AAAI2019 | 腾讯AI Lab详解自然语言处理领域三大研究方向及入选论文
感谢阅读腾讯AI Lab微信号第67篇文章。人工智能顶级国际会议AAAI即将举办,腾讯AI Lab第2次参与,共27篇文章入选。针对实验室关注自然语言处理领域的三大研究热点:知识库与文本理解、对话和文本生成、和机器翻译,本文将进行详细解读。Enjoy!
美国人工智能年会(the Association for the Advance of Artificial Intelligence),简称AAAI,是人工智能领域的顶级国际会议。会议由AAAI协会主办,今年是第33届,于1月27日-2月1日在美国夏威夷举行。腾讯AI Lab第2次参与会议,共27篇文章入选,涵盖自然语言处理、计算机视觉、机器学习等领域。

其中,腾讯AI Lab在自然语言处理领域,主要关注知识库与文本理解、对话和文本生成、和机器翻译这三大方向。以下为详细解读。
知识库与文本理解
在自然语言处理研究中,各种类型的知识(Knowledge,包括语义知识、实体关系知识、常识知识)已成为文本理解和下游任务中不可或缺的数据资源。腾讯AI Lab的多篇AAAI 2019论文关注了知识库的建模,及其在文本理解上的应用。
知识库与短文本理解
1.基于Lattice CNN的中文问答匹配方法
Lattice CNNs for Matching Based Chinese Question Answering
问答系统是普通用户使用知识库最直接的渠道。匹配用户问题这种短文本,通常面临相同语义的单词和表达方式不唯一的挑战。 中文这种还需要额外分词的语言中,这种现象尤为严重。在论文《基于Lattice CNN的中文问答匹配方法(Lattice CNNs for Matching Based Chinese Question Answering)》中,研究者提出一个基于Lattice CNN的模型,利用在单词语义中多粒度的信息来更好地处理中文问答的匹配。在基于文本问答和知识库问答的实验中,实验结果表明提出的模型可以显著超过目前最好的匹配模型。
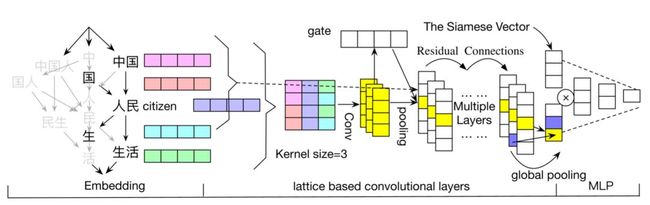
基于Lattice CNN模型理解短文本的框架
涉及新实体的知识库嵌入
2.基于逻辑注意力邻域聚集的归纳知识图谱嵌入方法
Logic Attention Based Neighborhood Aggregation for Inductive Knowledge Graph Embedding
知识库嵌入的目的是用低维向量建模实体和关系,用于下游任务。已有方法大多要求所有实体在训练时可见,这在每天更新的知识库中是不切实际的。在论文《基于逻辑注意力邻域聚集的归纳知识图谱嵌入方法(Logic Attention Based Neighborhood Aggregation for Inductive Knowledge Graph Embedding)》中,研究者使用同时训练邻域聚集模型的方式来去除这种限制,并提出一种基于规则和注意力机制的聚集模型,即逻辑注意力网络(LAN)。在两个知识图谱补全任务上,LAN被证明优于传统聚集模型。
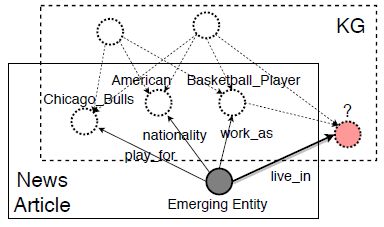
涉及新实体(Emerging Entity)的链接预测任务
常识知识库与故事补全
3.结构化常识在故事补全中的应用
Incorporating Structured Commonsense Knowledge in Story Completion
为故事选择恰当的结尾可以视作通往叙述型文本理解的第一步。这不仅需要显式的线索,还需要常识知识,而绝大多数已有工作都没有显式的使用常识。在论文《结构化常识在故事补全中的应用(Incorporating Structured Commonsense Knowledge in Story Completion)》中,研究者提出一个整合了叙述线索、情感演变以及常识知识的神经网络模型。这个模型在公共数据集ROCStory Cloze Task上取得了最好的性能。实验结果同时显示,引入常识知识带来了显著的性能增益。
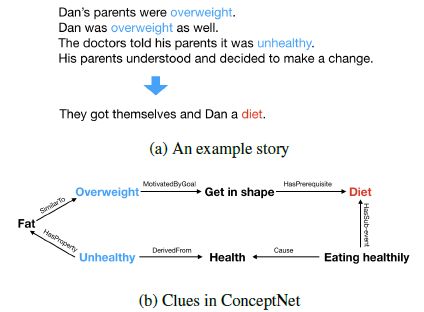
故事和结尾中的关键词在常识知识库中的联系
对话和文本生成
