深度学习研究理解5:Visualizing and Understanding Convolutional Networks
Visualizing and understandingConvolutional Networks
本文是Matthew D.Zeiler 和Rob Fergus于(纽约大学)13年撰写的论文,主要通过Deconvnet(反卷积)来可视化卷积网络,来理解卷积网络,并调整卷积网络;本文通过Deconvnet技术,可视化Alex-net,并指出了Alex-net的一些不足,最后修改网络结构,使得分类结果提升。
摘要:
CNN已经获得很好的结果,但是并没有明确的理解为什么CNN会表现的这么好,或者CNN应该怎样修改来提升效果。同构本文的可视化技术,可以很好地“理解”中间的特征层和最后的分类器层。通过类似诊断(可视化+“消除”研究ablation study)的方式,这种可视化技术帮助我们找到了超越Alex-net的结构,本文还通过在ImageNet上训练,然后在其他数据集上finetuning获得了很好的结果。
一,介绍
多项技术帮助CNN复兴(最早是98年,LeCun提出的):1,大的标定数据集;2,Gpu使得大规模计算成为可能;3,很好的模型泛化技术
本文的可视化方法是一种非参数化的可视化技术。
二,方法
首先通过监督的方式利用SGD来训练网络,要了解卷积,需要解释中间层的特征激活值;我们利用Deconvnet来映射特这激活值返回到初始的像素层。
2.1利用Deconvnet

1正常卷积过程convnet:
如图右侧黑框流程图部分,上一层pooled的特征图,通过本层的filter卷积后,形成本层的卷积特征,然后经过ReLU函数进行非线性变换的到Recitifed特征图,再经过本层的max-pooling操作,完成本层的卷积池化操作;之后传入下一层。本层需要记录在执行max-pooling操作时,每个pooing局域内最大值的位置
2选择激活值:
为了理解某一个给定的pooling特征激活值,先把特征中其他的激活值设置为0;然后利用deconvnet把这个给定的激活值映射到初始像素层。
3反卷积过程deconvnet:
3.1Unpooling
顾名思义就是反pooling过程,由于pooling是不可逆的,所以unpooling只是正常pooling的一种近似;通过记录正常pooling时的位置,把传进来的特征按照记录的方式重新“摆放”,来近似pooling前的卷基层特征。如图中彩色部分
3.2Recitfication
通过ReLU函数变换unpooling特征。
3.3Filtering
利用卷积过程filter的转置(实际上就是水平和数值翻转filter)版本来计算卷积前的特征图;从而形成重构的特征。
从一个单独的激活值获得的重构图片类似原始图片的一个部分。
总是感觉这个过程好熟悉,利用SGD训练卷进网络时,误差的反向传递就是这么计算的,如果是mean-pooling就把残差平均分分配到pooling局域,如果是max-pooling只把残差反馈到记录的max-pooling最max的那个位置。
三 训练细节
本文训练的网络,就是把Alex-net的3,4,5层只连接同一个GPU的特征图的局部连接方式,换成了全连接的形式。
参数设置,除了把bias全部设置为0外(Alex-net为了让ReLU尽可能多的提取特征,把一些bias设置为1),其他都和Alex-net一样。
四 CNN可视化
特征可视化
完成训练后,对于一个特征图,选择最大的9个激活值分别进行可视化;
每层可视化特征特点:
1,每张特征图激活值有聚集性;2,高层具有更好的不变性;3,“夸张”的图像判别部分(估计应该是高层特征可视化后能够还原原图的大部分);4,每层的卷积结构能够学习分层的特征。
训练阶段特征演变:

上图展示了各层特征在训练步骤增加时激活值对应特征变化情况;一个比较有意思的现象是底层的卷积最先收敛,高层的特征需要在充分训练后才能收敛。这个和深度网络的梯度弥散现象正好相反,说明ReLU这中非线性函数能够很好的传递误差梯度。这种底层先收敛,高层后收敛比较符合人的直观。
特征不变性

