目标检测 (Object Detection) (一): 评估标准 (mAP,IOU,NMS,FPS)
目标检测算法(一):评估标准
目标检测是计算机视觉领域的基本且重要的问题之一。一般目标检测(generic object detection)的目标是根据大量预定义的类别在自然图像中确定目标实例的位置与类别。本文主要介绍目标检测的评估标准。
常用的目标检测的评估标准包括:平均精度均值mAP(mean average precision)、交并比IoU(Intersection over Union)、非极大值抑制NMS(Non-Maximum suppression);每秒帧率FPS (Frame Per Second),即:每秒处理的图片数量。
1. mAP (mean average precision)
mAP是目标检测算法中最重要的评估指标之一。
AP(Average precision): 代表平均精度,是Precision-Recall曲线下的面积,分类器分类效果越好,AP越大。
mAP(Mean average precision): 即多类别的AP的平均值,mean代表队每个类别下得到的AP再求平均。mAP的取值范围为![[0,1]](http://img.e-com-net.com/image/info8/de5eda5e79d94e8580b65b4053ab5162.gif) ,值越大越好。
,值越大越好。
接下来我们详细介绍一下mAP涉及到的相关概念:
-
混淆矩阵,TP,FP,FN,TN,Precision,Recall
假设分类目标为二分类,分别为正样本(Positive,简写为P)和负样本(Negtative,简写为N),则分类结果分为一下几种。

上表混淆矩阵,可以看到表中给出了一下定义:
True Positives (TP):预测为Positive,实际为Positive的样本的数量。即:被正确识别的正样本的数量。
True Negatives (TN):预测为Negative,实际为Negative的样本的数量。即:被正确识别的负样本的数量。
False Positives (FP):预测为Positive,实际为Negative的样本的数量。即:被错误识别为正样本的负样本数量。
Fasle Negatives (FN):预测为Negative,实际为Positive的样本的数量。即:被错误识别为负样本的正样本的数量。
基于混淆矩阵,可以定义如下评估指标:
Accuracy: 被正确预测的样本占全部测试样本的比例。
![]()
Precision(查准率):被预测为正样本中实际为正样本所占的比例。

Recall(查全率):测试集中所有正样本,被正确预测为正样本的比例。

F1-score: 是precision和recall的调和均值,即:
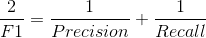
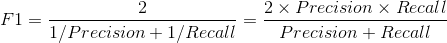
Precision-Recall (P-R)曲线:根据学习器的预测结果对样例进行排序,排在前面的是学习器认为“最可能”是正例的样本;排在租后的则是学习器认为“最不可能”是正例的样本。按此顺序,逐个将样本作为正例进行预测,则每次可以计算出当前的查全率recall和查准率precision。以recall为横轴,precision为纵轴,可以得到P-R曲线。Average Precision (AP)的值等于P-R曲线下的面积。
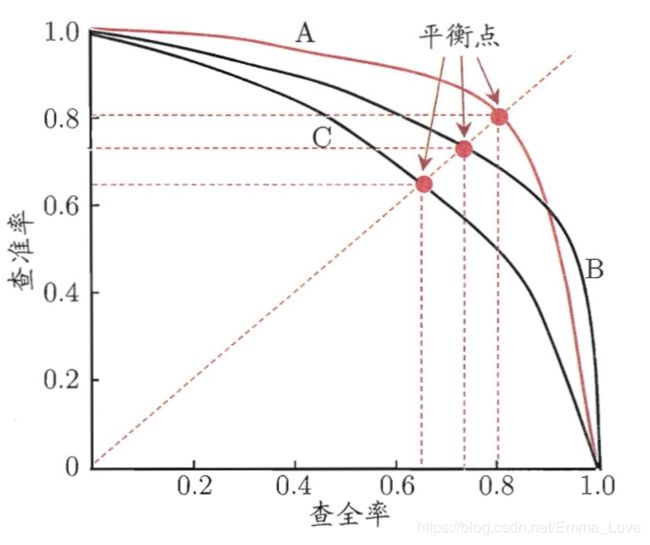
如果一个分类器的性能比较好,那么它应该有如下的表现:在Recall值增长的同时,Precision的值保持在一个很高的水平。而性能比较差的分类器可能会损失很多Precision值才能换来Recall值的提高。通常情况下,文章中都会使用Precision-recall曲线,来显示出分类器在Precision与Recall之间的权衡。
2. 交并比IoU (Intersection over Union)
IoU即:Intersection over Union,是目标检测中的一个衡量指标。
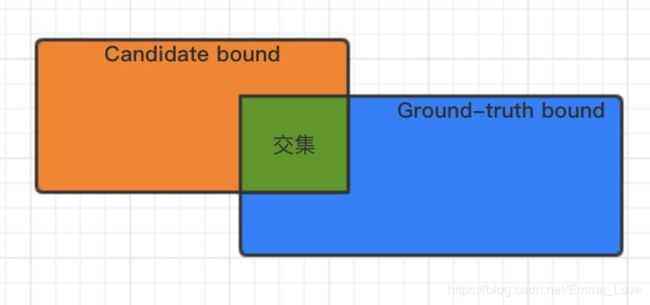
IoU表示产生的候选框(Candidate bound)与真实标记框(ground truth boudn)的重叠度,即:二者的交集与并集的比值。IoU越高,二者的相关度越高。最理想情况是候选框与真实标记框完全重合,即IoU=1。
计算公式为:

3. 非极大值抑制NMS (Non-Maximum Suppression)
NMS是目标检测框架中的后处理模块,主要用于删除高度冗余的bounding box。
NMS的算法基本步骤:
(1). 将所有检出的output_bbox按cls score划分(如pascal voc分20个类,也即将output_bbox按照其对应的cls score划分为21个集合,1个bg类,只不过bg类就没必要做NMS而已);
(2)遍历每个集合,对每个集合单独进行如下计算:
(2)-1: 在每个集合内根据各个bbox的cls score做降序排列,得到一个降序的list_k;
(2)-2: 从list_k中第一个元素开始,计算该元素与list_k中其他的元素 之间的IoU,若IoU大于阈值,则剔除元素,否则,暂时保留。
(2)-3: 选择list_k中的第二元素,中被保留下的元素,重复进行(2)-2操作,直至所有元素都完成筛选
(2)-4: 最后,对每个集合的list_k,重复(2)-2、3中的迭代操作,直至所有list_k都完成筛选;
NMS的算法流程示例图:
NMS的实现:(摘自Fast R-CNN的实现)
# --------------------------------------------------------
# Fast R-CNN
# Copyright (c) 2015 Microsoft
# Licensed under The MIT License [see LICENSE for details]
# Written by Ross Girshick
# --------------------------------------------------------
import numpy as np
def py_cpu_nms(dets, thresh):
"""Pure Python NMS baseline."""
x1 = dets[:, 0] # pred bbox top_x
y1 = dets[:, 1] # pred bbox top_y
x2 = dets[:, 2] # pred bbox bottom_x
y2 = dets[:, 3] # pred bbox bottom_y
scores = dets[:, 4] # pred bbox cls score
areas = (x2 - x1 + 1) * (y2 - y1 + 1) # pred bbox areas
order = scores.argsort()[::-1] # 对pred bbox按score做降序排序,对应(2)-1
keep = [] # NMS后,保留的pred bbox
while order.size > 0:
i = order[0] # top-1 score bbox
keep.append(i) # top-1 score的话,自然就保留了
xx1 = np.maximum(x1[i], x1[order[1:]]) # top-1 bbox(score最大)与order中剩余bbox计算NMS
yy1 = np.maximum(y1[i], y1[order[1:]])
xx2 = np.minimum(x2[i], x2[order[1:]])
yy2 = np.minimum(y2[i], y2[order[1:]])
w = np.maximum(0.0, xx2 - xx1 + 1)
h = np.maximum(0.0, yy2 - yy1 + 1)
inter = w * h
ovr = inter / (areas[i] + areas[order[1:]] - inter) # IoU计算
inds = np.where(ovr <= thresh)[0] # 这个操作可以对代码断点调试理解下,结合(2)-2,我们希望剔除所有与当前top-1 bbox IoU > thresh的冗余bbox,那么保留下来的bbox,自然就是ovr <= thresh的非冗余bbox,其inds保留下来,作进一步筛选
order = order[inds + 1] # 保留有效bbox,就是这轮NMS未被抑制掉的幸运儿,为什么 + 1?因为ind = 0就是这轮NMS的top-1,剩余有效bbox在IoU计算中与top-1做的计算,inds对应回原数组,自然要做 +1 的映射,接下来就是的循环
return keep # 最终NMS结果返回4. 每秒帧率FPS (Frame Per Second)
除了检测准确度,目标检测算法的另一个重要评估指标是速度,只有速度快,才能够实现实时检测。FPS用来评估目标检测的速度。评估速度的常用指标是每秒帧率(Frame Per Second,FPS),即每秒内可以处理的图片数量。当然要对比FPS,你需要在同一硬件上进行。另外也可以使用处理一张图片所需时间来评估检测速度,时间越短,速度越快。