近年来,随着端到端的深度神经网络的流行,对话生成及更多场景的文本生成逐渐成为自然语言处理中一个热点研究领域。其中,对话生成技术正逐渐广泛地应用于智能对话系统,帮助实现更为智能的人机交互,也可以通过自动生成新闻、财报及其它类型的文本,提高撰文者的工作效率。
在对话生成问题上,通过迁移神经机器翻译的序列到序列模型等,对话生成的效果取得了显著的进展。然而,现有的对话生成模型仍存在较多问题。首先,目前的模型大多模拟的是输入到回复一对一的映射,而实际对话数据经常是一对多的关系的训练方式,因此模型容易输出通用回复,欠缺回复多样性。其次,目前的回复生成模型缺乏对于用户背景、通用常识等知识的理解,因此如何挖掘更多有用的知识来指引回复生成是一个重要的研究问题。再次,目前多数的研究工作重点在提升单轮回复的生成之类,而缺乏对多轮对话生成的改进,多轮回复生成的质量仍较差。
在文本生成问题中,根据不同的输入类型,现有的研究任务大致划分为三大类:文本到文本的生成,数据到文本的生成以及图像、视频、音频到文本的生成。每一类的文本生成技术都极具挑战性,在近年来的自然语言处理及人工智能领域的顶级会议中均有相当多的研究工作。
腾讯AI Lab在对话生成及文本生成技术均有相关的论文被AAAI2019接收。
短文本中生成回复
4.短文本对话中的多样性回复
Generating Multiple Diverse Responses for Short-Text Conversation
短文本生成任务之前的工作,主要聚焦在如何学习一个模型为输入及其回复建立一个一对一的映射关系。但在实际场景中,一个输入往往有多种回复。因此,研究者提出了一种新的回复生成模型,在训练过程中考虑了一个提问同时具有多个回复的情况。具体来说,假设每个输入可以推断出多个潜在词,不同的回复是围绕着不同的潜在词而产生的。研究者设计了一个基于强化学习算法的对话生成模型。如下图所示,所提出的框架主要有两个核心部分:(1)潜在词推断网络:其根据输入的提问来选择合适的潜在词作为生成网络输入的一部分;(2)生成网络,根据潜在词推断网络选择的潜在词以及输入的提问来生成回复。基于强化学习的训练过程中,使用F1值来计算潜在词推断网络的奖赏并更新推断网络参数,并选取这多个回复中损失最小的一项来更新生成网络参数。
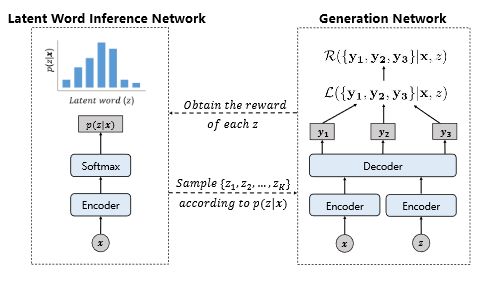
模型框架图
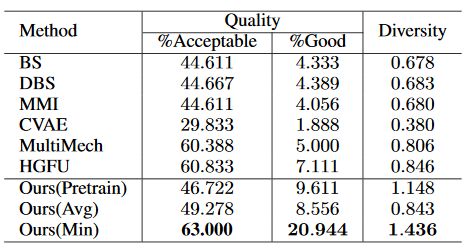
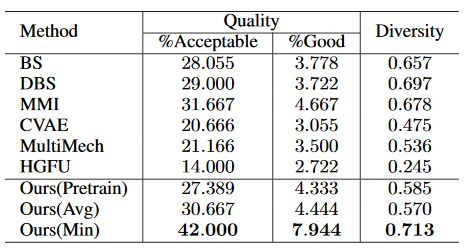
微博(左)和Twitter(右)数据集人工评测结果
研究者分别在微博和Twitter两个数据集上进行大量实验,人工评测的结果表明所提出的模型相比多个之前的模型,在提升回复信息量的同时保证了回复的多样性。以下是基线模型MultiMech和我们所提出的模型在微博数据集上的生成样例。方括号内为潜在词推断网络选择的潜在词。

微博数据集生成样例
多选干扰项生成
5.阅读理解问题的干扰选项生成
Generating Distractors for Reading Comprehension Questions from Real Examinations
本文探究了考试中为多选阅读理解题型生成干扰项的任务。和之前工作不同,研究者不以生成单词或短语类型的干扰项为目的,趋向生成更长并含有丰富语义信息的干扰项,从而生成的干扰项和真实考试中阅读理解题目的干扰项尽可能接近。
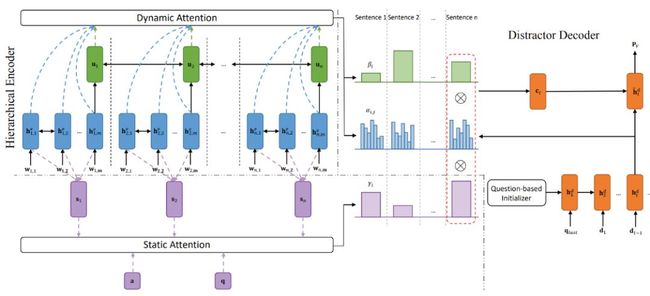
模型框架概览
如图所示,以阅读理解文章,问题和正确的答案选项作为输入,目标是生成多个与答案有关联,和问题语义上连贯并能在文章中找到蛛丝马迹的干扰项。研究者提出了一个层次编码器-解码器模型,辅之以静态与动态注意力机制来解决这个任务。具体来说,动态注意力机制可以融合句子级别和词级别的注意力信息,并在解码的每一个步骤会有所变化,从而生成一个可读性更强的序列。静态注意力机制可以调制动态注意力机制,打压与当前问题无关的句子或者包含正确答案的句子。
通过第一个阅读理解问题干扰项生成数据集上的实验,本文提出的模型超过了多个基线模型。人工评测中与一些基线模型生成的干扰项相比,其模型生成的干扰项更加容易迷惑标注者。
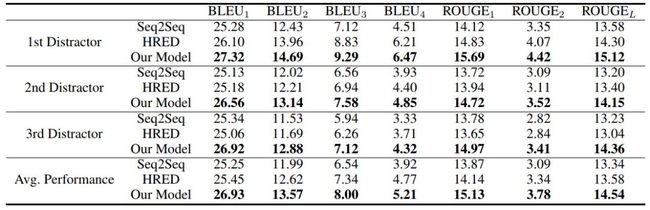
