linux操作系统之 内存管理
linux内存管理
linux内核给每一个进程都提供了一个独立的虚拟地址空间,并且这个地址空间是连续的。这样,进程就可以很方便地访问内存,也就是虚拟内存。
虚拟地址空间分为:内核空间和用户空间,不同字长(cpu指令可以处理数据的最大长度)的处理器,地址空间的范围也不同。如:32位和64位
进程在用户态时,只能访问用户空间的内存;只有进入内核态时才能访问内核空间内存。虽然每个进程的地址空间都包含了内核空间,但这些内核空间,其实关联的都是相同的物理内存。这样,进程切换到内核态后,就可以很方便地访问内核空间内存。
每一个进程都有一个这么大的地址空间,那么所有进程的虚拟内存加起来,自然要比实际的物理内存大的多。并不是所有的虚拟内存都会分配物理内存,只有那些实际使用的虚拟内存才分配物理内存,并且分配后的物理内存,是通过内存映射来管理的。
内存映射,其实就是将虚拟内存地址映射到物理内存地址。为了完成内存映射,内核为每一个进程都维护了一张页表,记录虚拟地址与物理地址的映射关系
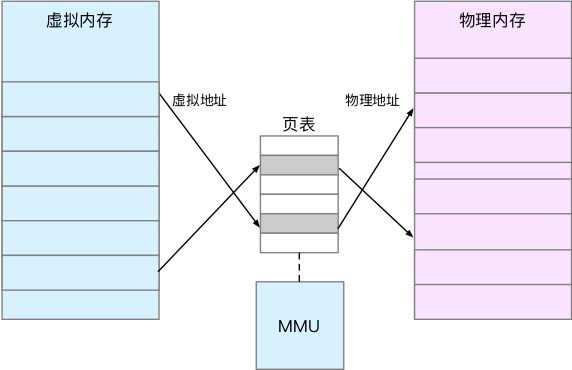
页表实际存储在cpu的内存管理单元MMU中,这样,正常情况下,处理器就可以直接通过硬件,找到要访问的内存。当进程访问的虚拟地址在页表中查不到时,系统会产生一个缺页异常,进入内核空间分配物理内存、更新进程页表,最后再返回用户空间,恢复进程的运行。
TLB(备缓冲器),就是MMU中页表的高速缓存。由于进程的虚拟地址空间是独立的,而TLB的访问速度又比MMU快得多,所以,通过减少进程的上下文切换,减少TLB的刷新次数,就可以提高TLB缓存的使用率,进而提高cpu的内存访问性能。
MMU不是以字节为单位来管理内存,而是规定了一个内存映射的最小单位,也就是页,大小4KB。每一次内存映射,都需要关联4KB或者4KB整数倍的内存空间。
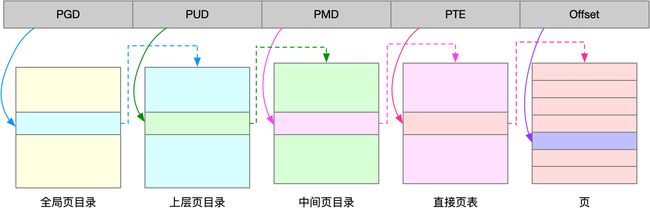
为了解决页表项过多的问题,linux提供了两种机制,也就是多级页和大页(HugePage)。
多级页:就是把内存分成区块来管理,将原来的映射关系改成块索引和区块内的偏移。由于虚拟内存空间通常只用了很少一部分,那么,多级页就保存这些使用中的区块,这样就可以大大地减少页表的项数。
linux使用四级页表来管理内存页。前4个表项用于选择页,最后一个索引表示页内偏移。
大页:比普通页更大的内存块,常见的有2MB和1GB。大页通常用在使用大量内存的进程上,如:Oracle等
linux进程如何使用内存
虚拟内存空间分布
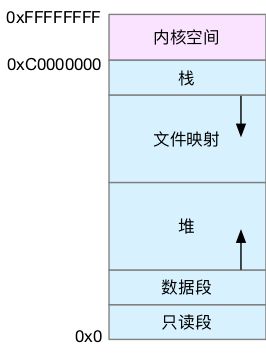
1、只读段:包括代码和常量
2、数据段:包括全局变量
3、堆:包括动态分配内存,从低地址开始向上增长
4、文件映射段:包括动态库、共享内存等,从高地址开始向下增长
5、栈:包括局部变量和函数调用的上下文等。栈的大小都是固定的,一般都是8MB。
内存分配和回收
malloc()是C标准库提供的内存分配函数,对应到系统调用上,有两种实现方式:brk()和mmap()。
brk():小块内存(小于128k),C标准库使用brk()来分配,也就是通过移动堆顶的位置来分配内存。这些内存释放后并不会立即归还系统,而是被缓存起来,这样就可以重复使用。
MMap():大块内存(大于128k),则直接使用内存映射mmap()来分配,也就是在文件映射段找一块空闲内存分配出去,释放后直接归还系统。
但是,这两种分配都有优缺点,brk可以减少缺页异常的发生,提高内存访问效率。这些内存没有归还系统,在内存工作繁忙时,在内存工作繁忙时,频繁的内存分配和释放会造成内存碎片。mmap会直接归还系统,所以每次mmap都会发生缺页异常。在内存工作繁忙时,频繁的内存分配会导致大量的缺页异常,使内核的管理负担增大。
linux通过三种方式回收内存:
回收缓存:使用LRU算法,回收最近使用最少的内存页面;
回收不常访问的内存:把不常用的内存通过交换分区直接写在磁盘中;
杀死进程:内存紧张时系统会通过oom,直接杀死占用大量内存的进程
其中,第二种方式回收不常访问的内存时,会用到交换分区swap。swap其实就是把一块磁盘空间当作内存使用。它可以把进程暂时不用的数据存储到磁盘中(这个过程就是换出)。当进程访问这些内存时,再从磁盘读取这些数据到内存中(这个过程称换入)。通常在内存不足时,才会使用swap。
第三种方式oom,其实是内核的一种保护机制。它监控进程的内存使用情况,并且使用oom_score为每一个进程的内存使用情况进行评分:
一个进程消耗的内存越大,oom_score就越大;
一个进程运行占用用的cpu越多,oom_score就越小。
可以通过手动设置进程的oom_adj,从而调整进程的oom_score。oom_adj的范围【-17,15】,数值越大,表示进程越容易被oom杀死;数值越小,表示进程越不容易被oom杀死,其中-17表示禁止oom。
[root@test proc]# lsof -i:22
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
sshd 3043 root 3u IPv4 21799 0t0 TCP *:ssh (LISTEN)
sshd 3499 root 3u IPv4 23448 0t0 TCP test:ssh->123.139.156.118:53251 (ESTABLISHED)
sshd 3552 root 3u IPv4 23652 0t0 TCP test:ssh->123.139.156.118:53254 (ESTABLISHED)
[root@test proc]# cat /proc/3043/oom_adj
-17
#此时ssh进程的oom_adj为-17,ssh就不容易被杀死查看内存整体情况
free
[root@test ~]# free -hm
total used free shared buff/cache available
Mem: 991M 93M 399M 484K 498M 737M
Swap: 0B 0B 0B
[root@test ~]# grep Cached /proc/meminfo
Cached: 408672 kB
SwapCached: 0 kB
[root@test ~]# grep Buffer /proc/meminfo
Buffers: 41252 kBtotal:总内存大小;
used:已经使用的内存大小,包含了共享内存;
free:未使用内存大小;
shared:共享内存大小;
buff/cache:缓存和缓冲区的大小;
