LeetCode上新出的《剑指offer》
文章目录
- 面试题03. 数组中重复的数字
- 面试题04. 二维数组中的查找
- 面试题05. 替换空格
- 面试题06. 从尾到头打印链表
- 面试题07. 重建二叉树
- 面试题09. 用两个栈实现队列
- 面试题10- I. 斐波那契数列
- 面试题10- II. 青蛙跳台阶问题
- 面试题11. 旋转数组的最小数字
- 面试题12. 矩阵中的路径
- 面试题15. 二进制中1的个数
- 面试题16. 数值的整数次方
- 面试题18. 删除链表的节点
- 面试题21. 调整数组顺序使奇数位于偶数前面
- 面试题22. 链表中倒数第k个节点
- 面试题24. 反转链表
- 面试题25. 合并两个排序的链表
- 面试题26. 树的子结构
- 面试题27. 二叉树的镜像
- 面试题28. 对称的二叉树
- 面试题29. 顺时针打印矩阵
- 面试题30. 包含min函数的栈
- 面试题31. 栈的压入、弹出序列
- 面试题32 - I. 从上到下打印二叉树
- 面试题32 - II. 从上到下打印二叉树 II
- 面试题32 - III. 从上到下打印二叉树 III
- 面试题33. 二叉搜索树的后序遍历序列
- 面试题35. 复杂链表的复制
- 面试题40. 最小的k个数
- 面试题41. 数据流中的中位数
- 面试题42. 连续子数组的最大和
- 面试题50. 第一个只出现一次的字符
- 面试题53 - II. 0~n-1中缺失的数字
- 面试题55 - I. 二叉树的深度
- 面试题56 - I. 数组中数字出现的次数
- 面试题56 - II. 数组中数字出现的次数 II
- 面试题57. 和为s的两个数字
- 面试题57 - II. 和为s的连续正数序列
- 面试题60. n个骰子的点数
- 面试题64. 求1+2+…+n
- 面试题68 - I. 二叉搜索树的最近公共祖先
- 面试题68 - II. 二叉树的最近公共祖先
面试题03. 数组中重复的数字
找出数组中重复的数字。
在一个长度为 n 的数组 nums 里的所有数字都在 0~n-1 的范围内。数组中某些数字是重复的,但不知道有几个数字重复了,也不知道每个数字重复了几次。请找出数组中任意一个重复的数字。
解题思路: 初步思考本题有3种做法,1.用hash记录每个元素出现的次数,这个的时间复杂度是O(n),但是空间复杂度O(n); 2. 对数组进行排序,相邻的元素若相等,则这个元素可以视为重复;方法1和方法2都没有考虑到n个数组全部都在0~n-1的范围内这个条件,因此方法3是遍历数组的过程中,若遍历到位置i发现位置i上的数字(数字为m)不等于i,看数字m与位置m上的数字是否相等,若相等则知道重复的元素,否则,遍历下一个元素。具体的可参考剑指offer书上第39页的介绍。
解法一:
class Solution {
public:
int findRepeatNumber(vector<int>& nums) {
sort(nums.begin(), nums.end());
for (int i = 0; i < nums.size() - 1; ++i) {
if (nums[i] == nums[i + 1]) return nums[i];
}
return -1;
}
};
解法二:
class Solution {
public:
int findRepeatNumber(vector<int>& nums) {
unordered_map<int, int> m;
for (int i = 0; i < nums.size(); ++i) {
++m[nums[i]];
}
for (auto a : m) {
if (a.second != 1) return a.first;
}
return -1;
}
};
解法三:
class Solution {
public:
int findRepeatNumber(vector<int>& nums) {
for (int i = 0; i < nums.size(); ++i) {
if (nums[i] != i) {
if (nums[i] == nums[nums[i]]) {
return nums[i];
} else {
swap(nums[i], nums[nums[i]]);
}
}
}
return -1;
}
};
面试题04. 二维数组中的查找
在一个 n * m 的二维数组中,每一行都按照从左到右递增的顺序排序,每一列都按照从上到下递增的顺序排序。请完成一个函数,输入这样的一个二维数组和一个整数,判断数组中是否含有该整数。
解题思路: 本题的数字特征是每行上从左至右递增,从上至下递增。那么如果我们想用类似二分查找的方式查到给定的数。那么此题的难点就在于当发现遍历的数与查找数不相等时,接下来是向哪个方向查找?正确的方法是,若我们从数组的右上角开始查找,在数组的左下角结束查找,则能规避上面的问题,具体的是:当我们发现当前的遍历的数字(设为A)与查找数(设为target)相等时,则找到,否则,若A>target,说明我们target可能在A的左边,否则在下边。直接看代码。
class Solution {
public:
bool findNumberIn2DArray(vector<vector<int>>& matrix, int target) {
if (matrix.empty() || matrix[0].empty()) return false;
int n = matrix.size(), m = matrix[0].size();
int row = 0, col = m - 1;
while (row < n && col >= 0) {
if (matrix[row][col] == target) return true;
else if (matrix[row][col] < target) ++row;
else --col;
}
return false;
}
};
面试题05. 替换空格
请实现一个函数,把字符串 s 中的每个空格替换成"%20"。
解题思路: 简单题,直接看代码。
class Solution {
public:
string replaceSpace(string s) {
string res;
for (auto c : s) {
if (c == ' ') {
res += "%20";
} else {
res.push_back(c);
}
}
return res;
}
};
面试题06. 从尾到头打印链表
输入一个链表的头节点,从尾到头反过来返回每个节点的值(用数组返回)。
解题思路: 若在O(1)空间复杂度下解题的话,可以选择修改链表的结构,即先将链表倒置,然后再遍历。
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode(int x) : val(x), next(NULL) {}
* };
*/
class Solution {
public:
vector<int> reversePrint(ListNode* head) {
if (!head) return {};
ListNode *pre = NULL;
while (head) {
ListNode *next = head->next;
head->next = pre;
pre = head;
head = next;
}
vector<int> res;
while (pre) {
res.push_back(pre->val);
pre = pre->next;
}
return res;
}
};
面试题07. 重建二叉树
输入某二叉树的前序遍历和中序遍历的结果,请重建该二叉树。假设输入的前序遍历和中序遍历的结果中都不含重复的数字。

