目录
一.基于权重的随机负载均衡策略
二.基于轮询的负载均衡策略
三.基于权重的轮询负载均衡策略
四.基于最少活跃数的轮询负载均衡策略
五.基于一致性hash的负载均衡策略
一.基于权重的随机负载均衡策略
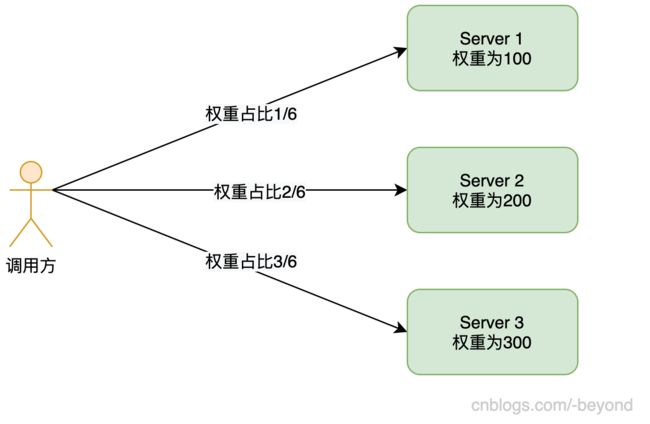
有3台机器,每台机器都有各自的权重,如下如所示:

现在假设用户发起1次调用,请求被Server1处理,下一次请求,请求可能仍然被Server1处理,也可能是Server2或者Server3处理。
只是在大量调用后,总体的规律是,1/6的请求会走到Server1上,2/6的请求会走到Server2上,3/6的请求会走到Server3上。
二.基于轮询的负载均衡策略
这种策略,与每台机器的权重就没有关系了,如下图所示:

在这种策略中,第1次请求被Server1处理,第2次请求被Server2处理,第3次请求被Server3处理,第4次请求被Server1处理,第5次请求被Server2处理,第6次请求被Server3处理....每个节点都会依次接收处理请求。
三.基于权重的轮询负载均衡策略
这种策略,是在轮询策略上增加了权重这个因素,如下图所示:
使用这种策略,会将请求“分组”,以上面这个图为例,因为总权重为600,和各节点约分后,分别占权重1/6,2/6,3/6,那么这个“分组”就是6,也就是说6个请求为一组,Server1会处理其中的1个请求(因为其权重占比为1/6),同理,Server2会处理2个请求,Server3会处理3个请求。
现在假设有2组(也就是12个请求),那么处理过程如下:
1.发起第1次请求,请求被Server1处理;
2.发起第2次请求,请求被Server2处理;
3.发起第3次请求,请求被Server3处理;
4.发起第4次请求,请求被Server2处理,注意,此时不是Server1处理,因为Server1已经处理了1/6的请求;
5.发起第5个请求,请求被Server3处理;
6.发起第6个请求,请求被Server3处理,注意,此时不是Server2处理,因为Server2已经处理2/6的请求;
此时,一组请求已经完成处理(共6个),接着进行第2组的处理。
7.发起第7个请求,请求被Server1处理;
8.发起第8次请求,请求被Server2处理;
9.发起第9次请求,请求被Server3处理;
10.发起第10次请求,请求被Server2处理,注意,此时不是Server1处理,因为Server1已经处理了1/6的请求(1个请求);
11.发起第11个请求,请求被Server3处理;
12.发起第12个请求,请求被Server3处理,注意,此时不是Server2处理,因为Server2已经处理2/6的请求(2个请求);
四.基于最少活跃数的轮询负载均衡策略

这里说的“最少活跃数”,是指每个Server正在处理的请求数量。
每个Server维护一个counter计数器,当一个请求被Server处理时,counter加1,当请求被处理完毕,counter减1。
新发起的请求总是被counter最小的Server处理,因为counter最小,从侧面可以推断出请求到达该Server后,会更快的拿到响应结果。
五.基于一致性hash的负载均衡策略
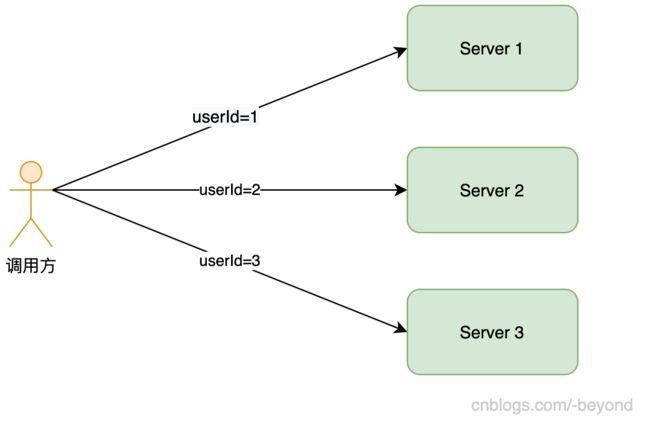
轮询和随机,这两种策略都存在这样一个问题,假设是同一个用户发起的多次请求,按照轮询和随机的规则,这多次请求会被不同Server机器处理。
但有些时候为了让同一用户的请求都被同一个Server处理,一般会根据某个条件进行路由,比如用userId取mod,确定服务器的编号,这样的话,一个用户发起多次请求,请求都将会被同一个机器处理。
上面说的这种方式,是一种简单的取模确定机器,但是存在雪崩的风险,为了避免出现这个风险,所以才有了一致性hash的算法,关于一致性hash算法,这里就不阐述了。