ORACLE数据库
Oracle数据库
标签(空格分隔): 数据库
参考书:《SQL入门经典–第五版》《Oracle 11g 权威指南》
作者:美国人 谷长勇
出版社: 人民邮电出版社 电子工业出版社 2008年左右出版
第一部分 Oracle数据库11g基础
第1章 数据库基础知识
1.1 什么是SQL
- Structured Query Language:结构化查询语言(SQL)
1.3数据库的组成
- 一个数据库由一组数据表组成
- 表的定义:
- 是一组彼此相关的记录的组合。
- 由字段(每列)和记录(表中每行的数据)
- 存在许多表衍生出来的对象,如视图(view)、索引(index)等。
- 表的构成:
- 字段:字段是表里的一列,用于保持每条记录的特量信息。
- 记录或一行数据:也被称为一行数据, 是表里的各行。
- 列:列是表里垂直的一项,包含表里特定字段的全部信息。
- 主键:主要用于区分表里每一条数据行。
- NULL值:没有值,NULL并不等同于0或空格。
1.5关系数据库 RMDBS
1.5.1定义:
- RDBMS即关系数据库管理系统(Relational Database Management System)。
- 一些相关的表和其他数据看对象的集合。
1.5.2组成:
-
信息存放在二维表(table)中。一个关系数据库包含多个数据表。每一个表包含行(记录)和列(字段)。
-
表之间相互关联。主键(PrimaryKey)和外键(ForeignKey)所体现的参照关系实现。
-
数据库除了表,还包含:视图、存储过程、索引等。
-
相关概念:
-
关键字(Key),是关系模型中的逻辑结构,分为主键外键。
- 主键(Primary Key),唯一非空,该列的唯一标识行。实施实体完整性。
- 外键(Foreign Key),表中含有与另外一个表的主关键字相对应的列祖,可以是一行或者多行。
- 外键优点:
- 提供了表之间的连接;
- 根据主关键字的列值来检查、参照该主键字的列值以确定合法性。
- 保证列的每个值都是有效的,实施参照完整性。
1.5.3关系数据库的特点:
- 数据完整性:所有的RDBMS都使用SQL或其变体控制包含在任意数据库中的数据。需要保证多张表中的数据被更新,则所有的数据都将更新(事务一致性)。
- 数据存储和数据安全:把实际数据和业务逻辑区分开,以确保数据库中的数据可以保持持久状态。压缩算法将冗余的数据删除的方式存储数据。
1.5.4关系数据库的功能:
- SQL(Structured Query Language)是由国际标准化组织(ISO)公布的,集数据定义(DDL)、数据操纵(DML)、数据定义(DDL)、数据控制(DCL)为一体的标准数据库语言。
第2章 数据库的基本类型
2.1 基本的数据类型
- 基本的数据类型:
- 日期和时间类型
- 数字
- 字符串
- 隐式转换
- 一些数据类型可以根据其格式自动转化为其他数据类型
- 比如:select cast(‘12/27/1994’,as,Datetime) as mydate
- 不同的数据库有不同的数据类型,但是基本数据类型在不同的数据库之间还是相同的。
2.2数据类型划分
2.2.1字符串
2.2.2.1 定长字符串
- 定长字符串通常具有相同的长度,是使用定长数据类型保存的。
- SQL字符串的际准:CHARACTER(n)–n是数字,定义字段能保存的最长字符数。
- 有些SQL使用CHAR(n) 数据类型来保存定长数据。使用空格填充数量不足的字符。
- 注意:
- 不要使用定长数据类型来保存长度不定的数据,比如姓名。如果不恰当地使用定长数据类型,可能浪费空间,影响对不同的数据进行精确比较。
- 用变长的数据类型保存不定长的字符串。
2.2.2.2 变长字符串
- SQL字符串的际准:CHARACTER VARYING(n)–n是数字,定义字段能保存的最长字符数。
- 常见的变长数据类型有VARCHAR, VARINARY和VARCHAR2。
区分:VARCHAR(n)、VARCHAR2(n)和nvarchar(n)、VARYING(n)
-
VARCHAR(n)
- VARCHAR 是ANSIC标准, Microsoft SQL Server 和MySQL 也使用。
- 长度为 n 个字节的可变长度且非 Unicode 的字符数据。n 必须是一个介于 1 和 8,000 之间的数值。存储大小为输入数据的字节的实际长度,而不是 n 个字节。
-
VARCHAR2(n)
- 1.varchar2把所有字符都占两字节处理(一般情况下),varchar只对汉字和全角等字符占两字节,数字,英文字符等都是一个字节;
- 2.VARCHAR2把空串等同于null处理,而varchar仍按照空串处理;
- 3.VARCHAR2字符要用几个字节存储,要看数据库使用的字符集;
- 大部分情况下建议使用varchar2类型,可以保证更好的兼容性。
-
NVARCHAR(n)
- 包含 n 个字符的可变长度 Unicode 字符数据。n 的值必须介于 1 与 4,000 之间。字节的存储大小是所输入字符个数的两倍。
- 如字段值只是英文可选择varchar,而字段值存在较多的双字节(中文、韩文等)字符时用nvarchar。
- varchar(4) 可以输入4个字母,也可以输入两个汉字。
- nvarchar(4) 可以输四个汉字,也可以输4个字母,但最多四个,占八个字节。
-
VARBINARY
- 类似于VARCHAR和VARCHAR2.只是包含的是不定长的字节。这种数据据类型通常用来保存"数字式"数据,例如图片文件。
注意:
- 定长字符串去做据类型用空格来填充字段里的空白, 但变长字符串不这样做。举例说明,如果某个变长字段的长度定且为10, 而输入的字符长度为5,那么这个值的长度也就是5,并不使用空格来填充字段里的空白。
2.2.2.3 直义字符串
- 直义字符串就是一系列字符,比如姓名或电话号码,这是由用户或程序明确指定的。并不需要把字段指定为直义字符串数据类型,而是指定字符串。
2.2.2数字
-
2.2.2.1 大对象类型 BLOB TEXT
- BLOB:是二进制大对象,它的数据是很长的二进制字符串.数据库里存储二进制媒体文件,比如图片和MP3。
- TEXT 长字符串类型,可以被看做作一个大VARCHAR 字段,通常用于在
数据库里保存大字符集,比如博在站点的HTML输入。
-
2.2.2.2 数值类型
-
分类:
-
下面是SQL数值的标准.