实验结果
新闻摘要生成
6.考虑读者评论的生成式文本摘要
Abstractive Text Summarization by Incorporating Reader Comments
在基于神经网络的生成式文本摘要研究领域中,传统的基于序列到序列的模型对文档主题的建模经常出错。为解决这个问题,研究者提出了读者感知的摘要生成任务,它利用读者的评论来帮助生成符合文档主题的更好的摘要。与传统的生成式摘要任务不同,读者感知型摘要面临两个主要挑战:(1)评论是非正式的,有噪音的; (2)联合建模新闻文档和读者评论具有一定挑战性。
为解决上述问题,本文设计了一个基于对抗学习的读者感知型摘要生成模型(RASG),它由四个部分组成:(1)基于序列到序列的摘要生成模块; (2)读者注意力建模模块来捕捉读者关注的主题; (3)督导建模模块来描述生成的摘要和读者关注主题之间的语义差距; (4)目标跟踪模块来产生每个生成步骤的目标。督导和目标定位模块以对抗学习的方式来指导我们框架的训练。
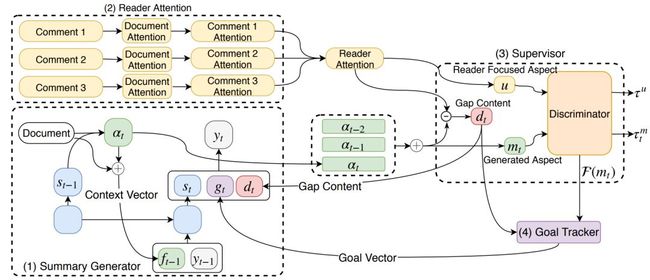
模型框架概览
研究者在自行收集的文摘数据集进行大量实验,结果表明RASG在自动评测和人工评测方面都取得了最好的效果。实验结果还证明了该框架中每个模块的有效性,同时研究人员发布了一个大规模数据集供进一步研究。
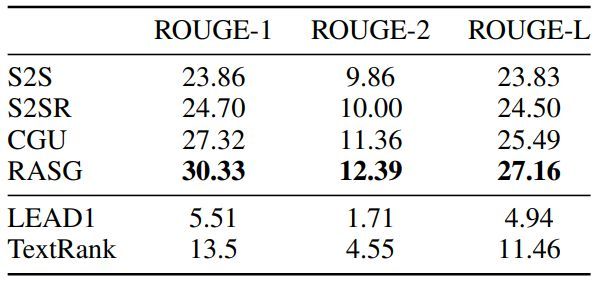
自动评测结果(左)和人工评测结果
机器翻译
机器翻译是人工智能的终极目标之一,其核心语言理解和语言生成是自然语言处理的两大基本问题,极具挑战性。近几年来,随着深度学习技术的发展,神经网络机器翻译取得了巨大进展,其生成的译文接近自然句子,成为了主流模型。但是由于当前神经网络的不可解释性,无法保证原文内容完整传递到译文,使得神经网络翻译模型存在译文忠实度问题(即“达而不信”)。腾讯AI Lab专注于解决该核心问题,在AAAI2019会议上发表的多篇论文通过改进模型架构和训练框架,提升模型对源句理解和目标句生成的能力,从而改善神经网络翻译模型忠实度低的问题。
自注意力模型
7.上下文增强的自注意力神经网络
Context-Aware Self-Attention Networks
自注意力模型通过直接计算任意两个词的向量表示,得到它们的关联性强弱(图(a))。由于其极佳的并行性运算及捕获长距离依赖的能力,自注意力模型成为当前主流翻译模型(如Transformer)的核心组件。在本工作中,通过改进自注意力模型的全局上下文建模能力,从而更好地计算词间的关联性。研究者使用不同策略来建模全局上下文信息,如顶层全局信息(图(b))、深层信息(图(c))及深层全局信息(图(d))。为保持自注意力模型的并行性及简易性,研究者将上下文信息引入注意力模型输入(如Query和Key)的转化函数中。该论文是改进自注意力模型的第二个工作,前续工作(Modeling Localness for Self-Attention Networks, EMNLP2018)改进了自注意力模型的局部建模能力 。
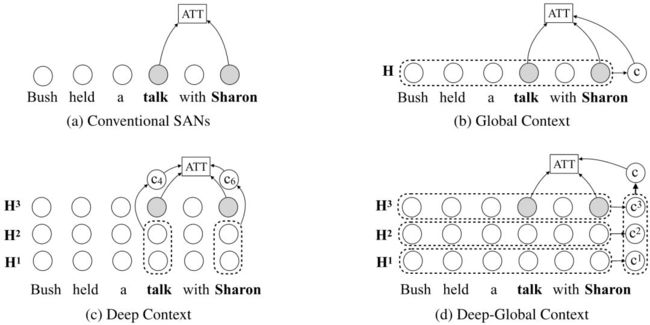
深层模型
8.基于动态层融合的神经网络机器翻译
Dynamic Layer Aggregation for Neural Machine Translation
主流的翻译模型都是深层网络结构,比如Transformer模型的编码器和解码器都是由多层自注意力网络组成。近期多个工作表明不同层表示可以捕获输入句子不同级别的语言学信息,但主流模型只利用了编码器和解码器的最上层表示信息,而忽视了其余层包含的有用信息。本研究使用胶囊网络中的迭代路径 (iterative routing)算法融合所有层的表示,从而更好地利用不同层捕获的不同语言学信息。该论文为利用深层表示的第二个工作,前续工作(Exploiting Deep Representations for Neural Machine Translation, EMNLP2018)使用深层连接改进深层网络中信息和梯度的传递路径(Information and Gradient Flow),而本工作更关注于直接融合不同层表示(Representation Composition)。
忠实度导向的训练框架
9.基于译文忠实度训练的神经网络机器翻译