available:新进程可用内存的大。
注意:available包含了可回收的缓存,所以大于free未使用的内存。并不是所有缓存都可以回收。
top
[root@test proc]# top
top - 11:42:36 up 2:10, 2 users, load average: 0.00, 0.01, 0.05
Tasks: 77 total, 1 running, 76 sleeping, 0 stopped, 0 zombie
%Cpu(s): 0.3 us, 0.3 sy, 0.0 ni, 98.0 id, 1.3 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem : 1015024 total, 352724 free, 94188 used, 568112 buff/cache
KiB Swap: 0 total, 0 free, 0 used. 747996 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
3476 root 20 0 611432 13556 2364 S 0.3 1.3 0:23.47 barad_agent
3775 root 20 0 571352 7168 2528 S 0.3 0.7 0:10.34 YDService
1 root 20 0 125476 3916 2592 S 0.0 0.4 0:01.45 systemd
2 root 20 0 0 0 0 S 0.0 0.0 0:00.00 kthreadd
3 root 20 0 0 0 0 S 0.0 0.0 0:00.10 ksoftirqd/0
5 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 kworker/0:0H
7 root rt 0 0 0 0 S 0.0 0.0 0:00.00 migration/0
8 root 20 0 0 0 0 S 0.0 0.0 0:00.00 rcu_bh
9 root 20 0 0 0 0 S 0.0 0.0 0:00.61 rcu_sched VIRT:进程虚拟内存的大小,只要申请过的内存,即便还没有真正分配物理内存,也会计算在内。
RES:常驻内存大小,也就是进程实际使用的物理内存大小,但不包括swap和共享内存
SHR:共享内存大小,如与其他进程共同使用的共享内存、加载的动态链接库以及程序的代码段等。
%MEM:进程使用物理内存占系统内存的百分比。
Buffers and Cached
Buffers是对原始磁盘块的临时存储,也就是用来缓存磁盘的数据,通过不会特别大(几十MB)。这样内核就可以把分散的写集中起来,统一优化磁盘写入,多次小的写合并成单次大的写。
Cached是从磁盘读取文件的页缓存,也就是用来缓存从文件读取的数据。这样下次访问的时候直接从内存读取。
SReclaimable是Slab的一部分。Slab包括两部分,可回收用:SReclaimable。不可回收:SUnreclaim。
注意:buffers和cache既有读又有写。不是单一的读或者写
进程缓存命中率
查看缓存命中率需要安装bcc软件包
centos7系统安装
[root@centos ~]# yum update
[root@centos ~]# rpm --import
https://www.elrepo.org/RPM-GPG-KEY-elrepo.org && rpm -Uvh
http://www.elrepo.org/elrepo-release-7.0-2.el7.elrepo.noarch.rpm
[root@centos ~]# uname -r ##
3.10.0-862.el7.x86_64
[root@centos ~]# yum remove kernel-headers kernel-tools kernel-tools-libs
[root@centos ~]# yum --disablerepo="" --enablerepo="elrepo-kernel" install
kernel-ml kernel-ml-devel kernel-ml-headers kernel-ml-tools
kernel-ml-tools-libs kernel-ml-tools-libs-devel
[root@centos ~]# sed -i '/GRUB_DEFAULT/s/=./=0/' /etc/default/grub
[root@centos ~]# grub2-mkconfig -o /boot/grub2/grub.cfg
[root@centos ~]# reboot
[root@centos ~]# uname -r ## 升级成功
4.20.0-1.el7.elrepo.x86_64
[root@centos ~]# yum install -y bcc-tools
[root@centos ~]# echo 'export PATH=$PATH:/usr/share/bcc/tools' > /etc/profile.d/bcc-tools.sh
[root@centos ~]# . /etc/profile.d/bcc-tools.sh
[root@centos ~]# cachestat 1 1 ## 测试安装是否成功Ubuntu系统安装步骤
sudo apt-key adv --keyserver keyserver.ubuntu.com --recv-keys 4052245BD4284CDD echo "deb https://repo.iovisor.org/apt/xenial xenial main" | sudo tee /etc/apt/sources.list.d/iovisor.list sudo apt-get update sudo apt-get install -y bcc-tools libbcc-examples linux-headers-$(uname -r) #bcc安装到/usr/share/bcc/tools这个目录中。需要配置系统的path路径 export PATH=$PATH:/usr/share/bcc/tools注意:bcc软件包,必须是内核4.1以上。
cachestat/cachetop进程的缓存命中
root@VM-16-7-ubuntu:~# cachestat 1 3
HITS MISSES DIRTIES HITRATIO BUFFERS_MB CACHED_MB
3414 0 5 100.00% 32 563
