Python简单爬虫开发的学习笔记整理(爬取百度百科词条)
Python简单爬虫开发的学习笔记整理(爬取百度百科词条)
笔者刚刚学完Python基础及利用Python进行数据分析,顺便跟着慕课网上的一个爬虫课程学习爬虫,网址:Python开发简单爬虫,课程条理逻辑清晰,简单易懂,项目代码易于拓展应用,适合入门学习。
以下是课程的主要内容及笔记:
第一章:课程介绍

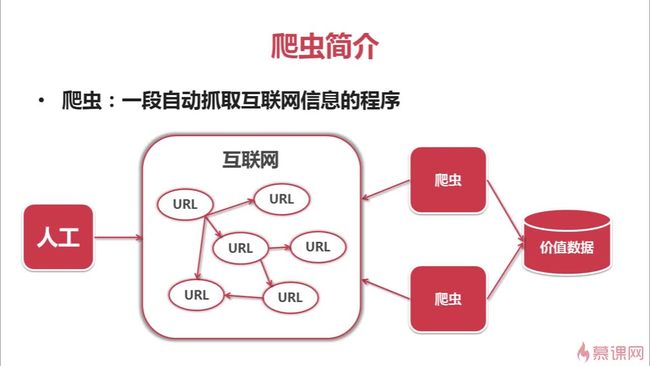
第二章:爬虫简介及其技术价值
第三章:简单爬虫架构
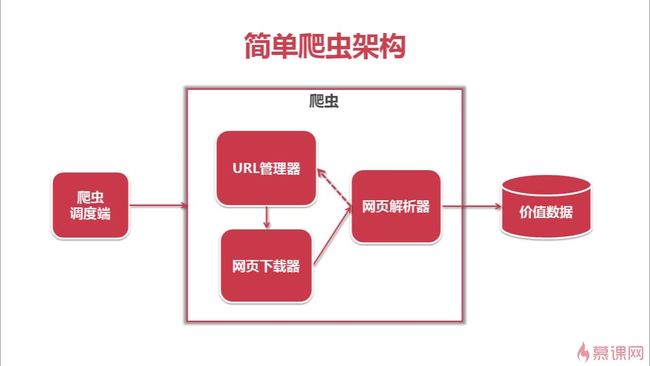
爬虫调度端:启动爬虫,停止爬虫,监视爬虫运行情况
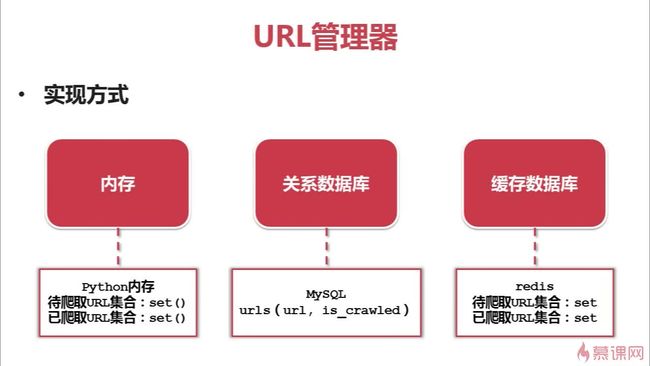
URL管理器:对将要爬取的和已经爬取过的URL进行管理;可取出带爬取的URL,将其传送给“网页下载器”
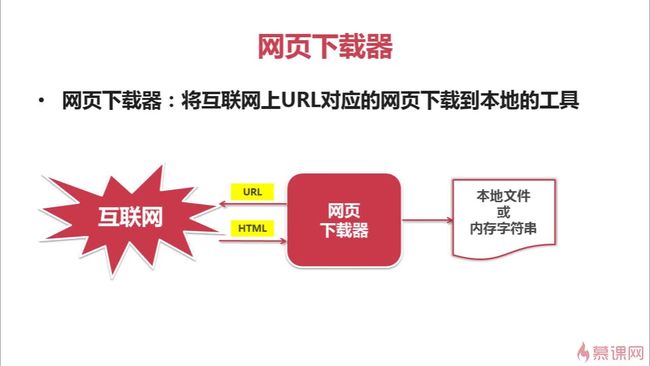
网页下载器:将URL指定的网页下载,存储成一个字符串,在传送给“网页解析器”
网页解析器:解析网页可解析出①有价值的数据②另一方面,每个网页都包含有指向其他网页的URL,解析出来后可补充进“URL管理器”
URL管理器:对将要爬取的和已经爬取过的URL进行管理;可取出带爬取的URL,将其传送给“网页下载器”
网页下载器:将URL指定的网页下载,存储成一个字符串,在传送给“网页解析器”
网页解析器:解析网页可解析出①有价值的数据②另一方面,每个网页都包含有指向其他网页的URL,解析出来后可补充进“URL管理器”
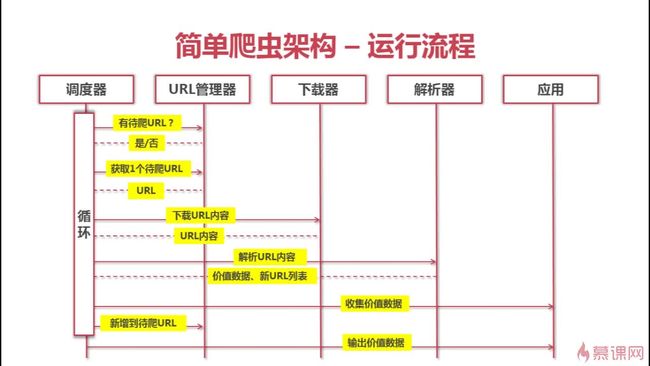
爬虫架构运行流程: 调度器询问url是否有待爬取的url,如果有,则取出一个url传送给下载器,下载器下载完成后,返回给调度器,调度器将内容传送给解析器,解析器分析出有用数据及关联url,返回给调度器,调度器一方面将有价值数据传送给应用进行存储及分析,另一方面将新的url传送给url管理器。如此循环
第四章:URL管理器及实现方法

第五章:网页下载器和urllib2模块介绍
5.1 Python爬虫网页下载器简介
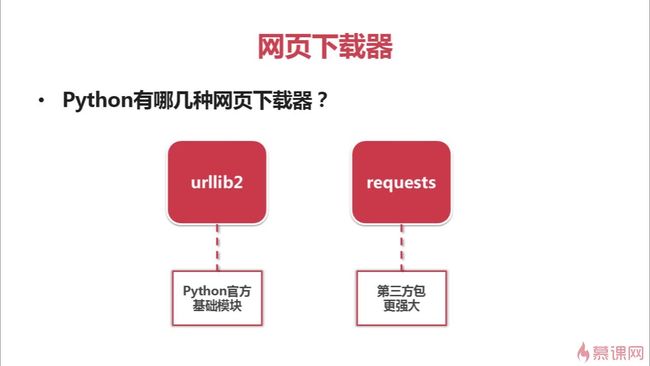
5.2、5.3 Python爬虫urllib2下载网页的三种方法及其代码