-
BIT(n)
-
BIT VARYING(n)
-
Decimal(p,s)
-
INTEGER
-
SmallInt
-
BigInt
-
Float(p,s)
-
Double PRECISION(p,s)
-
Real(s)
- p 表示字段的且大长度
- s 表示小数点后面的位数
-
-
2.2.2.2 小数类型
- 标准:DECIMAL(p,s),p 表示有效位数,s表示标度。
- 在数值定义DECIMAL(4,2)里, 有效位数是4,也就是说数值总位数是4,标度是小数点后面的位数,在前例中是2。
- 如果实际数值的小数位数超出了定义的位数,数值就会被四舍五入。 比如34.33 写入到定义为DEClMAL(3,1)的字段时,会被四舍五入为34.3。
-
2.2.2.3 整数类型
- 不包含小数点的数值〈包括正数和负数)。
-
2.2.2.4 浮点数
- 浮点数是有效位数和标度都可变井且没有限制的小数数值,任有效位数和标度都是可以的。数据类型REAL代表单精度浮点数值,而DOUBLEPRECISION表示双精度浮点数值.单精度浮点数值的有效位数为1~21(包含).双精度浮点数值的有效位数为22-53(包含)
######2.2.3日期和时间类型
- 日期和时间类型显然是用于保存日期和时间信息的. 标准SQL的类型:
- DATE
- TIME
- DATETIME
- TIMESTAMP
- DATETlME 数据类型的元素包括
- YEAR
- MONTH
- DAY
- HOUR
- MINUTE
- Second
######2.2.4NULL数据类型
- NULL:表示没有值,表示相应的字段不是必须要输入数据的。NOT NULL代表必须要输入值。
- 区分:
- NULL:NULL关键字,空值本身。
- ‘NULL’:包含NULL的直义字符串
######2.2.5布尔值
- 布尔值取值范围:TRUE FALSE NULL
#####2.2.6自定义数据类型
- 是由用户定义的类型,它允许用户根据已有的数据类型来定制自己的数据类型,从而满足数据存储的需要。
- 在MySQL 和Oracle中,可以创建一个下面的类型
CREATE TYPE PERSON AS OBJECT
(NAME VARCHAR(30),
SSN VARCHAR(9));
然后可以像下面这样引用自定义类型
CREATE TABLE EMP_PAY
(EMPLOYEE PERSON ,
SALARY DECIMAL(10,2) ,
HIRE_OATE DATE);
表EMP_PAY 第一列EMPLOYEE的类型是PERSON,这正是在前面创建的自定义类型。
#####2.2.7域
- 域是能够被使用的有效数据类型的集合。域与数据相关联,从而只接受特定的数据,在域创建之后,我们可以向域添加约束。约束与数据类型共同发挥作用,从而进一步限制字段能够接受的数据。域的使用类似于自定且类型。
像下面这样就可以创建域
CREATE DOMAIN MONEY_D AS NUMBER(8 ,2);
像下面这样为域添加约束
ALTER DOMAIN MONEY_D AS NUMBER(8,2)
ADD CONSTRAINT MONEY_CON1
CHECK (VAlUE>5);
然后像下面这样引用域
CREATE TABlE EMP_PAY
(EMP_ID NUMBER(9),
EMP_NAME VACHAR2(30),
PAY_RATE MONEY_D):
第3章 管理数据库对象
3.1 数据库对象和规划
- 数据库对象:是数据库里定义的的、用于存储或引用数据的对象,比如表、视图、簇、序列、索引和异名。
- 规划:与数据库某个用户名相关联的数据库对象集合。相应的用户名被称为规划所有人,或者是关联对象组的所有人。数据库里可以有一个或多个规划。
- 用户默认访问自己规划的表,如果要访问其他规划的表需要加上规划名。
user1 访问 user2.table
3.2表:数据的主要存储方式
3.2.1 列和行
- 列:字段
- 行:内容(数据库里的一条记录)
3.2.2 建表语句
create table tabelname(
columnName dataType[length] [Not NULL],
columnName dataType [Not NULL],
columnName dataType [Not NULL]
);
3.2.3 ALTER TABLE
- 标准命令
alter table table_name [modify] [column column_name] [datatype | null
not null] [restrict|cascade]
[drop] [constraint_constraint_name]
[add] [column] column definition
- 1、修改表的属性
属性:
列的数据类型
列的长度、有效位数或者标度
列是否为空
ALTER TABLE EMPLOYEE_TBL MODIFY EMP_ID VARCHAR2(10 BYTE);
- 2、添加列
- 如果表已经有数据,新添加的列不能为NOT NULL;
- 强行添加一列的方法,如下:
- 添加一列,把他定义为NULL(这一行不一定要包含数据)
- 给新列每条记录都插入数据
- 把列修改为NOT NULL
- 删除表中的字段
格式: alter table 表名 drop column 字段名称;
需求: 删除person表格中的name字段
alter table person drop column name;
- 添加表中的字段
格式: alter table 表名 add 字段名 字段类型(长度);
需求: 向person表中 添加一个name字段 ,类型为varchar2长度为10
alter table person add name varchar2(10);
- 3、添加自动增长列
- MySQL:提供serial方法生成。
CREATE TABLE TEST_ INC FlEMENT(
ID SERIAL,
TEST_NAME VAACHAR(20));
- 4、增加注释
comment on column 表名.字段名 is 'XX';
-
Oracle:使用Sequence对象和触发器来实现类似的效果。22章会讲。可以直接插入内容,不为自动增加的列制定值。
-
4、修改表
比较复杂的情况,可以删除表重新建。
3.2.4 从一个表新建另一个表
- 注: 默认使用相同的 STORAGE 属性。新表和原表具有相同的属性。但是索引可能有不同。
语法:
create table new table name as
select [ *|column1, column2 ]
from table_name
[ where ]
实例:
--原先的表--
SELECT * FROM PRODUCTS_TBL ;
--新生成的表--
CREATE TABLE products_tbl_test AS SELECT * FROM products_tbl ;
-- 新生成的表跟原表一样的属性 但是索引可能有不同--
SELECT * FROM products_tbl_test;
3.2.5 删除表
- 如果有约束限制,直接删除会报错,需要加cascade选项。
- 语法
drop table table_name [restrict|cascade]
3.3 完整性约束
- 完整性约束用于确定关系型数据库里数据的准确性和一致性。在关系型数据库里,数据完整性是通过引用完整性的概念实现的,而在引用完整性里包含了很多类型。
3.3.1 主键约束
- 表里一个或多个用于实现记录唯一性的字段。
- 唯一非空。
- 可以是一个字段,也可以是多个字段(联合主键)。
1、隐含约束:建表过程中指定的
create table table_name(
column_name datatype(length) not null primary key,
