文本分类——NLV算法研究与实现
内容提要
- 1 引言
- 2 NLV算法理论
- 2.1 训练模型
- 2.2 分类模型
- 3 NLV算法实现
- 3.1 算法描述
- 4 实验及性能评估
- 4.1 实验设计
- 4.1.1 实验环境
- 4.1.2 数据集
- 4.1.3 实验目标
- 4.1.4 关于预处理
- 4.2 实验说明
- 4.3 实验结果
- 4.3.1 选参前提实验
- 4.3.2 NLV分类实验
- 4.3.3 分类对比实验
- 5 分析总结
1 引言
分类器的分类效率是衡量分类器性能的一项重要指标。为了提高分类的效率,本文将表示训练集文本的向量空间模型矩阵压缩成二维的归一化向量(Normalized Vector, NLV),通过特征向量进行未标注文本的类别识别。NLV算法时间复杂度比较低,分类速度将得到明显提高。下面将具体描述NLV算法的理论基础及算法的实现过程。
本文通过归一化思想提出一种文本分类算法。训练过程将三维向量空间模型压缩成二维的归一化特征向量。描述了两种用来调整归一化特征向量的特征权重的归一化函数。分类过程采用未标注文本与训练生成的归一化特征向量的相似度进行类别判断。相似度可以采用向量内积或夹角进行计算
2 NLV算法理论
2.1 训练模型
经过特征选择算法选择出作为分类特征之后,就进入分类器构建的过程。分类器一般分为训练和分类两个过程。训练就是从已标注数集构建分类模型。归一化向量算法针对每一个类别,将选出来的特征重新计算特征频率(Feature Frequency,FF),然后对所计算的类别特征向量进行归一化变换,生成用于分类或分类预测的归一化向量。
特征频率的计算类似于词频,本文区分词频与特征频率,特征频率是从已选择的特征角度考虑。文本di 的特征fk 的特征频率指特征fk 出现的次数比上文本di 的含有的特征总数,计算如式:

其中: Njk 表示特征fk 在文本di 中出现的次数,Nj 表示文本di 中出现的特征总数。类别ci 的特征fk 的平均特征频率如式:

其中 m 代表训练集类别ci 的文本数量,平均词频更好的描述了一个特征fk 的综合重要程度,并且可以比较好地中和或抵消噪声数据对分类结果的影响。
类别ci 的归一化特征向量表示为 NLVi = (wi1,wi2, …,win) ,wik 表示特征*fk*的归一化权重。 wik 的计算可以有多种方式。为了使用一个归一化向量恰当地表示一个类别所有文本,本文采用平均特征频率来衡量一个特征的权重。特征权重的一般表示形式如式:
其中 Φ(x) 称为归一化函数(Normalized Function, NLF)。根据归一化思想的要求,本文提出两种方式的归一化函数,一种“方根型”归一化函数,另一种“对数型”归一化函数。
1) 方根型NLF
方根型归一化函数采用方根变换调整平均特征频率计算权重。计算如下式所示:
其中 η 为根指数,一般取自然数。将平均特征频率代入上式得归一化向量特征权重的计算形式如下式所示:

2) 对数型NLF
对数型归一化函数采用对数变换调整平均特征频率计算权重。计算如下式所示:
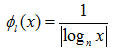
将平均特征频率代入上式得到归一化向量特征权重的计算形式如下式所示:
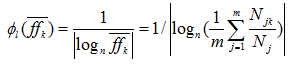
一般取自然对数就可以得到比较理想的分类效果。上式可以转化为式:
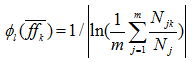
只经过计算平均特征频率所得到的权重差异比较大,低频词对分类的贡献相对较低。为了平衡特征权重,采用归一化函数缩小高频词和低频词的权重差距。本文提出的归一化方法的归一化思想主要体现在两个方面。一方面是将训练集类别空间的文本生成归一化的特征向量,相当于三维空间变换成二维。归一化的另一个方面就是归一化函数变换特征频率,缩小特征权重差距。不同 η 的方根型NLF函数 y= Φr(x) 的曲线如图1所示:
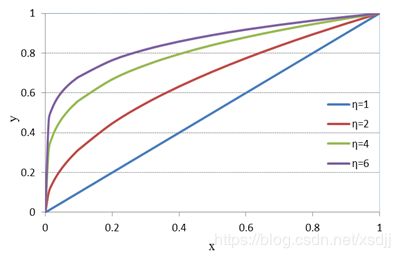
由于特征频率满足 0≤ffjk≤1,从图4.1可以看出,在x靠近0时 y= Φr(x) 增幅明显,并且随着 η 的增大, y= Φr(x) 的值调整不断加大,并趋向于1,但是仍然保持原有递增趋势。归一化函数目的保持相对差异并且将权重归化趋于1。这样可以保持高频词的分类能力并加强低频词的分类能力。
对数型归一化函数虽然不是严格在[0,1]区间上趋于1,但是在实际应用中的特征频率区间上能够表现出归一化特性。
2.2 分类模型
通过判断未标注文本与已经训练出来的特征归一化向量的距离或相似度来判断未标注文本的类别。NLV算法相似度(Similarity)可以采用向量的内积或两向量的夹角。设未标注文本为 dx , dx 的VSM表示形式 dx=(wx1,wx2,…,wxn) 采用词频作为权重。
1) 内积(Inner Product,IP) 型相似度
未标注文本 dx 与归一化向量 dx=(wx1,wx2,…,wxn) 的内积型相似度计算如下式所示:
将 dx 与 NLVi 代入上式,得到最终内积型相似度计算如下式所示:
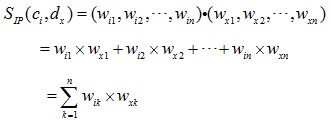
2) 夹角(Included Angle,IA)型相似度
夹角型相似度认为两文本向量越接近,其向量夹角 θ 越小;而夹角 θ 越小, θ 的余弦值越大。向量夹角的余弦值很容易用两个向量表示出来。未标注文本 dx=(wx1,wx2,…,wxn) 与归一化向量 NLVi = (wi1,wi2, …,win) 的夹角型相似度计算如下式所示:
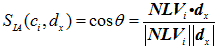
将 dx 与 NLVi 代入上式,得到最终夹角型相似度计算如下式所示