59 0 4 100.00% 32 563
62 0 4 100.00% 32 563
root@VM-16-7-ubuntu:~# cachetop
12:50:16 Buffers MB: 80 / Cached MB: 572 / Sort: HITS / Order: ascending
PID UID CMD HITS MISSES DIRTIES READ_HIT% WRITE_HIT%
3267 root YDService 2 0 0 100.0% 0.0%
1843 root barad_agent 3 0 1 66.7% 0.0%
20042 root barad_agent 8 0 3 62.5% 0.0%
323 root jbd2/vda1-8 8 8 6 12.5% 12.5%
20041 root barad_agent 9 2 4 45.5% 9.1%
20034 root cachetop 30 0 0 100.0% 0.0%
20044 root sh 158 0 0 100.0% 0.0%
20045 root sh 158 0 0 100.0% 0.0%
20046 root sh 158 0 0 100.0% 0.0%
20043 root sh 392 0 0 100.0% 0.0%
20044 root cat 491 0 0 100.0% 0.0%
20043 root barad_agent 496 0 0 100.0% 0.0%
20045 root grep 638 0 0 100.0% 0.0%
20046 root awk 915 0 0 100.0% 0.0%
#指标
TOTAL:总的IO次数;
MISSES:缓存未命中的次数;
HITS:缓存命中次数;
DIRTIES:新增到缓存中的脏页数;
CACHED_MB:buffer的大小,MB为单位;
BUFFERS_MB:cache的大小,MB为单位;
pcstat文件缓存查看
#pcstat 安装:
if [ $(uname -m) == "x86_64" ] ; then
curl -L -o pcstat https://github.com/tobert/pcstat/raw/2014-05-02-01/pcstat.x86_64
else
curl -L -o pcstat https://github.com/tobert/pcstat/raw/2014-05-02-01/pcstat.x86_32
fi
chmod 755 pcstat
./pcstat #即可使用
####
root@VM-16-7-ubuntu:~# ls
pcstat
root@VM-16-7-ubuntu:~# ./pcstat pcstat
|----------+----------------+------------+-----------+---------|
| Name | Size | Pages | Cached | Percent |
|----------+----------------+------------+-----------+---------|
| pcstat | 3049296 | 745 | 745 | 100.000 |
|----------+----------------+------------+-----------+---------|
##指标
三、内存泄漏
当进程通过malloc()申请虚拟内存后,系统并不会立即为其分配物理内存,而是在首次访问时,才通过缺页异常陷入内核中分配内存。为了协调快速cpu和慢速磁盘的性能差异,linux还会使用cache和buffer,分别把文件和磁盘读写的数据缓存到内存中。所以,对于程序来说,动态分配内存和回收,就是事故的地点。
没有正确回收分配后的内存,导致了泄漏。
访问的是已分配内存边界外的地址,导致程序异常退出等等
内存的分配和回收
进程的内存空间
1、只读段:包括代码和常量。不会再去分配新的内存,所以不会产生内存泄漏
2、数据段:包括全局变量。变量在定义的时候就确定了大小,所以不会产生内存泄漏
3、堆:包括动态分配内存,从低地址开始向上增长。应用程分配管理,没有正确释放堆内存,内存泄漏
4、文件映射段:包括动态库、共享内存等,从高地址开始向下增长。共享内存也是程序管理,内存泄漏
5、栈:包括局部变量和函数调用的上下文等。栈的大小都是固定的,一般都是8MB。系统管理,不会泄漏
四、内存泄漏案例
环境
2cpu 8GB内存
预先安装sysstat docker bcc
#安装docker、sysstat
sudo apt-get install -y sysstat docker.io
#安装bcc
sudo apt-key adv --keyserver keyserver.ubuntu.com --recv-keys 4052245BD4284CDD
echo "deb https://repo.iovisor.org/apt/bionic bionic main" | sudo tee /etc/apt/sources.list.d/iovisor.list
sudo apt-get update
sudo apt-get install -y bcc-tools libbcc-examples linux-headers-$(uname -r)
#拉取镜像
docker run --name=app -itd feisk /app:mem-leak #k后面加y
#检查
root@test:~# docker logs app
2th => 1
3th => 2
4th => 3
5th => 5
6th => 8
7th => 13
8th => 21
9th => 34
10th => 55排查
vmstat
root@test:~# vmstat 3
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
0 0 0 143036 108584 558084 0 0 20 63 146 313 1 0 99 0 0
0 0 0 142904 108584 558068 0 0 0 0 173 400 0 0 100 0 0
0 0 0 142440 108588 558072 0 0 0 271 159 333 1 1 96 2 0
0 0 0 142472 108588 558072 0 0 0 17 128 313 1 0 99 0 0
1 0 0 142472 108588 558072 0 0 0 5 115 283 0 0 100 0 0
....