XXX
);
2、建表语句字段后创建
create table table_name(
column_name datatype(length) not null,
XXX,
primary key(column_name1 [,column_name2])
);
3、修改表结构
ALTER TABLE PRODUCT_TST
ADD CONSTRAINT PRODUCTS_PK PRIMARY KEY (PROD_ID , VEND_ID);
3.3.2 唯一约束 UNION
- 要求表里某个字段的值在每条记最里都是唯一的
--唯一约束 UNIQUE--
CREATE TABLE EMPLOYEE_TBL_UNIQUE
(
EMP_ID VARCHAR(9) NOT NULL,
LAST_NAME VARCHAR(15) NOT NULL,
FIRST_NAME VARCHAR(15) NOT NULL,
MIDDLE_NAME VARCHAR(15),
ADDRESS VARCHAR(30) NOT NULL,
CITY VARCHAR(15) NOT NULL,
STATE CHAR(2) NOT NULL,
ZIP INTEGER NOT NULL,
PHONE CHAR(10) UNIQUE, --唯一约束--
PAGER CHAR(10),
CONSTRAINT EMP_PK_UNIQUE PRIMARY KEY (EMP_ID)
);
3.3.3 外键约束 FOREIGN KEY
- 定义: 外键是子表里的一个字段,引用父表里的主键。
- 注意:主表和子表的字段的列类型(包括长度)要一致。
- 意义:EMP_ID字段为EMPLOYEE_PAY_TBL的外键,它引用了EMPLOYEE_TBL里的EMP_ID字段。这个外键确保了EMPLOYEE_PAY_TBL里的每个EMP_ID都在表EMPLOYEE_TBL里有对应的 EMP_ID。这被称为父子关系,其中父表是EMPLOYEE_TBL,子表是EMPLOYEE_PAY_TBL。

-- 外键约束--
CREATE TABLE EMPLOYEE_PAY_TST(
EMP_ID VARCHAR(9) NOT NULL,
POSITION VARCHAR2(15) NOT NULL,
DATA_HIRE DATE NULL,
PAY_RATE NUMBER(4,2) NOT NULL,
DATE_LAST_RAISE DATE NULL,
--子表EMPLOYEE_PAY_TST
CONSTRAINT EMP_ID_PK FOREIGN KEY (EMP_ID) REFERENCES EMPLOYEE_TBL (EMP_ID)
);
或者ALTER向表里添加外键
alter table employee_pay_tbl add constraint id_fk foreign key(emp_id) references EMPLOYEE_TBL (EMP_ID);
3.3.4 NOT NULL约束
- 不允许空值
3.3.5 检查约束
- 检查(CHK)约束用于检查输入到特定字段的数据的有效性,可以提供后端的数据库编辑。
CREATE TABLE employee_check_tst
(EMP_ID CHAR(9) NOT NULL,
EMP_NAME VARCHAR2(40) NOT NULL,
EMP_ST_ADDR VARCHAR2(20) NOT NULL,
EMP_CITY VARCHAR2(15) NOT NULL,
EMP_ST CHAR(2) NOT NULL,
EMP_ZIP NUMBER(5) NOT NULL,
EMP_PHONE NUMBER(10) NULL,
EMP_PAGER NUMBER(10) NULL,
PRIMARY KEY(EMP_ID),
CONSTRAINT CHE_EMP_ZIP CHECK( (EMP_ZIP = '46234') )
);
--确保了输入到这个表里的全部雇员的 EMP_ZIP代码都是 "46234"
3.3.6 删除约束
-- 删除约束
ALTER TABLE TABLE_NAME DROP CONSTRAINT CONSTRAINT_NAME;
第4章 规格化过程(范式)
4.1规格化数据库
- 规格化/范式:把原始数据库按照一定的规则拆封成表的过程。
- 开发人员利用规格化过程来设计数据库,使其便于组织和管理、减少数据冗余,同时确保数据在整个数据库里的正确性。
4.1.1范式形式
参考链接: https://www.cnblogs.com/1906859953Lucas/p/8299959.html
- 最常见的三种范式
- 第一范式:确保每列的原子性(不可再分)。
- 如果数据库表中的所有字段值都是不可分解的原子值,就说明该数据库满足第一范式。
- 第二范式:确保表中的每列都和主键相关。
- 第二范式在第一范式的基础上更进一层,第二范式需要确保数据库表中每一列都和主键相关,而不能只与主键的某一部分相关(主要针对联合主键而言)。也就是说在一个数据库表中,一个表中只能保存一种数据,不可以把多种数据保存在同一张数据库表中。
- 第三范式:确保每列都和主键列直接相关,而不是间接相关。
- 第一范式:确保每列的原子性(不可再分)。
4.1.2范式优点
- 直好的数据库整体组织性。
- 减少冗余数据。
- 数据库内部的数据一致性。
- 更灵活的数据库设计。
- 更好地处理数据库安全。
- 加强引用整体性的概念。
4.1.3范式缺点
- 降低了数据库的性能。
- 性能降低的程度取决于查询事务或事物被提交给数据库的时机,其中涉及多个因素,比如CPU使用率、内存使用率和输入输出(I/O)。简单来说,规格化的数据库比非规格化的数据库需要更多的CPU、内存和I/O来处理事务和查询。规格化的数据库必须找到所需的表,然后把这些表的数据结合合起来,从而得到需要的信息或处理相应的数据。
4.2 去规格化数据库
- 定义:修改规格化数据库的表的构成。
- 唯一原因:在可控制的冗余范围内提高数据库性能。
- 去规格化也是有代价的.它增加了数据冗余,虽然提高了性能,但需要付出更多的精力来处理相关的数据。程序代码会更加复杂,因为数据被分散到多个表,而且可能更难于定位。另外,引用完整性更加琐碎,因为相关数据存在于多个表里。规格化与去规格化都有好处,但都需要我们时实际的数据和公司的详细业务需求布全面的了解。
第4章 SQL语句基础
4.1 SQL语言概述
4.1.2 SQL语言分类
- 主要分类
- DQL(Data Query Language):SELECT语句(数据查询语言):检索数据库数据。
- DML(Data Manipulation Language,数据操纵语言):用于改变数据库数据。INSERT UPDATE DELETE。需要提交。
- DDL(Date Definition Language数据定义语言):用于建立、修改和删除数据库对象。
- Create table用于创建表,
- Alter table语句对表结构进行修改,
- Drop table删除表结构。
- DDL表会自动提交事务。
- DCL(Data Control Language 数据控制语言):用于执行权限授予和权限收回操作。
- Grant命令用于给用户或者角色授予权限。
- Revoke命令用于收回用户角色或用户权限。
- 自动提交事务。
- DAC (Data Administration Commands)资数据管理命令
- 允许使用者对使用中的资料库产生稽核与分析,共有两种主要指令:START AUDIT、STOP AUDIT。
- TCL(Transactional Control Language 事务控制语言)。
- commit:提交,确认已经进行的数据库变更。
- rollback:回滚,取消已经进行的数据库变更。
- savepoint:用于设置保存点,以取消部分数据库改变。
- set transaction: 设置事务的名称.
