【起航】目标检测的里程碑R-CNN通俗详解
前面我们学习了目标检测中常用的评价指标以及传统的目标检测思路,如下:目标检测中常用的评价指标
传统目标检测思路
为了系统的学习,以及形成一个完整的知识体系,所以接下来我们逐步深入学习常见的目标检测模型。后面常见模型的学习顺序大致为R-CNN->SPP-Net->Fast-RCNN->Faster-RCNN->SSD->YOLOv1->YOLOv2->YOLOv3->Mask-RCNN,依次从two-stage到one-stage逐步学习目标检测算法常见的原理。R-CNN是将卷积神经网络方法应用到目标检测问题上的一个里程碑算法,借助于CNN良好的特征提取和分类性能通过RegionProposal的方法实现目标检测。
1. 算法整体框架
算法的整体框架思想还是挺好理解的,如下图,主要是先通过SS区域进行选取候选框,然后对每个候选框固定大小,之后通过一个卷积网络进行提取特征,接着把提取的特征存硬盘,最后对提取的特征进行训练分类器,对候选框进行训练回归器。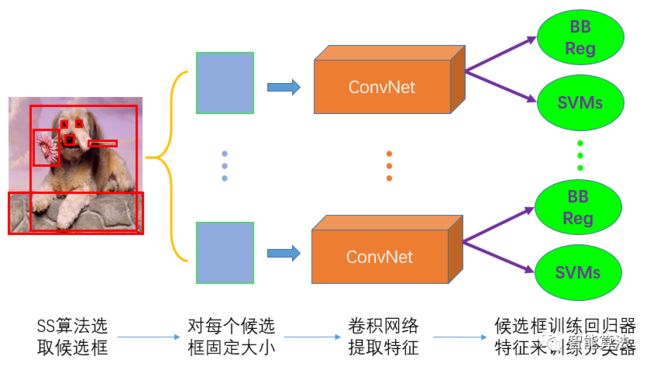
这样整体上来说,跟传统的方法比起来主要是这两方面的改进:
利用SS算法选取候选框,相比于传统滑动窗口方法,大大提高了计算效率。
利用卷积神经网络提取特征也比传统的
HOG,SIFT等方法要好一些。
2. 算法通俗步骤
通过上面的框架,可以知道R-CNN算法的步骤分以下几步:选取候选框,选择网络模型,修改网络结构,特征保存,训练分类器,训练回归器等,我们逐步学习。
2.1 SS算法选取候选框
从之前我们学的传统目标检测算法思路,我们知道,传统的选取候选框的方法常用的是滑动窗口法,但是该方法会产生大量的计算。除了滑动窗口法之外还有另一类基于区域(Region Proposal)的方法,其中Selective Search(SS)算法就是其中之一。
简单来说SS算法就是先通过经典的图像分割方法进行初步分割,然后基于一些视觉特征计算相似区域,最后得到一组目标检测的候选框。如下图:
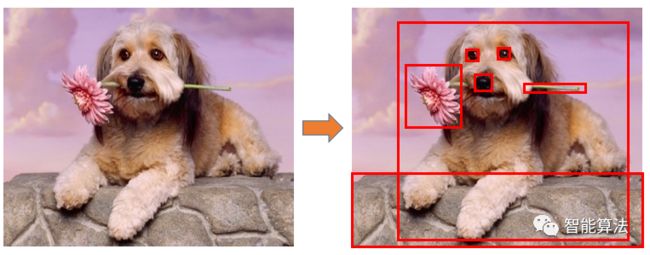
下面,我们来看一下SS算法是怎么工作的?
步骤
输入: 一张图片
输出:候选的目标位置候选区域L
算法:
1: 利用经典的图像分割算法(Graph-Based Segmentation)得到候选的区域集合R = {r1,r2,…,rn}
2: 初始化相似集合S = 0 ,计算区域集R里每个相邻区域的相似度S = {s1,s2,...}
3: while S != 0:
4: 从S中得到最大的相似度s(ri,rj)=max(S)
5: 合并对应的区域rt = ri ∪ rj
6: 移除ri,rj对应的所有相似度
7: 计算rt对应的相似度集合St
8: S = S ∪ St
9: R = R ∪ rt
10: L = R中所有区域对应的边框如上,SS算法就是基于颜色,纹理,大小和形状等视觉特征相似度,来不断的合并区域,以此可以快速的获得不同尺度,多样化的候选区。具有捕捉不同尺度(Capture All Scales)、多样化(Diversification)、快速计算(Fast to Compute)的特点。
2.2 选取模型
首先根据上面的算法整体框架,我们知道,SS算法选取过候选框后,对候选框固定大小尺寸后,就需要进入卷积网络,那么用什么模型的卷积网络呢?有很多比较好的卷积网络模型都可以用,比如VGGNet, AlexNet,这里以VGGNet-16模型为例,如下图:
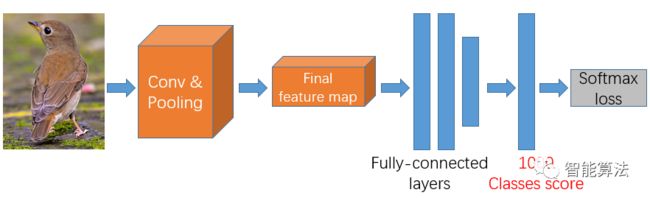
上图中,首先输入区域通过一系列卷积池化的操作,得到最后的特征图,将特征图输入到全连接层中,最后得出分类得分,和损失值。
2.3 微调网络
