Cascaded Generative and Discriminative Learning for Microcalcification Detection in Breast Mammogram
摘要:微钙化在早期的乳腺癌中出现最多。之前的多数的微钙化检测模型以属于判别模型,用分类器将其与背景分开。将微钙化点与正常组织分开依然是一项挑战,因为它们太小了(最多14个像素)。尽管生成模型可以精确地对正常组织建立模型,并且可以将不正常组织做为异常值,但是他们不能够进一步将微钙化与其他异常区分开(血管钙化与微钙化这两个都是异常,但不能将其分开)。本文中,我们提出了一个混合方法,通过利用生成模型和判别模型。首先,称之为异常分离网络(ASN)的生成模型用来生成候选微钙化。ASN包括两个部分:一个深度卷积encoder-decoder网络,该网络用来学得图重建映射;一个t-test损失函数,该函数用来从正常组织中分开微钙化的重建残差的分布。其次,串联一个判别模型,用来从假阳性中区分微钙化。最后,为了验证我们的方法,我们在公开数据集上和内部数据集上进行了试验,证明我们的方法优于之前最新的方法。
一、绪言
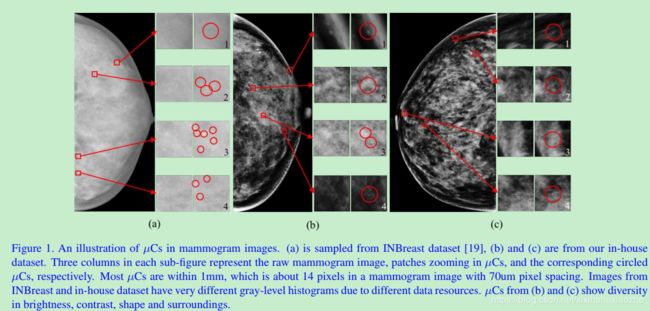
乳腺癌在女性范围中非常普遍。为早些发现它,乳腺筛查非常必要。在早期的乳腺癌迹象中,微钙化是最普遍的一种。为了分析它们,乳腺X线照片广泛使用。如图1所示,微钙化非常小且在亮度,对比度,外形方面与其周围差异巨大。对放射科医生来说,一个个地去发现它们非常困难且耗时。因此,精确度高的自动微钙化检测方法非常重要。
为达此目的,不同的方法已经被提出,其中最多的就是判别模型,即分类模型。一般做法是从图片中取不同的特征(如哈希特征,形状、纹理特征,深度特征)来训练一个将微钙化像素与正常像素分开的二分类模型。但是,这些方法面临着极端不均衡数据,原因就是微钙化太小了,在图像中普遍小于14像素,图像中绝大多数是正常组织。因此,对这种小目标抽取有效的特征极具挑战,并且会引出微钙化与其他组织的极端分布。在我们的实验中,正样本与负样本的之间的比例为4000。
针对上述问题,我们首先尝试区分正常像素和异常像素,而微钙化属于异常区域。这样,我们就可以减少判别模型中存在的大量的负样本。为此,我们从图像重建的角度对微钙化检测任务进行了重新思考。正常的样本是那些规则的背景,并且有大量的这些区域。因此,要找到一本字典来重建这些正常的样本应该不难。相反,微钙化是不规则的、稀小的、难以重建的。因此,学习一个正常样本可以很好地被重建模型是很自然的,而微钙化是不能的。本文设计了一种图像重建网络,将其建模为深度卷积编码-解码器网络,该网络具有强大学习能力的重建功能。此外,利用U-Net[24]作为主干网,对这些微小对象进行信息特征提取。
为进一步提高重建过程的性能,设计了t-test损失函数来驱动微钙化的残差分布远离正常区域的分布。提出的t-test损失函数受经典假设检验方法两样本t-test的启发。这里,我们将它替换为一个数据驱动的损失函数。具体来说,我们将正样本(微钙化)像素和负样本(正常组织)像素的重建残差作为重构网络学习到的两个独立随机变量。我们的t-test损失函数不是确定这两个分布是否不同,而是迫使重构网络尽可能不同地约束这两个分布。由于正常组织易于重建,而微钙化不易重建,我们将负像素的重建残差最小化,并对正像素进行硬阈值限制,使其大于预先设置的阈值。到目前为止,我们已经诠释了所提出的生成模块的所有必要组件,即异常分离网络(ASN)。