解题思路: 经典题,遍历的时候找到对应的左子树和右子树的边界即可解题。
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode(int x) : val(x), left(NULL), right(NULL) {}
* };
*/
class Solution {
public:
TreeNode* helper(vector<int> &preorder, int l1, int r1, vector<int>& inorder, int l2, int r2) {
if (l1 > r1 || l2 > r2) return NULL;
int idx = l2;
while (idx <= r2 && inorder[idx] != preorder[l1]) ++idx;
TreeNode *root = new TreeNode(preorder[l1]);
root->left = helper(preorder, l1 + 1, l1 + idx - l2, inorder, l2, idx - 1);
root->right = helper(preorder, l1 + idx - l2 + 1, r1, inorder, idx + 1, r2);
return root;
}
TreeNode* buildTree(vector<int>& preorder, vector<int>& inorder) {
if (preorder.size() != inorder.size()) return NULL;
int n = preorder.size();
return helper(preorder, 0, n - 1, inorder, 0, n - 1);
}
};
面试题09. 用两个栈实现队列
用两个栈实现一个队列。队列的声明如下,请实现它的两个函数 appendTail 和 deleteHead ,分别完成在队列尾部插入整数和在队列头部删除整数的功能。(若队列中没有元素,deleteHead 操作返回 -1 )
解题思路: 先定义两个栈(st1,st2),然后入队很好处理,直接将元素压栈,出队的时候,要从栈st2中出,这时候需要先判断以下栈st2是否为空,若为空,则将栈st1中的元素全部压入到栈st2中,然后出队。
class CQueue {
public:
CQueue() {
}
void appendTail(int value) {
st1.push(value);
}
int deleteHead() {
if (st2.empty()) {
while (!st1.empty()) {
st2.push(st1.top());st1.pop();
}
}
if (!st2.empty()) {
int res = st2.top(); st2.pop();
return res;
} else {
return -1;
}
}
private:
stack<int> st1, st2;
};
/**
* Your CQueue object will be instantiated and called as such:
* CQueue* obj = new CQueue();
* obj->appendTail(value);
* int param_2 = obj->deleteHead();
*/
面试题10- I. 斐波那契数列
写一个函数,输入 n ,求斐波那契(Fibonacci)数列的第 n 项。斐波那契数列的定义如下:
F(0) = 0, F(1) = 1
F(N) = F(N - 1) + F(N - 2), 其中 N > 1.
斐波那契数列由 0 和 1 开始,之后的斐波那契数就是由之前的两数相加而得出。
答案需要取模 1e9+7(1000000007),如计算初始结果为:1000000008,请返回 1。
解题思路: 常规题,直接看代码。
class Solution {
public:
int fib(int n) {
if (n == 0) return 0;
if (n == 1) return 1;
long a = 0, b = 1, M = 1e9 + 7;
for (int i = 0; i < n; ++i) {
long t = b;
b = (a + b) % M;
a = t;
}
return a;
}
};
面试题10- II. 青蛙跳台阶问题
一只青蛙一次可以跳上1级台阶,也可以跳上2级台阶。求该青蛙跳上一个 n 级的台阶总共有多少种跳法。
答案需要取模 1e9+7(1000000007),如计算初始结果为:1000000008,请返回 1。

解题思路: 此题属于斐波那契数列的应用。
class Solution {
public:
int numWays(int n) {
if (n == 0) return 1;
if (n == 1) return 1;
long a = 0, b = 1, M = 1e9 + 7;
for (int i = 0; i < n; ++i) {
long t = b;
b = (a + b) % M;
a = t;
}
return b;
}
};
面试题11. 旋转数组的最小数字
把一个数组最开始的若干个元素搬到数组的末尾,我们称之为数组的旋转。输入一个递增排序的数组的一个旋转,输出旋转数组的最小元素。例如,数组 [3,4,5,1,2] 为 [1,2,3,4,5] 的一个旋转,该数组的最小值为1。

