一、缩进
其实从控制流开始就应该讲解缩进了,但好像缩进的范围对函数来说更明显点,就放这里来讲了。
Python中,是通过代码的缩进,来决定代码的逻辑的。
通俗的说,Python中的代码的缩进,不是为了好看,而是觉得代码的含义,上下行代码之间的关系。
缩进弄错了,就会导致程序出错,执行结果变成不是你想要的了。
关于第一行要执行的代码



(以上例子来源于网络,由于图中例子是基于python2,所以print不是print(),其实差不多,不用在意这个细节,
__name__==
__main__下的内容暂时理解成可这个文件运行时最开始调用的地方)
代码块
对应的,上述几个图解中,def indentDemo后面的代码,也就被因此成为代码块:

说白了,就是一个逻辑上的概念,可以简单理解为其他语言中的,一个函数内的代码,一个if判断内的代码等等相应的概念;
简单的例子
最后,再举一个简单的例子,以下引用我以前带班时说过的话:
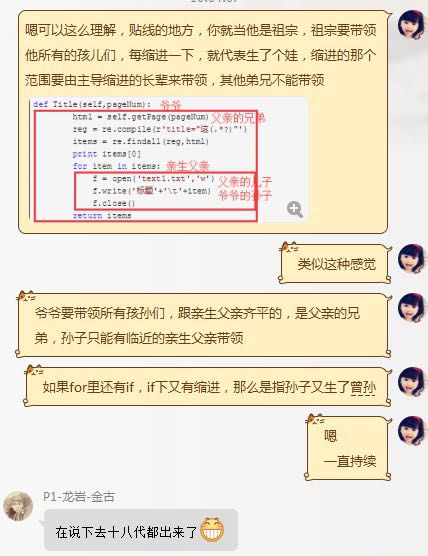
二、函数
函数是组织好的,可重复使用的,用来实现单一,或相关联功能的代码段。
函数能提高应用的模块性,和代码的重复利用率。你已经知道Python提供了许多内建函数,比如print()。但你也可以自己创建函数,这被叫做用户自定义函数。
函数定义
你可以定义一个由自己想要功能的函数,以下是简单的规则:
- 函数代码块以 def 关键词开头,后接函数标识符名称和圆括号()。
- 任何传入参数和自变量必须放在圆括号中间。圆括号之间可以用于定义参数。
- 函数的第一行语句可以选择性地使用文档字符串—用于存放函数说明。
- 函数内容以冒号起始换行,并且缩进。
- return [表达式] 结束函数,选择性地返回一个值给调用方。不带表达式的return相当于返回 None。
语法:
def functionname( parameters ):
"函数_文档字符串"
function_suite
return [expression]
- functionname 函数名,调用时使用
- parameters 函数的参数
- function_suite 函数内容
- return 可有可没有,表示返回return后面跟着的东西到调用函数的地方
函数调用
函数定义好后,如果没有调用,是不会运行的,就像是做好了一个风筝,但是没有连线,那风筝是飞不起来的,那么函数调用就像是给风筝连上了线。
定义一个函数只给了函数一个名称,指定了函数里包含的参数,和代码块结构。
这个函数的基本结构完成以后,你可以通过另一个函数调用执行,也可以直接从Python提示符执行。
语法:
#在函数外写上函数名,传入参数,就是调用函数了
functionname(parameters)
参数传递
python 函数的参数传递:
- 不可变类型:整数、字符串、元组。如fun(a),传递的是a的地址,但是由于a是不可变类型,即使在函数内,改变了a,其实也是新建了一块内存(地址改变),a内存的内容依然没有变,比如在 fun(a)内部修改 a 的值,只是修改另一个对象,不会影响 a 本身。
当然还有另一种说法是,值传递或者说是传入的是原对象的副本,是说改变副本不会影响原对象,其实意思都差不多,领悟即可。 - 可变类型: 列表,字典。如 fun(la),则是也是将la的地址传入,由于传入的类型是可变类型,在fun内修改后,fun外部的la也会受影响。
举个栗子:
#不可变
def ChangeInt( a ):
a = 10
b = 2
ChangeInt(b)
print(b)
# 结果是 2
#可变
def changeme( mylist ):
"修改传入的列表"
mylist.append([1,2,3,4]);
print("函数内取值: ", mylist)
return
# 调用changeme函数
mylist = [10,20,30];
changeme( mylist );
print("函数外取值: ", mylist)
#输出
#函数内取值: [10, 20, 30, [1, 2, 3, 4]]
#函数外取值: [10, 20, 30, [1, 2, 3, 4]]
参数
以下是调用函数时可使用的正式参数类型:
- 必选参数
- 默认参数
必选参数和默认参数一起讲,比较容易理解
首先讲下规则:
一是必选参数在前,默认参数在后,否则Python的解释器会报错(思考一下为什么默认参数不能放在必选参数前面);
二是如何设置默认参数:
当函数有多个参数时,把变化大的参数放前面,变化小的参数放后面。变化小的参数就可以作为默认参数。
def enroll(name, gender, age=6, city='Beijing'):
print 'name:', name
print 'gender:', gender
print 'age:', age
print 'city:', city
name和gender就是必选参数,在调用时不给与必选参数是会报错的,因为对象不存在,没有指向,而age和city,调用时不给值也是可以的,因为Python函数在定义的时候,默认参数L的值就被计算出来了(即对象已存在)。