重建后得到异常区域,包括候选微钙化和其他类型的钙化,如血管钙化、杆状钙化等。虽然它们都属于钙化,但我们观察到它们在形状上有很大的不同。利用这一属性,我们建立了一个判别模型,即一个深度二分类网络,可以对微钙化和其他进行分类。该判别模型旨在实现假阳性抑制(FPR)。
为了验证该方法的有效性,我们在公共数据集INBreast[19]和我们的内部数据集上都进行了评估。我们在每张图像中检测到5例假阳性,召回率为78.35%(简化为R@5), InBreast检测到的R@10的召回率为85.96%;在内部数据集上,R@5为90.71%,R@10为92.24%,优于以前最先进的方法。
综上所述,我们的贡献主要有三方面:1)为了解决之前的判别模型所存在的不平衡问题,我们提出了一个生成模型来区分候选微钙化所处的正常区域和异常区域。此外,还利用U-Net来提取这些微小物体的信息特征。2)为了进一步提高性能,设计了一种新的t-test损失,以扩大正常区域和异常区域之间的分布多样性。3)与以前最先进的方法相比,ASN在公共和内部数据集上都实现了最好的性能。
二、相关工作
2.1 微钙化检测
多数的微钙化检测方法大约可以分为两类:基于图像处理的方法和基于学习的方法。第一类主要是基于这样一种现实,即微钙化普遍比周围的组织频率高且更明亮。乳腺照片首先用小波变换[1, 14]来增强,然后用黑塞矩阵响应[20],接着通过形态学操作[1]来确定微钙化。但是这种方法易受到组织密度的影响,并会出现较多的假阳性。
第二类是基于监督学习的方法。有效的二分类器可以训练将微钙化与正常组织区分开。Khalaf et al[14]提取几个形状和纹理描述,使用学生t-test和RBF核的SVM来进行特征筛选和训练。Harr-like特征[31]在文献[3]中被使用,其中一个串联分类器集合被用来处理类不均衡问题。Cai et al[4]使用CNN来学习深度特征来分类。该网络通过对带通滤波后的图像进行阈值化生成的建议进行训练。
2.2 图像重建
图像重建是重建可能存在噪声和模糊的原始图像的问题。一个典型的应用方法是稀疏字典学习,它的目的是学习组成字典的元素的稀疏线性表示。该算法采用L1正则化实现,对遮挡具有较强的鲁棒性。例如,提出了一种基于稀疏编码的分类算法[33],在人脸图像识别中成功地统一、鲁棒地处理遮挡和腐蚀问题。
为了利用CNN强大的表示能力,Turchenko等人提出了一种深度卷积自动编码器,实现降维、聚类和图像重建。Kingma和Welling[16]设计了自动编码变分贝叶斯算法,使我们能够执行非常有效的近似后验推理,也可以用于识别、去噪、表示和可视化等任务。Johnson等人[13]提出使用感知损失函数训练用于图像转换任务的前馈网络。Goodfellow等人[8]通过对抗性过程建立了一个新的生成模型估计框架,可广泛应用于图像生成。
2.3 双样本T-test
双样本t检验是一种确定两组数据是否存在显著差异的统计假设检验方法。假设每组样本独立于正态分布,且服从正态分布,计算得到的t统计量服从零假设下的学生t分布,即两组样本的分布不存在差异。通过乘积,也可以计算出对应的p值,p值衡量的是零假设成立的概率。因此,假定值小于α预定义阈值水平,可以拒绝零假设,这意味着两组数据被认为是不同的分布。
2.4 异常检测