4.1.3 SQL语言规则
- 不区分大小写: 关键字、对象和列名。
- 区分大小写: 字符值、日期。
- SQL*Plus中,SQL以分号结束。(命令行模式交互的客户端工具)
第5章 操作数据
5.1 概述
- DML语句(Data Manipulation Language),数据库操作语言,对关系型数据库里的数据进行修改。
- DML可以和SELECT语句组合使用
- INSERT
- UPDATE
- DELETE
5.2 插入INSERT
5.2.1 简单插入
1. 全字段添加
INSERT INTO TABLE_NAME VALUES('value1','value2',[NULL]);
格式: insert into 表名 values(数据列表);
数据列表 : 表示的是一个数据组,数据的顺序按照创建表格时的字段顺序传入,不同字段的值使用英文逗号隔开,字符串用单引号
2. 选择字段添加
INSERT INTO TABLE_NAME('COLUMN1','COLUMN2',...) VALUES('value1','value2',...);
格式: insert into 表名(字段列表) values(数据列表);
字段列表可以任意排列 , 多个字段名之间使用英文逗号隔开,数据列表的顺序, 参照字段列表
5.2.2 从另一张表插入
- 语法
insert into table_name [('column1','column2')]
select [ *|('column1','column2') ] from table_name
[ where condition[s] ];
insert into table_A select * from table_b; --必须保证A和B表结构一致
- 要满足条件:
- 1、指定的字段列表具有相同的次序
- 2、要确定SELECT语句返回的数据与要插入数据的表的字段具有兼容的数据类型。
5.2.3 插入NULL
这两条语句是一样的
--语句A
INSERT INTO ORDERS_TBL (ORD_NUM, CUST_ID, PROD_ID, QTY, ORD_DATE) VALUES ('23A16','109', '7725',2, NULL);
--语句B
INSERT INTO ORDERS_TBL (ORD_NUM, CUST_ID, PROD_ID, QTY) VALUES ('23A16','109', '7725',2);
5.3 更新UPDATE
5.3.1 更新一列的数据
- 语法
update table_name set colunm_name = 'value' [where conditions];
不加where条件会更新所有的数据。
5.3.2 更新一条或者多记录里的多个字段
- 语法
update table_name set colunm_name1 = 'value',
[colunm_name2 = 'value', colunm_name3 = 'value']
[where conditions];
不加where条件会更新所有的数据。
5.4 删除DELETE
- DELETE 命令用于从表里删除整行数据. 它不能删除某一列的数据, 而是删除行里全部字段的数据。
- DELETE要搭配WHERE语句 否则会删除所有的数据。
- 语法
delete from table_name [where conditions]
第6章 管理数据库事务
6.1 事务定义:
- 事务:是数据库管理系统执行过程中的一个逻辑单位,由一个有限的数据库操作序列构成。
- 意义:
- 一个数据库事务通常包含了一个序列的对数据库的读/写操作。它的存在包含有以下两个目的:
- 为数据库操作序列提供了一个从失败中恢复到正常状态的方法,同时提供了数据库即使在异常状态下仍能保持一致性的方法。
- 当多个应用程序在并发访问数据库时,可以在这些应用程序之间提供一个隔离方法,以防止彼此的操作互相干扰。
6.2 事务控制
- 对关系型数据库库管理系统(RDBMS)里可能发生的各种事务的管理能力。
- 事务控制搭配INSERT、UPDATE、DELETE语句。建表和删除表默认提交,不能用事务控制。
- 控制事务命令:
- commit
- rollback
- savepoint
6.2.1 commit
- 事务所做的更改保存到数据库。
- 不同的数据库对commit的命令的提交有不同。有些数据库自动提交,不需要commit。
- 语法
commit [work];
6.2.2 rollback
- ROLLBACK 命令用于撤销还投有被保存到数据库的命令,它只能用于撤销上一个
COMMIT或ROLLBACK命令之后的事务。 - ROLLBACK 命令清楚回退区域里的全部修改。
- 语法
rollback [work];
6.2.3 savePoint
- 保存点是事务过程中的一个逻辑点,我们可以把事务回退到这个点,而不必回退整个事务。
- 保存点的名称必须唯一,但是可以跟表名相同。
- 语法
savepoint savepoint_name ;
6.2.4 rollback to SavePoint
- 语法
rollback to savepoint_name ;
- 例子
savepoint sp1;
savepoint create;
SQL_X1;
savepoint sp2;
savepoint create;
SQL_X2;
rollback to sp1;
6.2.5 release savePoint
- 删除保存点
- 语法
release savePoint savepoint_name ;
6.2.6 set transaction
- 这个命令用于初始化数据库事务, 可以指定事务的特性
- 语法
SET TRANSACTION READ WRITE;--查询和操作,对数据库对象加锁,保证数据完整性。
SET TRANSACTION READ ONLY; --只读 适合生成报告,速度快。
6.3 事务控制与数据库性能
- 当出现COMMIT命令时,回退事务信息被写入到目标表里,临时存储区域里的回退信息被清除。当出现ROLLBACK命令时,修改不会作用于数据库,而临时存储区域里的回退信息被清除。如果一直没有出现COMMIT或ROLLBACK命令,临时存储区域里的回退信息就会不断增长,直到没有剩余空间,导致数据库停止全部进程。直到空间被释放。虽然存储空间的使用实际上是由数据库管理员(DBA)控制的,但缺少事务控制控制还是会导致数据库处理停止,有时迫使 DBA 采取行动中止正在运行的用户进程。
第三部分 从查询中获得有效的结果
第7章 数据库查询
7.1 什么是查询
- 从数据库获取数据。
7.2 SELECT语句
- SELECT语句代表了SQL里的数据查询语言(DQL),是构成数据库查询的基本语句。
- 关键字
- select 必要
- from 必要
- where
- order by
7.2.1 SELECT语句
- select和from子句结合,以可读的有序方式从数据库读取数据。
- 语法 常用符号‘ , ’做分割参数
SELECT [ *|ALL|DISTINCT COLUMN1, COLUMN2,]
FROM TABLE1 [, TABLE2 1];
7.2.2 FROM语句
- from语句必须搭配select语句,查询必要元素。至少指定一张表可以指定多张表。
- 语法
from 表1[,表2]
7.2.3 where语句
- where子句里面指定了要返回满足什么标准的信息。条件值TRUE或者false。
- 语法
SELECT [ *|ALL|DISTINCT COLUMN1, COLUMN2,]
FROM TABLE1 [, TABLE2 1]
[ WHERE CONDITION1|EXPRESSION1 [ AND|OR CONDITION2|EXPRESSION2] ];
7.2.4 ORDER BY语句
- 排序。默认升序ASC。
- SQL排序基于字符的ASCII值。数字0-9按照值排序,在字母A-Z之前。
- 有一些SQL实现,由于数字位在排序时是被当作字符处理的,所以下面这些数字的排序是这样的1、12、2、255、3。
- 但是我自己用Oracle。 order by number类型可以正常排序。
- 如果出现数字隐氏转换,可以用TO_CHAR函数转换补位,将数字转换成统一格式的字符串比较排序。
SELECT ROWID, TO_CHAR(COST,'999990.000') ,SUBSTR( TO_CHAR(COST,'999990.000'),-4,2) FROM PRODUCTS_TBL ORDER BY SUBSTR( TO_CHAR(COST,'999990.000'),-2,2);
- 语法
SELECT [ *|ALL|DISTINCT COLUMN1, COLUMN2,]
FROM TABLE1 [, TABLE2 1]
[ WHERE CONDITION1|EXPRESSION1 [ AND|OR CONDITION2|EXPRESSION2]
ORDER BY COULMN1|INTEGER [ASC\DESC] ];
- 字段缩写成整数
--1代表第一个字段 按照prod_desc排序
select prod_desc, prod_id,cost from products_tbl where cost < 200 order by 1;
- 字段顺序,先按照A排序,再按照B排序。
ORDER BY A,B
7.2.5 大小写敏感
- 一般SQL实现,命令和关键字不区分大小写。
- Oracle默认区分大小写。要注意。
7.3 查询范例
7.3.1 统计表数量
- 语法
select count(*) from 表名 表里全部数据行数
select count(非空字段)from 表名 =表全部记录
select count(可以为空字段) from 表名 不含有全部表记录
select count(DISTINCT 字段) from 表名 去重
7.3.1 从另一个表选择数据
SELECT 字段名 FROM 规划名|用户名.表名
7.3.1 别名
- 有时候 ,我们在对表格进行查询时, 因为字段进行了运算, 它的表头出现了改变, 我们需要指定一个别名, 来更方便的使用它
语法格式:
select 查询的列或者表达式1 别名,查询的列或者表达式2 别名 from 表名;
单个列只允许存在一个别名!