解题思路: 本题的主体依然是使用二分查找,我们知道二分查找的一个关键点是如何选择判定条件以及左右边界该如何向中间缩进。本题的缩进其实可以这么理解,我们知道旋转数组的几何形态是左边界往右呈上升(区间A),右边界往左呈下降(区间B),因此我们只需知道中间点与左右边界点的大小关系,即可知道中间点是在哪个区间,若中间点在区间A上,则知道最小值一定在中间点的右边,但至少我们知道能将此时的左边界缩减到此时的中间点上,右边界也同理,这样反复循环最终能讲左右边界缩进到相距一个间隔。当然此题需要考虑序列不严格递增的情况。 下面看代码。
class Solution {
public:
int helper(vector<int>& numbers, int left, int right) {
int mn = INT_MAX;
for (int i = left; i <= right; ++i) {
mn = min(mn, numbers[i]);
}
return mn;
}
int minArray(vector<int>& numbers) {
int n = numbers.size(), left = 0, right = n - 1, mid = left;
while (numbers[left] >= numbers[right]) {
if (right - left == 1) {
mid = right;
break;
}
mid = (left + right) / 2;
if (numbers[mid] == numbers[left] && numbers[mid] == numbers[right]) {
return helper(numbers, left, right);
} else if (numbers[mid] >= numbers[left]) left = mid;
else if (numbers[mid] <= numbers[right]) right = mid;
}
return numbers[mid];
}
};
面试题12. 矩阵中的路径
请设计一个函数,用来判断在一个矩阵中是否存在一条包含某字符串所有字符的路径。路径可以从矩阵中的任意一格开始,每一步可以在矩阵中向左、右、上、下移动一格。如果一条路径经过了矩阵的某一格,那么该路径不能再次进入该格子。例如,在下面的3×4的矩阵中包含一条字符串“bfce”的路径(路径中的字母用加粗标出)。
[[“a”,“b”,“c”,“e”],
[“s”,“f”,“c”,“s”],
[“a”,“d”,“e”,“e”]]
但矩阵中不包含字符串“abfb”的路径,因为字符串的第一个字符b占据了矩阵中的第一行第二个格子之后,路径不能再次进入这个格子。
解题思路: dfs解题。
class Solution {
public:
bool dfs(vector<vector<char>>& board, string word, int &start, int r, int c, vector<vector<bool>>& visited) {
int n = board.size(), m = board[0].size();
if (start == word.size()) {return true;}
bool res = false;
if (r >= 0 && r < n && c >= 0 && c < m && !visited[r][c] && board[r][c] == word[start]) {
visited[r][c] = true;
++start;
res = dfs(board, word, start, r - 1, c, visited) ||
dfs(board, word, start, r + 1, c, visited) ||
dfs(board, word, start, r, c - 1, visited) ||
dfs(board, word, start, r, c + 1, visited);
if (!res) {
--start;
visited[r][c] = false;
}
}
return res;
}
bool exist(vector<vector<char>>& board, string word) {
int n = board.size(), m = board[0].size();
vector<vector<bool>> visited(n, vector<bool>(m, false));
int start = 0;
for (int i = 0; i < n; ++i) {
for (int j = 0; j < m; ++j) {
if (dfs(board, word, start, i, j, visited)) {
return true;
}
}
}
return false;
}
};
面试题15. 二进制中1的个数
请实现一个函数,输入一个整数,输出该数二进制表示中 1 的个数。例如,把 9 表示成二进制是 1001,有 2 位是 1。因此,如果输入 9,则该函数输出 2。

解题思路: 简单题,直接看代码。
class Solution {
public:
int hammingWeight(uint32_t n) {
int res = 0;
for (int i = 0; i < 32; ++i) {
int mask = (1 << i);
if (n & mask) ++res;
}
return res;
}
};
面试题16. 数值的整数次方
实现函数double Power(double base, int exponent),求base的exponent次方。不得使用库函数,同时不需要考虑大数问题。
解题思路: 解出此题不难,但是有几个测试点需要考虑,即int型在取相反数时候溢出的、直接迭代求次方时间复杂度为O(n),其实可以达到O(logn)的复杂度,方法是当我们已经取得了 a x a^x ax值时,可以用 a x ∗ a x a^x*a^x ax∗ax求 a 2 x a^{2x} a2x,这样时间复杂度可以达到O(logn).直接看代码:
class Solution {
public:
double helper(double x, long n) {
if (n == 0) return 1;
if (n == 1) return x;
if (n & 1) {
double tmp = helper(x, (n - 1) / 2);
return tmp * tmp * x;
} else {
double tmp = helper(x, n / 2);
return tmp * tmp;
}
}
double myPow(double x, int n) {
if (x == 0 && n == 0) return -1;
if (n == 0) return 1.0;
int sign = 1;
long exp = n;
if (exp < 0) {
sign = -1;
exp = -exp;
}
double res = helper(x, exp);
return sign == 1 ? res : 1 / res;
}
};
面试题18. 删除链表的节点
给定单向链表的头指针和一个要删除的节点的值,定义一个函数删除该节点。
返回删除后的链表的头节点。
注意:此题对比原题有改动

说明:
题目保证链表中节点的值互不相同
若使用 C 或 C++ 语言,你不需要 free 或 delete 被删除的节点
解题思路: 此题属于常规题,不过多解释,直接看代码。
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode(int x) : val(x), next(NULL) {}
* };
*/
class Solution {
public:
ListNode* deleteNode(ListNode* head, int val) {
ListNode *dummy = new ListNode(-1), *cur = dummy;
dummy->next = head;
while (cur->next) {
if (cur->next->val == val) {
cur->next = cur->next->next;
break;
}
cur = cur->next;
}
head = dummy->next;
delete dummy;
return head;
}
};
面试题21. 调整数组顺序使奇数位于偶数前面
输入一个整数数组,实现一个函数来调整该数组中数字的顺序,使得所有奇数位于数组的前半部分,所有偶数位于数组的后半部分。

解题思路: 牛客网关于此题的条件与这题还有点不同,牛客网加了个限制,即需要保证数据的稳定性,换句话说在变动后的奇数顺序与变动之前奇数的顺序是相同的,偶数同理。但是此题没有这个要求,因此处理上会简单很多。主要的思想是,用两个指针分别从数组的两端向中间搜索,前指针找前半段的偶数,后指针找后半段的奇数,然后将这两个数进行交换。
class Solution {
public:
vector<int> exchange(vector<int>& nums) {
int left = 0, n = nums.size(), right = n - 1;
while (left < right) {
while (left < n && (nums[left] & 1)) ++left;
while (right >= 0 && ((nums[right] & 1) == 0)) --right;
if (right <= left) break;
swap(nums[left++], nums[right--]);
}
return nums;
}
};
面试题22. 链表中倒数第k个节点
输入一个链表,输出该链表中倒数第k个节点。为了符合大多数人的习惯,本题从1开始计数,即链表的尾节点是倒数第1个节点。例如,一个链表有6个节点,从头节点开始,它们的值依次是1、2、3、4、5、6。这个链表的倒数第3个节点是值为4的节点。