异常检测,也称为离群点检测,是指识别数据中不符合预期行为[5]的模式的问题。这种不符合模式,即离群值,通常被定义为异常、罕见事件或异常数据,怀疑是由明显偏离最常见或预期模式[7]的不同机制产生的。异常值的检测可以为我们提供重要的信息,例如信用卡欺诈、临床试验中的医疗问题。此外,这些异常值的存在可能会导致估计、推理和模型选择等方面的不稳定性。因此,在给定新数据[12]的情况下,异常点识别是获得鲁棒参数估计和异常检测的关键。在本文中,我们将微钙化作为异常值,因为与常规的负像素相比,正像素的数目很少,并且分布也不同。
对于离群值的检测,已经提出了多种方法,包括单变量模型[17]和多变量模型[32,12,25]。对于未标记异常的无监督离群点检测,通常可以使用Hubers loss[12]的鲁棒回归,这使得正常数据的平方损失和异常数据的绝对损失最小化。在[26]中证明了该方案等价于LASSO问题,将异常检测转化为模型选择问题。
三、.方法
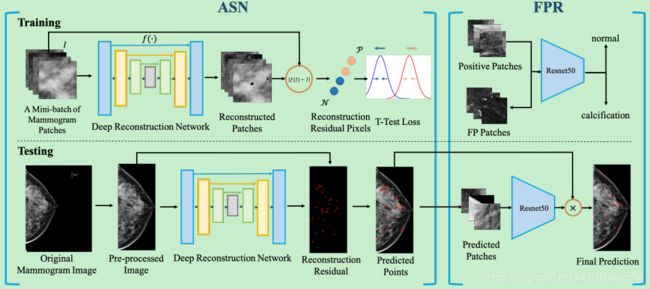
Figure 2.该方法的流程图。串联模型有两种:异常分离网络(ASN)模型和假阳性抑制(FPR)模型。ASN的输出直接输入到FPR中,FPR预测最终的结果。对于ASN,在训练过程中,使用x光片对基于U-Net的重建网络进行训练。对重建后的残差像素使用t检验损失,使正常残差和微钙化残差相互远离。在检测过程中,给定一幅乳房x线照片,经过预处理,计算重建残差,可以生成预测点(红色圆圈表示)。FPR模型是一种ResNet50,由ASN的硬负底片和ground truth的正底片训练而成。最后的预测是两个模型在得分水平上的乘积融合。
如图2所示,我们的系统主要由两个级联模块组成:异常分离网络(ASN)和假阳性约约束(FPR)模型。ASN的输出直接输入到FPR中,FPR预测最终的结果。在本节中,我们将分别介绍ASN和FPR。
3.1. Anomaly Separation Network
ASN包括两个核心部分:深度重建网络和具有t检验损失的重构残差学习。在训练过程中,乳房x线照片被切成小块,然后送到一个深度重建网络中,然后将t检验损失应用于重建残差,使得正常像素残差较小,微钙化像素相对较大。在测试过程中,对每一张完整的乳房x线照片计算重建残差图,并根据重建残差图预测点和评分。在本节中,我们将首先展示我们的重建网络和重建残差学习,然后解释广泛用于异常检测的Huber loss[12]与t检验损失之间的关系。
3.1.1 Deep Reconstruction Network
设计了一个深度重建网络来提供一个可学习的重建函数,深度卷积神经网络已被证明对许多图像任务具有鲁棒性和有效性。为了获得更好的表示能力,我们使用U-Net[24]进行像素级重建。我们的U-Net由三个下采样阶段和带有skip连接的三个上采样阶段。每个阶段包括3个卷积层。
设计这样一个网络有三个原因。首先,下采样操作可以得到有效的接收域大小,这有利于重建每个像素和重建图像的一致性。其次,微钙化的尺寸在14像素以内。因此,为了避免太多的信息丢失而无法重建,只对图像进行了8倍的降采样。第三,skip连接可以保持低层次的信息,这对于精确定位是必要的。
3.1.2 Reconstruction Residual Learning
设f(·)为重建网络函数。给定图像 I ,重建残差值为
其中P定义为像素,Θ定义为重建网络中的参数。正像素和负像素的重建残差的分布是不同的。因此,我们提出了t检验损失。在接下来的章节中,我们将首先回顾双样本t检验,然后演示t检验loss的有效性。
Two-Sample T-test 给定两个样本组,x1, ..., xNx独立同分布∼ N(µx, σx2) and y1, ..., yNy ∼ N(µy, σy2),iid。为检验