文本 dx 最终所属类别为与类别归一化向量相似度最大的类别标签。文本 dx 的内积型分类结果如下式所示:
文本 dx 的夹角型分类结果如下式所示:
即文本 dx 的类别就是与其最相似的类别归一化向量的类别。
3 NLV算法实现
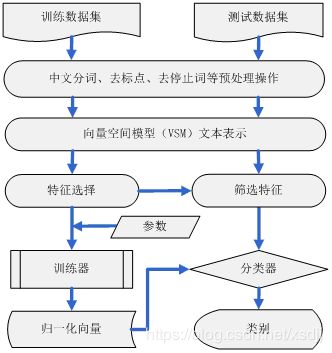
NLV文本分本分类算法建立文本与类别之间的映射的过程如图2所示。分为训练和分类两个主过程,仅针对训练集进行特征选择。分类过程中未标注文本从已选择的特征中进行特征筛选,与特征选择是两个不同的过程。训练过程主要输出用于分类的归一化向量,并且模型建立一次,可以多次用于分类。
3.1 算法描述
名称:NLV文本分类算法
输入:训练集文本语料,测试集文本语料或未标注文本;
输出:分类结果、混淆矩阵或文本类别标注;
步骤:
- 文本预处理:对中文文本进行中文分词处理,对英文文本进行词根还原,删除停止词、标点符号等;
- 文本表示:采用向量空间模型(VSM)表示文本;
- 特征选择:对训练集进行特征选择操作,特征选择可以采用矩阵投影(MP)、信息增益(IG)、卡方校验(CHI)、文档频率(DF)、互信息(MI)等;
- 训练学习过程:根据训练集文本语料,计算类别 ci 的特征 fk 的平均特征频率 ffik–,采用归一化函数对 ffik– 进行归一化变换,计算类别 ci 的特征 fk 的归一化向量权重并用权重表示出归一化的类别特征向量;
- 特征筛选:对未标注文本进行特征筛选,建立未标注文本特征向量空间模型;
- 分类测试过程:计算未标注文本与所有分类系统类别的归一化特征向量的相似度,根据相似度标注文本的类别;
- 性能评估:输出分类结果、混淆矩阵或文本类别标注;算法结束。
4 实验及性能评估
文本分类作为数据挖掘、信息检索的重要研究内容,其算法要通过真实的数据集检验测试才能评价其实用价值。本章从多个角度分别对特征选择方法和文本分类算法进行对比实验。
4.1 实验设计
为了实验设计的合理性、可靠性与全面性,本文实验将采用两种语种(英文和中文)的三套数据集,英文一套,中文两套,每套都包含一万篇以上文本,规模较大;而且数据集的平衡性都不相同,分别为非常不平衡、较平衡和严格平衡。采用多种特征选择算法与多种文本分类算法进行对比试验。
相同的文本分类算法在不同的软硬件环境下实验,理论上分类的精度应该没有差异,然而训练和分类的时间会有所区别。不同的软硬件环境测试的时间性能值有所差别,但是相对结果应该保持一致。为了明确实验中时间性能的测试条件,首先描述本文实验的测试环境。
4.1.1 实验环境
a) 硬件环境
CPU:Core,2.67GHz
内存:4.0G
硬盘:7200转/分钟
b) 软件环境
语言环境:Java语言平台
IDE工具:MyEclipse、NetBeans
4.1.2 数据集
本文实验采用文本分类常用的三套语料库。英文采用麻省理工学院(MIT)的 Jason Rennie 处理过形成的20_Newsgroups-18828。中文采用中科院的TanCorpV1.0和搜狗实验室文本分类语料的完整版SogouC中的20000篇文本,构成SogouC-20000语料库。其中20_Newsgroups-18828为较平衡语料,TanCorpV1.0为非平衡语料,SogouC-20000为严格平衡语料。三套语料库规模都比较大,能够比较好的测试训练与分类的时间性能。
为了便于实验结果显示,20_Newsgroups中类别采用类别名简写标记。语料20_Newsgroups、TanCorpV1.0、SogouC20000的类别分布如表1、2、3所示:



通过上述三个表可以看出20_Newsgroups共有20个类别,每类文本比例比较接近。TanCorpV1.0共有12个类,最多的“电脑”类占20.8%的语料,而最少的“地域”类,只占1.06%的语料,可以看出TanCorpV1.0语料分布非常不平衡。SogouC20000共有10个类,每类正好占10%,即每类2000篇文本,属于严格平衡语料。
为了便于实验,本文采用多种数据集划分方式。本文所有测试均为开放测试,即训练集与测试集互异。由于kNN和SVM算法时间复杂度相对较高,参数选优在全部数据集上,花费时间很多。尤其是选参要做几十到几百次的实验。用于kNN和SVM参数选优的数据集划分方式(1)如表4所示:

为了便于对比各种算法的训练和分类时间,分别采用三种数据集的1:1划分,用于实际分类和算法对比的数据集划分方式(2)如下表5所示:

4.1.3 实验目标
一般评价文本分类的性能仅考虑分类的精度,没有考虑训练学习与分类的时间,这是一种较片面的评估方式。面向Web应用的文本分类算法不仅需要较高的分类精度,也需要高效的训练、分类速度。
本文实验的主要目标包括以下几方面:
- 测试相关算法的参数对分类精度或时间性能的影响;
- 在不同的数据集上,采用多种特征选择方法选择特征,对比测试本文提出的归一化向量(NLV)算法与其他文本分类算法(k近邻、两种朴素贝叶斯、支持向量机)的分类性能;
- 测试不同分类算法与特征维度之间分类结果变化关系;
- 测试不同文本分类算法的训练学习与分类的时间性能(本文中的所有时间数据都不包括预处理、中文分词、特征选择时间,只包括加载数据时间、训练和分类时间);
4.1.4 关于预处理
英文语料20_Newsgroups不采用词根还原,中文语料TanCorpV1.0的采用中科院的ICTCLAS分词系统已经分好词的语料。SogouC20000采用极易分词组件分词。中英文语料都进行停止词去除操作
4.2 实验说明
由于kNN是分类性能较好的分类器,Naïve Bayes是最直接有效的启发式学习算法之一,分类效果也较好, SVM是目前公认分类效果最好的分类器[参见文献]。所以采用kNN、Naïve Bayes与SVM方法与NLV算法进行对比实验。
本文实验中,kNN分类算法的特征项权重采用词频-倒排文档频率(TF-IDF)方式进行计算。文本 dj 的特征项 fk 的权重计算如式:

其中 tfjk 表示文本 dj 的特征项 fk 出现的次数,|N| 表示训练集文本总数,|Nk| 表示训练集中出现特征项 fk 的文本数量。测试集文本没有文档频率,因此其特征项的权重IDF部分来源于训练集。kNN中未标注文本与训练集文本之间的相似度采用向量夹角形式就算。
kNN分类算法计算未标注文本与每一篇训练集文本之间的相似度,然后根据相似度大小选出最大的k篇训练集文本,从这k篇训练集文本中统计出最多的类别标签作为未标注文本的类别输出。一般的做法是未标注文本与一篇训练集文本计算完相似度,再去和下一篇训练集文本计算相似度,本文称此种方法为普通kNN实现算法。
朴素贝叶斯分类方法采用卡内基梅隆大学McCallum 和 Nigam 提出的两种贝叶斯分类模型:多重伯努利朴素贝叶斯(简记:MBNB)和多项式朴素贝叶斯(简记:MNNB) 。
支持向量机分类器采用台湾大学林智仁(Chih-Jen Lin)博士开发的LibSVM软件包。LibSVM是一款优秀、快速有效的通用SVM 工具包,可以使用C-SVC或n-SVC解决各种机器学习中的分类问题,使用e-SVR或n-SVR解决回归等数据挖掘问题。工具包提供了四种常用的核函数包括:线性、多项式、径向基和S形函数。
4.3 实验结果
4.3.1 选参前提实验
前提实验用于验证实验中相应分类算法的性能或参数的选择。主要测试两种kNN实现算法的训练和分类时间,kNN算法中k值对分类结果的影响和SVM算法中最佳参数的寻找。
1) kNN算法中参数k值对分类的影响
kNN分类算法分类过程相对来说比较花费时间,尤其是维数比较高的情况。由于测试次数较多,为了便于对比不同k值对k近邻算法的分类影响,采用数据集划分方式(1)。三种数据集都采用卡方校验(CHI)特征选择方法。三种数据集子集上,不同特征维度下k值对kNN算法的分类影响如图4.1、4.2、4.3所示:

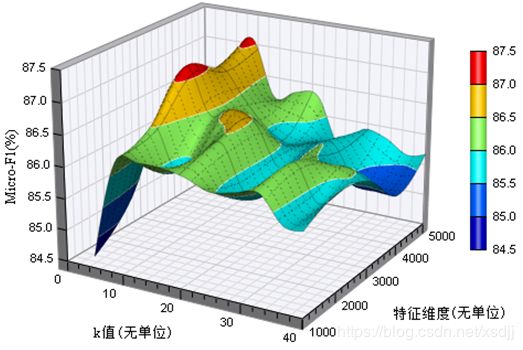

TanCorpV1.0子集分类精度受k值影响较大,特征维度对分类精度的影响相对较小。当k取得10左右时候,能够取得较好的分类结果。TanCorpV1.0子集这种波动性可能是由于语料的不平衡性造成的。SogouC20000子集受k值和特征维度的影响都较大,随着k值和特征维度的增大,分类精度整体呈升高趋势。
为了在一定程度上避免k值投票平局现象,一般将k值设置为奇数。根据上述实验曲面图我们分别设定不同数据集的k近邻算法的k值如表6所示:

2) SVM算法参数寻优
林智仁(Chih-Jen Lin)博士对如何使用LibSVM工具包给出了很多指导性的建议,其中建议读者使用工具包进行分类的步骤如下:
1) 将数据转换成LibSVM工具包的格式;
2) 对数据进行简单的缩放处理(scaling);
3) 考虑使用径向基(RBF)核函数;
4) 使用交叉验证(cross-validation)在数据子集上寻找最优的参数C与γ;
5) 使用最优参数C与γ来训练整个训练数据集;
6) 对整体测试集进行测试实验。
工具包中提供了用于寻找RBF核函数分类最优参数的工具。
LibSVM作者另外提醒:数据集的规模会影响最佳参数的选择,但在实践中,从交叉验证中获得的最佳参数已经适用于整个训练集。
由于SVM算法时间复杂度比较高,尤其在大规模数据集上,收敛速度更慢,根据LibSVM作者的建议我们选择径向基(RBF)作为SVM的核函数在数据集的子集上进行参数寻优。选择径向基(RBF)作为核函数的SVM分类精度主要受惩罚因子C和核函数参数γ的影响。参考LibSVM中参数寻优的过程,本文做参数寻优实验采用C-SVC类型的SVM。LibSVM中惩罚因子C用c表示,核函数中的γ用g表示。为了表示参数变化区间及步长,分别用 log2c 和 log2g 作为惩罚因子C和核函数参数γ的输入。例如 log2c=2 ,就是惩罚因子 C=4。
为了清晰分辨最优分类精度结果的分布,本实验采用色阶表形式显示分类精度。 在三套语料集子集上的SVM算法的参数C和γ的变化对分类精度(微平均F1)的影响如色阶表7、8、9所示:
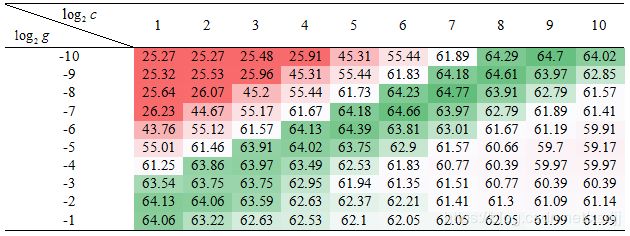
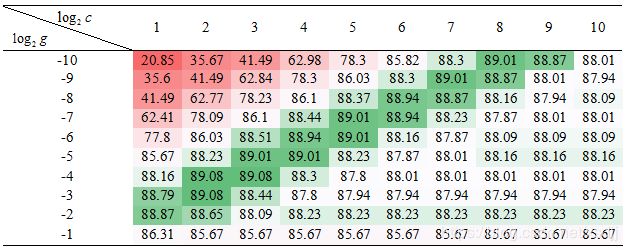
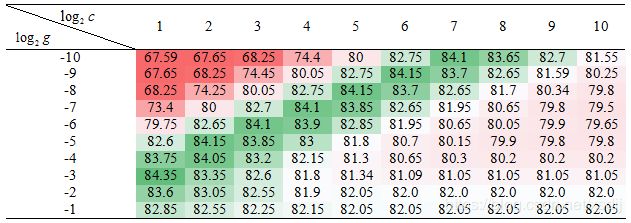
SVM参数选优实验中特征选择方法为卡方校验(CHI),特征维度为1000, 采用数据集划分方式(1)。通过色阶表7-9可以观察三种数据集子集上的SVM最优值分布在一条对角线区域上。选择绿色区域中间位置对应的 log2c 和log2g 值作为SVM分类的参数。三种数据集RBF核SVM的C和γ参数值选择如下:
a) log2c=5 ,即C=32;
b) log2g=-6 ,即γ≈0.016。
4.3.2 NLV分类实验
本小节在三种语料库数据集划分方式(2)上验证NLV算法的分类效果。分别包括两种归一化函数(方根型与对数型)与两种相似度(内积型与夹角型)计算方式的结合。NLV算法的组合方式与缩写表示如表10所示:

本小节试验中的特征选择方法都是卡方校验(CHI),采用数据集划分方式(2)。
1) 四种组合方式NLV分类对比
根指数设为6,在三种数据集上的四种组合方式的NLV算法分类精度(宏平均F1)如图4.4-4.6所示:

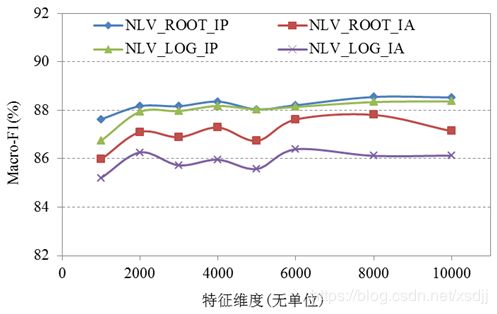

从图4.4-4.6看以观察到,四种组合方式的NLV算法在三种数据集上的分类效果都比较理想。内积型相似度的优势相对明显。整体来说分类精度优劣排序如下:
a) 归一化函数(NLF):方根型(ROOT)>对数型(LOG);
b) 相似度(Similarity):内积型(IP)>夹角型(IA);
c) 组合方式:NLV_ROOT_IP>NLV_LOG_IP>NLV_ROOT_IA>NLV_LOG_IA。
本文以下部分全部采用方根型(ROOT)归一化函数和内积(IP)相似度进行归一化算法(NLV_ROOT_IP)实验,统一用NLV表示。
2) NLV算法中根指数(η )对分类精度影响
合适的根指数(η)在一定程度上能够提高NLV算法的分类精度。在三种数据集上 η 对方根型NLV分类精度影响等值线如图4.7-4.9:

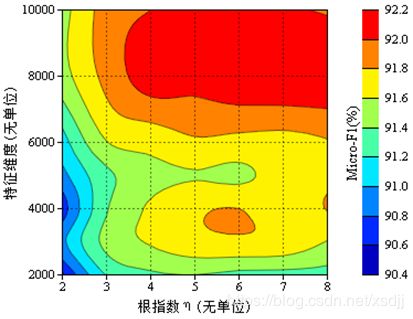
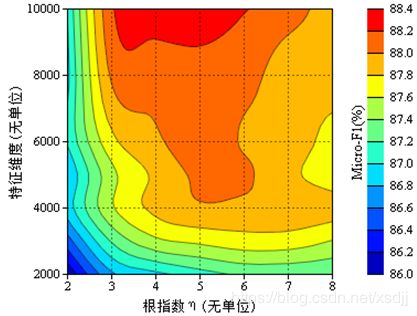
从图4.7-4.9可以发现,根指数 η 对分类精度(微平均F1)的影响也比较明显,尤其是在20_Newsgroups数据集上,但是这种变化趋势比较稳定,随着 η 的增加,分类精度先上升后稍微下降。一般在 η 取值为5和6时,三种数据集都能取得最好的分类结果。kNN算法中的参数k不如NLV算法中的根指数 η 稳定,在不同的数据集上取得最优分类精度的k值变化较大。
本文后续部分实验中NLV算法根指数 η 未加特殊说明的,都设置成6。
3) NLV分类混淆矩阵
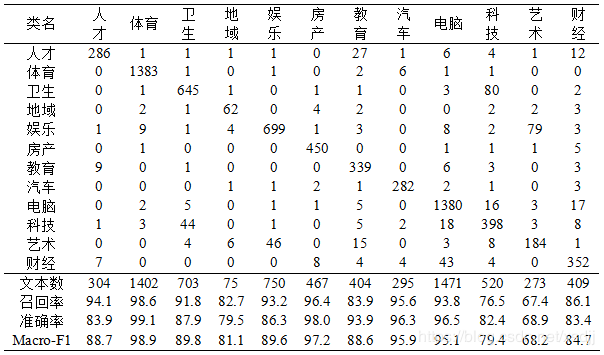
为了进一步观察NLV算法在数据集上的具体类别上分类识别效果,将三种数据集上的一次分类混淆矩阵结果显示如表11,12所示。
观察表11可以看出在非平衡数据集TanCorpV1.0上分类精度也比较好。只有类别色彩不明显的“文化”和“科技”类别错误率比较高。这本身也是由于很多文本具有多类别性造成。像类别色彩分明的类“体育”类,F1值可以达到98.9%。
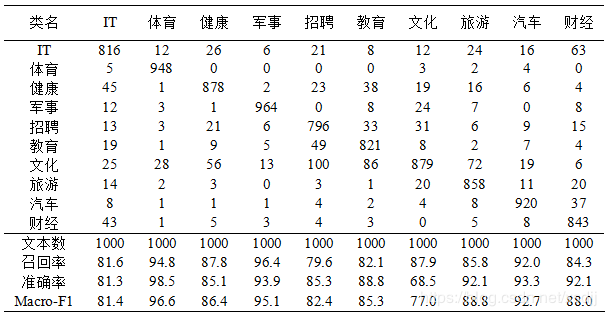
通过表12,可以看到SogouC20000数据集在具有多类型的类别上分类效果不够理想。对于类别独立性比较好的类别“体育”、“军事”,分类效果较好。
许多文本内容具有多类别色彩,并且数据集的类别也是人为划分,同样一篇文本,例如假设一篇短文本“姚明今年第一季度广告收入5000万,超过一线大牌电影明星。”,一个人可能归为“体育”类,另外一个人可能归为“财经”类,或许换一个人就把它归为“娱乐”类。在真实的数据集上做到100%正确率是不现实的,也几乎是不可能的。
4.3.3 分类对比实验
通过实验可以看出卡方校验(CHI) 和矩阵投影(MP)特征选择方法都比较有效,本节仍然选用经典的卡方校验(CHI)特征选择方法在三套数据集上对比各种分类方法的分类性能。采用数据集划分方式(2)。
1) 20_Newsgroups数据集分类对比
数据集20_Newsgroups上五种分类算法的分类精度(宏平均F1)对比如图4.10所示:
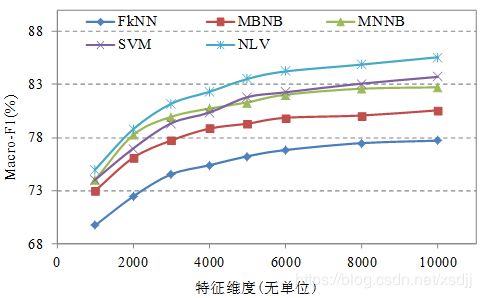
观察图4.10 可以看出在20_Newsgroups数据集上NLV算法取得最好的分类精度结果。SVM和MNNB分类精度相当,最差的是kNN算法。
由于不同算法时间性能差异较大,为了便于观察不同算法的训练和分类时间,采用两个图显示20_Newsgroups数据集上不同算法的训练时间和分类时间性能如图4.11、4.12所示:

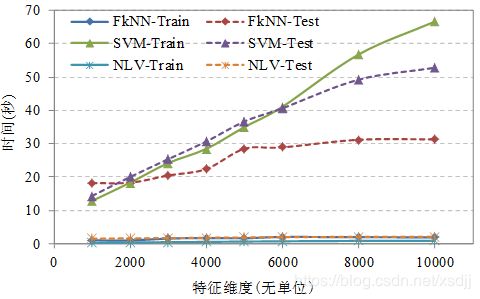
从图4.11可以看出NLV和NB分类方法训练时间非常相近,都比较低;而分类时间NLV比NB低,也就是说NLV分类速度比较快。并且随着维度的增加,NLV算法的训练时间和分类时间增加的较小。
从图4.12可以看出NLV和kNN分类方法训练时间比较相近;而分类时间NLV比kNN和SVM要低很多,NLV分类速度与kNN和SVM相比非常快。随着维度的增加,kNN和SVM算法的训练时间和分类时间增加的非常快,而NLV算法几乎成为一条平行线。
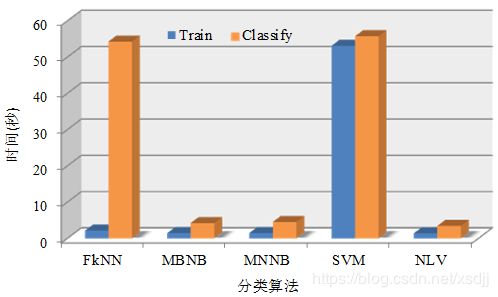
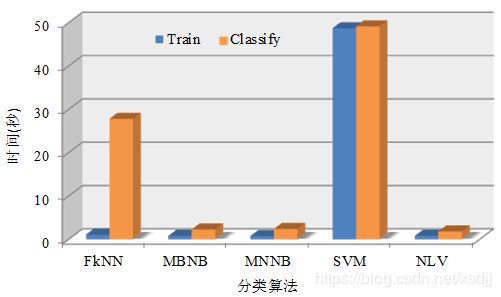
采用柱状图4.13形式统一对比五种分类算法在特征维数5000时的时间性能。
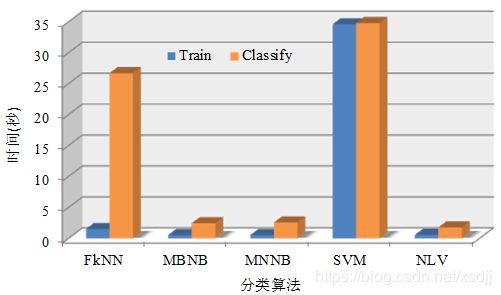
从图4.13可以看出NLV算法的训练时间和分类时间都是最低的。NB方法的训练和分类时间相对也比较低,kNN只有分类时间比较高,而SVM算法无论是训练还是分类,时间消耗都很大。
2) TanCorpV1.0数据集分类对比
数据集TanCorpV1.0上五种分类算法的分类精度(宏平均F1)对比如图4.14所示:
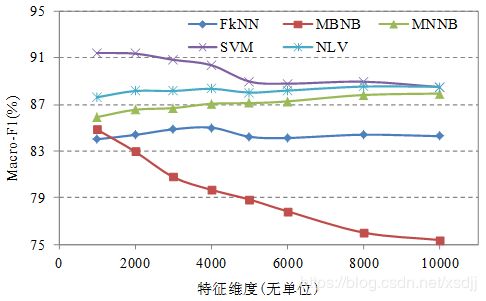
观察图4.14 可以看出在TanCorpV1.0数据集上SVM算法取得最好的分类精度结果。NLV算法分类效果仅次于SVM算法而优于NB和kNN算法,分类效果最差的是MBNB算法。
TanCorpV1.0数据集上不同算法的训练时间和分类时间性能如图4.15、4.16和4.17所示:
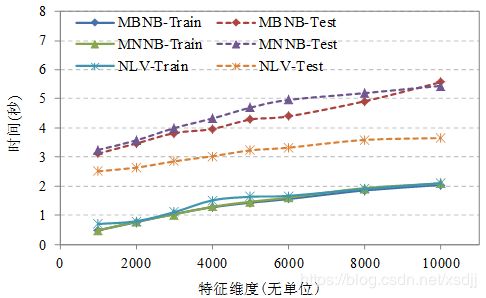
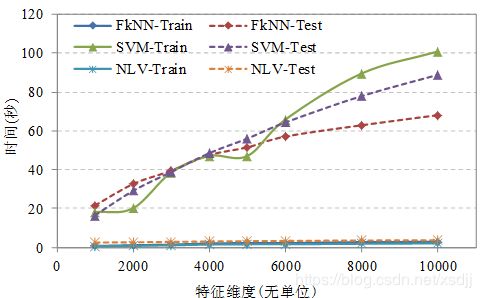
观察图4.14-4.17可以发现TanCorpV1.0数据集上的分类时间性能与20_Newsgroups数据集一致。NLV训练和分类速度都是最快的,而SVM的训练和分类速度都是最慢的。
3) SogouC20000数据集分类对比
数据集SogouC20000上五种分类算法的分类精度(宏平均F1)对比如图4.18:
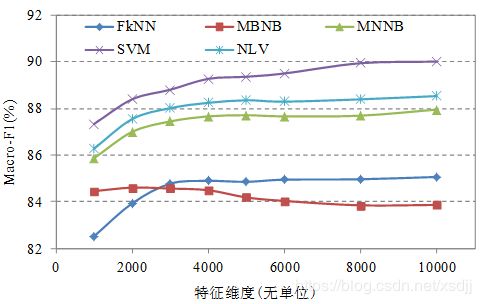
观察图4.18可以看出在SogouC20000数据集上也是SVM算法取得最好的分类精度结果,其次是NLV分类算法,MNNB算法仅次于NLV算法,分类效果最差的是kNN、MBNB算法。
SogouC20000上不同算法的训练时间和分类时间性能如图4.19、4.20和4.21:

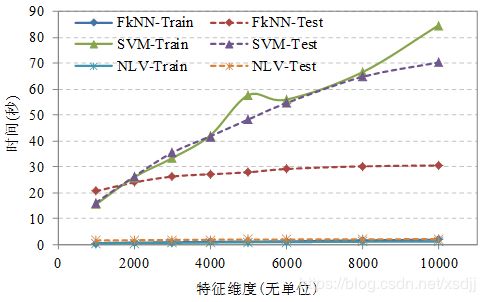
从图4.19-4.21仍然能够发现,NLV算法的训练时间和分类时间都最低,时间性能最佳,SVM训练和分类时间最高,时间性能最差。
5 分析总结
通过三种不同的较大规模数据集详细而全面地验证了本文提出的NLV分类算法的通用性和有效性。并分别与多种特征选择和文本分类算法做了对比实验,不仅考虑了分类的精度(宏平均F1和微平均F1),而且也对时间性能做了充分的对比验证。
NLV分类算法分别与kNN、MBNB、MNNB和SVM分类算法做了大量的对比实验。通过全面而详细的实验,我们得到如下分类性能,时间性能采用分类速度形式比较:
- 20_Newsgroups数据集
a) 分类精度:NLV > SVM > MNNB > kNN >= MBNB
b) 训练速度:NLV ≈ MNNB ≈ MBNB > kNN >> SVM
c) 分类速度:NLV > MNNB ≈ MBNB >> kNN >= SVM - TanCorpV1.0数据集
a) 分类精度:SVM > NLV > MNNB > kNN > MBNB
b) 训练速度:NLV ≈ MNNB ≈ MBNB > kNN >> SVM
c) 分类速度:NLV > MNNB ≈ MBNB >> kNN >= SVM - SogouC20000数据集
a) 分类精度:SVM > NLV > MNNB > MBNB > kNN
b) 训练速度:NLV ≈ MNNB ≈ MBNB > kNN >> SVM
c) 分类速度:NLV > MNNB ≈ MBNB >> kNN >= SVM
通过实验数据我们可以看出两套语料库上SVM精度最高,紧随其后的是NLV算法,可见SVM算法分类精度确实优秀,而在英文语料20_Newsgroups上NLV取得最优结果。不过SVM的时间性能是最差的,三套语料库上,NLV的训练和分类速度是SVM的20到50倍。其中NLV算法中统计的时间主要是加载数据(读取硬盘数据)的时间,本质来讲加载数据的时间不应该考虑到训练和分类的时间中,如果去掉加载数据的时间,NLV的训练和分类速度比SVM至少高2个数量级。
| 知更鸟博文推荐 | |
|---|---|
| 上一篇 | 特征选择——Matrix Projection算法研究与实现 |
| 下一篇 | 文本分类——快速kNN设计实现 |
| 推荐篇 | 基于Kubernetes、Docker的机器学习微服务系统设计——完整版 |
| 研究篇 | RS中文分词 | MP特征选择 | NLV文本分类 | 快速kNN |
| 作者简介 | |
| 兴趣爱好 | 机器学习、云计算、自然语言处理、文本分类、深度学习 |
| [email protected] (欢迎交流) | |
参考文献
[1] Croft, W. B., Metzler, D., Strohman, T. Search Engines: Information retrieval in practice [M]. New Jersey:Addison-Wesley,2010.
[2] 王素格,李德玉,魏英杰.基于赋权粗糙隶属度的文本情感分类方法[J].计算机研究与发展,2011,48(5):855-861.
[3] 宗成庆. 统计自然语言处理[M].北京:清华大学出版社,2008.
[4] Sebastiani,F. Machine learning in automated text categorization [J]. ACM Comput. Surv. 2002, 34(1): 1-47.
[5] McCallum,A.,Nigam,K. A comparison of event models for naive Bayes text classification [C]. In: Proc. of the AAAI ’98 Workshop on Learning for Text Categorization. 1998: 41 - 48.
[6] 戴新宇,田宝明,周俊生等.一种基于潜在语义分析和直推式谱图算法的文本分类方法LSASGT[J].电子学报,2008,36(8):1626-1630.
[7] Vapnik,V. N. The nature of statistical learning theory [M]. 2nd ed. New York : Springer-Verlag,2000.
[8] Tan,S. B.,Cheng,X. Q.,Ghanem,M. M.,Wang,B.,Xu,H. B. A novel refinement approach for text categorization [C]. In: ACM CIKM,2005.
[9] Zhang,H. The optimality of Naive Bayes [C]. In: Proceedings of the 17th Int’l FLAIRS Conference, American Association for Artificial Intelligence. Miami Beach: AAAI Press, 2004: 562–567.
[10] Lin C. J. A practical guide to support vector classification [DB/01].
[11] 陈立孚,周宁,李丹.基于机器学习的自动文本分类模型研究[J]. 现代图书情报技术,2005,21(10):23-27.
[12] 邱江涛,唐常杰,曾涛,刘胤田.关联文本分类的规则修正策略[J].计算机研究与发展,2009,46(4):683- 688.