这就是必选参数和默认参数的区别。
- 关键字参数
- 不定长参数
我个人感觉这两个其实很像,都是不定长的,只是关键字参数是 某某变量名=啥啥啥,而不定长参数是直接传入多个变量。
(不定长参数允许你传入0个或任意个参数,这些参数在函数调用时自动组装为一个tuple。而关键字参数允许你传入0个或任意个含参数名的参数,这些关键字参数在函数内部自动组装为一个dict。)
我们可以来这么理解一下不定长参数:
不定长参数在函数定义时用到了(大家还记得解包用吧),其实就是理解成可传入的参数是可以被解包的tuple,那么传入的那么多参数自然就被组合成了tuple,这是一种理解的方式。
举个栗子:
def calc(*numbers):
sum = 0
for n in numbers:
sum = sum + n * n
return sum
>>> calc(1, 2)
5
那么关键字参数呢,其实差不多,我们来举个栗子理解下:
def person(name, age, **kw):
print('name:', name, 'age:', age, 'other:', kw)
>>> person('Adam', 45, gender='M', job='Engineer')
name: Adam age: 45 other: {'gender': 'M', 'job': 'Engineer'}
关键字参数有什么用?它可以扩展函数的功能。比如,在person函数里,我们保证能接收到name和age这两个参数,但是,如果调用者愿意提供更多的参数,我们也能收到。试想你正在做一个用户注册的功能,除了用户名和年龄是必填项外,其他都是可选项,利用关键字参数来定义这个函数就能满足注册的需求。
和可变参数类似,也可以先组装出一个dict,然后,把该dict转换为关键字参数传进去。
(注意下和可变参数的区别,两个**号哦!!!)
最后,四种组合看一下:
def func(a, b, c=0, *args, **kw):
print('a =', a, 'b =', b, 'c =', c, 'args =', args, 'kw =', kw)
>>> func(1, 2)
a = 1 b = 2 c = 0 args = () kw = {}
>>> func(1, 2, c=3)
a = 1 b = 2 c = 3 args = () kw = {}
>>> func(1, 2, 3, 'a', 'b')
a = 1 b = 2 c = 3 args = ('a', 'b') kw = {}
>>> func(1, 2, 3, 'a', 'b', x=99)
a = 1 b = 2 c = 3 args = ('a', 'b') kw = {'x': 99}
>>> args = (1, 2, 3, 4)
>>> kw = {'x': 99}
>>> func(*args, **kw)
a = 1 b = 2 c = 3 args = (4,) kw = {'x': 99}
是不是很有趣呀~
三、作用域
那么讲完了缩进,函数,控制流,那么我们要来讲下变量的作用域这个很重要的内容了。
我们的变量在定义时,其实在命名空间(namespace)进行了内存分配,但是定义时的不同位置,决定了变量究竟定义在了哪个命名空间,那么在哪些空间找到这个名字才可以访问到这个变量。
命名空间的定义:变量到对象的映射集合。一般都是通过字典来实现的。主要可以分为三类:
- 内置命名空间
- 函数的本地命名空间
- 模块的全局命名空间
太深入的咱们不讲,我们讲一下大概:
在Python中,使用一个变量时并不严格要求需要预先声明它,但是在真正使用它之前,它必须被绑定到某个内存对象(被定义、赋值);这种变量名的绑定将在当前作用域中引入新的变量,同时屏蔽外层作用域中的同名变量。
L(local)局部作用域
局部变量:包含在def关键字定义的语句块中,即在函数中定义的变量。每当函数被调用时都会创建一个新的局部作用域。Python中也有递归,即自己调用自己,每次调用都会创建一个新的局部命名空间。在函数内部的变量声明,除非特别的声明为全局变量,否则均默认为局部变量。有些情况需要在函数内部定义全局变量,这时可以使用global关键字来声明变量的作用域为全局。局部变量域就像一个 栈,仅仅是暂时的存在,依赖创建该局部作用域的函数是否处于活动的状态。所以,一般建议尽量少定义全局变量,因为全局变量在模块文件运行的过程中会一直存在,占用内存空间。
注意:如果需要在函数内部对全局变量赋值,需要在函数内部通过global语句声明该变量为全局变量。
E(enclosing)嵌套作用域
E也包含在def关键字中,E和L是相对的,E相对于更上层的函数而言也是L。与L的区别在于,对一个函数而言,L是定义在此函数内部的局部作用域,而E是定义在此函数的上一层父级函数的局部作用域。主要是为了实现Python的闭包,而增加的实现。
G(global)全局作用域
即在模块层次中定义的变量,每一个模块都是一个全局作用域。也就是说,在模块文件顶层声明的变量具有全局作用域,从外部开来,模块的全局变量就是一个模块对象的属性。
