oracle sql 高级编程学习笔记(二十八)
- 反联结定义
- 1.1、not in 实例演示
- 1.2、not exists实例演示
- 1.3、not in 空值问题
- 1.4、反联结的其他实现形式
- 1.4.1、minus
- 1.4.2、利用外联结
- 二、反联结的必要条件
- 三、反联结的限制条件
- 四、反联结执行计划
- 4.1、not exists 执行计划
- 4.2、没有空值约束的not in 执行计划
- 4.3、空值约束的 not in 执行计划
- 4.4、minus
- 4.5、left outer join
- 五、反联结的控制执行计划
- 5.1、提示控制反联结的执行计划
- 5.1.1 nl_aj
- 5.1.2 hash_aj
- 5.2.1 用参数控制反联结为hash反联结
- 5.2.2 参数关闭半联结
反联结定义
反联结本质上来说与半联结是同样的,它也是一种可以应用于嵌套循环、散列和合并联结的优化方法。
但是返回 数据于方面与半联结是相反的。反联结返回谓语左侧的数据行,如果在谓语右侧没有对应的数据行存在的话,它返回右侧的子查询没有匹配(not in)的数据行,与半联结一样 ,也没有特定的sql语法可以调用反联结。它是当sql中包含not in 或not exists关键字时优化器可以选择的几个选项之一。顺便提一下not in比not exists更常用,可能是它更容易理解。
1.1、not in 实例演示
SELECT dept.department_name
FROM departments dept
WHERE dept.department_id NOT IN
(SELECT emp.department_id FROM employees emp);

1.2、not exists实例演示
SELECT dept.department_name
FROM departments dept
WHERE NOT EXISTS (SELECT 1
FROM employees emp
WHERE dept.department_id = emp.department_id);
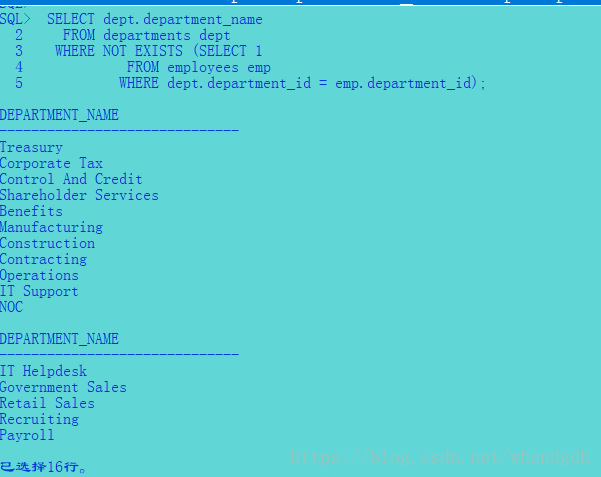
可以发现not in 和not exists返回的结果并不一样,因此功能上也不是等价的。这种差异的原因在于not in运算符返回空值时,则整个查询不会返回任何记录。not in 意思时子查询中找到一条记录,外层循环与之匹配,则这条记录匹配,那这条记录就会被丢弃。如果没有匹配则返回给用户,那如果不知道这条记录是否匹配时怎么办?需要记住的时空值不与人任何值相等,即使是另一个空值。在这种情况下Oracle 选择返回一个false值。
1.3、not in 空值问题
但如果你需求是即使子查询返回空值的时候也返回相应的记录,你可以有下面这些选择
1、在查询所返回的列上应用nvl函数
2、在子查询加上 is not null 谓语
3、实现not null约束
4、不使用not in 使用不关心空值的not exists
加上null 约束的not in常常是最佳选择。
1、 SELECT dept.department_name
FROM departments dept
WHERE dept.department_id NOT IN
(SELECT nvl(emp.department_id,-10) FROM employees emp );
2、 SELECT dept.department_name
FROM departments dept
WHERE dept.department_id NOT IN
(SELECT emp.department_id FROM employees emp where emp.department_id is not null);
1.4、反联结的其他实现形式
1.4.1、minus
minus 形式复杂但返回了正确的数据,并且在功能上与not exsts以及具有空值约束的not in 形式等价。
SELECT dept.department_name
FROM departments dept
WHERE dept.department_id IN (SELECT t.department_id
FROM departments t
MINUS
SELECT emp.department_id
FROM employees emp);
1.4.2、利用外联结
利用外联结为左侧每一条没有匹配数据的记录在右侧创建一个虚拟记录这样一个事实。 通过在外联结加上emp.department_id is null 来得到没有匹配的记录
SELECT dept.department_name
FROM departments dept
LEFT OUTER JOIN employees emp
ON dept.department_id =
emp.department_id
where emp.department_id is null;
二、反联结的必要条件
1、语句必须使用not in(!=any)或 not exists
2、语句必须在not in(!=any)或 not exists子句中有一个子查询
3、not in 或 not exists 子句不能包含在OR分支中
4、not exists 子句的子查询必须与外层查询相关
5、10g需要not in 子查询代码中确定不会返回空值,11g不需要
三、反联结的限制条件
与半联结一样,如果子查询是where子句的OR分支中则不能进行反联结转换。
在10g中主要的限制还是子查询可能会返回空值的子查询不能进行反联结优化,新的anti na (以及 anti sna)使得优化器即使在子查询可能
四、反联结执行计划
反联结的伪代码
Q1外层查询,Q2内层查询(子查询)
open Q1
while Q1 still has records
fetch record from Q1
result=true
open Q2
while Q2 still has records
fetch record from Q2
if(Q1.record matchs Q2.record) then --反联结优化 不用遍历所有的内层记录
result=false --与半联结不同之处
exit loop
end if
end loop
close Q2
if(result=true) reture Q1 record
end loop
close Q1
同样反联结提供子查询中找到第一条匹配记录时跳出内层循环(不用遍历所有的内层记录)的if语句。显然,对于大数据集,与对外层查询中的每一行数据都必须循环读取内层查询返回的所有记录的普通嵌套循环联结相比,这个技术可以节省大量时间。
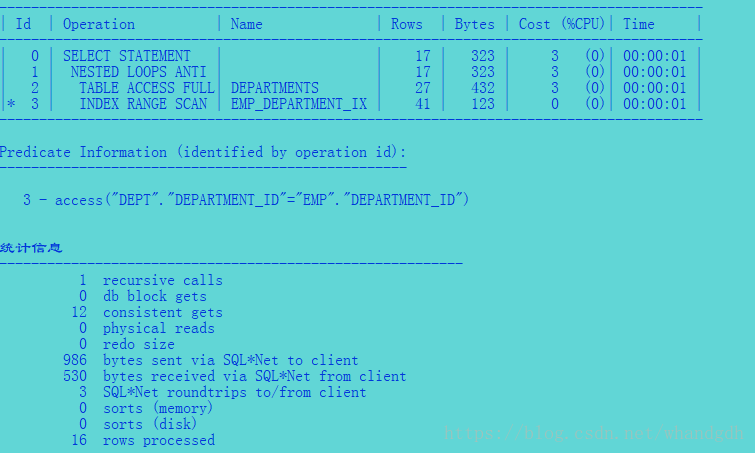
4.1、not exists 执行计划
SELECT dept.department_name
FROM departments dept
WHERE NOT EXISTS (SELECT 1
FROM employees emp
WHERE dept.department_id = emp.department_id);