....
0 0 0 142412 108596 558076 0 0 0 29 297 708 1 1 98 0 0
0 0 0 141480 108628 558152 0 0 0 12 170 404 0 0 99 0 0
0 0 0 141512 108628 558152 0 0 0 4 172 390 0 0 100 0 0
0 0 0 141512 108628 558152 0 0 0 16 176 399 1 1 98 0 0
#观察一段时间,发现free不断减少,buffer和cache基本不变。说明系统内存一直在使用,但是,无法说明内存泄漏memleak
bcc软件包中的
root@test:~# /usr/share/bcc/tools/memleak -a -p 17050
Attaching to pid 17050, Ctrl+C to quit.
cannot attach uprobe, Device or resource busy
[19:26:43] Top 10 stacks with outstanding allocations:
addr = 7f389c2fc700 size = 8192
addr = 7f389c2f86e0 size = 8192
addr = 7f389c300720 size = 8192
addr = 7f389c2fa6f0 size = 8192
addr = 7f389c2fe710 size = 8192
40960 bytes in 5 allocations from stack
fibonacci+0x1f [app]
child+0x4f [app]
start_thread+0xdb [libpthread-2.27.so]
[19:26:48] Top 10 stacks with outstanding allocations:
# -a 表示显示每个内存分配请求的大小以及地址
# -p 指定案例应用的 PID 号
# /usr/share/bcc/tools/
# -a 表示显示每个内存分配请求的大小以及地址
# -p 指定案例应用的 PID 号
#app进程一直在分配内存,并且fibonacci()函数分配的内存没有释放。
=====
#检查代码
root@test:~# docker exec app cat /app.c
#include
#include
#include
#include
long long *fibonacci(long long *n0, long long *n1)
{
long long *v = (long long *) calloc(1024, sizeof(long long));
*v = *n0 + *n1;
return v;
}
void *child(void *arg)
{
long long n0 = 0;
long long n1 = 1;
long long *v = NULL;
for (int n = 2; n > 0; n++) {
v = fibonacci(&n0, &n1);
n0 = n1;
n1 = *v;
printf("%dth => %lld\n", n, *v);
sleep(1);
}
}
int main(void)
{
pthread_t tid;
pthread_create(&tid, NULL, child, NULL);
pthread_join(tid, NULL);
printf("main thread exit\n");
return 0;
}root@test:~#
#发现child()调用了fibonacci函数,但是并没有释放fibonacci返回的内存。在child函数加free(v);释放内存 为什么会出现虚拟内存?