1,对比2,3列图像,2列中的第1层特征对变换前后的欧氏距离相对3列中第7层中变换前后欧氏距离普遍比较大(纵坐标分别为10和0.8相差很大),说明高层更具有特征不变性。
2,从每行对比中,发现卷积对于平移和缩放的不变形更好,对于旋转的不变性较差。高层对于平移的尺度,缩放的倍数与特征改变量成线性增长;对于旋转变换,随着旋转角度的变化,促增长较大外,规律性并不明显。
3,从列7正确标签概率图可以得出,不同类别正确标签的概率不一样,在平移和缩放变换中,其中鹦鹉和鳄鱼的概率比较低,其他种类类别概率比较高。这是为啥?
4.1结构选择
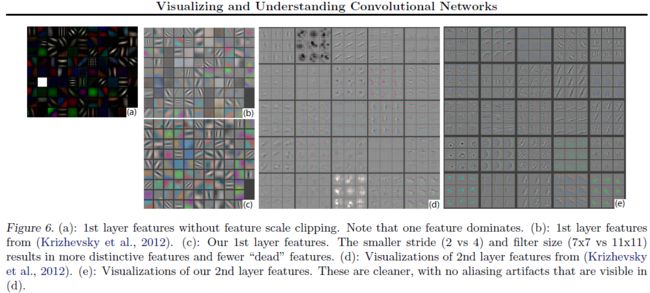
通过可视化Alex-net网络的第1,2层(图中的b和d),发现了各种问题。
问题1:第一层filter是非常高频和低频的信息,中间频率的filter很少覆盖
问题2:第二层的可视化比较混淆,由于第一层比较大的间隔。
为了解决这个问题:
1,减小第一层的filter的尺寸从11*11到7*7
2,缩小间隔,从4变为2。
这两个改动形成的新结构,获取了更多的信息,而且提升了分类准确率。
4.2 遮盖敏感性
对于图像分类,一个自然的想法就是这个模型是真正鉴别了物体在图像中的位置,还是只是使用了周围的场景。本文通过一个灰色方块,遮盖物体的不同位置,然后监控分类器的输出。最后结果证明模型定位了场景中的物体(图示没太看明白)。
4.3关联性分析
深度模型不同意其他识别方法,它没有明显建立对应关系的机制(脸中有鼻子和眼);但是深度模型可能隐士地建立了对应机制。
为了验证这一点,我们随机选择了5张包含狗正脸的图片;然后遮蔽相同的部分来观察。
观察方法:首先计算图片遮蔽前后特征,两个特征向量做差,通过sign来确定符号;然后通过海明距离来计算5张照片两两之间的一致性,然后求和。


有实验结果可以得出,layer-5的特征一致性中,眼和鼻子的数值较低,说明眼和鼻子比其他部分,有更强的相关性,这也说明深度网络能够隐式地建立对应关系。但是在layer-7中眼,鼻子和随机的数值较为相似,可能是因为高层尝试去区分狗的种类。
五,实验
新的结构

Input(224,224,3)→96F(7,7,3,2)→LRN→max-p(3,3,2)→256F(5,5,96,2)→LRN→max-p(3,3,2)→384F(3,3,256,1)→384F(3,3,384,1)→256F(3,3,384,1)→max-p(3,3,2)→4096fc→4096fc→softmax
对比Alex-net本文的结构改进汇总:
1,layer-1的filter尺寸7*7
2,layer-1的间隔距离 S=2
3,全连接,而不是局部连接
4,初始化偏执bias=0.
本文在只用ILSVRC2012数据集的情况下,单个网络获得了16.5%的识别率;超越Alex-net网络1.7%。
变化Alex-net结构:

首先探讨Alex-net,移除的层数越多,对于结果的损害就越大,说明深度很重要。
调整6,7层隐单元的个数,同时减少一倍,导致结果增加;同时增加一倍,结果没有明显变化。同样的调整,在作者的网络上,错误率有一些增加。
调整中间卷基层特征图的个数,结果有一些增加;但是同时增加卷基层和fc层,最后导致过拟合。
感觉网络结构真是一门艺术,多了不行,少了也不行;后面的论文会详细介绍结构调整的各种方案。
5.2 特征推广
探索在ImageNet数据集上通过监督学习到的特征,推广到其他数据集上。具体方法是保持网络的1到7层不变,改变softmax层最终的类别数。
才caltech101和caltech256上都达到了state-of-the-art的准确率;即使在使用很少的训练集的情况下。说明ImageNet特征提取具有很好的特征提取能力。但是在pascal上却比当前最好成绩差3.2%,这是由于pascal数据集和ImageNet数据集有很大的不通过,pascal数据集上有多个物体。
六,讨论
1,提出了一个新颖的可视化方法,通过可视化证明了卷积网络的一些特征,复合性,特征不变性和网络深度的关系;
2,通过可视化还可以调试网络结构,通过遮蔽实验证明网络学习到一种隐士的相关性,通过削减实验证明深度很重要
3,特征推广
七,一些困惑和理解
本文提出了一种新的卷积特征可视化技术,帮助理解卷积网络的特性,以及根据可视化来调整卷积网络。例如训练过程中,层数越深需要迭代的次数越多才能使学习到的特征收敛;卷积网络对于平移和缩放具有很好的不变形,对于旋转的不变形较差;但是在平移和缩放不变形实验中狗和鳄鱼(红线和绿线)的标签概率曲线都比较低,这个平移和缩放不变性对不同的物体差别有些大,到底为啥,没想明白?
本文单个网络比Alex-net提高了1.7%,感觉并不单单是改变filter大小和间隔这两个因素决定,因为作者的参数设置,连接方式都和Alex-net有改变,感觉都有共享。
这个类似迁移学习的特征生成器的方式比较好,由于小数据不能够训练大网络,但是大网络有很好的性能,所以通过类似的数据集来训练大网络来学习到特征提取器,然后改变分类器,在小数据集上微调。感觉作者的想法来源于上一篇博客中,为了提高ImageNet比赛的识别率,有些队伍现在一个比ImageNet比赛数据集还大的数据上训练,然后在比赛数据集上训练;本文作者在ImageNet比赛数据集上训练,然后在其他小数据集上训练,得到了很好的结果。说明数据集很重要,网络深度很重要;若是有更大的数据集,更好的网络,是不是可以建立一个公共的特征提取器,这个很类似余凯提出的公共特征集的概念。