语音识别(一)—特征提取
0.数据集选择
1.THCHS30 清华数据集 中文 6.7G
2.librispeech 30G
1. 特征提取
1.1 读取数据 wav & librosa
import scipy.io.wavfile as wav
import matplotlib.pyplot as plt
import os
import librosa
import librosa.display
import numpy as np
from scipy.fftpack import fft
filepath = 'data_thchs30/train/A36_246.wav'
fs, wavsignal = wav.read(filepath)
plt.plot(wavsignal)
plt.show()
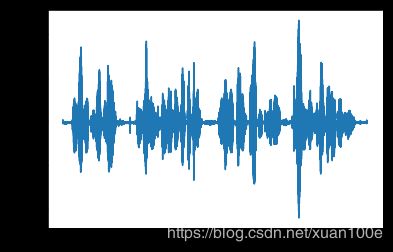
plt.figure()
y,sr = librosa.load(filepath,sr=None)
librosa.display.waveplot(y,sr)
plt.show()

采样点(s) = fs
采样点(ms)= fs / 1000
采样点(帧)= fs / 1000 * 帧长
1.2 MFCC & fbank & fMLLR & cmvn
- 手写fbank
def compute_fbank(file):
x=np.linspace(0, 400 - 1, 400, dtype = np.int64)
w = 0.54 - 0.46 * np.cos(2 * np.pi * (x) / (400 - 1) ) # 汉明窗
fs, wavsignal = wav.read(file)
# wav波形 加时间窗以及时移10ms
time_window = 25 # 单位ms
window_length = fs / 1000 * time_window # 计算窗长度的公式,目前全部为400固定值
wav_arr = np.array(wavsignal)
wav_length = len(wavsignal)
range0_end = int(len(wavsignal)/fs*1000 - time_window) // 10 # 计算循环终止的位置,也就是最终生成的窗数
data_input = np.zeros((range0_end, 200), dtype = np.float) # 用于存放最终的频率特征数据
data_line = np.zeros((1, 400), dtype = np.float)
for i in range(0, range0_end):
p_start = i * 160
p_end = p_start + 400
data_line = wav_arr[p_start:p_end]
data_line = data_line * w # 加窗
data_line = np.abs(fft(data_line))
data_input[i]=data_line[0:200] # 设置为400除以2的值(即200)是取一半数据,因为是对称的
data_input = np.log(data_input + 1)
#data_input = data_input[::]
return data_input
fbank = compute_fbank(filepath)
- librosa & python_speech_features
librosa
if feature == 'fbank': # log-scaled
feat = librosa.feature.melspectrogram(y=y, sr=sr, n_mels=dim,
n_fft=ws, hop_length=st)
feat = np.log(feat+1e-6)
elif feature == 'mfcc':
feat = librosa.feature.mfcc(y=y, sr=sr, n_mfcc=dim, n_mels=26,
n_fft=ws, hop_length=st)
feat[0] = librosa.feature.rmse(y, hop_length=st, frame_length=ws)
feat = [feat]
if delta:
feat.append(librosa.feature.delta(feat[0]))
if delta_delta:
feat.append(librosa.feature.delta(feat[0],order=2))
feat = np.concatenate(feat,axis=0)
if cmvn:
feat = (feat - feat.mean(axis=1)[:,np.newaxis]) / (feat.std(axis=1)+1e-16)[:,np.newaxis]
if save_feature is not None:
tmp = np.swapaxes(feat,0,1).astype('float32')
np.save(save_feature,tmp)
return len(tmp)
else:
return np.swapaxes(feat,0,1).astype('float32') #np.swapaxes 转置
python_speech_features
from python_speech_features import mfcc as pmfcc
m = pmfcc(wavsignal,numcep=40)
m.shape
(980, 26)