在很久以前,还没有虚拟内存概念的时候,程序寻址用的都是物理地址。程序能寻址的范围是有限的,这取决于CPU的地址线条数。比如在32位平台下,寻址的范围是2^32也就是4G。并且这是固定的,如果没有虚拟内存,且每次开启一个进程都给4G的物理内存,就可能会出现很多问题:
1 因为我的物理内存时有限的,当有多个进程要执行的时候,都要给4G内存,很显然你内存小一点,这很快就分配完了,于是没有得到分配资源的进程就只能等待。当一个进程执行完了以后,再将等待的进程装入内存。这种频繁的装入内存的操作是很没效率的
2由于指令都是直接访问物理内存的,那么我这个进程就可以修改其他进程的数据,甚至会修改内核地址空间的数据,这是我们不想看到的
3 因为内存时随机分配的,所以程序运行的地址也是不正确的。
于是针对上面会出现的各种问题,虚拟内存就出来了。
虚拟内存是怎么工作的
1 寻址逻辑
当每个进程创建的时候,内核会为进程分配4G的虚拟内存,当进程还没有开始运行时,这只是一个内存布局。实际上并不立即就把虚拟内存对应位置的程序数据和代码(比如.text .data段)拷贝到物理内存中,只是建立好虚拟内存和磁盘文件之间的映射就好(叫做存储器映射)。这个时候数据和代码还是在磁盘上的。当运行到对应的程序时,进程去寻找页表,发现页表中地址没有存放在物理内存上,而是在磁盘上,于是发生缺页异常,于是将磁盘上的数据拷贝到物理内存中。
另外在进程运行过程中,要通过malloc来动态分配内存时,也只是分配了虚拟内存,即为这块虚拟内存对应的页表项做相应设置,当进程真正访问到此数据时,才引发缺页异常。
可以认为虚拟空间都被映射到了磁盘空间中(事实上也是按需要映射到磁盘空间上,通过mmap,mmap是用来建立虚拟空间和磁盘空间的映射关系的)
2 虚拟内存和物理内存的比较
1实际使用情况,2内存连续性,3寻址
1每个进程都认为自己拥有4G的空间,这只是每个进程认为的,但是实际上,在虚拟内存对应的物理内存上,可能只对应的一点点的物理内存,实际用了多少内存,就会对应多少物理内存。
2进程得到的这4G虚拟内存是一个连续的地址空间(这也只是进程认为),而实际上,它通常是被分隔成多个物理内存碎片,还有一部分存储在外部磁盘存储器上,在需要时进行数据交换。
3每次我要访问地址空间上的某一个地址,都需要把地址翻译为实际物理内存地址,所有进程共享这整一块物理内存
3 页表
每个进程只把自己目前需要的虚拟地址空间映射到物理内存上,进程需要知道哪些地址空间上的数据在物理内存上,哪些不在(可能这部分存储在磁盘上),还有在物理内存上的哪里,这就需要通过页表来记录,页表的每一个表项分两部分,第一部分记录此页是否在物理内存上,第二部分记录物理内存页的地址(如果在的话)当进程访问某个虚拟地址的时候,就会先去看页表,如果发现对应的数据不在物理内存上,就会发生缺页异常,缺页异常的处理过程,操作系统立即阻塞该进程,并将硬盘里对应的页换入内存,然后使该进程就绪,如果内存已经满了,没有空地方了,那就找一个页覆盖,至于具体覆盖的哪个页,就需要看操作系统的页面置换算法是怎么设计的了。
关于虚拟内存与物理内存的关系图

页表的工作原理如下图

1我们的cpu想访问虚拟地址所在的虚拟页(VP3),根据页表,找出页表中第三条的值.判断有效位。 如果有效位为1,DRMA缓存命中,根据物理页号,找到物理页当中的内容,返回。
2若有效位为0,参数缺页异常,调用内核缺页异常处理程序。内核通过页面置换算法选择一个页面作为被覆盖的页面,将该页的内容刷新到磁盘空间当中。然后把VP3映射的磁盘文件缓存到该物理页上面。然后页表中第三条,有效位变成1,第二部分存储上了可以对应物理内存页的地址的内容。
3缺页异常处理完毕后,返回中断前的指令,重新执行,此时缓存命中,执行1。
4 将找到的内容映射到告诉缓存当中,CPU从告诉缓存中获取该值,结束。
利用虚拟内存机制的优点
1 通过内存地址转换解决了多个进程访问内存冲突的问题
2 内存共享 ; 当不同的进程使用同一段代码时,比如库文件的代码,在物理内存中可以只存储一份这样的代码,不同进程只要将自己的虚拟内存映射过去就好了,这样可以节省物理内存
3 进程内存管理
它有助于进程进行内存管理,主要体现在:
- 内存完整性:由于虚拟内存对进程的”欺骗”,每个进程都认为自己获取的内存是一块连续的地址。我们在编写应用程序时,就不用考虑大块地址的分配,总是认为系统有足够的大块内存即可。
- 安全:由于进程访问内存时,都要通过页表来寻址,操作系统在页表的各个项目上添加各种访问权限标识位,就可以实现内存的权限控制。
在程序需要分配连续空间的时候,只需要在虚拟内存分配连续空间,而不需要物理内存时连续的,实际上,往往物理内存都是断断续续的内存碎片。这样就可以有效地利用我们的物理内存
4 虚拟内存可以帮进程”扩充”内存
我们前文提到了虚拟内存通过缺页中断为进程分配物理内存,内存总是有限的,如果所有的物理内存都被占用了怎么办呢?
Linux 提出 SWAP 的概念,Linux 中可以使用 SWAP 分区,在分配物理内存,但可用内存不足时,将暂时不用的内存数据先放到磁盘上,让有需要的进程先使用,等进程再需要使用这些数据时,再将这些数据加载到内存中,通过这种”交换”技术,Linux 可以让进程使用更多的内存。
Linux 中的“大内存页”是个什么玩意?
“大内存页”有助于 Linux 系统进行虚拟内存管理。顾名思义,除了标准的 4KB 大小的页面外,它们还能帮助管理内存中的巨大的页面。使用“大内存页”,你最大可以定义 1GB 的页面大小。
在系统启动期间,你能用“大内存页”为应用程序预留一部分内存。这部分内存,即被“大内存页”占用的这些存储器永远不会被交换出内存。它会一直保留其中,除非你修改了配置。这会极大地提高像 Oracle 数据库这样的需要海量内存的应用程序的性能。
为什么使用huge page ?