4.2、没有空值约束的not in 执行计划
SELECT dept.department_name
FROM departments dept
WHERE dept.department_id NOT IN
(SELECT emp.department_id FROM employees emp);
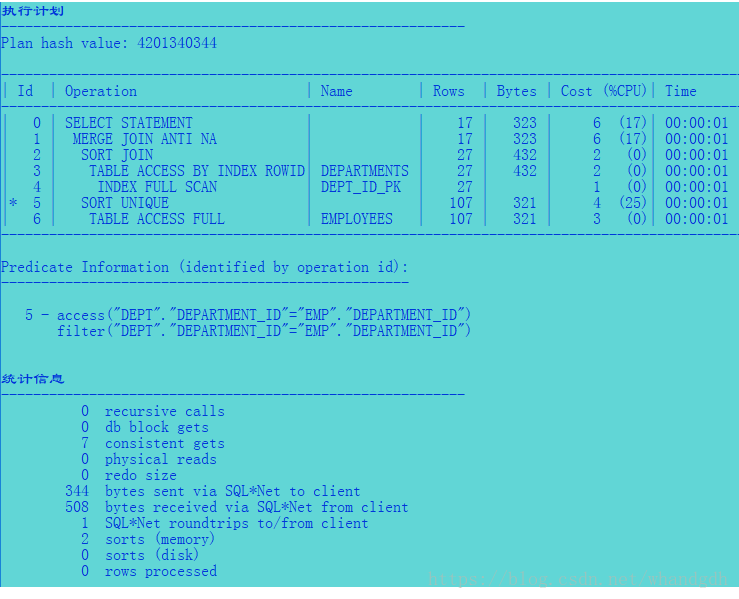
4.3、空值约束的 not in 执行计划
SELECT dept.department_name
FROM departments dept
WHERE dept.department_id NOT IN
(SELECT emp.department_id FROM employees emp where emp.department_id is not null);