注意:全局作用域的作用范围仅限于单个模块文件内
B(built-in)内置作用域
系统内固定模块里定义的变量,如预定义在builtin 模块内的变量。
变量名解析LEGB法则
搜索变量名的优先级:局部作用域 > 嵌套作用域 > 全局作用域 > 内置作用域
LEGB法则: 当在函数中使用未确定的变量名时,Python会按照优先级依次搜索4个作用域,以此来确定该变量名的意义。首先搜索局部作用域(L),之后是上一层嵌套结构中def或lambda函数的嵌套作用域(E),之后是全局作用域(G),最后是内置作用域(B)。按这个查找原则,在第一处找到的地方停止。如果没有找到,则会出发NameError错误。
下面举一个实用LEGB法则的例子:
globalVar = 100 #G
def test_scope():
enclosingVar = 200 #E
def func():
localVar = 300 #L
print __name__ #B
以上解释来自石晓文的学习日记
如果上面你暂时看不懂,也没关系,我们来看个更简单点的解释:

最后要注意一下就是:
在Python中并不是所有的语句块中都会产生作用域。只有当变量在Module(模块)、Class(类)、def(函数)中定义的时候,才会有作用域的概念!!(module和class可以暂时不用理解,后续慢慢会学到。)
四、注释docstring(课程里叫文档):
其实就是不会被编译器编译,被解释器解释去运行的部分内容。
常用的方法是一对三引号,或者一个井号,一般三引号是用于多行描述,而一个井号是用于单行描述。
要注意的是:
一对三引号作为注释的地方只有三个地方:
函数的def下面一行,那个叫 docstring of function
class下面一行,叫 docstring of class
文件顶行, 叫 docstring of module
其他写的地方,都会被python编译器翻译成字符串,一定要特别注意。(所以代码中间的注释用#号哦)
五、lambda表达式(匿名函数)
Python中,lambda函数也叫匿名函数,及即没有具体名称的函数,它允许快速定义单行函数,类似于C语言的宏,可以用在任何需要函数的地方。这区别于def定义的函数。
- 关键字 lambda 表示这是一个 lambda 表达式。
- lambda 之后是该匿名函数的一个或多个参数(用英文逗号分隔),然后是一个英文冒号 :。和函数相似,lambda 表达式中的参数名称是随意的。
- 最后一部分是被评估并在该函数中返回的表达式,和你可能会在函数中看到的 return 语句很像。
鉴于这种结构,lambda 表达式不太适合复杂的函数,但是非常适合简短的函数。
lambda语法格式:
lambda 变量 : 要执行的语句
lambda [arg1 [, agr2,.....argn]] : expression
这个东西,只有多写多查多领悟了,实在不知道怎么去解释。
举个栗子吧
>>>g = lambda x:x+1
>>>g(1)
2
>>>g(2)
3
可以这样认为,lambda作为一个表达式,定义了一个匿名函数,上例的代码x为入口参数,x+1为函数体,用函数来表示为:
def g(x):
return x+1
最后要特别说一下:lambda 定义了一个匿名函数,其实内部也是一个正常一行一行运行的函数,他并不会带来程序运行效率的提高,只会使代码更简洁。但碍于他的不易读性,所以如果可以使用for...in...if来完成的,坚决不用lambda。如果使用lambda,lambda内不要包含循环,如果有,我宁愿定义函数来完成,使代码获得可重用性和更好的可读性。
六、yeild
我在控制流的最开始其实已经讲了概念。那么这章节就来了解下yeild(有yeild一定是生成器)。
yield 是一个类似 return 的关键字,只是这个函数返回的是个生成器。
>>> def createGenerator() :
... mylist = range(3)
... for i in mylist :
... yield i*i
...
>>> mygenerator = createGenerator() # create a generator
>>> print(mygenerator) # mygenerator is an object!
>>> for i in mygenerator:
... print(i)
0
1
4
这个例子没什么用途,但是它让你知道,这个函数会返回一大批你只需要读一次的值.
为了精通 yield ,你必须要理解:当你调用这个函数的时候,函数内部的代码并不立马执行 ,这个函数只是返回一个生成器对象,这有点蹊跷不是吗。
那么,函数内的代码什么时候执行呢?当你使用for进行迭代的时候.
现在到了关键点了!
第一次迭代中你的函数会执行,从开始到达 yield 关键字,然后返回 yield 后的值作为第一次迭代的返回值. 然后,每次执行这个函数都会继续执行你在函数内部定义的那个循环的下一次,再返回那个值,直到没有可以返回的。
此部分转载至这里,非常建议看了,也可以更好理解生成器。