在虚拟内存管理中,内核维护一个将虚拟内存地址映射到物理地址的表,对于每个页面操作,内核都需要加载相关的映射。如果你的内存页很小,那么你需要加载的页就会很多,导致内核会加载更多的映射表。而这会降低性能。
使用“大内存页”,意味着所需要的页变少了。从而大大减少由内核加载的映射表的数量。这提高了内核级别的性能最终有利于应用程序的性能。
简而言之,通过启用“大内存页”,系统只需要处理较少的页面映射表,从而减少访问/维护它们的开销!
如何配置“大内存页”?
运行下面命令来查看当前“大内存页”的详细内容。
root@kerneltalks # grep Huge /proc/meminfo
AnonHugePages: 0 kB
HugePages_Total: 0
HugePages_Free: 0
HugePages_Rsvd: 0
HugePages_Surp: 0
Hugepagesize: 2048 kB从上面输出可以看到,每个页的大小为 2MB(Hugepagesize),并且系统中目前有 0 个“大内存页”(HugePages_Total)。这里“大内存页”的大小可以从 2MB 增加到 1GB。
运行下面的脚本可以知道系统当前需要多少个巨大页。该脚本取之于 Oracle。
!/bin/bash
#
# hugepages_settings.sh
#
# Linux bash script to compute values for the
# recommended HugePages/HugeTLB configuration
#
# Note: This script does calculation for all shared memory
# segments available when the script is run, no matter it
# is an Oracle RDBMS shared memory segment or not.
# Check for the kernel version
KERN=`uname -r | awk -F. '{ printf("%d.%d\n",$1,$2); }'`
# Find out the HugePage size
HPG_SZ=`grep Hugepagesize /proc/meminfo | awk {'print $2'}`
# Start from 1 pages to be on the safe side and guarantee 1 free HugePage
NUM_PG=1
# Cumulative number of pages required to handle the running shared memory segments
for SEG_BYTES in `ipcs -m | awk {'print $5'} | grep "[0-9][0-9]*"`
do
MIN_PG=`echo "$SEG_BYTES/($HPG_SZ*1024)" | bc -q`
if [ $MIN_PG -gt 0 ]; then
NUM_PG=`echo "$NUM_PG+$MIN_PG+1" | bc -q`
fi
done
# Finish with results
case $KERN in
'2.4') HUGETLB_POOL=`echo "$NUM_PG*$HPG_SZ/1024" | bc -q`;
echo "Recommended setting: vm.hugetlb_pool = $HUGETLB_POOL" ;;
'2.6' | '3.8' | '3.10' | '4.1' ) echo "Recommended setting: vm.nr_hugepages = $NUM_PG" ;;
*) echo "Unrecognized kernel version $KERN. Exiting." ;;
esac
# End
将它以 hugepages_settings.sh 为名保存到 /tmp 中,然后运行之:
root@kerneltalks # sh /tmp/hugepages_settings.sh
Recommended setting: vm.nr_hugepages = 124你的输出类似如上结果,只是数字会有一些出入。
这意味着,你系统需要 124 个每个 2MB 的“大内存页”!若你设置页面大小为 4MB,则结果就变成了 62。你明白了吧?
配置内核中的“大内存页”
本文最后一部分内容是配置上面提到的 内核参数 ,然后重新加载。将下面内容添加到 /etc/sysctl.conf 中,然后输入 sysctl -p 命令重新加载配置。
vm.nr_hugepages=126
注意我们这里多加了两个额外的页,因为我们希望在实际需要的页面数量之外多一些额外的空闲页。
现在,内核已经配置好了,但是要让应用能够使用这些“大内存页”还需要提高内存的使用阀值。新的内存阀值应该为 126 个页 x 每个页 2 MB = 252 MB,也就是 258048 KB。
你需要编辑 /etc/security/limits.conf 中的如下配置:
soft memlock 258048hard memlock 258048
某些情况下,这些设置是在指定应用的文件中配置的,比如 Oracle DB 就是在 /etc/security/limits.d/99-grid-oracle-limits.conf 中配置的。
这就完成了!你可能还需要重启应用来让应用来使用这些新的巨大页。
(LCTT 译注:此外原文有误,“透明大内存页”和“大内存页”不同,而且,在 Redhat 系统中,“大内存页” 不是默认启用的,而“透明大内存页”是启用的。因此这个段落删除了。)
swap 交换分区
linux下一般分一个/分区,一个/home分区,一个交换分区。
在Linux下,SWAP的作用类似Windows系统下的“虚拟内存”。当物理内存不足时,拿出部分硬盘空间当SWAP分区(虚拟成内存)使用,从而解决内存容量不足的情况。
SWAP意思是交换,顾名思义,当某进程向OS请求内存发现不足时,OS会把内存中暂时不用的数据交换出去,放在SWAP分区中,这个过程称为SWAP OUT。当某进程又需要这些数据且OS发现还有空闲物理内存时,又会把SWAP分区中的数据交换回物理内存中,这个过程称为SWAP IN。
当然,swap大小是有上限的,一旦swap使用完,操作系统会触发OOM-Killer机制,把消耗内存最多的进程kill掉以释放内存。
数据库系统为什么嫌弃swap?