解题思路: 本题解题思路还是比较简单。针对此题说一个题外话,实际上此题对k值没有做限制,在代码中应该对k值做讨论,当k值超过链表的长度时,应该返回非法的值。
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode(int x) : val(x), next(NULL) {}
* };
*/
class Solution {
public:
ListNode* getKthFromEnd(ListNode* head, int k) {
ListNode *fast = head, *slow = head;
for (int i = 0; i < k; ++i) fast = fast->next;
while (fast) {
fast = fast->next;
slow = slow->next;
}
return slow;
}
};
面试题24. 反转链表
定义一个函数,输入一个链表的头节点,反转该链表并输出反转后链表的头节点。

解题思路: 常规题。
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode(int x) : val(x), next(NULL) {}
* };
*/
class Solution {
public:
ListNode* reverseList(ListNode* head) {
if (!head) return NULL;
ListNode *pre = NULL;
while (head) {
ListNode *next = head->next;
head->next = pre;
pre = head;
head = next;
}
return pre;
}
};
面试题25. 合并两个排序的链表
输入两个递增排序的链表,合并这两个链表并使新链表中的节点仍然是递增排序的。

解题思路: 常规题。
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode(int x) : val(x), next(NULL) {}
* };
*/
class Solution {
public:
ListNode* mergeTwoLists(ListNode* l1, ListNode* l2) {
if (!l1) return l2;
if (!l2) return l1;
ListNode *dummy = new ListNode(-1), *cur = dummy;
while (l1 || l2) {
int d1 = l1 ? l1->val : INT_MAX;
int d2 = l2 ? l2->val : INT_MAX;
if (d1 < d2) {
cur->next = l1;
l1 = l1->next;
} else {
cur->next = l2;
l2 = l2->next;
}
cur = cur->next;
}
ListNode *head = dummy->next;
delete dummy;
return head;
}
};
面试题26. 树的子结构
输入两棵二叉树A和B,判断B是不是A的子结构。(约定空树不是任意一个树的子结构)
B是A的子结构, 即 A中有出现和B相同的结构和节点值。

解题思路: 先用DFS找到一个A树的节点和B树的根节点值相同的点,然后以此点为根简单,看B树这个树的子结构。
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode(int x) : val(x), left(NULL), right(NULL) {}
* };
*/
class Solution {
public:
bool helper(TreeNode *p, TreeNode *q) {
if (p == NULL && q == NULL) return true;
else if (p == NULL && q != NULL) return false;
else if (p && !q) return true;
else {
if (p->val != q->val) return false;
else return helper(p->left, q->left) && helper(p->right, q->right);
}
}
void dfs(TreeNode *a, TreeNode *b, bool &res) {
if (!a) return;
if (a->val == b->val) {
res = helper(a, b);
if (res) return;
}
dfs(a->left, b, res);
dfs(a->right, b, res);
}
bool isSubStructure(TreeNode* A, TreeNode* B) {
if (!A || !B) return false;
bool res = false;
dfs(A, B, res);
return res;
}
};
面试题27. 二叉树的镜像
请完成一个函数,输入一个二叉树,该函数输出它的镜像。

解题思路: 常规题。
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode(int x) : val(x), left(NULL), right(NULL) {}
* };
*/
class Solution {
public:
TreeNode* mirrorTree(TreeNode* root) {
if (!root) return NULL;
TreeNode* left = mirrorTree(root->left);
TreeNode* right = mirrorTree(root->right);
root->left = right;
root->right = left;
return root;
}
};
面试题28. 对称的二叉树
请实现一个函数,用来判断一棵二叉树是不是对称的。如果一棵二叉树和它的镜像一样,那么它是对称的。
例如,二叉树 [1,2,2,3,4,4,3] 是对称的。

但是下面这个 [1,2,2,null,3,null,3] 则不是镜像对称的:
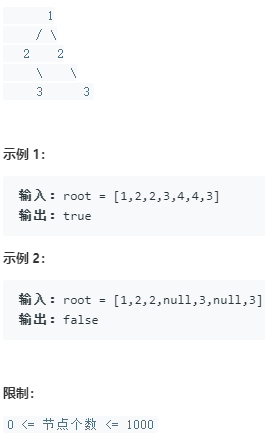
解题思路: 常规题。
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode(int x) : val(x), left(NULL), right(NULL) {}
* };
*/
class Solution {
public:
bool helper(TreeNode *node1, TreeNode *node2) {
if (!node1 && !node2) return true;
else if (!node1 || !node2) return false;
if (node1->val == node2->val) {
return helper(node1->left, node2->right) && helper(node1->right, node2->left);
} else return false;
}
bool isSymmetric(TreeNode* root) {
if (!root) return true;
return helper(root->left, root->right);
}
};
面试题29. 顺时针打印矩阵
输入一个矩阵,按照从外向里以顺时针的顺序依次打印出每一个数字。
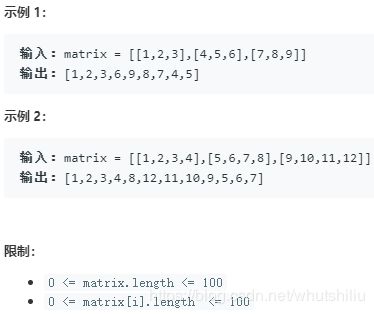
解题思路: 这一题不难,但是要细心的写,换句话,当一列或者一行扫描完后要知道接下来指针如何变。直接看代码。
class Solution {
public:
vector<int> spiralOrder(vector<vector<int>>& matrix) {
if (matrix.empty() || matrix[0].empty()) return {};
int rows = matrix.size(), cols = matrix[0].size(), r = 0, c = 0, cyc = 0, cnt = 0;
vector<int> res;
int dir = 0;
while (cnt < rows * cols) {
if (dir == 0) {
while (cnt < rows * cols && c < cols - cyc) {
res.push_back(matrix[r][c++]);
++cnt;
}
++dir;
--c;
++r;
} else if (dir == 1) {
while (cnt < rows * cols && r < rows - cyc) {
res.push_back(matrix[r++][c]);
++cnt;
}
++dir;
--r;
--c;
} else if (dir == 2) {
while (cnt < rows * cols && c >= cyc) {
res.push_back(matrix[r][c--]);
++cnt;
}
++dir;
++c;
--r;
} else if (dir == 3) {
++cyc;
while (cnt < rows * cols && r >= cyc) {
res.push_back(matrix[r--][c]);
++cnt;
}
dir = 0;
++r;
++c;
}
}
return res;
}
};
面试题30. 包含min函数的栈
定义栈的数据结构,请在该类型中实现一个能够得到栈的最小元素的 min 函数在该栈中,调用 min、push 及 pop 的时间复杂度都是 O(1)。