µx是否大于 µy,提出零假设和备择假设:![]() ,生成一个t统计量:
,生成一个t统计量: ,分子表示样本组的均值差值,Sx和Sy表示x和y的样本方差。当
,分子表示样本组的均值差值,Sx和Sy表示x和y的样本方差。当![]() 时,我们就拒绝零假设而接受备择假设,其中
时,我们就拒绝零假设而接受备择假设,其中![]() 是自由度为
是自由度为![]() 的t分布在显著水平为
的t分布在显著水平为![]() 下的临界值,即
下的临界值,即![]()
![]() ,其中
,其中
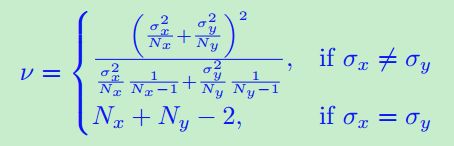
在现实中,![]() 和
和![]() 可能不满足正太分布,但是,根据中心极限定理,当Nx和Ny足够大时,x¯和y¯近似于正态分布,也可以采用双样本t检验。由于正常组织是规则的,钙化不是分散分布,我们估计自由度为
可能不满足正太分布,但是,根据中心极限定理,当Nx和Ny足够大时,x¯和y¯近似于正态分布,也可以采用双样本t检验。由于正常组织是规则的,钙化不是分散分布,我们估计自由度为
T-test Loss 给定独立的正负样本,我们使用1来计算重建的残差值,定义为![]() 和
和![]() 。在本文其余部分,我们将上述残差值表示为
。在本文其余部分,我们将上述残差值表示为![]() 和
和![]() ,然后我们提出以下t检验损失:
,然后我们提出以下t检验损失:![]() ,其中阈值超参数β表示正负样本残差分布均值之间的差;
,其中阈值超参数β表示正负样本残差分布均值之间的差;![]() 和
和![]() 是正则化超参数。
是正则化超参数。
最小化这种t检验损失可以看作是最大化式2中定义的t统计量,它通常用于确定两组数据是否不同。相反,我们的目标是准确的分类,即能够以监督的方式从负图像像素中识别出微钙化。为了实现这一目标,我们反过来提出通过最小化L来驱动标记为正的像素远离标记为负的像素。
更详细地,注意到![]() 希望重建参数(Θ)较好拟合负像素而给正像素的重建一个较大的差值。在另一方面,Θ用来训练学习负像素和剩下的像素,除了正样本块中的微钙化。因此,对于测试集中的正像素,Θ可以用大差值重建。通过这种方式,它可以成功地预测正标签和对应的残差可以被视为微钙化
希望重建参数(Θ)较好拟合负像素而给正像素的重建一个较大的差值。在另一方面,Θ用来训练学习负像素和剩下的像素,除了正样本块中的微钙化。因此,对于测试集中的正像素,Θ可以用大差值重建。通过这种方式,它可以成功地预测正标签和对应的残差可以被视为微钙化
除了公式6的部分,我们对Sx和Sy进行了正则化。没有这样的正则化,Θ的估计往往是不稳定的。这是因为较大的Sx和Sy值可以使![]() 容易变大或变小,因为它们倾向于发散分布。
容易变大或变小,因为它们倾向于发散分布。
相比之下,最小![]() 估计误差损失可能存在模型崩溃问题,即学习的映射函数趋于恒等。因此,它们无法对正像素的底层结构建模,因此不能的测试集中检测微钙化。此外,与估计误差损失相比,我们的损失是任务趋向,更偏向于在测试阶段与异常检测规则一致,即如果
估计误差损失可能存在模型崩溃问题,即学习的映射函数趋于恒等。因此,它们无法对正像素的底层结构建模,因此不能的测试集中检测微钙化。此外,与估计误差损失相比,我们的损失是任务趋向,更偏向于在测试阶段与异常检测规则一致,即如果![]() ,补丁i为离群值。
,补丁i为离群值。