显然,swap机制的初衷是为了缓解物理内存用尽而选择直接粗暴OOM进程的尴尬。但坦白讲,几乎所有数据库对swap都不怎么待见,无论MySQL、Oracal、MongoDB抑或HBase,为什么?这主要和下面两个方面有关:
-
数据库系统一般都对响应延迟比较敏感,如果使用swap代替内存,数据库服务性能必然不可接受。对于响应延迟极其敏感的系统来讲,延迟太大和服务不可用没有任何区别,比服务不可用更严重的是,swap场景下进程就是不死,这就意味着系统一直不可用……再想想如果不使用swap直接oom,是不是一种更好的选择,这样很多高可用系统直接会主从切换掉,用户基本无感知。
-
另外对于诸如HBase这类分布式系统来说,其实并不担心某个节点宕掉,而恰恰担心某个节点夯住。一个节点宕掉,最多就是小部分请求短暂不可用,重试即可恢复。但是一个节点夯住会将所有分布式请求都夯住,服务器端线程资源被占用不放,导致整个集群请求阻塞,甚至集群被拖垮。
从这两个角度考虑,所有数据库都不喜欢swap还是很有道理的!
swap的工作机制
既然数据库们对swap不待见,那是不是就要使用swapoff命令关闭磁盘缓存特性呢?非也,大家可以想想,关闭磁盘缓存意味着什么?实际生产环境没有一个系统会如此激进,要知道这个世界永远不是非0即1的,大家都会或多或少选择走在中间,不过有些偏向0,有些偏向1而已。很显然,在swap这个问题上,数据库必然选择偏向尽量少用。HBase官方文档的几点要求实际上就是落实这个方针:尽可能降低swap影响。知己知彼才能百战不殆,要降低swap影响就必须弄清楚Linux内存回收是怎么工作的,这样才能不遗漏任何可能的疑点。
先来看看swap是如何触发的?
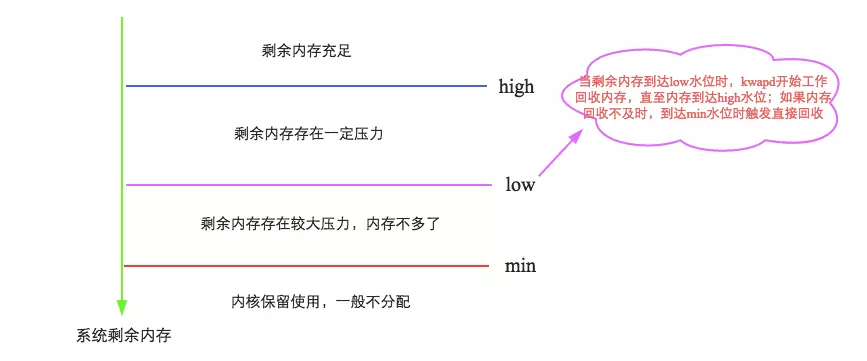
简单来说,Linux会在两种场景下触发内存回收,一种是在内存分配时发现没有足够空闲内存时会立刻触发内存回收;一种是开启了一个守护进程(swapd进程)周期性对系统内存进行检查,在可用内存降低到特定阈值之后主动触发内存回收。第一种场景没什么可说,来重点聊聊第二种场景,如下图所示:
a2
这里就要引出我们关注的第一个参数:vm.min_free_kbytes,代表系统所保留空闲内存的最低限watermark[min],并且影响watermark[low]和watermark[high]。简单可以认为:
watermark[min] = min_free_kbytes
watermark[low] = watermark[min] * 5 / 4 = min_free_kbytes * 5 / 4
watermark[high] = watermark[min] * 3 / 2 = min_free_kbytes * 3 / 2
watermark[high] - watermark[low] = watermark[low] - watermark[min] = min_free_kbytes / 4
可见,LInux的这几个水位线与参数min_free_kbytes密不可分。min_free_kbytes对于系统的重要性不言而喻,既不能太大,也不能太小。
min_free_kbytes如果太小,[min,low]之间水位的buffer就会很小,在kswapd回收的过程中一旦上层申请内存的速度太快(典型应用:数据库),就会导致空闲内存极易降至watermark[min]以下,此时内核就会进行direct reclaim(直接回收),直接在应用程序的进程上下文中进行回收,再用回收上来的空闲页满足内存申请,因此实际会阻塞应用程序,带来一定的响应延迟。当然,min_free_kbytes也不宜太大,太大一方面会导致应用程序进程内存减少,浪费系统内存资源,另一方面还会导致kswapd进程花费大量时间进行内存回收。再看看这个过程,是不是和Java垃圾回收机制中CMS算法中老生代回收触发机制神似,想想参数-XX:CMSInitiatingOccupancyFraction,是不是?官方文档中要求min_free_kbytes不能小于1G(在大内存系统中设置8G),就是不要轻易触发直接回收。
至此,基本解释了Linux的内存回收触发机制以及我们关注的第一个参数vm.min_free_kbytes。接下来简单看看Linux内存回收都回收些什么。Linux内存回收对象主要分为两种:
-
文件缓存,这个容易理解,为了避免文件数据每次都要从硬盘读取,系统会将热点数据存储在内存中,提高性能。如果仅仅将文件读出来,内存回收只需要释放这部分内存即可,下次再次读取该文件数据直接从硬盘中读取即可(类似HBase文件缓存)。那如果不仅将文件读出来,而且对这些缓存的文件数据进行了修改(脏数据),回收内存就需要将这部分数据文件写会硬盘再释放(类似MySQL文件缓存)。