注意not exists 语句生成了嵌套循环反联结(nested loops anti) 执行计划,而没有空值约束的not in 语句形成了
合并反联结(merge join anti na).嵌套循环反联结 是子oracle 7i 版本以来的标准反联结形式。 合并联结的anti na 是11g引入的新的优化方法(na 表示考虑空值)。可以看到有空值约束的not in都使用正常的反联结
我们再来看看 minus和 left outer外联结,看看他们会生成怎样的执行计划
4.4、minus
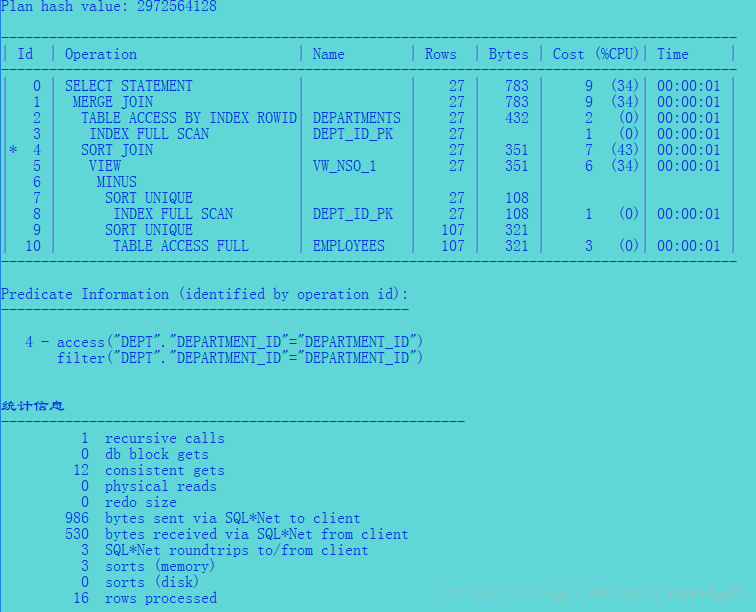
4.5、left outer join

可以看到minus 并没有使用反联结优化方法,而left外联结使用了反联结优化方法
五、反联结的控制执行计划
5.1、提示控制反联结的执行计划
1、antijoin --进行反联结(优化器来决定具体类型)
2、use_anti–antijoin提示的旧版本
3、nl_aj —嵌套循环反联结(10g起弃用)
4、hash_aj——散列反联结 (10g起弃用)
5、merge_aj —合并反联结(10g起弃用)
虽然部分提示在10g开始被弃用了,但是11gR2中任可以使用。
同半联结一样提示都必须在子查询中而不是在外层查询中声明。还需注意的是没有no_antijoin提示
5.1.1 nl_aj
SELECT dept.department_name
FROM departments dept
WHERE NOT EXISTS (SELECT /*+nl_aj*/1
FROM employees emp
WHERE dept.department_id = emp.department_id);
5.1.2 hash_aj
SELECT dept.department_name
FROM departments dept
WHERE NOT EXISTS (SELECT /*+hash_aj*/1
FROM employees emp
WHERE dept.department_id = emp.department_id);

5.2参数控制反联结
1、always_anti
2、_gs_anti_semi_join_allowed
3、_optimizer_null_aware_antijoin
4、_optimizer_outer_to_anti_enabeled
5、_always_anti_join
最主要的参数是_always_anti_join,其行为与_always_semi_join相同(具有相同的有效值和做同样的事情)
SELECT name_kspvld_values NAME, value_kspvld_values VALUE
FROM x$kspvld_values v
WHERE name_kspvld_values = '_always_anti_join';
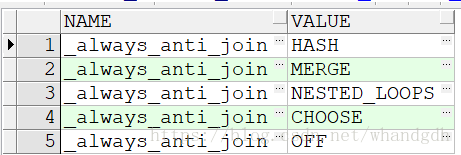
5.2.1 用参数控制反联结为hash反联结
--设置hash反联结
alter session set "_always_anti_join"= HASH ;
SELECT dept.department_name
FROM departments dept
WHERE NOT EXISTS (SELECT 1
FROM employees emp
WHERE dept.department_id = emp.department_id);

5.2.2 参数关闭半联结
alter session set "_always_anti_join"= off ;
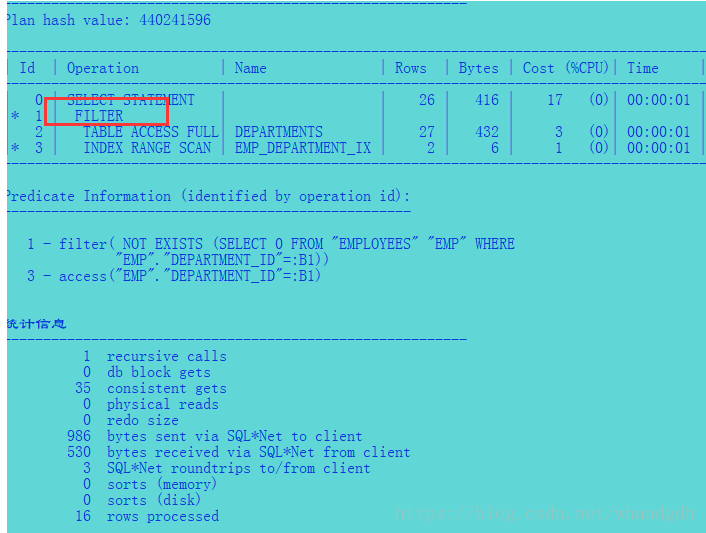
再来看同样sql的执行计划。可以看到没有采用反联结的执行计划,逻辑读取是35,成本是17,而散列反联结的逻辑读是8,成本是5,可见反联结是一种优化的联结方法。