解题思路: 这里需要借助一个最小栈,保存每次push进来的最小值,具体的是,每次push时若最小栈为空则直接入栈,否则将这个值与最小栈的栈顶相比取最小值入栈,这样即可保证每次取源数据栈中的最小值的操作时O(1)。请看代码:
class MinStack {
public:
/** initialize your data structure here. */
MinStack() {
}
void push(int x) {
s.push(x);
if (mins.empty()) mins.push(x);
else {
if (x > mins.top()) mins.push(mins.top());
else mins.push(x);
}
}
void pop() {
if (s.empty()) return;
s.pop();
mins.pop();
}
int top() {
if (s.empty()) return -1;
else return s.top();
}
int min() {
if (mins.empty()) return -1;
else return mins.top();
}
private:
stack<int> s, mins;
};
/**
* Your MinStack object will be instantiated and called as such:
* MinStack* obj = new MinStack();
* obj->push(x);
* obj->pop();
* int param_3 = obj->top();
* int param_4 = obj->min();
*/
面试题31. 栈的压入、弹出序列
输入两个整数序列,第一个序列表示栈的压入顺序,请判断第二个序列是否为该栈的弹出顺序。假设压入栈的所有数字均不相等。例如,序列 {1,2,3,4,5} 是某栈的压栈序列,序列 {4,5,3,2,1} 是该压栈序列对应的一个弹出序列,但 {4,3,5,1,2} 就不可能是该压栈序列的弹出序列。

解题思路: 本题本质上是在考察栈的压入和弹出的模拟。采取的方法是每次压入一个元素,然后将符合弹出序列的栈顶元素全部弹出,当压入序列的元素全部压栈完毕后,再次检测栈是否为空,若不会空,则按照弹出序列依次弹出栈顶元素。最后如果弹出序列是合理的,那么最后栈一定为空。
class Solution {
public:
bool validateStackSequences(vector<int>& pushed, vector<int>& popped) {
stack<int> st;
int n = pushed.size(), idx = 0;
for (int i = 0; i < n; ++i) {
st.push(pushed[i]);
while (!st.empty() && idx < n && st.top() == popped[idx]) {
st.pop();
++idx;
}
}
if (st.empty()) {
while (!st.empty() && idx < n && st.top() == popped[idx]) {
st.pop();
++idx;
}
}
return st.empty();
}
};
面试题32 - I. 从上到下打印二叉树
从上到下打印出二叉树的每个节点,同一层的节点按照从左到右的顺序打印。

解题思路: 此题考查层序遍历,属于简单题。
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode(int x) : val(x), left(NULL), right(NULL) {}
* };
*/
class Solution {
public:
vector<int> levelOrder(TreeNode* root) {
if (!root) return {};
vector<int> res;
queue<TreeNode*> q{{root}};
while (!q.empty()) {
for (int i = q.size(); i > 0; --i) {
TreeNode *t = q.front(); q.pop();
res.push_back(t->val);
if (t->left) q.push(t->left);
if (t->right) q.push(t->right);
}
}
return res;
}
};
面试题32 - II. 从上到下打印二叉树 II
从上到下按层打印二叉树,同一层的节点按从左到右的顺序打印,每一层打印到一行。

解题思路: 跟上一题解题思路基本相同。
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode(int x) : val(x), left(NULL), right(NULL) {}
* };
*/
class Solution {
public:
vector<vector<int>> levelOrder(TreeNode* root) {
if (!root) return {};
vector<vector<int>> res;
queue<TreeNode*> q{{root}};
while (!q.empty()) {
vector<int> tmp;
for (int i = q.size(); i > 0; --i) {
TreeNode *t = q.front(); q.pop();
tmp.push_back(t->val);
if (t->left) q.push(t->left);
if (t->right) q.push(t->right);
}
res.push_back(tmp);
}
return res;
}
};
面试题32 - III. 从上到下打印二叉树 III
请实现一个函数按照之字形顺序打印二叉树,即第一行按照从左到右的顺序打印,第二层按照从右到左的顺序打印,第三行再按照从左到右的顺序打印,其他行以此类推。

解题思路: 与上一题解题思路基本相同。
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode(int x) : val(x), left(NULL), right(NULL) {}
* };
*/
class Solution {
public:
vector<vector<int>> levelOrder(TreeNode* root) {
if (!root) return {};
vector<vector<int>> res;
int level = 0;
queue<TreeNode*> q{{root}};
while (!q.empty()) {
vector<int> tmp;
for (int i = q.size(); i > 0; --i) {
TreeNode *t = q.front(); q.pop();
tmp.push_back(t->val);
if (t->left) q.push(t->left);
if (t->right) q.push(t->right);
}
if ((level++) & 1) reverse(tmp.begin(), tmp.end());
res.push_back(tmp);
}
return res;
}
};
面试题33. 二叉搜索树的后序遍历序列
输入一个整数数组,判断该数组是不是某二叉搜索树的后序遍历结果。如果是则返回 true,否则返回 false。假设输入的数组的任意两个数字都互不相同。

