过程完成,在每次运行中发现的最好的网络被重新训练了5次。首先,我们用在进化过程中使用的相同的学习速率来训练网络(lr=0.01),但在400个epoch(而不是10个)。这个设置让我们在测试集上获得了88.41%的分类精度。为了进一步加强网络的准确性,我们为每个实例的测试集产生100张增强图像,并且预测是在100张增强图像上提取的平均信任值的最大值。在进行了这种验证方法之后,最好的进化网络的测试集的平均准确率提高到89.93%。
为了调查是否有可能提高最好的网络的性能,我们用同样的CGP-CNN策略来重新训练它们:一个从0.01开始变化的学习速率;在第5个epoch,它增加到0.1;到了第250个epoch,它降到了1.01;最后,在第37个epoch,它变成了0.001。在以往的训练政策中,最适当的网络的平均准确率提高到93.38%。如果在测试集上执行数据扩充,那么平均准确率将达到94.13%。平均误差为5.87%。

图3:CIFAR-10数据集产生的结果
图3显示了与其他方法报告的最佳结果的比较。结果表明深度进化网络结构表示是报告中精度最高的方法之一。在我们的方法中,可训练参数的数量要高得多,因为我们允许在进化的卷积神经网络中放置完全连通的层。此外,在进化过程中,没有先验知识用于对搜索空间(search space)的偏见。
对CIFAR-100数据集一般化
为了测试进化网络的一般化和可伸缩性,我们采用了由CIFAR-100数据集生成的最好的网络,并将其应用到CIFAR-100数据集的分类中。为了让网络在CIFAR-100数据集上工作,我们只改变了softmax层的100个输出神经元,而不是10个。
每个网络的训练都是随机的;初始条件是不同的,并且它们由于数据扩充过程使用不同的数据集实例进行训练。因此,为了进一步提高结果,我们研究了格雷厄姆(Graham)提出的方法,来测试分数的最大池化的性能是否提高了我们网络的性能。简而言之,不是一个单一的网络,而是一个整体被使用,在这个网络中,每一个组成部分的网络都是独立的网络训练的结果。采用这种方法,同一网络的一个整体被训练了5次,测试精度为77.51%,10次训练的测试精度为77.89%,12次训练的整体测试精度为78.14%。这些结果的表现超过了那些为卷积神经网络的进化而采用的数据扩充方法的文献。
此外,代替相同的网络结构形成的集合体,我们还测试了构建一个由深度进化网络结构表示的两个网络拓扑的整体性能,在使用这种方法后,精度提高到了78.75%。

图4:CIFAR-100数据集产生的结果
图4显示了与其他方法相比,在CIFAR-100数据集通过深度进化网络结构表示获得的结果。
本文转自ATYUN人工智能媒体平台,原文链接:深度进化网络结构表示:利用进化计算自动设计人工神经网络
更多推荐
数据集雪球效应:人工智能是如何改变SaaS的?
IBM为AI设计了一个“性能猛兽”
无人零售背后的秘密:使用Tensorflow目标检测API实现更智能的零售结账
随着AWS竞争加强,谷歌削减了其机器学习服务的价格
 欢迎关注ATYUN官方公众号,商务合作及内容投稿请联系邮箱:[email protected]
欢迎关注ATYUN官方公众号,商务合作及内容投稿请联系邮箱:[email protected]