【ceph的通用解决方案】-如何ssd作为ceph-osd的日志盘使用
作者:【吴业亮】
博客:https://wuyeliang.blog.csdn.net/
开篇:
目前企业的业务场景多种多样,并非所有Ceph存储解决方案都是相同的,了解工作负载和容量要求对于设Ceph解决方案至关重要。Ceph可帮助企业通过统一的分布式集群提供对象存储、块存储或文件系统存储。在设计流程中,这些集群解决方案针对每项要求都进行了优化。该设计流程的首要因素包括 IOPS 或带宽要求、存储容量需求以及架构和组件选择,确保这些因素的合理性有助于完美平衡性能和成本。不同类型的工作负载需要不同的存储基础设施方案。
下面将从以下6个方面介绍ceph的通用解决方案
- 性能方面:
1、如何ssd作为Ceph-osd的日志盘使用
2、如何同一个Ceph集群分别创建ssd和hdd池
3、如何将ssd作为hdd的缓存池
4、如何指定ssd盘为主osd,hdd为从osd
- 稳定及数据安全性方面:
5、Ceph双副本如何保证宕机数据的安全性
6、Ceph纠删码理论与实践
注意:该文章同时在华云数据官方公众号上发布
智汇华云 | Ceph的正确玩法之SSD作为Ceph-osd的日志盘使用
下面我们开始专题一:如何ssd作为Ceph-osd的日志盘使用
假设磁盘正在执行一个写操作,此时由于发生磁盘错误,或者系统宕机、断电等其他原因,导致只有部分数据写入成功。这种情况就会出现磁盘上的数据有一部分是旧数据,另一部分是新写入的数据,使得磁盘数据不一致。
Ceph引入事务与日志,来实现数据写盘操作的原子性,并解决数据不一致的问题。即所谓的“ceph数据双写”:先把数据全部封装成一个事务,将其整体作为一条日志,写入ceph-osd journal,然后再把数据定时回刷写入对象文件,将其持久化到ceph-osd filestore中。
基于以上过程,可以将SSD作为ceph-osd journal的底层存储设备,来加速写入性能。同时,由于SSD设备IO性能较高,可以将SSD划分成多个分区,以配比多个HDD设备使用。
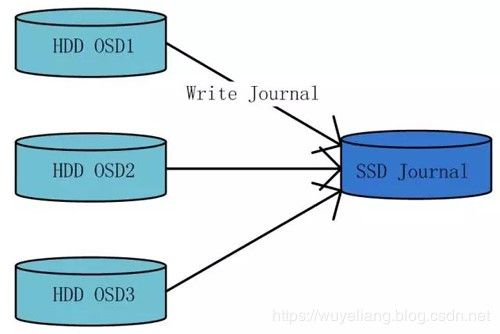
该方案的优点
该方案的优点为使用高速的SSD设备加速ceph-osd journal的写入性能,尤其是对小块数据随机IO的场景,加速效果尤为明显。
该方案的缺点
该方案的缺点为由于ceph-osd journal在实现逻辑上具有循环写入、定期回刷的特性,其对SSD设备容量空间的利用率很低。典型场景下,SSD设备与HDD设备的配比为1:4,而每块HDD设备一般只使用10GB的SSD设备分区,造成了SSD设备容量空间的浪费。
一、准备环境
3台adminos7.4 环境,存储节点上两块磁盘(sda操作系统,sdb数据盘)
172.16.8.94 storage1
172.16.8.95 storage2
172.16.8.96 storage3
二、配置环境
1、修改主机名(对应节点上执行)
# hostnamectl set-hostname storage1
# hostnamectl set-hostname storage2
# hostnamectl set-hostname storage3
2、配置hosts文件(每个节点上均执行)
# cat <<"EOF">/etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
172.16.8.94 storage1
172.16.8.95 storage2
172.16.8.96 storage3
EOF
3、ceph的官方源在国外,网速比较慢,此处添加ceph源为清华源(每个节点上均执行)
# cat </etc/yum.repos.d/ceph.repo
[Ceph]
name=Ceph packages for $basearch
baseurl=https://mirrors.tuna.tsinghua.edu.cn/ceph/rpm-mimic/el7/x86_64/
enabled=1
gpgcheck=1
type=rpm-md
gpgkey=https://download.ceph.com/keys/release.asc
[Ceph-noarch]
name=Ceph noarch packages
baseurl=https://mirrors.tuna.tsinghua.edu.cn/ceph/rpm-mimic/el7/noarch/
enabled=1
gpgcheck=1
type=rpm-md
gpgkey=https://download.ceph.com/keys/release.asc
[ceph-source]
name=Ceph source packages
baseurl=https://mirrors.tuna.tsinghua.edu.cn/ceph/rpm-mimic/el7/SRPMS/
enabled=1
gpgcheck=1
type=rpm-md
gpgkey=https://download.ceph.com/keys/release.asc
END
4、关闭selinux和firewall(各个节点)
# setenforce 0
# sed -i "s/SELINUX=enforcing/SELINUX=permissive/g" /etc/selinux/config
# systemctl disable firewalld.service
# systemctl stop firewalld.service
5、安装NTP(各个节点)
# yum -y install ntp
修改配置文件/etc/ntp.conf
server NTP-server
注意:
NTP-server修改为自己的NTP服务器,如果局域网内无NTP服务器,此处可以用默认配置,采用centos官方ntp服务器
启动服务并设置开机启动
# systemctl start ntpd
# systemctl enable ntpd
查看ntp状态
# ntpq -p
注意:
如果ntp时钟不同步,后面ceph服务起不来!