Neural Machine Translation with Adequacy-Oriented Learning
当前翻译模型的训练通常是基于最大化词的似然概率的框架。该框架有三个缺陷:(1)训练/测试不一致,训练时是基于正确的目标序列而测试时是由于包含错误的生成序列;(2)基于词级别的目标函数,而在实际场景中评判译文质量的指标通常是基于句子级别的;(3)最大似然估计更多是关注译文的流利度而不是忠实度,这也是导致模型偏好短译文的重要原因。
本研究尝试在统一框架中同时解决上述三个缺陷。如图1所示,将翻译建模成强化学习中的随机策略(Stochastic Policy)问题,而学习奖励则是基于模型生成的完整序列评估的。为了更好地评估译文的忠实度,本文提出了一种新的标准 – 覆盖差异率(Coverage Difference Ratio, CDR),通过比较生成译文和人工译文对源端词的覆盖程序,以评估有多少源端词被遗漏翻译。在图2展示的例子中,译文的 CDR=4/7,其中4和7分别是生成译文和人工译文中覆盖的源端词个数。 该论文中的覆盖率思想也是延续作者的前续工作(Modeling Coverage for Neural Machine Translation),在训练框架中验证该策略的普适性,实验同时证明两种方法具有一定互补性,同时使用可进一步提升翻译效果。
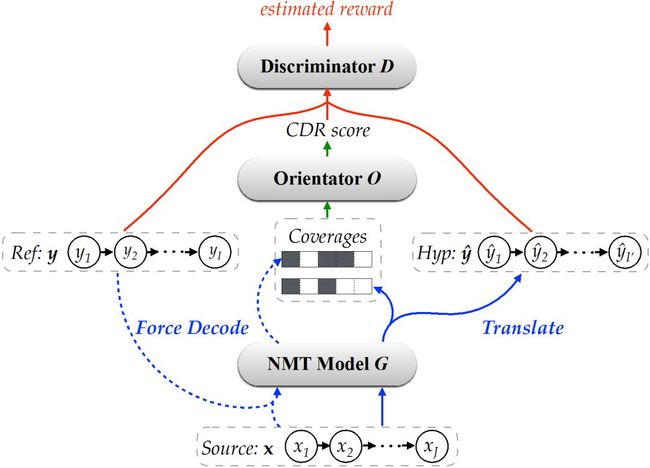
图 1 训练框架
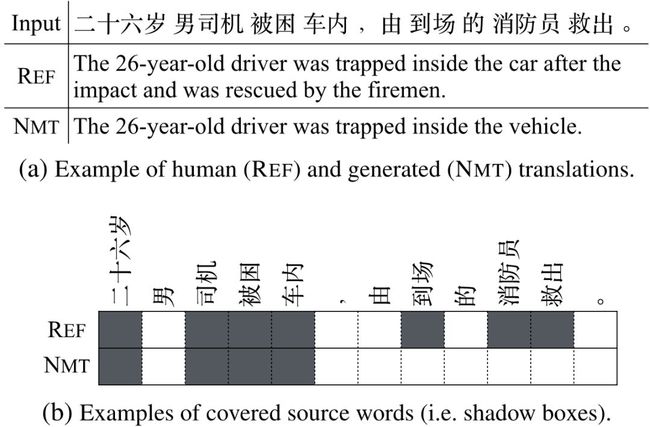
图 2 CDR示例
除了改进基本的翻译模型,研究者同时探索辅助翻译,从而使当前神经网络机器翻译系统更好地为真实用户服务。围绕最近推出的辅助翻译产品TranSmart, 腾讯AI Lab发表在AAAI2019的论文(Graph Based Translation Memory for Neural Machine Translation) 将用户提供的或者自动检索的翻译记忆融入神经翻译模型,从而改善翻译质量。不同于现有的翻译记忆方法,本文将翻译记忆组织成一个压缩图并采用基于图的注意力机制来构建翻译的上下文。其优势是,既可以保证计算的有效性,又可以充分地建模翻译记忆中全局信息比如长距离的调序,因而获得了更好的翻译质量。
入选论文
精彩一览
10. MOBA游戏AI的多层次宏观策略模型
Hierarchical Macro Strategy Model for MOBA Game AI
该论文由腾讯AI Lab独立完成,在通用AI研究中,可解决部分可观测、团队协作、博弈等复杂AI问题。即时战略游戏是游戏AI的下一个挑战。即时战略游戏给AI研究提供了一个部分可观测的游戏环境,智能体在这样的环境中基于比围棋大的多的操作空间产生交互。攻克即时战略游戏需要同时具备强大的宏观策略及精准的微观执行。最近,研究人员在微观执行层面取得了巨大突破,然而宏观策略层面仍然缺乏完整有效的解决方案。该论文创新提出了基于机器学习的多层宏观策略模型以提升智能体在多人在线格斗游戏(MOBA)游戏 - 即时战略游戏的一个子类 - 中的宏观策略能力。经过多层次宏观策略模型训练的智能体显示的进行宏观策略决策以指导微观操作。更进一步的,每一个智能体在做决策的同时,通过本文创新设计的模仿跨智能体通信机制与其他智能体进行配合。研究者在一款风靡的5v5 MOBA游戏(王者荣耀)上充分验证了多层次宏观策略模型的效果。研究团队的5 AI战队在与前1%的人类战队的对战测试中,取得了48%的胜率。
11. 意见目标抽取以及目标情感预测的统一模型
A Unified Model for Opinion Target Extraction and Target Sentiment Prediction
