首先做一下背景介绍,Tesseract是一个开源的OCR组件,主要针对的是打印体的文字识别,对手写的文字识别能力较差,支持多国语言(中文、英文、日文、韩文等)。是开源世界里最强的一款OCR组件。当然和世界最强的OCR工具Abbyy相比还是有一点差距,尤其在图片质量较差时,差距还是明显的。
网上有很多关于如何使用这个组件的介绍,不过都是针对英文识别的。而如果是对中文或日文等方块字进行识别,除了需要使用不同的语言包外,还要对Tesseract做一些特别的设置,否则识别率会很低,以下我就和大家分享一下我使用Tesseract对日文做OCR的一些经验。
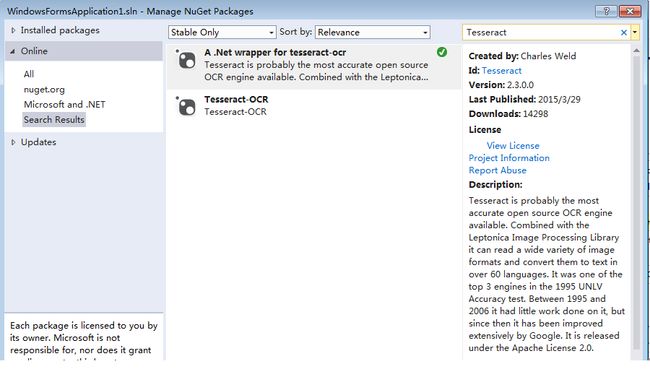
第一步,是要下载Tesseract组件,最简单的方法就是使用VisualStudio的NUGet来下载。选择第一个组件。
第二步,下载日文语言包,由于在大陆地区无法访问google,所以不能打开官网直接下载语言包。我给出文件的地址,可以使用迅雷下载。
http://tesseract-ocr.googlecode.com/files/tesseract-ocr-3.02.jpn.tar.gz
下载完成后将语言包文件解压后放到tessdata文件夹下。
到目前为止,准备工作已经就绪,可以开始编写代码。
第三步,初始化Tesseract组件,代码如下。
TesseractEngine engine = new TesseractEngine(@"tessdata文件夹路径", "jpn", EngineMode.Default))
第四步,设置OCR参数,关于各参数的解释,可以参照官网
Useful parameters for Japanese and Chinese
Some Japanese tesseract user found these parameters helpful for increasing tesseract-ocr (3.02) accuracy for Japanese :
| Name | Suggested value | Description |
| chop_enable | T | Chop enable. |
| use_new_state_cost | F | Use new state cost heuristics for segmentation state evaluation |
| segment_segcost_rating | F | Incorporate segmentation cost in word rating? |
| enable_new_segsearch | 0 | Enable new segmentation search path. It could solve the problem of dividing one character to two characters |
| language_model_ngram_on | 0 | Turn on/off the use of character ngram model. |
| textord_force_make_prop_words | F | Force proportional word segmentation on all rows. |
| edges_max_children_per_outline | 40 | Max number of children inside a character outline. Increase this value if some of KANJI characters are not recognized (rejected). |
以下是代码
engine.SetVariable("chop_enable ", "F"); engine.SetVariable("enable_new_segsearch", 0); engine.SetVariable("use_new_state_cost ", "F"); engine.SetVariable("segment_segcost_rating", "F"); engine.SetVariable("language_model_ngram_on", 0); engine.SetVariable("textord_force_make_prop_words", "F"); engine.SetVariable("edges_max_children_per_outline", 50);
这里面chop_enable参数与官网推荐的不太一样,我发现按照官网的设置,会有很多文字识别不出来。
第五步,开始识别。
var page = engine.Process(p); var testText = page.GetText(); var c=page.GetMeanConfidence();
第一行代码返回一个Page对象,通过该对象可以获得识别的文本,而且还可以获得识别文本所在位置(这个在识别非固定模式文档时非常有用,可以根据关键字动态查找识别字段位置)。
在例子中OCR做全文识别,但是做全文识别很多情况下识别质量一般,最好增加识别区域参数,同时将PageSegMode参数设置为PageSegMode.SingleBlock(代表多行大小相同的文字)或PageSegMode.SingleRow(代表单行大小相同的文字)。
第二行和第三行分别返回识别的文本与识别的信任度。在实际使用时我发现识别信任度不是特别有用。无论识别对错,信任度基本在0.7左右,有些时候信任度较高,识别结果反而是错误的。
经过以上几步,就可以完成日文的OCR。但要让以上代码成功运行,还必须要在安装VC++运行时2012,否则会报错。
我使用以上方法对扫描图片进行测试,发现识别精确度还是比较高的,尤其在指定区域与PageSegMode参数后。但是日文字库也存在一些低级失误,如将数字“1”识别成了汉字“一”等。如果要想解决这个问题,必须要从头训练日文,这个工作量非常大!而这真的是Tesseract一个非常不智能的地方,应该支持在原有训练字库的基础上追加训练内容!或者在官网上提供Box文件和训练用Tif供开发者下载。