大数据学习笔记(一)
一、大数据
大数据(big data),指无法在一定时间范围呢用常规软件工具进行捕捉、管理和处理的数据集合,是需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力的海量、高增长率的多样化的信息资产。
在维克托·迈尔·舍恩伯格及肯尼斯·库克耶编写的《大数据时代》中大数据指不用随机分析法(抽样调查)这样捷径,而采用所有数据进行分析处理。大数据的5V特点(IBM提出):Volume(大量)、Velocity(高速)、Variety(多样)、Value(低价值密度)、Veracity(真实性)。
大数据5V特征: 1、Volume(大体量):即可从数百TB到数十数百PB、甚至EB的规模。 2、Variety(多样性):即大数据包括各种格式和形态的数据。 3、Velocity(时效性):即很多大数据需要在一定的时间限度下得到及时处理。 4、Veracity(准确性):即处理的结果要保证一定的准确性。 5、Value(大价值):即大数据包含很多深度的价值,大数据分析挖掘和利用将带来巨大的商业价值大数据的应用类型大致可分为三类:
1.传统企业数据(Traditional enterprise data):包括 CRM systems的消费者数据,传统的ERP数据,库存数据以及账目数据等。
2.机器和传感器数据(Machine-generated /sensor data):包括呼叫记录(Call Detail Records),智能仪表,工业设备传感器,设备日志(通常是Digital exhaust),交易数据等。
3.社交数据(Social data):包括用户行为记录,反馈数据等。如Twitter,Facebook这样的社交媒体平台。
大数据的应用目标:
利用一系列信息技术实现海量数据条件下的深度洞察和决策智能化,最终走向人工智能融合。
大数据的关键技术:数据科学。
数据科学核心技术:
(1)机器学习(machine learning)
-机器学习是大数据处理承上启下的关键技术
-往上是深度学习、人工智能
-往下是数据挖掘和统计学习
(2)数据挖掘(data mining)
-数据挖掘核心技术来自于机器学习领域
二、数据仓库 Data warehouse
自从1991 年数据仓库之父Bill Inmon 提出了数据仓库概念以来,数据仓库已从早期的探索走向实用阶段,进入了一个快速发展阶段。在此期间,全球经济急速发展,激烈的竞争、企业间频繁的兼并重组,使企业对信息的需求大大加剧,这是数据仓库发展的根本原因。当越来越多的企业开始重视数据资产的价值时,数据仓库也就成为必然的选择。
目前企业面对经济增长减缓和竞争日益激烈的双重压力,为继续保持经济的高速稳定增长,大量的企业面临着减员增效、股份制改造等各种变革,准确、全面的信息是企业变革制胜的法宝。随着经营策略从以产品为中心转变为以顾客为中心,数据的潜在价值正在得到越来越多的关注,企业已经认识到充分地利用信息是应对挑战的关键,数据仓库正成为IT 领域中被关注的热点技术。
信息技术的广泛应用使企业的运营更加高效、灵活,但同时也带来了“数据爆炸”的问题,许多遗留下来的历史数据被束之高阁,人们面对浩如烟海的数据显得手足无措,如何有效地组织和存储数据,把其内部隐藏的信息转化为商业价值,为企业效益提供服务成为决策者们迫切关心的问题。数据仓库作为高效集成、管理数据的技术,为各级决策者洞察企业的经营管理状况,及时发现问题,为提高决策水平提供了基础。目前数据仓库逐渐被越来越多的企业应用。
从数据库到数据仓库,企业的数据处理大致分为两类。一类是操作型处理,也叫联机事务处理(OnlineTransactionProcesssing,OLTP),它是针对具体业务在数据库联机的日常操作,通常对少数记录进行查询、修改。用户较为关心操作的响应时间、数据的安全性、完整性和并发支持的用户数等问题。传统的数据库系统作为数据管理的主要手段,主要用于操作型处理。另一类是分析型处理(OnlineAnalyticalProcesssing,OLAP),一班针对默写主题的历史数据进行分析,支持管理决策。
数据仓库的概念:
从本质上讲,设计数据仓库的初衷是为操作型系统过渡到决策支持系统提供一种工具或整个企业范围内的数据集成环境,并尝试解决数据流相关的各种问题。这些问题包括如何从传统的操作型处理系统中提取与决策主题相关的数据,如何经过转换把分散的、不一致的业务数据转换成集成的、低噪声的数据等。
Bill Inmon 认为数据仓库就是面向主题的(Subject-Oriented )、集成的(Integrated)、非易失的(Non-Volatile)和时变的(Time-Variant )数据集合,用以支持管理决策 。数据仓库不是可以买到的产品,而是一种面向分析的数据存储方案。对于数据仓库的概念可以从两个层次理解:首先,数据仓库用于支持决策,面向分析型数据处理,不同于提高业务效率的操作型数据库;其次,数据仓库对分布在企业中的多个异构数据源集成,按照决策主题选择数据并以新的数据模型存储。此外,存储在数据仓库中的数据一般不能修改。
数据仓库主要有以下特征。
1.面向主题