当我们拿到这个网络后,肯定要做一些修改来适应我们当前的R-CNN算法,我们知道R-CNN是1000个输出类别的网络,那么我们需要将这个输出层的个数进行修改,如下图:
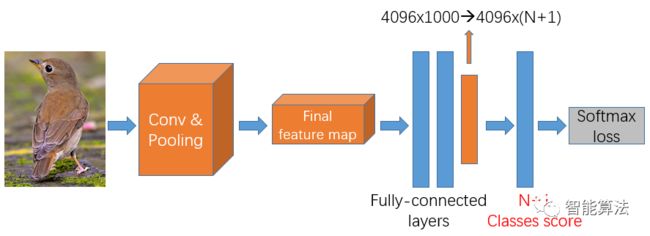
首先将分类个数从1000改为N+1,N是要检测的目标个数,因为还需要有一个背景类,所以要改为N+1,对于VOC数据集来说,N=20,这里就需要改为21,对于ILSVRC2013来说,N=200,那么这里就应该是201。做完网络修改后就可以对该模型进行fine-tuning,主要是优化卷积层和池化层的参数。
2.4 保存硬盘
在做完上一步的修改和优化之后,我们可以对每一个候选区域进行特征提取,按照网络流程,将全连接层前面的最后特征图提取的特征进行保存到硬盘,如下图:
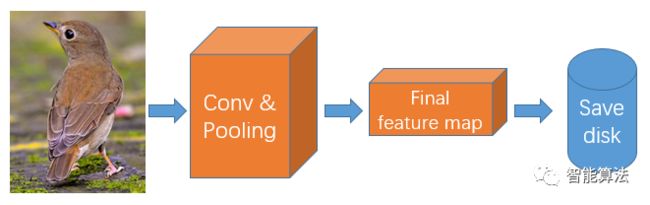
保存到硬盘上的特征是用来做什么的呢?我们继续往下走。
2.5 训练分类器
我们知道,目标检测是一个分类和定位的过程,那么现在先说第一个分类。上一步,我们已经将提取的特征存放到了硬盘中,接着我们将这些特征用来训练一个分类器,这里用的是SVM分类器。也就是说将提取的特征输入到SVM分类器中,利用SVM的分类性能,来达到分类的效果。对于SVM分类器的原理和实战,前面学机器学习算法的时候,我们已经学过,如下:
初识支持向量机原理
深入理解支持向量机算法
支持向量机实践指南(附代码)
这里我们直接看怎么用在R-CNN中。这里有N+1个类别,那么我们就需要有N+1个SVM分类器,也就是说,每一个类别都有一个对应的分类器来判断候选框中的区域是不是该类。如下图:

如上图,以鸟类为例,对应的负样本就是非鸟类候选区域对应的特征,而正样本则是鸟类候选区域对应的特征,如此即可将正负样本对应的特征输入到SVM分类器中进行训练。这样训练完成后,即可得到N+1个分类器。
2.6 训练回归器
对于SS算法选取的候选区域不可能跟标注的Ground Truth完全一致,所以我们需要对SS算法选取的候选框做一个回归,使它尽可能的跟Ground Truth一致。
我们知道一个矩形框的表示是用了一个四位向量[x,y,w,h],分别是中心点坐标和宽高,那么,我们需要回归的就有四个参数[dx,dy,dw,dh],其中dx和dy表示水平竖直平移,dw和dh表示宽度和高度的缩放。通过这4个参数,就可以将候选框区域尽可能的靠近Ground Truth的标注框。那么问题来了,如何训练这4个参数呢?
所以实际上就是利用上面提取出来的特征,学习一种映射关系,使得候选区域尽可能的接近Ground Truth。那么需要回归的损失就是预测区域跟Ground Truth的距离,有了损失函数,就可以通过最小二乘法或者梯度下降来进行回归训练,得到[dx,dy,dw,dh]。如下图:

如上图,回归值就是上面通过损失函数训练出来的[dx,dy,dw,dh],比如对应左边候选区域的回归值是[0,0,0,0],说明该区域跟标注区域是一致的(也就是IoU大于设定阈值),中间图的回归值[0.25,0,0,0]表示该候选框需要向左移动25%,而右图回归值[0,0,-0.15,0]表示宽度缩小15%。
3. R-CNN小结
R-CNN通过以上步骤,在ILSVRC2013的200分类检测数据集上,表现还可以,mAP达到了31.4%,远远超过传统方法。通过以上学习,我们可以看出来R-CNN存在以下三个明显的问题:
多个候选区域对应的图像需要预先提取,占用较大的磁盘空间;
针对传统
CNN需要固定尺寸的输入图像,归一化会产生物体截断或拉伸,会导致输入CNN的信息丢失;每一个候选框都需要进入
CNN网络计算,上千个Region存在大量的范围重叠,重复的特征提取带来巨大的计算浪费。
那么接下来,我们会学习在R-CNN上发展起来的算法Fast-RCNN和Faster-RCNN。
