descheduler源码走读笔记
descheduler整体介绍
descheduler是k8s Incubator下面的一个项目,旨在补充默认的kube-scheduler调度能力。在k8s中,pod启动之后会经过调度器调度到某个节点上,之后不会再被调度。但是,随着集群的节点和pod不断增加,就会出现下面的情况需要把pod调度到其他节点上面去运行。
- 某些节点资源使用过高
- 因为后面添加了节点affinity,taints和labels等,使得原来调度的pod与node不匹配
- 新的节点被加入到集群当中,需要在其他节点转移pod到新的 node上
deshceduler的主要功能是寻找出一些可以被调度的pod,然后把它们从原来的节点进行evicts,依赖于默认的调度器将重新生成的pod调度到其他节点上,从而起到调整集群pod分布的目的。descheduler主要包含四个策略:
- RemoveDuplicates:一个node上有由deployment,rc,rs,job管理着的pod时,evict到剩下一个pod。
- LowNodeUtilization: 集群中有资源利用不充分的node时,从资源利用率高的node中驱逐一些pod,期待默认scheduler将其调度。
- RemovePodsViolatingInterPodAntiAffinity:同一个node中若有反亲和性的pods,如果antiaffinity是在pod已经在运行中添加的,会出现这种情况。这时候可以驱逐不符合affinity的pod。
- RemovePodsViolatingNodeAffinity:pod不能满足node的affinity而集群中有其他node能够满足pod的affinity,需要驱逐pod。
desheculer的主要工作原理是使用封装好的k8s客户端client-go与k8s集群进行通信,获取集群中node和pod的情况,然后依次执行四个驱逐策略想集群发送驱逐pod的请求进行evict。下面从阅读descheduler源代码区分析descheduler的具体逻辑。
descheduler源码阅读笔记
descheduler的代码开源在github,可以下载到本地进行阅读。descheduler代码量不大,逻辑清晰,下面先展示一下descheduler项目的代码结构。

入口代码
代码主要集中在两个文件夹下面,分别是cmd和pkg,其中cmd下面是入口代码,主要是使用了一个cobra命令行程序软件包,负责读入启动程序时的参数。在/descheduler/cmd/descheduler/app/server.go里面的Run函数会跳转到pkg包下面的descheduler主函数。
// line: 59
func Run(rs *options.DeschedulerServer) error {
return descheduler.Run(rs)
}
主函数如下:
func main() {
out := os.Stdout
cmd := app.NewDeschedulerCommand(out)
cmd.AddCommand(app.NewVersionCommand())
flag.CommandLine.Parse([]string{})
if err := cmd.Execute(); err != nil {
fmt.Println(err)
os.Exit(1)
}
}
cmd.Execute()正式执行descheduler逻辑。
接下来主要分析一下pkg里面的descheduler逻辑。
deschduler主逻辑
主要的执行逻辑都在/pkg/descheduler/descheduler.go里面
// /pkg/descheduler/descheduler.go
func Run(rs *options.DeschedulerServer) error {
// 获取k8s的客户端
rsclient, err := client.CreateClient(rs.KubeconfigFile)
rs.Client = rsclient
// 从配置文件中载入配置
deschedulerPolicy, err := LoadPolicyConfig(rs.PolicyConfigFile)
// 读取k8s集群支持的evict版本
evictionPolicyGroupVersion, err := eutils.SupportEviction(rs.Client)
// 用于停止协程的通道
stopChannel := make(chan struct{})
// 获取准备好可以进行驱逐的nodes
nodes, err := nodeutil.ReadyNodes(rs.Client, rs.NodeSelector, stopChannel)
// 初始化数据
nodePodCount := strategies.InitializeNodePodCount(nodes)
// 按顺序执行四个驱逐策略
strategies.RemoveDuplicatePods(rs, deschedulerPolicy.Strategies["RemoveDuplicates"], evictionPolicyGroupVersion, nodes, nodePodCount)
strategies.LowNodeUtilization(rs, deschedulerPolicy.Strategies["LowNodeUtilization"], evictionPolicyGroupVersion, nodes, nodePodCount)
strategies.RemovePodsViolatingInterPodAntiAffinity(rs, deschedulerPolicy.Strategies["RemovePodsViolatingInterPodAntiAffinity"], evictionPolicyGroupVersion, nodes, nodePodCount)
strategies.RemovePodsViolatingNodeAffinity(rs, deschedulerPolicy.Strategies["RemovePodsViolatingNodeAffinity"], evictionPolicyGroupVersion, nodes, nodePodCount)
return nil
}
以上代码经过精简,去掉了错误处理,增加了注释。可以看到,整个流程十分清晰,首先是获取客户端,然后是一些初始化,选出nodes,对nodes进行四个策略的驱逐。
下面首先看生成客户端的程序:
// /pkg/descheduler/client/client.go
func CreateClient(kubeconfig string) (clientset.Interface, error) {
var cfg *rest.Config
if len(kubeconfig) != 0 {
// 读取kubeconfig配置
master, err := GetMasterFromKubeconfig(kubeconfig)
cfg, err = clientcmd.BuildConfigFromFlags(master, kubeconfig)
} else {
var err error
// 没有kubeconfig配置说明在集群内,直接使用client-go的InClusterConfig()
cfg, err = rest.InClusterConfig()
}
return clientset.NewForConfig(cfg)
}
这段代码是client-go的基本用法,获得一个可以与k8s通信的客户端,client-go实则是一个封装了k8s的RESTful API的接口,使得开发者跟k8s通信更容易。
接下来是载入配置和获取k8s集群支持的evict版本。
// /pkg/descheduler/policyconfig.go