该论文由腾讯AI Lab主导,与香港中文大学合作完成,该研究通过改进基本的序列标注模型来提升端到端抽取用户评论中的意见目标和相应的情感倾向的性能。基于意见目标的情感分析(TBSA)涉及到了意见目标抽取和目标情感预测两个子任务。目前的工作主要是将他们作为两个单独的任务来研究,对于实际应用的贡献是非常有限的。这篇文章的目标在于以一种端到端的方式来解决完整的TBSA任务。为了实现这个目标,本文提出了一个新的统一模型并在模型中采用了一种联合的标注方案。整个模型用到了两层循环神经网络(RNN):上层的RNN用来预测联合的标签,这些标签会作为主要任务TBSA的输出;为了引导上层的RNN更好的完成TBSA任务,本文引入了下层的RNN来同时解决辅助任务--意见目标实体的边界检测。RNN产生的边界特征表示可以直接用于提升目标情感预测的质量。为了探索任务之间的依赖,本文提出显式地对目标边界到目标情感极性的转换进行约束。本文也设计了一个组件对同一个意见目标内的情感一致性进行维持,这个组件主要基于门控制机制来对上一个时刻的特征和当前时刻的特征之间的关系进行建模。本文在三个标准数据集上进行了大量实验,结果表明本文的方法都比现有的方法更好。
12. 通过样本加权进行更好地微调文本分类模型
Better Fine-tuning via Instance Weighting for Text Classification
该论文由腾讯AI Lab主导,与南京大学合作完成。深度神经网络中使用迁移学习在许多文本分类应用中取得了巨大成功。一种简单而有效的迁移学习方法是对预训练的模型参数进行微调。之前的微调工作主要集中在预训练阶段,并且研究如何预训练一组对目标任务最有帮助的参数。本文提出了一种基于样本加权的微调(IW-Fit)方法,对于微调阶段进行了改进以提高分类器在目标域的最终性能。 IW-Fit动态调整每个微调时期的样本权重,以实现两个目标:1)有效地识别和学习目标域的特定知识; 2)很好地保留源域和目标域之间的共享知识。 IW-Fit中使用的样本加权计算指标与模型无关,对于基于DNN的通用分类器而言易于实现。实验结果表明,IW-Fit可以持续提高模型在目标域的分类精度。
13. 深层特征结构学习方法
Learning (from) Deep Hierarchical Structure among Features
该论文由香港科技大学与腾讯 AI Lab合作完成,提出了多种层次结构特征学习方法。数据中的特征通常存在着复杂的层次结构。大多数现有的研究侧重于利用已知的层次结构来帮助监督学习提高学习的精度,而且通常仅能够处理层次深度为2的简单结构。本文提出了一种深度层次特征学习方法(DHS),用于学习任意深度的特征层次结构,并且学习目标是凸函数。DHS方法依赖于结构中边上的权重的指数系数,然而这些指数系数需要提前人为给定,这会导致学习出的特征表达是次优的。基于DHS方法,本文又提出了可以自动学习这些指数系数的方法。进一步的,本文考虑层次结构未知的情况,并且在DHS的基础上又提出一种深度特征层次结构学习方法(LDHS)。不同于以往的方法,LDHS不需要知道关于层次结构的先验知识,而是通过fused-lasso技术和一种特定的序列约束条件直接从数据中学习出特征的层次结构。上述所有提出的模型的优化方法都可以通过近似梯度的方式求解,并且本文给出了求解过程中每个子问题的高效解答算法。本文在多种人工和真实数据集上进行了实验,结果表明了本文提出方法的有效性。
14. DDFlow:通过无监督数据蒸馏学习光流
DDFlow:Learning Optical Flow with Unlabeled Data Distillation
这项研究由腾讯AI Lab主导,与香港中文大学合作完成,提出一种无监督的数据蒸馏方法学习光流——DDFlow。该方法由一个教师模型中提取出预测结果,并用这些结果来指导学生模型学习光流。以往的无监督学习方法是通过一些人工设定的能量函数来处理被遮挡的区域,这篇论文的不同之处是通过数据来自动学习和预测被遮挡区域的光流。通过该方法,模型只需使用一个非常简单的目标函数,就能取得更高的准确率。本文在Flying Chairs, MPI Sintel, KITTI 2012 和 KITTI 2015四个数据集上做了详尽的实验。实验表明,本文提出的方法超过所有无监督的光流预测方法,并且可以实时运行。
15. 类间角度损失用于卷积神经网络
Inter-Class Angular Loss for Convolutional Neural Networks