解题思路: 这题还是考察给定树的遍历序列,重建或者遍历树的过程。比较简单,直接看代码。
class Solution {
public:
void helper(vector<int> &inorder, int l1, int r1, vector<int> &postorder, int l2, int r2, bool &res) {
if (l1 > r1 || l2 > r2) return;
int idx = l1;
while (idx <= r1 && inorder[idx] != postorder[r2]) ++idx;
if (idx > r1) {
res = false;
return;
}
helper(inorder, l1, idx - 1, postorder, l2, l2 + idx - l1 - 1, res);
if (res) helper(inorder, idx + 1, r1, postorder, l2 + idx -l1, r2 - 1, res);
}
bool verifyPostorder(vector<int>& postorder) {
vector<int> inorder = postorder;
sort(inorder.begin(), inorder.end());
int n = postorder.size();
bool res = true;
helper(inorder, 0, n - 1, postorder, 0, n - 1, res);
return res;
}
};
面试题35. 复杂链表的复制
请实现 copyRandomList 函数,复制一个复杂链表。在复杂链表中,每个节点除了有一个 next 指针指向下一个节点,还有一个 random 指针指向链表中的任意节点或者 null。
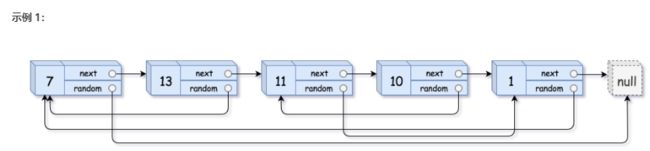
输入:head = [[7,null],[13,0],[11,4],[10,2],[1,0]]
输出:[[7,null],[13,0],[11,4],[10,2],[1,0]]
解题思路: 此题的关键是如何复制节点的random,我们可以选择建立一个从模板链表(head)的节点到生成链表(称为res)的节点的映射,通过这个映射即可在再次遍历(res)时查找到random节点。请看代码:
/*
// Definition for a Node.
class Node {
public:
int val;
Node* next;
Node* random;
Node(int _val) {
val = _val;
next = NULL;
random = NULL;
}
};
*/
class Solution {
public:
Node* copyRandomList(Node* head) {
if (!head) return NULL;
Node *cur = head, *res = NULL, *p = NULL;
unordered_map<Node*, Node*> mp;
while (cur) {
if (res == NULL) {
res = new Node(cur->val);
p = res;
} else {
p->next = new Node(cur->val);
p = p->next;
}
mp[cur] = p;
cur = cur->next;
}
p = res;
cur = head;
while (p) {
p->random = mp[cur->random];
p = p->next;
cur = cur->next;
}
return res;
}
};
面试题40. 最小的k个数
输入整数数组 arr ,找出其中最小的 k 个数。例如,输入4、5、1、6、2、7、3、8这8个数字,则最小的4个数字是1、2、3、4。
示例 1:
输入:arr = [3,2,1], k = 2
输出:[1,2] 或者 [2,1]
示例 2:
输入:arr = [0,1,2,1], k = 1
输出:[0]
限制:
0 <= k <= arr.length <= 10000
0 <= arr[i] <= 10000
解题思路: 这题属于比较经典的面试题,求TOP K,最简单的方法是用堆排序来做。其中时间复杂度为O(nlogk).关于Top K问题的复杂度分析可以看网友feliciafay.
class Solution {
public:
vector<int> getLeastNumbers(vector<int>& arr, int k) {
priority_queue<int> q;
for (int i = 0; i < arr.size(); ++i) {
q.push(arr[i]);
if (q.size() > k) q.pop();
}
vector<int> res;
while (!q.empty()) {
res.push_back(q.top()); q.pop();
}
return res;
}
};
面试题41. 数据流中的中位数
如何得到一个数据流中的中位数?如果从数据流中读出奇数个数值,那么中位数就是所有数值排序之后位于中间的数值。如果从数据流中读出偶数个数值,那么中位数就是所有数值排序之后中间两个数的平均值。
例如,
[2,3,4] 的中位数是 3
[2,3] 的中位数是 (2 + 3) / 2 = 2.5
设计一个支持以下两种操作的数据结构:
void addNum(int num) - 从数据流中添加一个整数到数据结构中。
double findMedian() - 返回目前所有元素的中位数。
解题思路: 此题参考了Grandyang的解法。用大堆保存数据流的较大半部分,用小堆保存数据流的较小半部分。
class MedianFinder {
public:
/** initialize your data structure here. */
MedianFinder() {
}
void addNum(int num) {
small.push(num);
int t = small.top(); small.pop();
largest.push(-t);
if (largest.size() > small.size()) {
t = largest.top(); largest.pop();
small.push(-t);
}
}
double findMedian() {
return small.size() > largest.size() ? small.top() : (small.top() - largest.top()) * 0.5;
}
private:
priority_queue<int> largest, small;
};
/**
* Your MedianFinder object will be instantiated and called as such:
* MedianFinder* obj = new MedianFinder();
* obj->addNum(num);
* double param_2 = obj->findMedian();
*/
面试题42. 连续子数组的最大和
输入一个整型数组,数组里有正数也有负数。数组中的一个或连续多个整数组成一个子数组。求所有子数组的和的最大值。
要求时间复杂度为O(n)。
解题思路: 此题考查动态规划。直接看代码.
class Solution {
public:
int maxSubArray(vector<int>& nums) {
int n = nums.size();
vector<int> dp(n);
dp[0] = nums[0];
for (int i = 1; i < n; ++i) {
if (dp[i - 1] > 0) dp[i] = nums[i] + dp[i - 1];
else dp[i] = nums[i];
}
int mx = dp[0];
for (int i = 1; i < n; ++i) {
mx = max(mx, dp[i]);
}
return mx;
}
};
面试题50. 第一个只出现一次的字符
在字符串 s 中找出第一个只出现一次的字符。如果没有,返回一个单空格。
解题思路: 解此题时想到的最直接的思路是遍历统计字符串的每个字符出现的次数。然后再遍历字符串时,若发现此字符只出现一次,则返回该字符。
class Solution {
public:
char firstUniqChar(string s) {
unordered_map<char, int> m;
for (char c : s) ++m[c];
for (char c : s) {
if (m[c] == 1) return c;
}
return ' ';
}
};
面试题53 - II. 0~n-1中缺失的数字
一个长度为n-1的递增排序数组中的所有数字都是唯一的,并且每个数字都在范围0~n-1之内。在范围0~n-1内的n个数字中有且只有一个数字不在该数组中,请找出这个数字。
**解题思路:**由于此题是排序的序列,因此只需要扫描一遍就能找出缺失的数字。另外需要注意的是若数组不缺失数组应该返回数组的长度。
class Solution {
public:
int missingNumber(vector<int>& nums) {
for (int i = 0; i < nums.size(); ++i) {
if (i != nums[i]) return i;
}
return nums.size();
}
};
面试题55 - I. 二叉树的深度
输入一棵二叉树的根节点,求该树的深度。从根节点到叶节点依次经过的节点(含根、叶节点)形成树的一条路径,最长路径的长度为树的深度。
例如:
给定二叉树 [3,9,20,null,null,15,7],