此外,估计出的Θ可以在测试阶段直接用于检测微钙化,这是有监督(微钙化是标记好的)去为负(正)样本样本小(大)于阈值参数β的残差值建模,。因此,可以将t检验损失纳入整个端到端过程中,如图2所示。
3.1.3 Connection to Huber’s loss
我们提取的t-test损失可以认为是具有hubor‘s损失的鲁棒性回归的一个变种,hubor是一种无监督检测方法。更详细地说,Hubor's损失在本文中可以写为: (该公式为平方损失<平均无偏估计>和绝对损失<中位数无偏估计>的组合),N为训练集中切分块的数量,且
(该公式为平方损失<平均无偏估计>和绝对损失<中位数无偏估计>的组合),N为训练集中切分块的数量,且![]()
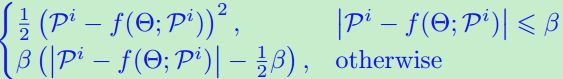 ,已经证明最小化Hubor’s损失等价于
,已经证明最小化Hubor’s损失等价于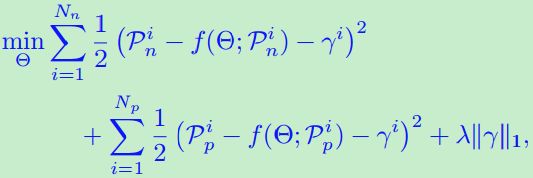 ,i是异常值,即当且仅当
,i是异常值,即当且仅当![]() 时
时![]() 。异常值在这是无标签的,他们可以被认为是
。异常值在这是无标签的,他们可以被认为是![]() 非零值元素。
非零值元素。
在我们的实验中,异常值在训练数据 中是带标签的。因此,为了消除这些异常值的偏差效应,又提出了约束这些异常值以满足Huber损失的定义,即对第个i有![]() 。结合对
。结合对![]() 的绝对损失,总损失设计为:
的绝对损失,总损失设计为:![]() 。其中
。其中![]() 期望大于阀值参数β,为了更强的鲁棒性和更好的泛化,这是Huber 's loss中的约束是一种抵消。通过消除异常值的影响,可以实现Θ稳健估计,进而可能在测试数据中获得准确检测异常值。此外,如前所述,我们还对方差进行了正则化,以防止不稳定的参数估计。
期望大于阀值参数β,为了更强的鲁棒性和更好的泛化,这是Huber 's loss中的约束是一种抵消。通过消除异常值的影响,可以实现Θ稳健估计,进而可能在测试数据中获得准确检测异常值。此外,如前所述,我们还对方差进行了正则化,以防止不稳定的参数估计。
3.1.4 Setting Hyper-parameters
阈值参数β>0,与显著性水平α成反比。从异常值检测的角度来看,它是掩蔽效应和淹没效应[12]之间的权衡。太小β可能导致错误识别负面像素作为离群值,即淹没效应;而太大的值可能会丢失一些异常值,即掩蔽效应。
较大的![]() 意味着在方差上更多的正则化。在这里,我们将异构正规化(λp不等于λn)引入到我们的损失,这意味着方差是不同的。在我们的实验中,微钙化是不规则的,因此重构可能会有很大的变化。因此,在Sp上实现更大的正则化是合理的,以防止Sp过大。正如展示在实验的部分即最好的预测结果是当λp >λn。
意味着在方差上更多的正则化。在这里,我们将异构正规化(λp不等于λn)引入到我们的损失,这意味着方差是不同的。在我们的实验中,微钙化是不规则的,因此重构可能会有很大的变化。因此,在Sp上实现更大的正则化是合理的,以防止Sp过大。正如展示在实验的部分即最好的预测结果是当λp >λn。
3.2. False Positive Reduction

该方法能较好地重建正常组织,并将微钙化视为异常。然而,在乳房x光检查中有各种各样的钙化。如图3所示,左侧斑块中的绿色矩形为血管钙化,可以认为是大量钙化像素。对于ASN来说,虽然它们在形状上与真实的微钙化有很大的不同,但是对于重构来说,它们也是异常值,如图3中右侧patch上的橙色圆圈所示。但对于判别模型,它们并不难区分。因此,我们将一个深度分类网络串联,以进一步减少假阳性。
