字节 输入输出流 byte
输入和输出是相对于程序的:
流的分类:
第一:
输入流: 数据从外部流入写的程序
输出流: 数据从程序流到外面
第二:
从流结构上:其实底层都是以字节流来实现的。
**字节流:
字符流**:在字节流的基础上做了封装,相当于直接操作字符串一样,简化操作。
字节流**byte Stream的输入和输出基础是 **InputStream 和 OutoutStream这两个抽象类 字节的输入和输出是由这两个类的子类实现的。
使用字节流读取或者写入二进制数据
字符流 character Stream 的输入和输出基础是 抽象类 Reader 和 Writer, 采用了统一的编码标准,因而可以国际化。
读数据的逻辑:
1. open a stream
2. while more information{ read information }
3. close the stream
第三:
节点流:从特定的地方读写的流,比如从某一块磁盘
过滤流:使用节点流作为输入和输出,过滤流是使用一个已经存在的输入流或者输出流创建的,对节点流的信息进行过滤,包装
比较常用的几个流 :
FileInputStream 和FileOutputStream // 文件流
BufferedInputStream 和 BufferedOutputStream //带缓冲的文件流
DateInputStream 和 DataOutputStream //操作数据类型的文件流
ByteArrayInputStream 和 ByteArrayOutputStream // 字节数组流,有时会用到
InputStream:
三个基本的读方法:
abstract read() // 是一个抽象方法, 供子类实现
// 为什么只有这一个read方法是抽象的,而其他两个read是具体的,
// 解释:其他两个read 方法都是直接或者间接根据第一个方法实现的,只有第一个read方法是跟具体的I/O设备相关的,它需要通过子类实现。
int read(byte[] b) // 将数据读入一个字节数组,如果返回-1,表示读取到了输入流的末尾
int read(byte[] b ,int off, int len) // 将数据读入一个字节数组, off 指定在数组b 中存放数据的起始偏移位置,len 指定读取的最大字节数。
如果返回-1,表示读取到了输入流的末尾。
例子: 从文件中读取数据
// 从一个文件中读取信息 ,非常固定的一个写法,流程记住
public class FileInputStreamTest {
public static void main(String[] args) throws IOException {
File file = new File("G:/a2.txt");
InputStream in = new FileInputStream(file);
byte[] byteData = new byte[200];
// 从in 这个流中读取数据,每次最多读取200个字节,赋给byteData,
// 返回值是一次实际读取的字节个数赋给length, 比如现在的流中只有150个字节,则第一次循环的时候length = 150
// 第二次条件判断 length = -1 , 结束读取操作
int length = 0;
while (-1 != (length = in.read(byteData, 0 , 200)) ){
// 将字节数组转化为字符串, 第一个参数为字节数组, 第二个参数是转化的起始位置, 第三个参数为转化的长度
String str = new String(byteData, 0, length);
System.out.println(str);
}
in.close(); // 关闭流,一定要关闭
}
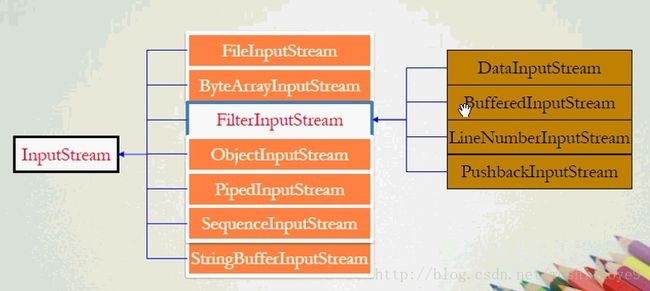
}InputStream的一些子类 除了FilterInputStream 是过滤流,其他全是节点流。
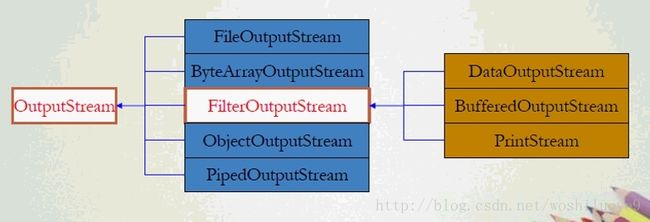
OutoutStream
public class FileOutputStreamTest {
public static void main(String[] args) throws IOException {
File file = new File("G:/a2.txt");
FileOutputStream out = new FileOutputStream(file);
String str = "qqqqqqqqq wwww sssssss";
// 首先要将字符串转化为字节
byte[] byteData = str.getBytes();
//可以直接写入,但是会从都开始写入,覆盖掉文件中开头的字符串
out.write(byteData);
// 如果是在文件中进行追加,必须在构造流的时候,将后面的参数设置为true
FileOutputStream out2 = new FileOutputStream(file, true);
out2.write(byteData);
out.close();
out2.close();
}
}过滤流的主要功能:
主要是在输入输出数据的同时,对所能传输的数据做指定类型或者指定格式的转换,即可实现对二进制字节数的理解和编码转换。
BufferedOutputStream 缓冲的输出流
它提供了和FileOutputStream类同样的写操作方法,不同的是:
它把所有的输出先全部写入缓冲区中,当缓冲区满了或者该输出流关闭的时候,它再一次性的输出到流。或者也可以显式的调用flush() 方法主动将缓冲区输出到流。通过减小系统写数据的时间而提高了性能。
// 构造函数,接收的是一个**节点流**
BufferedOutputStream(OutputStream out)
BufferedOutputStream(OutputStream out, int size) 它的使用方式:
File file = new File("G:/a2.txt");
FileOutputStream out = new FileOutputStream(file);