func LoadPolicyConfig(policyConfigFile string) (*api.DeschedulerPolicy, error) {
// 从配置文件中读入数据
policy, err := ioutil.ReadFile(policyConfigFile)
versionedPolicy := &v1alpha1.DeschedulerPolicy{}
// 解码到policy的对象中
decoder := scheme.Codecs.UniversalDecoder(v1alpha1.SchemeGroupVersion)
runtime.DecodeInto(decoder, policy, versionedPolicy)
internalPolicy := &api.DeschedulerPolicy{}
scheme.Scheme.Convert(versionedPolicy, internalPolicy, nil)
return internalPolicy, nil
}
这里是从配置文件中读取配置,需要注意的一点事使用了api和apis文件夹里面生成的代码。
在分析strategies的代码之前,先来看一个evict,node,pod三个文件夹下面提供的工具函数。
正如文件的名字一样,这三个文件分别提供关于驱逐,节点和pod的相关函数。比如node/node.go里面的某个函数。
// /pkg/descheduler/node/node.go
func ReadyNodes(client clientset.Interface, nodeSelector string, stopChannel <-chan struct{}) ([]*v1.Node, error) {
ns, err := labels.Parse(nodeSelector)
var nodes []*v1.Node
nl := GetNodeLister(client, stopChannel)
// 通过client读取node的数据
nItems, err := client.Core().Nodes().List(metav1.ListOptions{LabelSelector: nodeSelector})
readyNodes := make([]*v1.Node, 0, len(nodes))
// 获取ready状态的node
for _, node := range nodes {
if IsReady(node) {
readyNodes = append(readyNodes, node)
}
}
return readyNodes, nil
}
可以看到node.go里面的函数是调用客户端lientset进行node的处理。另外的pod和evict也是这样,这里不再展示具体的细节。go文件的函数名清晰地表明了函数的作用。
这里分析一个pod.go里面的函数
// /pkg/descheduler/pod/pod.go
// IsEvictable checks if a pod is evictable or not.
func IsEvictable(pod *v1.Pod, evictLocalStoragePods bool) bool {
ownerRefList := OwnerRef(pod)
if IsMirrorPod(pod) || (!evictLocalStoragePods && IsPodWithLocalStorage(pod)) || len(ownerRefList) == 0 || IsDaemonsetPod(ownerRefList) || IsCriticalPod(pod) {
return false
}
return true
}
判断一个pod是否能够被驱逐,调用pod.go的其他函数,这里主要排除了一些特殊类型的pod,比如属于daemonset,具有本地存储,没有上层资源负责管理等等。
// /pkg/descheduler/evictions/evictions.go
func EvictPod(client clientset.Interface, pod *v1.Pod, policyGroupVersion string, dryRun bool) (bool, error) {
deleteOptions := &metav1.DeleteOptions{}
// 驱逐选项
eviction := &policy.Eviction{
TypeMeta: metav1.TypeMeta{
APIVersion: policyGroupVersion,
Kind: eutils.EvictionKind,
},
ObjectMeta: metav1.ObjectMeta{
Name: pod.Name,
Namespace: pod.Namespace,
},
DeleteOptions: deleteOptions,
}
// 用客户端向k8s集群请求驱逐pod
err := client.Policy().Evictions(eviction.Namespace).Evict(eviction)
}
驱逐其实是用客户端发送驱逐请求。
strategies代码分析
strategies文件夹下面有四个策略的go文件,整体思路都是根据不同的策略选出要驱逐的pod,然后进行驱逐。下面简要分析一下其中的一个duplicates.go,其余策略都是类似的逻辑。通过clientset获得集群的状态,根据不同的策略选择pod进行驱逐。
// /pkg/descheduler/strategies/duplicates.go
// 列出node中重复的pod
func ListDuplicatePodsOnANode(client clientset.Interface, node *v1.Node, evictLocalStoragePods bool) DuplicatePodsMap {
//找出可以驱逐的pod
pods, err := podutil.ListEvictablePodsOnNode(client, node, evictLocalStoragePods)
return FindDuplicatePods(pods)
}
// 找出重复的pod
func FindDuplicatePods(pods []*v1.Pod) DuplicatePodsMap {
dpm := DuplicatePodsMap{}
for _, pod := range pods {
ownerRefList := podutil.OwnerRef(pod)
for _, ownerRef := range ownerRefList {
// Namespace/Kind/Name should be unique for the cluster.
s := strings.Join([]string{pod.ObjectMeta.Namespace, ownerRef.Kind, ownerRef.Name}, "/")
dpm[s] = append(dpm[s], pod)
}
}
return dpm
}
通过以上两个函数找到可以驱逐的pod,然后进行驱逐。其他三个文件的逻辑基本一样,值得一提的是lownodeutilization.go文件很长,包含的逻辑比较多。这里提供一个简单的流程图。
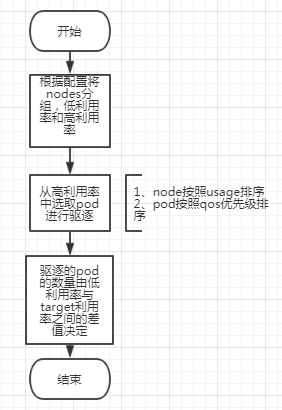
以上是源代码的简单走读
总结
- descheduler是为了解决一次调度产生的问题,k8s一次调度室根据当时的集群情况作出的最佳选择,随着集群的扩大,它只能是次有解,甚至后期还会变成不怎么好的解。而descheduler是按照一定的策略去选取一些pod进行驱逐,尽量维持集群pod的均匀分布。
- descheduler的基本思路是利用client-go与集群通信,分析node与pod的状态,选择pod驱逐,我们可以在它的基础上增加一些我们自己的策略。