三、安装和配置ceph(以下操作均在ceph-deploy节点上执行)
1、配置互信
$ ssh-keygen -t dsa -f ~/.ssh/id_dsa -N ""
$ ssh-copy-id 172.16.8.93
$ ssh-copy-id 172.16.8.94
$ ssh-copy-id 172.16.8.95
exit
2、安装ceph-deploy包
$ sudo yum -y install ceph-deploy
注意:最新版的ceph-deploy是2.0,安装操作系统用mimal的ISo会报如下错误,需要安装python-setuptools
[root@storage1 ceph]# ceph-deploy --help
Traceback (most recent call last):
File "/bin/ceph-deploy", line 18, in
from ceph_deploy.cli import main
File "/usr/lib/python2.7/site-packages/ceph_deploy/cli.py", line 1, in
import pkg_resources
ImportError: No module named pkg_resources
# yum install python-setuptools
3、创建配置文件目录
$ mkdir /etc/ceph
4、创建集群
$ cd /etc/ceph
$ ceph-deploy new storage1 storage2 storage3
注意:如果需要指定网络,创建命令跟以下参数
--cluster-network
--public-network
关于ceph的网络拓扑如下:
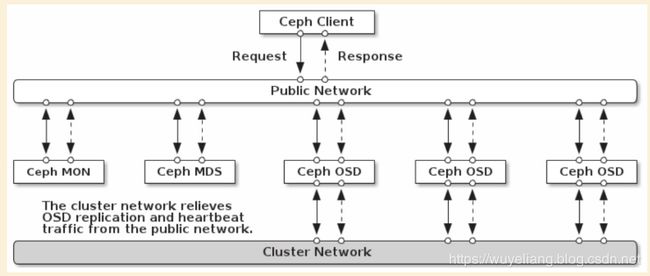
5、在各个节点上安装ceph包
# yum -y install ceph ceph-radosgw
6、、设置monitor和key
$ ceph-deploy mon create-initial
注意:执行完成后会在/etc/ceph目录多以下内容:
ceph.client.admin.keyring
ceph.bootstrap-mgr.keyring
ceph.bootstrap-osd.keyring
ceph.bootstrap-mds.keyring
ceph.bootstrap-rgw.keyring
ceph.bootstrap-rbd.keyring
ceph.bootstrap-rbd-mirror.keyring
7、将ceph.client.admin.keyring拷贝到各个节点上
# ceph-deploy admin storage1 storage2 storage3
8、安装MGR
# ceph-deploy mgr create storage1 storage2 storage3
9、创建OSD(支持filestore和bluestore)
使用filestore
9.1.1、使用filestore采用journal模式(每个节点数据盘需要两块盘或两个分区) 创建逻辑卷
vgcreate data /dev/sdb
lvcreate --size 00G --name log data
9.1.2、创建OSD
# ceph-deploy osd create --filestore --fs-type xfs --data /dev/sdc --journal data/log storage1
# ceph-deploy osd create --filestore --fs-type xfs --data /dev/sdc --journal data/log storage2
# ceph-deploy osd create --filestore --fs-type xfs --data /dev/sdc --journal data/log storage3
使用bluestore
9.2.1、创建逻辑卷
vgcreate cache /dev/sdb
lvcreate --size 100G --name db-lv-0 cache
vgcreate cache /dev/sdb
lvcreate --size 100G --name wal-lv-0 cache
9.2.2、创建OSD
# ceph-deploy osd create --bluestore storage1 --data /dev/sdc --block-db cache/db-lv-0 --block-wal cache/wal-lv-0
# ceph-deploy osd create --bluestore storage2 --data /dev/sdc --block-db cache/db-lv-0 --block-wal cache/wal-lv-0
# ceph-deploy osd create --bluestore storage3 --data /dev/sdc --block-db cache/db-lv-0 --block-wal cache/wal-lv-0
关于filestore和bluestore的区别这篇文章做了详细的说明,在有ssd的情况下bluestore优势比较明显。
http://www.yuncunchu.org/portal.php?mod=view&aid=74
wal & db 的大小问题
使用混合机械和固态硬盘设置时,block.db为Bluestore创建足够大的逻辑卷非常重要 。通常,block.db应该具有 尽可能大的逻辑卷。 建议block.db尺寸不小于4% block。例如,如果block大小为1TB,则block.db 不应小于40GB。 如果不使用快速和慢速设备的混合,则不需要为block.db(或block.wal)创建单独的逻辑卷。Bluestore将在空间内自动管理这些内容block。
10、验证
$ ceph health
HEALTH_OK
参考:
http://docs.ceph.com/docs/mimic/man/8/ceph-deploy/
http://stor.51cto.com/art/201711/559120.htm