解题思路: 简单题。
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode(int x) : val(x), left(NULL), right(NULL) {}
* };
*/
class Solution {
public:
int maxDepth(TreeNode* root) {
if (!root) return 0;
return max(maxDepth(root->left), maxDepth(root->right)) + 1;
}
};
面试题56 - I. 数组中数字出现的次数
一个整型数组 nums 里除两个数字之外,其他数字都出现了两次。请写程序找出这两个只出现一次的数字。要求时间复杂度是O(n),空间复杂度是O(1)。
解题思路: 如果此题不限制算法的复杂度的话,解起来不难,可以看代码1的解法。但是题目要求空间复杂度为O(1),时间复杂度为O(n),那么需要使用异或运算来解题。我们先把题目简化一下,如果给定一个序列,序列中只有一个数字只出现一次,其他数字都出现两次。那么我们对这个序列所以元素做异或,得到的结果值一定是这个只出现一次的数字,因为出现两次的数在异或过程全部消掉了。那么回到本题,我们可以把序列拆分成两组,拆分的依据是,对原序列做一次异或之后,异或的结果值是只出现一次的两个数字的异或。那么这两个数字一定有一个数位是不同,那么我们找出这个数位之后,就可以将源序列分成两组了,问题就解决了。请看代码2。
- 代码1
class Solution {
public:
vector<int> singleNumbers(vector<int>& nums) {
unordered_map<int, int> mp;
for (int num : nums) ++mp[num];
vector<int> res;
for (auto it : mp) {
if (it.second == 1) res.push_back(it.first);
}
return res;
}
};
- 代码2
class Solution {
public:
vector<int> singleNumbers(vector<int>& nums) {
int tmp = 0;
for (int num : nums) tmp ^= num;
int one = 0;
for (int i = 31; i >= 0; --i) {
if (tmp & (1 << i)) {
one = i;
break;
}
}
vector<int> res(2, 0);
for (int num : nums) {
if (num & (1 << one)) res[0] ^= num;
else res[1] ^= num;
}
return res;
}
};
面试题56 - II. 数组中数字出现的次数 II
在一个数组 nums 中除一个数字只出现一次之外,其他数字都出现了三次。请找出那个只出现一次的数字。
解题思路: 同样这题也可以用hash的方法来做,即统计元素出现的频率,看代码1;此题标记的难度是中等,应该有优化的方法。想出的第二个方法是对原数组先进行排序,然后如果一个元素只出现一次,那么与这个元素相邻的两个元素与之一定不相等,看代码2;
- 代码1
class Solution {
public:
int singleNumber(vector<int>& nums) {
unordered_map<int, int> mp;
for (int num : nums) ++mp[num];
for (auto it : mp) {
if (it.second == 1) return it.first;
}
return -1;
}
};
- 代码2
class Solution {
public:
int singleNumber(vector<int>& nums) {
sort(nums.begin(), nums.end());
for (int i = 1; i < nums.size() - 1; ++i) {
if (nums[i] != nums[i - 1] && nums[i] != nums[i + 1]) return nums[i];
}
if (nums[0] != nums[1]) return nums[0];
else return nums.back();
}
};
面试题57. 和为s的两个数字
输入一个递增排序的数组和一个数字s,在数组中查找两个数,使得它们的和正好是s。如果有多对数字的和等于s,则输出任意一对即可。

解题思路: 本题考查二分查找,最终可以达到时间复杂度为O(nlogn).
class Solution {
public:
vector<int> twoSum(vector<int>& nums, int target) {
int n = nums.size();
for (int i = 0; i < n; ++i) {
int val = target - nums[i];
int left = i + 1, right = n - 1, mid = 0;
while (left < right) {
mid = (left + right) / 2;
if (val > nums[mid]) left = mid + 1;
else right = mid;
}
if (nums[right] == val) return {nums[i], val};
}
return {};
}
};
面试题57 - II. 和为s的连续正数序列
输入一个正整数 target ,输出所有和为 target 的连续正整数序列(至少含有两个数)。
序列内的数字由小到大排列,不同序列按照首个数字从小到大排列。