第一种简洁方法: (这里注意编解码的问题)
import urllib2
response= urllib2.urlopen("http://www.baidu.com") # 直接请求
print response.getcode() #获取状态码,若是200表示获取成功
cont= response.read() #读取内容
第二种:【添加data、http header urllib2.Request urllib2.urllopen(requset)】
import urllib2
request=urllib2.Request(url) # 创建Request对象
request.add_data('a','1') #添加数据
request.add_header('User-Agent','Mozilla/5.0') #添加http的header
response=urllib2.urlopen(request) #发送请求获取结果
第三种 【添加特殊情景的处理器】
import urllib2,cookielib
cj=cookielib.CookieJar() #创建cookie容器
opener=urllib2.build_opener(urllib2.HTTPCookiePrpcessor(cj))# 创建一个opener
urllib2.install_opener(opener) #给urllib2安装opener
response=urllib2.urlopen('http://www.baidu.com/')#使用有cookie的urllib2访问网页第六章:Python网页解析器及beautifulsoup第三方库
6.1 网页解析器简介
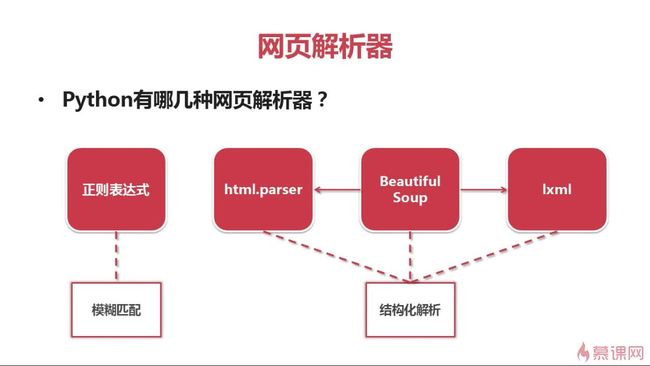
6.2 beautifulsoup介绍及其安装
BeautifulSoup:Python第三方库,用于从HTML或XML中提取数据
官网:http://www.crummy.com/software/BeautifulSoup
安装:在已有pip的情况下在cmd中运行pip install beautifulsoup4
导入:import bs4
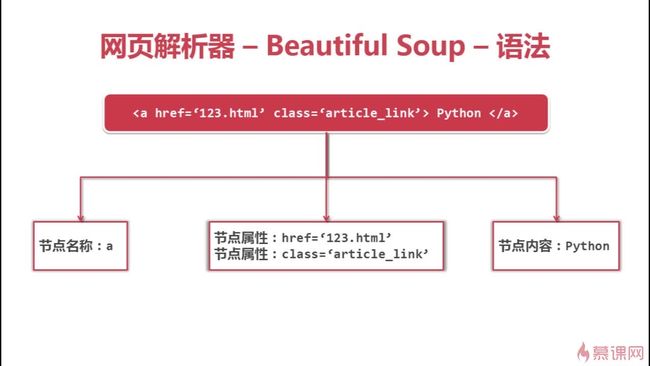
6.3 beautifulsoup语法


第七章:实例:爬取百度百科1000页的词条内容