这项研究由南京理工大学与腾讯AI Lab合作完成。卷积神经网络在各种分类任务中表现出强大的力量,并且在实际应用中取得了显着的成果。然而,现有网络在很大程度上忽略了不同类别对的区分学习难题。例如,在CIFAR-10数据集中,区分猫和狗通常比区分马和船更难。通过仔细研究卷积神经网络模型在训练过程中的行为,研究者观察到两类的混淆程度与它们在特征空间中的角度可分性密切相关。也就是说,类间角度越大,混淆度越低。基于这一观察,研究者提出了一种新的损失函数,称为“类间角度损失”(ICAL)。它明确地模拟了类相关性,可以直接应用于许多现有的深度网络。通过最小化ICAL,网络可以通过扩大它们对应的类向量之间的角度来有效地区分相似类别中的示例。对一系列视觉和非视觉数据集的全面实验结果证实,ICAL极大地提高了各种代表性深度神经网络的辨别能力,并为传统的softmax损失产生了优于原始网络的性能。
16. 基于最大化后验估计的词嵌入模型
Word Embedding as Maximum A Posteriori Estimation
这项研究由肯特大学与腾讯AI Lab合作完成。词嵌入模型GloVe可以被重构成一个最大似然估计问题,再通过优化的方式进行求解。该论文通过考虑基于GloVe的参数化方法,同时结合先验分布来对GloVe词嵌入模型进行泛化。本文提出了一个新的词嵌入模型,该模型对每个上下文词的变化进行建模,来表示这个词的信息重要性。论文中提出的框架可以统一学习词向量和每个词的变化。实验表明本文提出词向量模型优于GloVe和它的其他变种。
17.可控的图像到视频转换:关于人脸表情生成的案例分析
Controllable Image-to-Video Translation: A Case Study on Facial Expression Generation
这项研究由腾讯AI lab主导,与麻省理工学院(MIT)合作完成。深度学习的最新进展使得利用神经网络生成如照片般逼真的图像成为可能,甚至可以从视频过去几帧推断出未来几帧——某种意义上,实现了从过去视频到未来视频的生成。为了进一步深化这种探索,同时也出于对实际应用的兴趣,我们研究了图像到视频的转换,特别关注面部表情的视频。与图像到图像的转换相比,该问题通过一个额外的时间维度来挑战深度神经网络;此外,这里的单张输入图像使大多数视频到视频转换的方法无法应用。为了解决这个新问题,研究者提出了一种用户可控制的方法,以便从单个人脸图像生成各种长度的表情视频剪辑,用户可控制视频的长度和表情的类型。因此,我们设计了一种新颖的神经网络架构,可将用户输入作用到网络的跳层连接上;同时,提出对神经网络的对抗训练方法的若干改进。通过实验和用户研究验证了该方法的有效性。尤其值得强调的是,即使随机的网络图像和作者自己的图像相对于训练数据有较大的差异,本文的模型也可以生成高质量的面部表情视频,其中约50%被用户认为是真实采集的视频。
18. 利用考虑偏好的损失学习实现任务迁移
Task Transfer by Preference-Based Cost Learning
这项研究由清华大学与腾讯AI Lab合作完成。强化学习中的任务迁移旨在把智能体在源任务中的策略迁移到目标任务。尽管当前方法取得了一定成功,但是他们依赖于两个很强的假设:1)专家演示和目标任务精确相关 以及 2)目标任务中的损失函数需要显式定义。在实际中这两个假设都是难以满足。该论文提出了一个新颖的迁移框架减少对这两个假设的依赖,为此,研究者使用了专家偏好作为迁移的指导。具体而言,研究者交替进行以下两个步骤:首先,研究者通过预定义的专家偏好从源任务鸿挑选与目标任务相关的演示;然后,基于这些挑选的演示,研究者通过利用增强版的对抗最大熵模型来同时学习目标损失函数以及状态-操作的轨迹分布。该论文的理论分析证明了方法的收敛性。大量的仿真实验也验证了该论文方法的有效性。
19. 超越RNN:面向视频问答的具有位置特性的自注意力和交互注意力模型
Beyond RNNs: Positional Self-Attention with Co-Attention for Video Question Answering
这项研究由电子科技大学与腾讯AI Lab合作完成。当前,大部分实现视频问答的方法都是基于考虑注意力的递归神经网络(RNN)。虽然取得一些进展,但是RNN的局限性导致了这些方法往往需要花费大量训练时间却难以捕捉长时间关联。该论文提出了一种新的架构,具有位置属性的自注意力和交互注意力结合(PSAC),这个框架不再需要RNN来实现视频问答。具体而言,研究者从机器翻译中自注意力的成功得到启发,提出了一种具有位置属性的自主力模型来计算同一个序列中每个位置自身的激活以及其与其他位置的相关激活。因此,PASC能利用问题与视频的全局依赖,并且使得问题和视频编码能并行进行。除了利用视频自注意力,研究者更进一步查询问题中“哪些单词需要注意”来设置交互注意力机制。据研究者所知,这是视频问答领域中首次尝试去抛开RNN而只用注意力模型。在三个公开的数据集上,本文的方法显著优于当前最好,并且在另外一个数据集上取得了接近当前最好的结果。与RNN模型相比,本文的方法在更短的运算时间取得了更高的精度。此外,本文还进行了若干对比实验来验证方法每个组件的有效性。
