动态网页数据抓取(ajax,selenium 基础)
文章目录
- ajax
- 什么是 ajax
- 获取 ajax 数据的方式
- selenium+chromedriver 获取动态数据
- 有界面的
- 无界面的
- 无界面测试 test.py
- selenium 常见操作
- 关闭页面
- 定位元素
- 常见的表单元素
- 页面前进后退
- 浏览器界面大小自定义
- 屏幕截图
- 页面刷新
- 滚动页面
- 退出浏览器
- 练习:
- 注:
ajax
什么是 ajax
- ajax 异步 JavaScript 和 xml,在后台与服务器之间使用 xml 格式进行少量数据交换,ajax 可以使网页实现异步更新,这意味着可以在不重新加载整个网页的情况下,对网页的某部分进行更新
- 传统的网页(不适用 ajax)如果需要更新内容,必须重新加载整个网页页面,因为传统的 ajax 在传输数据格式方面,使用的是 xml 语法,因此叫做 ajax,其实现在数据交互基本上都是 json,使用 ajax 加载的数据,即使使用了 js,将数据渲染到了浏览器中,在
右键-查看网页源代码还是不能看到通过 ajax 加载的数据,只能看到使用这个 url 加载的 html 代码
获取 ajax 数据的方式
- 直接分析 ajax 调用的接口,然后通过代码请求这个接口
- 使用 selenium + chromedrieve 模拟浏览器行为获取数据
| 方式 | 优点 | 缺点 |
|---|---|---|
| 分析接口 | 直接可以请求到数据,不需要做一些解析工作,代码量少,性能高 | 分析接口比较复杂,特别是一些通过 ajax 混淆的接口,要有一定的 js 功底,容易被发现是爬虫 |
| selenium | 直接模拟浏览器的行为,浏览器能请求到的,使用 selenium 也能请求到,爬虫更稳定 | 代码量多,性能低 |
selenium+chromedriver 获取动态数据
有界面的
- 安装 selenium:selenium 有很多语言的版本,有 Java,ruby,python 等,我下载 pyhton
pip install selenium - 安装
chromedriver:下载完成后,放到不需要权限的纯英文目录下就可以,Chromedriver:
https://sites.google.com/a/chromium.org/chromedriver/downloads
无界面的
- 无界面的,比如腾讯云 Ubuntu18 服务器
- 安装 selenium:
pip install selenium - 安装 chrome:
sudo apt-get install libxss1 libappindicator1 libindicator7 # 依赖包
wget -c https://dl.google.com/linux/direct/google-chrome-stable_current_amd64.deb
sudo dpkg -i google-chrome*.deb
sudo apt-get install -f
google-chrome --version # 看版本
- 安装 chromedriver:在https://npm.taobao.org/mirrors/chromedriver中查找对应 chrome 版本的 chromedriver
wget -c https://npm.taobao.org/mirrors/chromedriver/80.0.3987.16/chromedriver_linux64.zip
unzip chromedriver_linux64.zip #解压
sudo chmod +x /home/ubuntu/chromedriver #授权
无界面测试 test.py
from selenium import webdriver
options = webdriver.ChromeOptions()
options.add_argument('--headless') #浏览器无界面加载,必须有
options.add_argument('--disable-gpu') #不开启 GPU 加速
options.add_argument('--no-sandbox') # 以根用户打身份运行Chrome,使用-no-sandbox标记重新运行Chrome,禁止沙箱启动
driver = webdriver.Chrome(options=options, executable_path='/home/ubuntu/chromedriver')
driver.get('https://www.jianshu.com/')
print(driver.page_source)
driver.quit()
- 其他设置
chromeOptions.add_argument('--hide-scrollbars') #隐藏滚动条, 应对一些特殊页面
chromeOptions.add_argument('blink-settings=imagesEnabled=false') #不加载图片, 提升速度
chromeOptions.add_argument("user-agent=Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36") #伪装其它版本浏览器,有时可以解决代码在不同环境上的兼容问题,或者爬虫cookie有效性保持一致需要设置此参数
————————————————
版权声明:本文为CSDN博主「wto882dim」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/wto882dim/article/details/101214371
- 如果报错
selenium.common.exceptions.WebDriverException: Message: unknown error: Chrome failed to start: exited abnormally(unknown error: DevToolsActivePort file doesn't exist)
设置chromeOptions.add_argument('--disable-dev-shm-usage')
selenium 常见操作
- 更多教程参考:https://readthedocs.org/#introduction
关闭页面
- driver.close():关闭当前页面
- driver.quit():退出整个浏览器
定位元素
- find_element_by_id:根据 id 来查找某个元素,等价于
submitTag = driver.find_element_by_id('su')
submitTag1 = driver.find_element(By.ID,'su')
- find_element_by_class_name:根据类名查找元素,等价于:
submitTag = driver.find_element_by_class_name('su')
submitTag1 = driver.find_element(By.CLASS_NAME,'su')
- find_element_by_name:根据 name 属性的值查找元素,等价于:
submitTag = driver.find_element_by_name('email')
submitTag1 = driver.find_element(By.NAME,'email')
- find_element_by_tag_name:根据标签名查找元素,等价于:
submitTag = driver.find_element_by_tag_name('div')
submitTag1 = driver.find_element(By.TAG_NAME,'div')
- find_element_by_xpath:根据 xpath 语法来获取元素,等价于:
submitTag = driver.find_element_by_xpath('//div')
submitTag1 = driver.find_element(By.XPATH,'//div')
- find_element_by_css_selector:根据 css 选择器选择元素,等价于:
submitTag = driver.find_element_by_css_selector('//div')
submitTag1 = driver.find_element(By.CSS_SELECTOR,'//div')
常见的表单元素
- input(type=password/email/text/submit/number)
- button input(type=submit)
- checkbox input(type=checkbox)
- select 下拉列表
页面前进后退
控制浏览器后退、前进
WebDriver 也提供了对应的 back()和 forward()方法来模拟后退和前进按钮.