我们在FPR阶段使用了ResNet50[10]。对于给定的图像,我们对ASN生成的重构残差图使用一个简单的阈值。对于每个连通分量,我们使用中心作为预测位置,重建残差值的求和得分作为ASN得分。对于每个ASN预测,裁剪一个大小为56*56的图片块,并将其调整为224*224,然后输入ResNet50。我们使用ASN和FPR评分的结果作为最终评分。
四、实验
4.1 Implement details
乳腺x线照片通常以12位或14位的DICOM格式存储。要将其转换为8位灰度图像,需将所有原始像素线性映射到0~255区间。对于预处理,我们首先对图像进行归一化,使其像素间距相同,为70µm。然后,我们用Otsus方法[21]分割乳腺区域,去除乳房x线照片的背景。
我们使用pytorch实现了所提出的模型。ASN使用从论文[9]中初始化的权重进行训练。我们使用Adam[15],其衰减为10E-4,初始学习率为0.001。运行的梯度平均及其平方的运行平均值分别为0.9和0.999,边缘参数β设置为0.8,而权重参数λp和λn分别设置为1和0.1。在训练过程中,乳腺x线照片被裁剪成大小为112*112的小块,并输入ASN。我们不使用整个图像,因为它们通常是高分辨率的(3500*2500像素),这对于内存限制来说太大了。我们将阳性和阴性的patch采样为1:1,以提取更多的proposal。
FPR模型由ImageNet进行预训练。使用SGD,学习率从0.001开始。ASN的所有预测和全部ground truth微钙化都用于训练FPR模型,不需要额外的采样。
4.2 Datasets
我们评估了一个名为INBreast[19]的公共数据集和一个内部数据集的性能。乳腺x线摄影数据集有MIAS[29]、DDSM[11]、INBreast等。我们选择INBreast是因为图像质量微钙化标注相对较好。INBreast包含115例,410幅乳腺x线照片,其中两名放射科医生发现了6880个钙化点,滤除大于1mm的钙化点后,取5782 钙化点进行实验。我们以3:1:1的比例将数据集随机分为训练集、验证集和测试集。具体划分见补充资料。
我们还收集了一个内部的数据集进行进一步的评估,其中包含439个案例和1799张图像,不同研究年限但来自同一女性的图像被作为同一案例拍摄,两名经验超过10年的放射科医生对数据集进行了注释,找到了7588颗经鉴定为真实的微钙化。我们选取了339例1386张图像和5479张微钙化作为训练集,50例208张图像和1129张微钙化作为验证集,50例205张图像和980张微钙化作为测试集。
4.3. Baseline Methods
对于这两个数据集,我们建立了两个基准:
FPN FRCN:faster RCNN[23]与特征金字塔网络(FPN)[18]。FPN是一种最新的检测模型,尤其适用于小目标。我们使用ResNet50作为骨干。对于每个预测的边界框,使用中心点进行最终评估。
U-Net w FPR:带FPR的U-Net。U-Net[24]对医学图像分割是有效的。跳跃连接有助于小对象分割。在此,我们将U-Net与ASN进行比较,以验证所提出的生成模型的有效性。为了处理极端不平衡样本,并与所提出的模型进行公平比较,我们设计了一个与ASN相似的两阶段分割模型。我们首先使用相同的带有交叉熵损失ASN有监督网络结构训练一个分割任务;将阳性和阴性的patch采样为1:1,以提取更多的proposal;我们选择预测掩模的连通区域作为建议,与所提出的方法相似。然后对FPR模型进行串联,以减少报假阳性。表3。INBreast数据集的提案评估(%)。