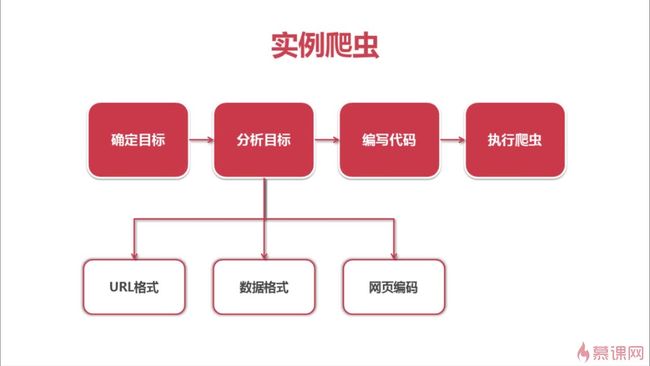
7.1 分析目标

7.2 调度程序
以下是整理好的程序,并加上了注释爬取了100个词条,如需更多,只需更改一下限制条件
# coding: utf-8
import html_downloader
import html_outputer
import html_parser
import url_manager
"""
爬虫主程序
"""
class SpiderMain(object):
# 初始化爬虫
def __init__(self):
# URL管理器
self.urls = url_manager.UrlManager()
# HTML下载器
self.downloader = html_downloader.HtmlDownloader()
# HTML解析器
self.parser = html_parser.HtmlParser()
# HTML输出器
self.outputer = html_outputer.HtmlOutputer()
# 爬虫的调动程序
def craw(self, root_url):
# 记录当前爬取的url序号
cnt = 1
# 添加爬取入口的url
self.urls.add_new_url(root_url)
# 若有新的待爬取的url,则一直循环爬取
while self.urls.has_new_url():
try:
# 获取新的待爬取的url
new_url = self.urls.get_new_url()
# 打印当前爬取的url序号与名字
print('craw %d : %s' % (cnt, new_url))
# 下载爬取的页面
html_content = self.downloader.download(new_url)
# 解析爬取的页面
new_urls, new_data = self.parser.parse(new_url, html_content)
# 添加批量的带爬取的url
self.urls.add_new_urls(new_urls)
# 收集数据
self.outputer.collect_data(new_data)
# 爬取目标定为爬取20个url,若完成任务,则退出循环
if cnt == 100:
break
cnt += 1
except:
print('craw failed.')