from selenium import webdriver
driver = webdriver.Firefox()
#访问百度首页
first_url= ‘http://www.baidu.com’
print “now access %s” %(first_url)
driver.get(first_url)
#访问新闻页面
second_url=‘http://news.baidu.com’
print “now access %s” %(second_url)
driver.get(second_url)
#返回(后退)到百度首页
print "back to %s "%(first_url)
driver.back()
#前进到新闻页
print “forward to %s”%(second_url)
driver.forward()
driver.quit()
浏览器界面大小自定义
-
浏览器运行后,如果页面没有最大化,可以调用driver.maximize_window()将浏览器最大化,相当于点击了页面右上角的最大化按钮
-
也可以自定义浏览器的尺寸
driver.maximize_window() #浏览器窗口最大化
driver.set_window_size(500, 360) #设置窗口大小为500*360
屏幕截图
- 打开页面以后,可以对页面进行截屏(无界面也可以截屏),在遇到异常的时候,根据截图可以快速定位问题的原因所在
- 浏览器截屏操作,参数是截屏的图片保存路径:
#1. get_screenshot_as 系列
driver.get_screenshot_as_file('/home/ubuntu/test_spider/jietu.png')
#2. save_screenshot
driver.save_screenshot('/home/ubuntu/test_spider/screenshot.png')
- 无界面截图
页面刷新
- 有时页面过期后,网页上显示的信息可能不是最新的,需要对页面进行刷新,使用refresh()方法刷新页面,相当于点击浏览器的刷新按钮
driver.refresh() #重新加载页面
滚动页面
driver.execute_script('window.scrollBy(0,10000)') #滚动到页面的末尾
driver.execute_script('var q=document.documentElement.scrollTop=10000') #滚动到页面的末尾
driver.execute_script('var q=document.documentElement.scrollTop=0') #滚动到页面的顶部
driver.execute_script('var q=document.body.scrollTop=10000') #滚动到 body 标签末尾
driver.execute_script('window.scrollTo(0, document.body.scrollHeight)') #滚动到 body 标签末尾
driver.execute_script("window.scrollTo(0,0)") #滚动到页面顶部
ul_tag = driver.find_elements(By.CLASS_NAME, 'note-list')[0]
# 移动到元素对象的“底端”与当前窗口的“底部”对齐
driver.execute_script('arguments[0].scrollIntoView(false);', ul_tag)
# 移动到元素对象的“顶端”与当前窗口的“顶部”对齐
driver.execute_script("arguments[0].scrollIntoView();", ul_tag)
退出浏览器
在测试脚本运行完后,一般会在最后关闭浏览器,有两种方法关闭浏览器,close()方法用于关闭当前页面,quit()方法关闭所有和当前测试有关的浏览器窗口
driver.close() //关闭当前页面
driver.quit() //关闭所有由当前测试脚本打开的页面
driver.switch_to_alert().accept()#处理警告弹窗
time.sleep(2)
print’处理好警告弹窗’
js=“var q=document.documentElement.scrollTop=10000”
driver.execute_script(js)#处理右侧的滚动条
time.sleep(3)
print"右侧的滚动条拉倒最低处"
练习:
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
# chromedriver 的储存路径
# driver_path = 'C:\Program Files (x86)\Google\Chrome\Application\chromedriver.exe'
driver_path = 'D:\downloads\chromedriver_win32\chromedriver.exe'
# 初始化 driver,并且指定 chromedriver 的路径
driver = webdriver.Chrome(executable_path=driver_path)