20. 置信加权多任务学习
Confidence Weighted Multitask Learning
这项研究由阿卜杜拉国王科技大学与腾讯AI Lab合作完成。为了缓解传统在线多任务学习仅利用了数据流的一阶信息的问题,我们提出置信加权多任务学习的算法。对于每个任务,它都维护了一个高斯分布来引导在线学习过程。高斯分布的均值向量(协方差矩阵)是一个局部成分和全局成分的和,其中全局成分是在所有任务间共享的。此外,本文也解决了在线多任务学习场景下主动学习的挑战。不同于索要所有样本的标签,所提算法可以基于相关任务的预测置信度来决定是否索要相应的标签。理论结果显示,后悔上界可以被显著的减小。经验结果表明,所提算法可以获得很高的学习性能,且同时可以减小标注成本。
21. 旨在提升asepct-level情感分类的、从粗粒度到细粒度的迁移学习
Exploiting Coarse-to-Fine Task Transfer for Aspect-level Sentiment Classification
这项研究由香港科技大学与腾讯AI Lab合作完成。Aspect-level的情感分类旨在找出句子里针对具体aspect的情感倾向,其中aspect可以是一个泛类(AC-level),比如食品、服务,也可以是一个具体的项(AT-level),比如三文鱼、时速。然而,由于极其耗时耗力的标注成本,当前AT-level的公开数据集都相对较小。受限于这些小规模的数据集,当前大多数方法依赖于复杂的结构,从而限制了神经网络模型的有效性。该论文提出了一个新的解决方案,即从数据相对充足的粗粒度任务(AC-level)到数据稀疏的细粒度任务(AT-level)进行迁移学习。为了解决两个领域在aspect粒度以及特征上的不一致,本文提出了一个多粒度对齐网络(MGAN)。在MGAN中,一个全新的Coarse2Fine注意力机制可以帮助AC-level的任务也可以建模同AT-level相似的细粒度。同时,一个对比的特征对齐方法用来语义对齐两个领域的特征表示。另外,本文提供了一个AC-level的大规模多领域情感分类数据集。大规模的实验证明了MGAN的有效性。
22. 基于属性仓库的表亲网络引导的素描图识别
Cousin Network Guided Sketch Recognition via Latent Attribute Warehouse
这项研究由腾讯AI Lab主导,与澳洲国立大学合作完成,本论文对扫描图片识别的问题进行研究。由于两个原因导致该问题难度较高:1)素描图片相对自然图片比较稀缺,2)素描图片与自然图片之间存在较大的鸿沟。为了克服这些困难,研究者提出了利用自然图像训练好的网络(表亲网络)来引导素描图片识别网络的学习过程。表亲网络将引导素描图片识别网络学习更多与自然图像相关的特征(通过对抗学习)。为加强分类模型的可迁移能力,一个连接自然图像和素描图像的属性仓库建立起来,以逼近自然图像和素描图像的域间差。实验证明本文提出的方法取得了当前最优的识别性能。
23. 层级化的照片场景编码器用于相册故事生成
Hierarchical Photo-Scene Encoder for Album Storytelling
这项研究由腾讯AI Lab主导,与山东大学合作完成。本文提出了一种用于相册故事生成的新型模型,该新型模型使用了层级相片-场景编码器和重构器。其中,相片-场景编码器包含两个子模块,分别是相片编码器和场景编码器,它们重叠在一起,以分层的形式充分利用相册中照片的结构信息。具体来说,相片编码器利用相册中相片的时序关系的同时,为每一张照片生成语义表示。场景编码器依赖于生成的相片语义表示,负责检测相册的场景变化并生成场景特征。接着,解码器动态地、有选择性地总结这些编码的相片和场景语义表示,用以生成相册表示序列。基于此,一个含有多个一致性句子的故事就产生了。为了充分提取和利用相册中有效的语义信息,重构器被引入到该模型中,来重构那些基于解码器的隐藏状态而被动态总结了的相册表示。本文提出的模型以一种端到端的形式进行训练,在公开的visual storytelling数据集(VIST)上得到了更好的性能。对比研究实验进一步论证了本文所提出的层级相片-场景编码器和解码器的有效性。