BufferedOutputStream bufferedOut = new BufferedOutputStream(out);
bufferedOut.write(byteData);
// 需要注意的是,如果下面的两句不写上,是不会写入到文件中去的,因为此时要写入的数据还在缓冲区
bufferedOut.flush(); // 将缓冲区的字节写入到文件中,然后清空缓冲区
bufferedOut.close(); // 关闭的时候也会检查缓冲区,缓冲区有数据,会先写入文件清空缓冲区,再关闭ByteArrayOutputStream 和 ByteArrayInputStream
上面介绍的几个类,都是以文件作为输入或者输出使用的源头,这两个方法不同的是:
使用字符数组作为输入和输出的源头。
String str = "qqqqqqqqq wwww sssssss";
byte[] byteData = str.getBytes();
ByteArrayInputStream in = new ByteArrayInputStream (byteData) // 以字符数组作为输入流
由此引申出来的对 char, int , byte 的思考:
明天要试验一下,看看程序运行的结果验证我的想法
好的,试验出来了,
我们知道字节流是以一个字节为单位进行处理的,
char 和 byte 的区别
一个字节 byte = 8位二进制数
一个英文字符和中文字符在java 中定义都是char 型的,一个char型的数据是两个字节,为什么通过字节流输出的时候英文字母会直接就输出了呢?
可以看到在下面的例子中, “helloworld”的字节流长度为10个,”你好世界”的字节流长度为8个,英文字符不也是char型的吗?为什么”helloworld”的字节数长度为10 而不是20 呢?
解释: 这是因为,中文的表示只能用两个字节才能完整的表示一个中文,而英文字母只需要一个字节就能表示了,它的高8位二进制全为0,因此在存储英文字母的时候只用了一个字节,所以虽然char是2个字节,但是在表示英文字母的时候只用了一个字节存储。
一个byte是有符号的,能表示的整数范围为 -128 —– 127
一个char 型是无符号的,表示的范围为 0 — 65536
public class BufferedInputstreamTest {
// 使用字节数组输入过滤流 ,对比了
public static void main(String[] args) throws IOException {
String str1 = "helloworld";
String str2 = "你好世界";
byte[] bytestr1 = str1.getBytes();
byte[] bytestr2 = str2.getBytes();
ByteArrayInputStream in1 = new ByteArrayInputStream(bytestr1);
ByteArrayInputStream in2 = new ByteArrayInputStream(bytestr2);
int length1 = 20;
int length2 = 20;
byte[] inbyte1 = new byte[50];
byte[] inbyte2 = new byte[50];
length1 = in1.read(inbyte1, 0, 20); // length1 = 10
for( int i = 0; iout.println((char)inbyte1[i]); // helloworld
}
length2 = in2.read(inbyte2, 0, 20); // length1 = 8
for( int i = 0; iout.println((char)inbyte2[i]); // 乱码
}
in1.close();
in2.close();
}
} DataInputStream 和 DataOutputStream
数据输入流DataInputStream 中定义了多个针对不同类型的数据的读方法,比如 readByte(),readChar(), readLine() (字符串),readInt() 等等,同样的还有DataOutputStream 定义了多个不同的写方法
public class DataOutputStreamTest {
public static void main(String[] args) throws IOException {
// 将信息写入到文件中
File file = new File("G:/dataOutput.txt");
//输出到文件上,并且设置信息添加到文件的后面
FileOutputStream out = new FileOutputStream(file, true);
// 将输出流转化为带缓冲区的输出流
BufferedOutputStream bufferOut = new BufferedOutputStream(out);
// 将带缓冲区的输出流转换为能处理不同数据类型的输出流
DataOutputStream dataOut = new DataOutputStream(bufferOut);
int i = 1;
int j = 2;
String str1 = "hello";
String str2 = "world";
dataOut.writeInt(i); // 将数据以整形的方式读进去
dataOut.writeInt(j);
dataOut.writeUTF(str1);
dataOut.writeBytes(str2);
dataOut.close();
// 将信息从文件中读取到到程序
DataInputStream dataInput = new DataInputStream(new FileInputStream("G:/dataOutput.txt"));
System.out.println(dataInput.readInt());
System.out.println(dataInput.readInt());
System.out.println(dataInput.readUTF());
System.out.println(dataInput.readUTF());
dataInput.close();
}
}