需求: 查询年薪, 并且给年薪字段添加别名:
-- 别名
--select last_name,salary*13 yearly salary from s_emp;--报错 ORA-00933: ORA-00923: 未找到要求的 FROM 关键字 yearly salary改成yearly_salary
--select last_name,salary*13 as '年薪' from s_emp;--不可以 ORA-00923: 未找到要求的 FROM 关键字
select last_name,salary*13 yearlySalary from s_emp;--可以
select last_name,salary*13 as yearlySalary from s_emp;--可以
select last_name,salary*13 as 年薪 from s_emp;--可以
- 3.别名中存在空格等特殊字符时 使用双引号引住, 可以把空格之类的特殊字符 看作一个整体,并且会原样显示(大小写区分显示)
--查询员工的id , 并加10000显示, 给id添加别名 id heheda
select id+10000 "id heheda" from s_emp;
--查询员工的id , 并加10000显示, 给id添加别名 as不省略 id heheda
select id+10000 as "id heheda" from s_emp;
第八章 使用操作符进行分类
8.1 定义和分类
- 操作符是个保留字或字符,主要用于SQL语句的WHERE子句来执行操作。
- 比较操作符
- 逻辑操作符
- 求反操作符
- 算术操作符
8.2 比较操作符
- 分为:
- 等于 = 返回TRUE 或者FALSE
- 不等于 != 或<>
- 小于 < 小于等于<=
- 大于 > 小于等于>=
8.3 逻辑操作符和模糊查询
- IS NULL:判断是否为空, 'null’代表空字符串,不为空。
- BETWEEN AND: 判断值是否在一个区间[MIN,MAX]之间。可以是数字,文本或日期。闭区间包含边界值。
- BETWEEN A AND B:[A-B]包含A和B的值。
- 如果是DATE日期类型:between ‘2010-04-21’ and ‘2010-04-23’ ,这样’2010-04-23 16:42:39’这条记录查不到。因为日期数据类型是左闭右开的区间,它的边界值是’2010-04-23 00:00:00’。
- IN:把一个值与一个指定列表(点的集合)进行比较,当被比较的值至少与列中的一个值相匹配时,它会返回TRUE。
- EXISTS:搜索指定表里是否存在满足特定条件的记录。
- ALL:ALL用于把个值与另一个集合里的全部值进行比较。
- SOME、ANY:用于把一个值与另一个列表里任意值进行比较。
8.3.1模糊查询
- Like:用于模糊查询。
- 百分号:%零个、一个或多个字符。
- 下划线_:一个数字或字符。
第二个字符是大写S的记录。
name like '_S%'
8.4 连接操作符
- AND:让我们可以在一条SQL语句的WHERE子句里使用多个条件。所有由AND连接的条件都必须为TRUE。SQL语句才会实际执行。
- OR:可以在SQL 语句的WHERE 于句里连接多个条件,这时无论SQL 语句是事
务惮作还是查询,只要OR 连接的条件里有至少一个是TRUE. SQL 语句就会执行。 - 多个条件时要善用()
8.5 求反操作符
- NOT
- 不等于<> !=
- NOT BETWEEN 不包含边界。 BETWEEN包含边界
- NOT IN
- NOT LIKE
- IS NOT NULL
- NOT EXISTS
- NOT UNIQUE
8.6 算术操作符
- (+) 加 (-)减 (*)乘 (/)除法
- 注意使用括号,否则运算符有优先级的顺序。
第10章 数据排序与分组
10.1 group by子句
SELECT COLUMN1,COLUMN2
FROM TABLE1, TABLE2
WHERE CONDITIONS
GROUP BY COLUMN1,COLUMN2
ORDER BY COLUMN1,COLUMN2
默认升序:具体数值在排序时位于NULL 值之前。
10.2 GROUP BY与ORDER BY
- GROUP BY:分组
- ORDER BY:排序
- 所有被选中的、非汇总函数(SUM AVG等)的字段必须列在GROUP BY子句里
- 除非需要使用汇单函数,否则使用GROUPBY 子句进行排序通常是么有必要的。
select 字段1,字段2 from 表 group by 字段一;--错误 group by 要跟所有的非汇总函数字段
select 字段1,字段2 from 表 group by 字段一,字段2;
10.3 CUBE与ROLLUP语句
参考链接: https://blog.csdn.net/liuxiao723846/article/details/49020575
- ROLLUP
GROUP BY ROLLUP(ordered column list 0f grouping set)
- ROLLUP语句可以用来进行小计,即在全部分组数据的基础上,对其中的一部分进行汇总。