# 输出收集好的数据
self.outputer.output_html()
if __name__ == '__main__':
# 爬虫入口页面
root_url = 'http://baike.baidu.com/item/Python'
obj_spider = SpiderMain()
# 启动爬虫
obj_spider.craw(root_url)
7.3 URL管理器
# coding: utf-8
"""
URL管理器
"""
class UrlManager(object):
def __init__(self):
self.new_urls = set() # 待爬取的url集合
self.old_urls = set() # 已爬取的url集合
def add_new_url(self, url):
"""
添加新的带爬取的url
:param url:
:return:
"""
if url is None:
return
if url not in self.new_urls and url not in self.old_urls:
# 若为新的Url,则添加进待爬取的url集合中
self.new_urls.add(url)
def add_new_urls(self, urls):
"""
批量添加新的带爬取的url集合
:param urls:
:return:
"""
if urls is None or len(urls) == 0:
return
for url in urls:
self.add_new_url(url)
def has_new_url(self):
"""
检测待爬取集合是否为空
:return:
"""
return len(self.new_urls) != 0
def get_new_url(self):
"""
获取要爬取的url
:return:
"""
new_url = self.new_urls.pop() # 获取url并从集合中剔除该url
self.old_urls.add(new_url) # 将获取的url添加进已爬取的url中
return new_url
7.4 HTML下载器
# coding: utf-8
import urllib2
"""
Html下载器
"""
class HtmlDownloader(object):
def download(self,url):
"""
下载该页面
:param url:
:return:
"""
if url is None:
return None
# 打开一个url,返回一个 http.client.HTTPResponse
response = urllib2.urlopen(url)
# 若请求失败
if response.getcode() != 200:
return None
return response.read()
7.5 HTML解析器
# coding: utf-8
import re
from bs4 import BeautifulSoup
import urlparse
class HtmlParser(object):
def parse(self, page_url, html_content):
"""
解析该页面
:param page_url:
:param html_content:
:return:
"""
if page_url is None or html_content is None:
return
soup = BeautifulSoup(html_content, 'html.parser', from_encoding='utf-8')
new_urls = self._get_new_urls(page_url, soup)
new_data = self._get_new_data(page_url, soup)
return new_urls, new_data
def _get_new_urls(self, page_url, soup):
"""
获取该页面中所有的符合检验规则的url
:param page_url:
:param soup:
:return:
"""
# 新的带爬取的url集合
new_urls = set()
# 获取所有符合检验规则的url
links = soup.find_all('a', href=re.compile(r'/item/'))
for link in links:
new_url = link['href']
# 将相对路径的url拼接成绝对路径的url
new_full_url = urlparse.urljoin(page_url, new_url)
new_urls.add(new_full_url)
return new_urls
def _get_new_data(self, page_url, soup):
"""
整合页面的数据
:param page_url:
:param soup:
:return:
"""
# 该页面整合的数据
res_data = {'url': page_url}
"""
获取爬取页面的标题
Python
"""
title_node = soup.find('dd', class_='lemmaWgt-lemmaTitle-title').find('h1')
res_data['title'] = title_node.get_text()
"""
获取爬取页面的概要
Python语法简洁清晰,特色之一是强制用空白符(white space)作为语句缩进。
"""
summary_node = soup.find('div', class_='lemma-summary')
res_data['summary'] = summary_node.get_text()
return res_data
7.6 HTML输出器
# coding: utf-8
"""
Html输出器
"""
class HtmlOutputer(object):
def __init__(self):
self.datas = []
def collect_data(self, data):
"""
收集数据
:param data:
:return:
"""
if data is None:
return
self.datas.append(data)
def output_html(self):
"""
将收集结果输出成Html页面
:return:
"""
file_out =open('output.html', 'w')
file_out.write('')
file_out.write('')
file_out.write('')
#ascii
for data in self.datas:
file_out.write('')
file_out.write('%s '%data['url'])
file_out.write('%s '%data['title'].encode('utf-8'))
file_out.write('%s '%data['summary'].encode('utf-8'))
file_out.write(' ')
file_out.write('')
file_out.write('')
file_out.write('')
file_out.close()
到此为止,我们就可以获得网页中1000多个词条页面的信息了!
8. 课程总结

你可能感兴趣的:(Python)