24. 结构化常识在故事补全中的应用
Incorporating Structured Commonsense Knowledge in Story Completion
这项研究由加州大学戴维斯分校与腾讯AI Lab合作完成。为一个给定的故事选择恰当的结尾,被认为是通往叙述型文本理解的第一步。故事结尾预测不仅需要显式的线索,还得需要一些隐式的知识(如常识)。之前绝大多数方法都没有明显地使用各种背景常识。该论文提出一个基于神经网络的故事结尾预测模型,这个模型整合了三种不同类型的信息来源:叙述线索、情感演变以及常识知识。实验结果表明本文的模型在一个公共数据机ROCStory Cloze Taks上取得了最好的性能。同时,实验结果表明引入常识知识带来了显著的性能增益。
25. 一种针对多模态数据的高效特征提取方法
An Efficient Approach to Informative Feature Extraction from Multimodal Data
这项研究由腾讯AI Lab主导,与清华大学、清华-伯克利深圳学院、麻省理工学院(MIT)合作完成。多模态特征提取的一个研究重点在于如何找到每个模态中相关度最大的特征表达。作为一种常用的相关度度量方式,HGR最大相关度因较好的理论性质,经常被作为优化的目标函数。然而,HGR最大相关度中对于白化的严格约束,部分限制了其应用。为解决这一问题,本文提出了Soft-HGR的新框架,以解决从多个数据模态中提取有效特征的问题。具体来说,本方法在优化HGR最大相关度的过程中,避免了严格白化约束,同时也能保持特征的集合特性。Soft-HGR的优化目标仅包含两个内积项,可以保证优化过程的求解效率和稳定性。研究者进一步将该方法泛化,用于解决超过两个数据模态以及部分模态缺失的问题。对于数据中仅有部分标注信息的情况,研究者可以通过半监督适应的方法,使得所提取的特征更具有判别力。实验结果表明,本文的方法可以学习到更有信息量的特征映射,同时优化过程也更为高效。
26. Plan-And-Write: 更好的自动故事写作
Plan-And-Write: Towards Better Automatic Storytelling
这项研究由北京大学、南加州大学与腾讯AI Lab合作完成。自动故事生成的目标是用更长、更流畅的语句来描述一个有意义的事件序列,这是一个极具挑战的任务。尽管已有许多工作在研究自动故事生成,但是先前的研究要么局限于plot planning,要么只能生成特定领域的故事。该论文探索了开放领域的基于给定故事题目的故事生成任务。研究者提出了plan-and-write的层级生成框架,先生成故事线,再基于此生成整个故事。研究者对比了两种planning的策略:动态模式是将故事线的planning和故事的文本生成交替进行,而静态模式是先确定好故事线再生成故事。实验结果表明,在显式的故事线planning作用下,系统能生成更多样、更连贯、更切题的故事,在自动指标和人工评测结果中,都优于没有planning的对比方法。
27. 翻译记忆图的神经机器翻译
Graph based translation memory for neural machine translation
该论文由腾讯AI Lab主导,与卡内基梅隆大学合作完成,可有效地利用翻译记忆构建翻译模型。翻译记忆对提高统计机器翻译很有帮助,随着统计机器翻译向神经机器翻译的进化,将翻译记忆融入到神经翻译框架已经引起了很多关注。现有的工作中,有的为了保证效率,仅利用了翻译记忆中的局部信息;也有工作利用了翻译记忆中的全局信息,但是降低了效率。该论文提出了一个有效的方法,它可以充分利用翻译记忆的全局信息。它的基本思想是,将包括冗余词的序列化翻译记忆压缩成一个结构紧凑的图,然后计算一个基于图的注意力模型。在6个翻译任务上的实验表明,本文提出的方法是有效的:它获得了比基线系统Transformer更好的效果,而且也比现有的基于翻译记忆的模型更好。