- ROLLUP语句的工作方式是这样的,在完成了基本的分组数据汇且以后,按照从右向左的顺序,每次去掉字段列表中的最后一个字段,再对剩余的字段进行分组统计,并将获得的小计结果插入返回表中,被去掉的字段位置使用NULL 填充。最后,再对全表进行一次统计,所有字段位置均使用NULL填充。
1)对比没有带rollup的goup by :
Group by A,B产生的分组种数:1种;
group by A,B
返回结果集:也就是这一种分组的结果集。
2)带rollup但group by与rollup之间没有任何内容 :
A、Group by rollup(A ,B) 产生的分组种数:3种;
第一种:group by A,B
第二种:group by A
第三种:group by NULL
返回结果集:为以上三种分组统计结果集的并集且未去掉重复数据。
3)带rollup但groupby与rollup之间还包含有列信息
A、Group by A , rollup(A ,B) 产生的分组种数:3种;
第一种:group by A,A,B 等价于group by A,B
第二种:group by A,A 等价于group by A
第三种:group by A,NULL 等价于group by A
返回结果集:为以上三种分组统计结果集的并集且未去掉重复数据。
- CUBE
CUBE语句的工作万式与此不同。它对分组列表中的所有字段进行排列组合,井根据每一种组合结果,分别进行统计汇总。最后,CUBE语句也会对全表进行统计。 CUBE语句的语法结构如下:
GROUP BY CUBE(column list of grouping sets)
- 3、cube和rollup区别:
带cube子句的groupby会产生更多的分组统计数据。cube后的列有多少种组合(注意组合是与顺序无关的)就会有多少种分组。
1)假设有n个维度,rollup会有n个聚合:
rollup(a,b) 统计列包含:(a,b)、(a)、()
rollup(a,b,c)统计列包含:(a,b,c)、(a,b)、(a)、()
……以此类推ing……
2)假设有n个纬度,cube会有2的n次方个聚合:
cube(a,b) 统计列包含:(a,b)、(a)、(b)、()
cube(a,b,c) 统计列包含:(a,b,c)、(a,b)、(a,c)、(b,c)、(a)、(b)、(c)、()
10.4 having
- having子句和group by一起使用,紧跟在group by的后边,having子句可以使用结果集中的列,也可以使用聚合函数(max、min、count、sum、svg)。having的作用是对分组后的结果进行过滤。这里在提一下where,where是对每一行进行过滤的,查询出符合where条件的每一行。having是对查询出结果集分组后的结果进行过滤。
SELECT COLUMN1,COLUMN2
FROM TABLE1, TABLE2
WHERE CONDITIONS
GROUP BY COLUMN1,COLUMN2
HAVING CONDITIONS
ORDER BY COLUMN1,COLUMN2
第11章 调整数据外观
11.1 ANSI字符函数
- 在SQL里以不同于存储方式的格式来表示字符串。
11.2 常用字符函数
11.2.1 串接函数
MySQL
select concat('A','B')
CONCAT(COLUMN_NAME ,[' ',] COLUMN_NAME [COLUMN_NAME])
Oracle
COLUMN_NAME || [''||] COLUMN_NAME [COLUMN_NAME]
11.2.2 TRANSLATE函数
- 搜索字符串里的字符并查找特定的字符,标记找到的位置,然后用替代字符串里对应的字符替换它。
TRANSLATE( CHARACTER SET , VALUE1 , VALUE2)
--所有的I都被替换为A 、N替换为B 、D 替换为C
SELECT TRANSLATE(CITY,'IND','ABC') FROM EMPLOYEE_TBL;
11.2.3 REPLACE函数
- 用于把某个字符或字符串替换为指定的个字符〈或多个字符)。其使用
类似于TRANSLATE函数,只是它是把一个字符或字符串替换到另一个字符串里面。
第四部分 建立复杂的数据库查询
第13章 在查询里结合表
13.1 从多个表查询数据
- 能够从多个在选择数据是SQL最强大的特性之一。如果没有这种能力,关系型数据库的
整个概念就无法实现了。有时单表查询就可以得到有用的信息,但在现实世界里,最实用用的查询是要从数据库里的多个表获取数据。
13.2 综合的类型
- 概念:结合就是把两个或事个表组合在一起来在取数据。
- 分类:
- 等值结合、内部结合、等值连接,内连接。
- 非等值结合(范围连接)
- 外部结合(外连接又分成左连接、右连接)
- 自连接(自结合)
13.2.2 内连接(等值结合)
- 最常用也是最重要的结合就是等值结合,也被称为内部结合/内连接。内连接通常利用通用字段结合两个表,而这个字段通常是每个表里的主键。
- 语法:
SELECT TABLE1.COLUMN1 , TABLE2.COLUMN2 ...