在操作型数据库中,各个业务系统可能是相互分离的。而数据仓库是面向主题的。逻辑意义上,每一个商业主题对应于企业决策包含的分析对象。从图3.1 中可以看出,一个保险公司的数据仓库的主题可能有顾客、政策、保险金和索赔等。

操作型处理对数据的划分并不适用于决策分析。而基于主题组织的数据则不同,它们被划分为各自独立的领域,每个领域有各自的逻辑内涵但互不交叉,在抽象层次上对数据进行完整、一致和准确的描述。一些主题相关的数据通常分布在多个操作型系统中。
2.集成性
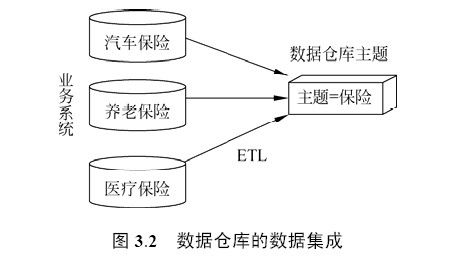
不同操作型系统之间的数据一般是相互独立、异构的。而数据仓库中的数据是对分散的数据进行抽取、清理、转换和汇总后得到的,这样保证了数据仓库内的数据关于整个企业的一致性。图3.2 说明一个保险公司综合数据的简单处理过程,其中数据仓库中与“保险”主题有关的数据来自于多个不同的操作型系统。这些系统内部数据的命名可能不同,数据格式也可能不同。把不同来源的数据存储到数据仓库之前,需要去除这些不一致。
3.数据的非易失性
操作型数据库主要服务于日常的业务操作,使得数据库需要不断地对数据实时更新,以便迅速获得当前最新数据,不至于影响正常的业务运作。在数据仓库中只要保存过去的业务数据,不需要每一笔业务都实时更新数据仓库,而是根据商业需要每隔一段时间把一批较新的数据导入数据仓库。事实上,在一个典型的数据仓库中,通常不同类型数据的更新发生的频率是不同的。例如产品属性的变化通常每个星期更新一次,地理位置上的变化通常一个月更新一次,销售数据每天更新一次。
数据非易失性主要是针对应用而言。数据仓库的用户对数据的操作大多是数据查询或比较复杂的挖掘,一旦数据进入数据仓库以后,一般情况下被较长时间保留。数据仓库中一般有大量的查询操作,但修改和删除操作很少。因此,数据经加工和集成进入数据仓库后是极少更新的,通常只需要定期的加载和更新。
4.数据的时变性
数据仓库包含各种粒度的历史数据。数据仓库中的数据可能与某个特定日期、星期、月份、季度或者年份有关。数据仓库的目的是通过分析企业过去一段时间业务的经营状况,挖掘其中隐藏的模式。虽然数据仓库的用户不能修改数据,但并不是说数据仓库的数据是永远不变的。分析的结果只能反映过去的情况,当业务变化后,挖掘出的模式会失去时效性。因此数据仓库的数据需要更新,以适应决策的需要。从这个角度讲,数据仓库建设是一个项目,更是一个过程 。数据仓库的数据随时间的变化表现在以下几个方面。
(1)数据仓库的数据时限一般要远远长于操作型数据的数据时限。
(2)操作型系统存储的是当前数据,而数据仓库中的数据是历史数据。
(3)数据仓库中的数据是按照时间顺序追加的,它们都带有时间属性。
数据仓库主要包括数据的提取、转换与装载(ETL )、元数据、数据集市和操作数据存储等部分,常用的数据仓库结构如图3.3 所示。

三、分析ETL和挖掘DM的区别
首先,介绍一下ETL 和 DM:
ETL/Extraction-Transformation-Loading——用于完成DB到DW的数据转存,它将DB中的某一个时间点的状态,“抽取”出来,根据DW的存储模型要求,“转换”一下数据格式,然后再“加载”到DW的一个过程,这里需要强调的是,DB的模型是ER模型,遵从范式化设计原则,而DW的数据模型是雪花型结构或者星型结构,用的是面向主题,面向问题的设计思路,所以DB和DW的模型结构不同,需要进行转换。 DM/Data Mining/数据挖掘——这个挖掘,不是简单的统计了,他是根据概率论的或者其他的统计学原理,将DW中的大数据量进行分析,找出我们不能直观发现的规律,比如,如果我们每天早上照相,量身材的时候,还记录下头一天吃的东西,黄瓜,猪腿,烤鸭,以及心情,如果记录上10年,形成了3650天的相貌和饮食心情的数据,我们每个人都记录,有20万人记录了,那么,我们也许通过这些记录,可以分析出,身材相貌和饮食的客观规律;再说一个典型的实例,就是英国的超市,在积累了大量数据之后,对数据分析挖掘之后,得到了一个规律:将小孩的尿布和啤酒放在一起,销量会更好——业务专家在得到该结论之后,仔细分析,知道了原因,因为英国男人喜欢看足球的多,老婆把小孩介绍男人看管,小孩尿尿需要尿布,而男人看足球喜欢喝酒,所以两样商品有密切的关系,放在一起销售会更好
数据分析只是在已定的假设,先验约束上处理原有计算方法,统计方法,将数据分析转化为信息,而这些信息需要进一步的获得认知,转化为有效的预测和决策,这时就需要数据挖掘,也就是我们数据分析师系统成长之路的“更上一楼”
总的来说,挖掘带有价值取向,分析没有价值取向。
四、hadoop
Apache Hadoop软件库是一个框架,允许使用简单的编程模型跨计算机群集分布式处理大型数据集。 它旨在从单台服务器扩展到数千台机器,每台机器提供本地计算和存储。 该库本身不是依靠硬件来提供高可用性,而是设计用于在应用层检测和处理故障,从而在一组计算机之上提供高可用性服务,每个计算机都可能出现故障。
该项目包括这些模块:
Hadoop Common:支持其他Hadoop模块的常用工具。
Hadoop分布式文件系统(HDFS™):提供对应用程序数据的高吞吐量访问的分布式文件系统。
Hadoop YARN:作业调度和集群资源管理的框架。
Hadoop MapReduce:一个用于并行处理大型数据集的基于YARN的系统。