4.4 Performances
我们给出了每幅图像在有k个假阳性情况下的召回率(简化为R@k),其中k={1,5,10,15,20}用于最终模型,k={5,10,15,20,30}用于建议模型。如果在距离钙化点1mm以内至少有一个预测点,则认为钙化点被召回。
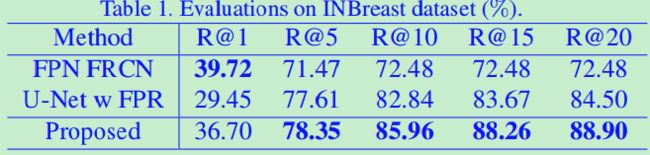

如表1和表2所示,所提出的模型在两个数据集上都优于最先进的方法。FPN的召回率相对较低,主要原因是一些微钙化非常小(小于5像素)。相对于原始图像,FPN最优预测水平的分辨率仅为1/4。对于图6中的前3个例子,FPN都没有检测到。此外,较小的尺寸也意味着RPN中阳性锚点较少,这可能导致召回率较低。U-Net模型可以处理较小的微钙化尺寸,因为它们能很好地预测像素。然而,一些模糊的样本仍然具有挑战性,并且在第一阶段被遗漏,而所提出的模型受到的影响较小。表3和表4为提案定量评价结果,ASN在这两个数据集中的表现都比U-Net好3%左右。由图4和图5可知,ASN的查全率和假阳性率均高于U-Net,说明生成方法对微钙化等噪声异常值更为敏感。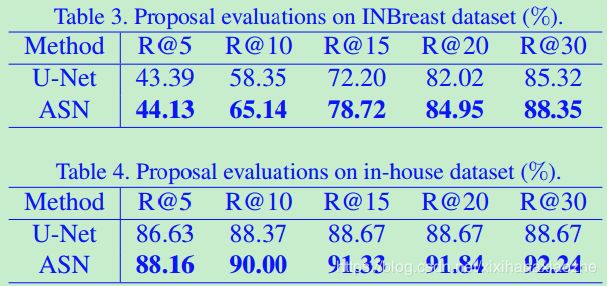
图6第四行是一个血管钙化的例子,ASN预测为微钙化,血管钙化区域可以看作是非常局部钙化像素的组合。但是,它们在全局模式上与微钙化有很大的不同,这对于FPR模型来说并不难学。简而言之,生成模型和判别模型在某种程度上是互补的。因此,所提出的模型既能提高召回率,又能降低假阳性。
4.5 Ablation study
为了验证t检验损失的有效性,我们首先训练一个具有损失函数的平面重建模型,使原始图像和重建图像的均方误差最小。然而,该模型似乎崩溃成一个简单的模糊函数,其中只有少数高频成分出现在重建 残差中,它不能识别大多数微钙化。这一现象也说明提出的t检验损失是必要的。
验证正则化的必要性,设置λp =λn = 0和损失函数变成公式![]() ,即没有正残差方差的正则化和负残差方差的正则化。
,即没有正残差方差的正则化和负残差方差的正则化。
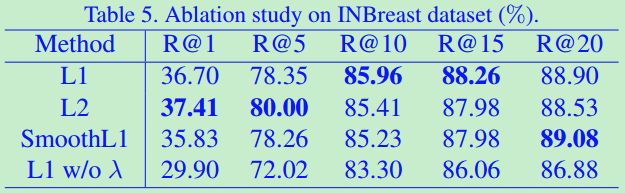 如表5所示,对最后一行的改进可能是由于正则化可以避免估计过于分散以致残差不稳定。
如表5所示,对最后一行的改进可能是由于正则化可以避免估计过于分散以致残差不稳定。
此外,我们比较了一些变量以揭示不同组件的贡献。在Eq1中,利用L1距离计算重构残差。用L2和Smooth L1[23]来代替它,以进一步研究其影响。如表5所示,这些变体产生了可比较的结果。
5. Discussions and Conclusions
本文提出了一种将判别模型级联到生成模型的新模型,以解决乳腺x线照片中微钙化检测问题。微钙化非常小,在正常组织中也很少见,这对鉴别模型具有挑战性。首先提出了一种新的生成模型——异常分离网络(ASN)来提取建议proposal,然后将分类网络训练成假阳性抑制(FPR)模型。在ASN中,采用深卷积编解码器网络进行重建学习,并提出了t检验损失函数对网络进行监督训练。在公共数据集和内部数据集上的实验表明,我们的模型优于以前最先进的方法。然而,当微钙化太接近时(图6最后一行),该方法仍然具有挑战性。在未来,我们会努力尝试以端到端方式进行整个流程。