FROM TABLE1, TABLE2 [, TABLE3]
WHERE TABLE1.COLUMN_NAME = TABLE2.COLUMN_NAME
[AND TABLE1.COLUMN_NAME = TABLE3.COLUMN_NAME ]
- 具体范例如下:
SELECT EMPLOYEE_TBL.EMP_ID,
EMPLOYEE_PAY_TBL.DATE_HIRE
FROM EMPLOYEE_TBL,
EMPLOYEE_PAY_TBL
WHERE EMPLOYEE_TBL.EMP_ID=EMPLOYEE_PAY_TBL.EMP_ID;
13.2.3 使用表别名
- 使用表的别名在SQL 语句显对表进行重命名,这是种临时性的改变。表在数据
库里的实际名样不会受到影响。 - 起别名是完成自结合的必要条件。
- 选择字段必须用表别名修饰。
- 减少代码量,易读性,不易犯错。
SELECT E.EMP_ID, EP.SALARY, EP. DATE_HIRE, E.LAST_NAME
FROM EMPLOYEE_TBL E,
EMPLOYEE_PAY_TBL EP,
WHERE E.EMP_ID=EP.EMP_ID
AND EP.SALARY>20000;
13.2.4 不等值连接(结合)
- 不使用等号进行连接多表查询的条件, 就是非等值连接。
- 不等值连接可能会产生冗余数据注意删除。
- 语法:
SELECT TABLE1.COLUMN1 , TABLE2.COLUMN2 ...
FROM TABLE1, TABLE2 [, TABLE3]
WHERE TABLE1.COLUMN_NAME != TABLE2.COLUMN_NAME
[AND TABLE1.COLUMN_NAME!= TABLE3.COLUMN_NAME ]
具体范例如下:
SELECT EMPLOYEE_TBL.EMP_ID,
EMPLOYEE_PAY_TBL.DATE_HIRE
FROM EMPLOYEE_TBL,
EMPLOYEE_PAY_TBL
WHERE EMPLOYEE_TBL.EMP_ID != EMPLOYEE_PAY_TBL.EMP_ID;
salgrade : 工资级别表格
- grade工资级别 1-5
- losal这个级别最低工资
- hisal这个级别最高工资
- 查询每个员工的salary和对应的工资级别
1. between
select salary,last_name,grade from s_emp,salgrade where salary between losal and hisal;
2. and
select salary,last_name,grade from s_emp,salgrade where salary>=losal and salary<=hisal;
13.2.5外连接(+) 外部结合
-
定义
- 外连接的结果集, 等于内连接的结果集,加上匹配不上的记录!
- 通过在字段后面添加(+), 来完成外连接操作。(+)在谁后面就用NULL补充谁的数据。
- 外连接会返回一个表里的全部记录,即使对应的记录在第二个表里不存在。加号(+)用于在查询里表示外部结合,放在WHERE子句里表名的后面,具有加号的表是没有匹配记录的表。
-
分类:外连接被划分为左外连接、右外连接和全外连接。
-
语法:
外部结合的-般语法如下所示
FROM TABLEl
{RIGHT | LEFT | FULL} [OUTER] JOIN
ON TABLE2
Oracle 的语法是
FromSELECT A.COLUMN_NAME, B.COLUMN_NAME [, C.COLUMN_NAME]...
FAOM TABLE1 A, TABLE2 B [,TABLE3 C]
WHERE TABLE1A.COLUMN_NAME[(+)] = TABLE2 = B.COLUMN_NAME[(+)]
[ AND TABLE1A.COLUMN_NAME[(+)] = TABLE3.COLUMN_NAME[(+)] ]
- 格式:
把(+)加在where条件的字段后面,(+)号修饰的字段所在的表的对面表格的数据全部被选中 !