# 请求网页
# driver.get('https://www.baidu.com/')
# 通过 page_source 获取网页源代码
# print(driver.page_source)
# 通过标签 id 的属性值查找
# inputTag = driver.find_element_by_id('kw')
# inputTag = driver.find_element(By.ID,'kw')
# 通过标签的 name 属性值查找
# inputTag = driver.find_element_by_name('wd')
# inputTag = driver.find_element(By.NAME,'wd')
# 通过标签的类名查找
# inputTag = driver.find_element_by_class_name('s_ipt')
# inputTag = driver.find_element(By.CLASS_NAME,'s_ipt')
# 通过标签名查找所有的 input 标签的第八个 input
# inputTag = driver.find_elements_by_tag_name('input')[7]
# inputTag = driver.find_elements(By.TAG_NAME,'input')[7]
# 通过 xpath 查找
# inputTag = driver.find_element_by_xpath('//input[@id="kw"]')
# inputTag = driver.find_element(By.XPATH,'//input[@id="kw"]')
# 通过 css 选择器查找(class="soutu-btn" 紧随的 input)
# inputTag = driver.find_element_by_css_selector('.soutu-btn + input')
# inputTag = driver.find_element(By.CSS_SELECTOR,'.soutu-btn + input')
# 通过 css 选择器查找 class="bg s_ipt_wr iptfocus quickdelete-wrap" 的 span 的
# id="kw" 的子标签(即 id="kw" 的 input)
# inputTag = driver.find_element_by_css_selector(
# 'span[class="bg s_ipt_wr iptfocus quickdelete-wrap"] #kw'
# )
# inputTag = driver.find_element(By.CSS_SELECTOR,
# 'span[class="bg s_ipt_wr iptfocus quickdelete-wrap"] #kw'
# )
# 通过 css 选择器查找 class="bg s_ipt_wr iptfocus quickdelete-wrap" 的 span 的
# 所有 input 子标签(是个列表)的第一个 input 标签
# inputTag = driver.find_elements_by_css_selector(
# 'span[class="bg s_ipt_wr iptfocus quickdelete-wrap"] input'
# )[0]
# inputTag = driver.find_elements(By.CSS_SELECTOR,
# 'span[class="bg s_ipt_wr iptfocus quickdelete-wrap"] input'
# )[0]
# 如果只是想要解析网页的数据,推荐将网页源代码用 lxml 解析,因为 lxml 是用 c 语言写的,解析效率会更高
# 如果想要对元素进行一些操作,比如给一个文本框输入值,或者是点击某个按钮,就必须使用 selenium 给我们提供的查找元素的方法
# inputTag.send_keys('xingye')
# 输入框
# inputTag = driver.find_element_by_id('kw')
# 填写内容到 input 标签
# inputTag.send_keys('xingye')
# time.sleep(3)
# 清除 input 标签内的内容
# inputTag.clear()
# checkbox
# driver.get('http://login.kaixin001.com/')
# print(driver.page_source)
# rememberBtn = driver.find_element(By.NAME,'remember')
# time.sleep(3)
# # 自动勾选开心网的 记住我
# rememberBtn.click()
# time.sleep(2)
# rememberBtn.click()
# select 选择框
# 将获取到的元素当成参数传到这个类中,创建这个对象,
# 以后就可以使用这个对象进行选择了
from selenium.webdriver.support.ui import Select
# driver.get('http://www.mailianjie.com/?renqun_youhua=191401')
# print(driver.page_source)
# selectBtn = Select(driver.find_element(By.NAME,'n'))
# # 索引,第一个为 0
# selectBtn.select_by_index(2)
# value 属性的内容
# selectBtn.select_by_visible_text()
# selectBtn.select_by_value('50')
# time.sleep(2)
# 按钮点击
driver.get('https://www.baidu.com')
inputTag = driver.find_element(By.ID,'kw')
inputTag.send_keys('xingye')
submitTag = driver.find_element(By.ID,'su')
submitTag.click()
注:
- 在获取时可能会发现按网页源代码获取不到,这时要以 page_source 的返回为标准,比如:
page_source:

网页源代码:

检查:
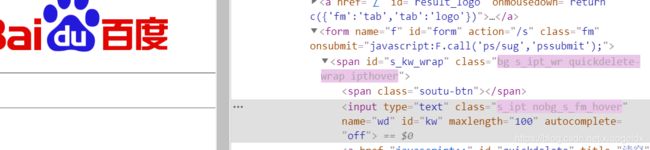
- 如果按照网页源代码方式写,是得不到我们想要的结果,所以要以 page_source 返回的结果