解题思路: 考查DFS+回溯剪枝。
class Solution {
public:
void helper(int target, int sum, int start, vector<int> &out, vector<vector<int>> &res) {
if (start > target || sum > target) return;
if (sum == target) {
res.push_back(out);
return;
}
out.push_back(start);
helper(target, sum + start, start + 1, out, res);
out.pop_back();
}
vector<vector<int>> findContinuousSequence(int target) {
vector<vector<int>> res;
vector<int> out;
for (int i = 1; i < target; ++i) helper(target, 0, i, out, res);
return res;
}
};
面试题60. n个骰子的点数
把n个骰子扔在地上,所有骰子朝上一面的点数之和为s。输入n,打印出s的所有可能的值出现的概率。
你需要用一个浮点数数组返回答案,其中第 i 个元素代表这 n 个骰子所能掷出的点数集合中第 i 小的那个的概率。
面试题64. 求1+2+…+n
求 1+2+…+n ,要求不能使用乘除法、for、while、if、else、switch、case等关键字及条件判断语句(A?B:C)。
解题思路: 这题属于技巧题。估计做多了应该知道怎么做,遇到技巧题的做法是遇到一个记住一个场景。这里我参考了《剑指offer》书籍的解法。
class A {
public:
A() {
++n;
sum += n;
}
~A() {}
static int getSum() {
return sum;
}
static void reset() {
n = 0;
sum = 0;
}
private:
static int sum;
static int n;
};
int A::n = 0;
int A::sum = 0;
class Solution {
public:
int sumNums(int n) {
A::reset();
A* p = new A[n];
delete[] p;
p = nullptr;
return A::getSum();
}
};
面试题68 - I. 二叉搜索树的最近公共祖先
给定一个二叉搜索树, 找到该树中两个指定节点的最近公共祖先。
百度百科中最近公共祖先的定义为:“对于有根树 T 的两个结点 p、q,最近公共祖先表示为一个结点 x,满足 x 是 p、q 的祖先且 x 的深度尽可能大(一个节点也可以是它自己的祖先)。”
例如,给定如下二叉搜索树: root = [6,2,8,0,4,7,9,null,null,3,5]
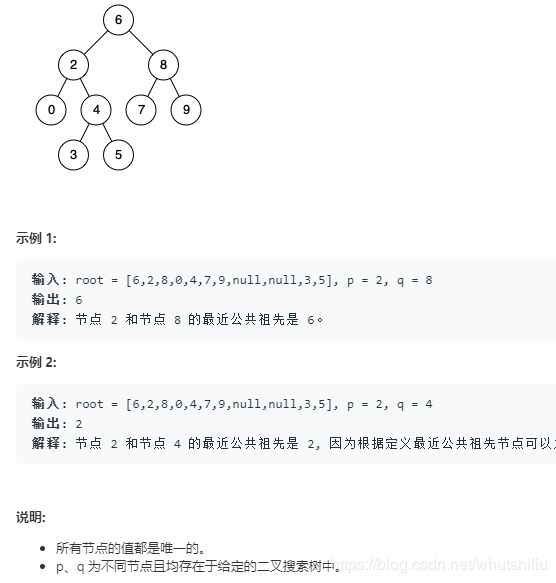
解题思路: 由两个节点共同祖先的定义可知,这两个节点要不其中一个是共同祖先,要不这两个节点是某个根节点的左右子树,且这个根节点是共同祖先。由于BST树是有序的。这个特性给判断三个节点的关系带来极大便利。思路还是比较明确,直接看代码。
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode(int x) : val(x), left(NULL), right(NULL) {}
* };
*/
class Solution {
public:
void helper(TreeNode *root, TreeNode *p, TreeNode *q, TreeNode* &res) {
if (!root) return;
if (root->val == p->val) res = p;
else if (root->val == q->val) res = q;
else {
if ((root->val > p->val && root->val < q->val) || (root->val < p->val && root->val > q->val)) res = root;
else if (root->val > p->val) helper(root->left, p, q, res);
else helper(root->right, p, q, res);
}
}
TreeNode* lowestCommonAncestor(TreeNode* root, TreeNode* p, TreeNode* q) {
TreeNode* res = NULL;
helper(root, p, q, res);
return res;
}
};
面试题68 - II. 二叉树的最近公共祖先
给定一个二叉树, 找到该树中两个指定节点的最近公共祖先。
百度百科中最近公共祖先的定义为:“对于有根树 T 的两个结点 p、q,最近公共祖先表示为一个结点 x,满足 x 是 p、q 的祖先且 x 的深度尽可能大(一个节点也可以是它自己的祖先)。”
例如,给定如下二叉树: root = [3,5,1,6,2,0,8,null,null,7,4]

解题思路: 此题是上一题的一般形式,上一题给出的树的形式是BST树,而本题的树是一般树。此题解法是,首先判断p或者q是否等于root,然后再假设LCA在root的左子树(右子树)中,然后得到对应的LCA为left和right,试想一下 ,若得到的LCA为空,则可以表明LCA不在相应的子树中,因此可以得到一个逻辑判断,当left和right都不为空时,说明p和q节点分别在root的左右子树中,则LCA为root节点。请看代码。
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode(int x) : val(x), left(NULL), right(NULL) {}
* };
*/
class Solution {
public:
TreeNode* lowestCommonAncestor(TreeNode* root, TreeNode* p, TreeNode* q) {
if (!root) return NULL;
if (root == p || root == q) return root;
TreeNode *left = lowestCommonAncestor(root->left, p, q);
TreeNode *right = lowestCommonAncestor(root->right, p, q);
if (left && right) return root;
else if (left == NULL) return right;
else return left;
}
};