e.manager_id(+)=m.id: m表被全部选中 e.manager_id=m.id(+):e表被全部选中
特点: 内连接匹配不上的数据, 因为外连接要取出, 外连接会通过补足null行来生成结果集
查询s_emp表格, 获取普通员工的信息
select distinct m.last_name,m.id from s_emp e,s_emp m where e.manager_id(+)=m.id and e.manager_id is null;
e m
e.id e.name e.m_id m.id m.name m.m_id
1 a null 1 a null
2 b 1 2 b 1
3 c 1 3 c 1
4 d 2 4 d 2
5 e 2 5 e 2
select m.id,m.name from e,m where e.manager_id is null;
- 实例:
表结构:
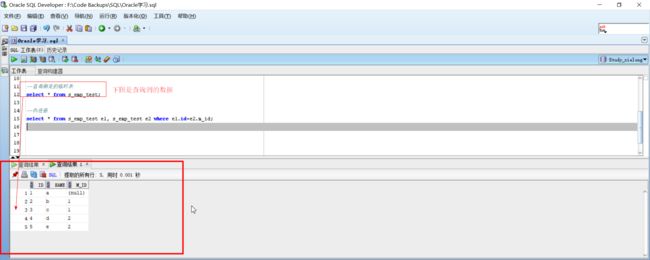
- 外连接实例:
--查询测是的临时表
select * from s_emp_test;
--内连接 两张表的数据
select * from s_emp_test e1, s_emp_test e2
where e1.id=e2.m_id;
--内连接 一张表的数据 有重复
select e1.* from s_emp_test e1, s_emp_test e2
where e1.id=e2.m_id;
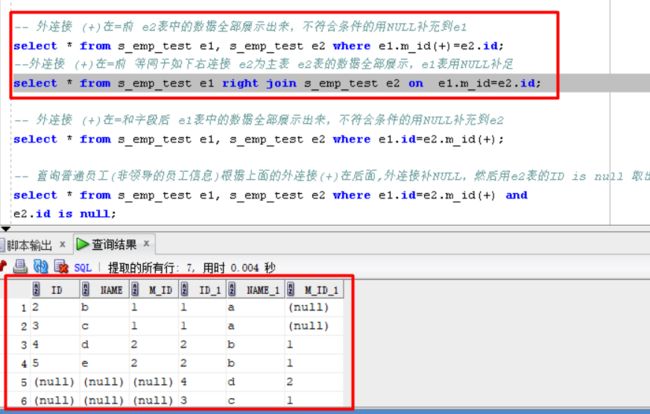
-- 外连接 (+)在=前 e2表中的数据全部展示出来,不符合条件的用NULL补充到e1
select * from s_emp_test e1, s_emp_test e2
where e1.m_id(+)=e2.id;
--外连接 (+)在=前 等同于如下右连接 e2为主表 e2表的数据全部展示,e1表用NULL补足
select * from s_emp_test e1 right join
s_emp_test e2 on e1.m_id=e2.id;
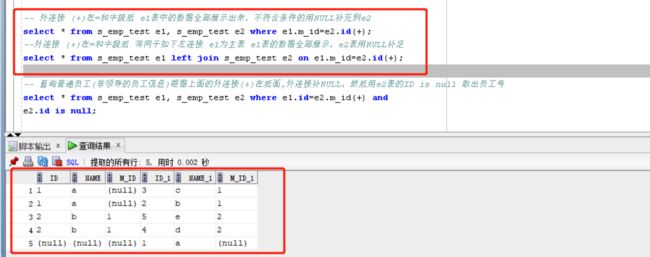
-- 外连接 (+)在=和字段后 e1表中的数据全部展示出来,不符合条件的用NULL补充到e2
select * from s_emp_test e1,
s_emp_test e2 where e1.m_id=e2.id(+);
--外连接 (+)在=和字段后 等同于如下左连接 e1为主表 e1表的数据全部展示,e2表用NULL补足
select * from s_emp_test e1 left join
s_emp_test e2 on e1.m_id=e2.id(+);
-- 查询普通员工 --
-- 左连接:查询普通员工(非领导的员工信息)根据上面的外连接(+)在后面,外连接补NULL,然后用e2表的ID is null 取出员工号
select * from s_emp_test e1, s_emp_test e2
where e1.id=e2.m_id(+) and e2.id is null;
-- 右连接:查询普通员工的另一种方式
select * from s_emp_test e1, s_emp_test e2
where e1.m_id(+)=e2.id and e1.id is null;
--注意用 where 而不是 and 用and去并集 不符合要求
select * from s_emp_test e1 right join
s_emp_test e2 on e1.m_id=e2.id where e1.id is null;
-- 查询领导 --
-- 右连接
select distinct e2.* from s_emp_test e1
right join s_emp_test e2
on e1.m_id = e2.id where e1.m_id is not null;
-- 左连接
select distinct e1.* from s_emp_test e2
left join s_emp_test e1 on e2.m_id = e1.id
where e2.m_id is not null;
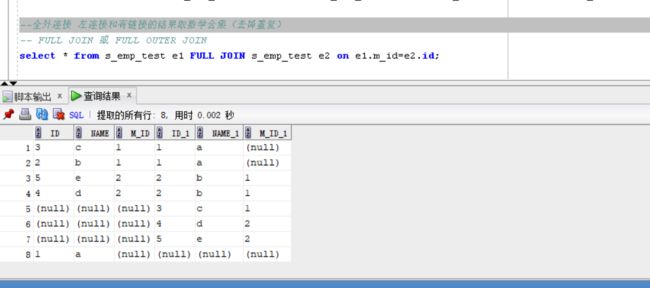
--全外连接 左连接和有链接的结果取数学合集(去掉重复)
-- FULL JOIN 或 FULL OUTER JOIN
select * from s_emp_test e1 FULL JOIN s_emp_test e2 on e1.m_id=e2.id;


13.2.6自连接
- 一张表中,有多层的业务含义的数据,要把某一层的含义数据取出来时,使用自连接!把一张表看作多张表进行查询。
- 具体范例例如:
SELECT A.LAST_NAME, B.LAST_NAME , A.FIRST_NAME...
FROM EMPLOYEE_TBL A,
EMPLOYEE_TBL B
WHERE A.LAST_NAME = B.LAST_NAME;
第14章 使用于查询定义未确定数据
14.1 什么是子查询
- 定义:就是嵌套查询。是位于另一个查询的WHERE子句里的查询,它返回的数据
通常在主查询里作为个条件,从而进一步限制数据库返回的数据。 - 语法:
SELECT COLUMN_NAME FROM TABLE
WHERE COLUMN_NAME = ( SELECT COLUMN_NAME FROM TABLE WHERE CONDITIONS);
14.2 子查询嵌套
1、select与子查询 常用
-- 查询低于编号311549902员工工资的 人员的的信息
select EP.PAY_RATE,E.EMP_ID,E.LAST_NAME,E.FIRST_NAME from EMPLOYEE_PAY_TBL EP,EMPLOYEE_TBL E where EP.SALARY >(SELECT SALARY from EMPLOYEE_PAY_TBL where EMP_ID='311549902');
2、子查询也可以用于DML(INSERT UPDATE DELETE等语句)不常用。