Python爬虫 requests模块使用post方法提交表单
使用
requests库中的post(url,params)方法,先通过观察表单的网页源代码,或者是通过逆向工程的方法获取表单提交的字段,构造参数params,就能实现模拟登录操作.
例如:url = 'http://xxx.com/login' captcha = input() params = { 'email': '[email protected]', 'password': '********', } html = requests.post(url, params)就是一个典型的利用Post登录网站的方法.
不过想要获取表单进行提交还需要一些技巧,下面将描述两个获取的方法.
查看网页源代码提交表单
以 https://www.douban.com/豆瓣网为例,豆瓣网的登录只需要填写账号和密码就能登录.

我们根据表单找到相应的源代码信息:
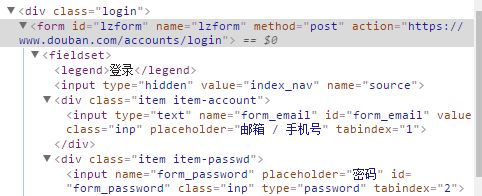
其中,标签是表单,中的action=为表单提交的URL,下面中为表单提交的字段,name=就是字段的名称,由此可以构造表单进行登录.(因为没有验证码,所以只需要构造来源,邮箱,密码即可登录)
import requests
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) '
'AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/67.0.3396.79 Safari/537.36'
}
url = 'https://www.douban.com/accounts/login'
# html=requests.get(url,headers)
params = {
'source': 'index_nav', # 在首页进行登录
'form_email': '[email protected]', # 邮箱/手机号
'form_password': '********' # 密码
}
html = requests.post(url, params)
html.encoding = html.apparent_encoding
print(html.text)
查看html,可以发现登陆已经成功
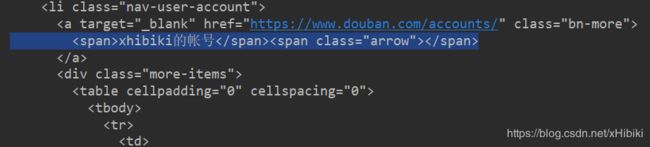
逆向工程提交表单

在浏览器中打开开发者工具,选择Network,然后输入邮箱和密码,点击登录.

发现在All中第一个文件是login,通过查看Headers获取到方法是Post,请求的URL

在最下方的Form Data得到提交的表单信息
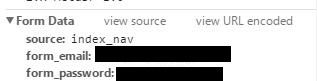
这样就可以不用观察源代码得到了表单的信息.之后就可以编写代码使用Post进行登录.
针对验证码的表单提交
现在像豆瓣网这种登录只需要账号密码,不用验证码的太少了,这里以 http://bangumi.tv/Bangumi 番组计划为例,说明一下.

用逆向工程的方法登录后,可以看到POST和URL

在Form data中得到表单的信息
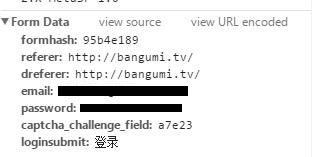
不过提交的表单中不仅包括了表单的哈希值,登录的来源,邮箱,密码,还有验证码和点击的按钮.
通过验证源代码,确定只会改变的是验证码
前三个值

账号和密码
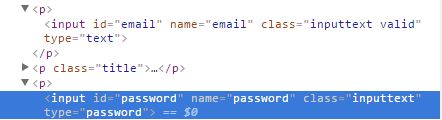
验证码
登录框(不是很懂为什么这个要提交)

所以在构建params时,需要先将网页中的验证码图片下载下来,通过人工观察,或者验证码识别工具或者深度学习的方法等获取验证码的信息,填写到params中才能实现登录.
因为还没学得这么深,所以这里只用人工观察的方法获取验证码信息
获取验证码
url='http://bangumi.tv/login'
res=requests.get(url,headers)
res.encoding=res.apparent_encoding
selector=etree.HTML(res.text)
selector.xpath('//p[@class="captcha_img"]/img/@src')
但是遗憾的是,selector并没有返回任何的内容

也就是虽然标签存在,但是验证码图片并不是立刻出现在response中,而是只用了异步加载的技术加载,查看network选项卡进行抓包,
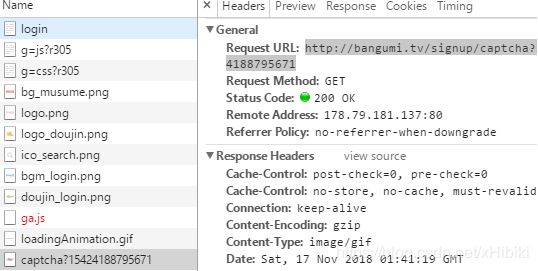
果不其然,得到了验证码URL,将验证码保存到本地
import requests
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) '
'AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/67.0.3396.79 Safari/537.36'
}
captcha_url = 'http://bangumi.tv/signup/captcha?15424188795671'
res = requests.get(captcha_url, headers)
with open('d:/captcha.jpg', 'wb') as pf:
pf.write(res.content)
在d:/根目录下就能找到验证码,
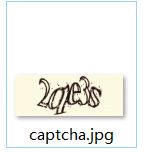
根据验证码构造params
url = 'http://bangumi.tv/FollowTheRabbit'
captcha = input() #输入本地路径的验证码信息,例如上图中的2qe3s
params = {
'form_hash': '95b4e189',
'referer': 'http://bangumi.tv/',
'dreferer': 'http://bangumi.tv/',
'email': '[email protected]',
'password': '********',
'captcha_challenge_field': captcha,
'loginsubmit': '登录'
}
html = requests.post(url, params)
html.encoding = html.apparent_encoding
print(html.text)
然而很遗憾还是不行…

这是因为,验证码存在自身拥有hash校验值和时间值所以它的URL也是会变化的,不能用于相同的登录页面.
不过不用担心,我们还有最终的解决方法—Selenium模拟浏览器,不过这里篇幅太小,写不下.
解决方法可以继续参考我的这篇文章还没写完