-
匿名内存,这部分内存没有实际载体,不像文件缓存有硬盘文件这样一个载体,比如典型的堆、栈数据等。这部分内存在回收的时候不能直接释放或者写回类似文件的媒介中,这才搞出来swap这个机制,将这类内存换出到硬盘中,需要的时候再加载出来。
具体Linux使用什么算法来确认哪些文件缓存或者匿名内存需要被回收掉,这里并不关心,有兴趣可以参考这里。但是有个问题需要我们思考:既然有两类内存可以被回收,那么在这两类内存都可以被回收的情况下,Linux到底是如何决定到底是回收哪类内存呢?还是两者都会被回收?这里就牵出来了我们第二个关心的参数:swappiness,这个值用来定义内核使用swap的积极程度,值越高,内核就会积极地使用swap,值越低,就会降低对swap的使用积极性。该值取值范围在0~100,默认是60。这个swappiness到底是怎么实现的呢?具体原理很复杂,简单来讲,swappiness通过控制内存回收时,回收的匿名页更多一些还是回收的文件缓存更多一些来达到这个效果。swappiness等于100,表示匿名内存和文件缓存将用同样的优先级进行回收,默认60表示文件缓存会优先被回收掉,至于为什么文件缓存要被优先回收掉,大家不妨想想(回收文件缓存通常情况下不会引起IO操作,对系统性能影响较小)。对于数据库来讲,swap是尽量需要避免的,所以需要将其设置为0。此处需要注意,设置为0并不代表不执行swap哦!
至此,我们从Linux内存回收触发机制、Linux内存回收对象一直聊到swap,将参数min_free_kbytes以及swappiness进行了解释。接下来看看另一个与swap有关系的参数:zone_reclaim_mode,文档说了设置这个参数为0可以关闭NUMA的zone reclaim,这又是怎么回事?提起NUMA,数据库们又都不高兴了,很多DBA都曾经被坑惨过。那这里简单说明三个小问题:NUMA是什么?NUMA和swap有什么关系?zone_reclaim_mode的具体意义?
NUMA(Non-Uniform Memory Access)是相对UMA来说的,两者都是CPU的设计架构,早期CPU设计为UMA结构,如下图(图片来自网络)所示:

a3
为了缓解多核CPU读取同一块内存所遇到的通道瓶颈问题,芯片工程师又设计了NUMA结构,如下图(图片来自网络)所示:
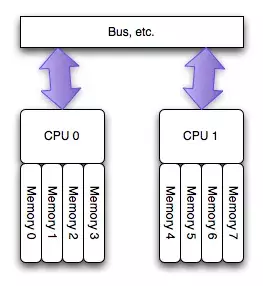
a4
这种架构可以很好解决UMA的问题,即不同CPU有专属内存区,为了实现CPU之间的”内存隔离”,还需要软件层面两点支持:
-
内存分配需要在请求线程当前所处CPU的专属内存区域进行分配。如果分配到其他CPU专属内存区,势必隔离性会受到一定影响,并且跨越总线的内存访问性能必然会有一定程度降低。
-
另外,一旦local内存(专属内存)不够用,优先淘汰local内存中的内存页,而不是去查看远程内存区是否会有空闲内存借用。
这样实现,隔离性确实好了,但问题也来了:NUMA这种特性可能会导致CPU内存使用不均衡,部分CPU专属内存不够使用,频繁需要回收,进而可能发生大量swap,系统响应延迟会严重抖动。而与此同时其他部分CPU专属内存可能都很空闲。这就会产生一种怪现象:使用free命令查看当前系统还有部分空闲物理内存,系统却不断发生swap,导致某些应用性能急剧下降。见叶金荣老师的MySQL案例分析:《找到MySQL服务器发生SWAP罪魁祸首》。
所以,对于小内存应用来讲,NUMA所带来的这种问题并不突出,相反,local内存所带来的性能提升相当可观。但是对于数据库这类内存大户来说,NUMA默认策略所带来的稳定性隐患是不可接受的。因此数据库们都强烈要求对NUMA的默认策略进行改进,有两个方面可以进行改进:
-
将内存分配策略由默认的亲和模式改为interleave模式,即会将内存page打散分配到不同的CPU zone中。通过这种方式解决内存可能分布不均的问题,一定程度上缓解上述案例中的诡异问题。对于MongoDB来说,在启动的时候就会提示使用interleave内存分配策略.
-
改进内存回收策略:此处终于请出今天的第三个主角参数zone_reclaim_mode,这个参数定义了NUMA架构下不同的内存回收策略,可以取值0/1/3/4,其中0表示在local内存不够用的情况下可以去其他的内存区域分配内存;1表示在local内存不够用的情况下本地先回收再分配;3表示本地回收尽可能先回收文件缓存对象;4表示本地回收优先使用swap回收匿名内存。可见,HBase推荐配置zone_reclaim_mode=0一定程度上降低了swap发生的概率。
cxczx