DeepMind深度学习高级课程,视频已全部放出
痴栗子 发自 麦蒿寺
量子位 报道 | 公众号 QbitAI
昨天,DeepMind兴奋地发推宣告:
我们在伦敦大学学院 (UCL) 讲授的课程,现在全部课堂视频都放出来了。

课号COMPGI22,名叫高级深度学习和强化学习 (Advanced Deep Learning and Reinforcement Learning) ,是今年早些时候结课的。
面对这一喜讯,推特上的小伙伴们纷纷马克,奔走相告。

DeepMind发布研究成果的推特,几条加起来可能也不及这一条资源的关注度。
两个部分,合体进化
一个学期18节课,老师是DeepMind研究负责人兼UCL教授Thore Graepel,与他率领的一众DM研究员。

课程分为两个部分,互有交叉,在学期的结尾正式汇合:
一个部分,是用深度神经网络做机器学习;
另一部分,是用强化学习做预测和控制。
两股溪流,终会以“深度强化学习”之名,合为一体:
在强化学习环境里,深度神经网络会以函数逼近器 (Function Approximators) 的形象出现。
深度学习部分

开始,是简要介绍神经网络和监督学习,用的是TensorFlow。
后面,是卷积神经网络 (CNN) ;
递归神经网络 (RNN) ;
端到端 (End-to-End) 以及基于能量 (Energy-Based) 的学习;
优化方法 (Optimization Methods) ;
无监督学习 (Unsupervised Learning) ;
当然,还会讲到注意力 (Attention) 和记忆 (Memory) 。
课堂要讨论的应用方向,包括物体识别,以及自然语言处理。

强化学习部分
这一部分,会涉及马尔可夫决策过程 (Markov Decision Process) ;
动态规划/动态编程 (Dynamic Programming) ;
无模型预测和控制 (Model-Free Prediction and Control) ;
价值函数 (Value Function) ;
近似 (Approximation) ;
策略梯度方法 (Policy Gradient Methods) ;
学习与规划的整合 (Integration of Learning and Planning) ;
以及强化学习里最重要的,探索未知与利用已知之间的两难抉择。
应用层面的讨论,包括学打经典游戏,和桌游。
最终,两个部分完成合体。
友情提示:以上两部分是穿插进行,同学们可提前做好心理建设。
祝您成功
这里,是每一节课的主题。
前三节是深度学习,又三节是强化学习。不过再往后,就是一节深度学习、一节强化学习,这样的高频切换了。
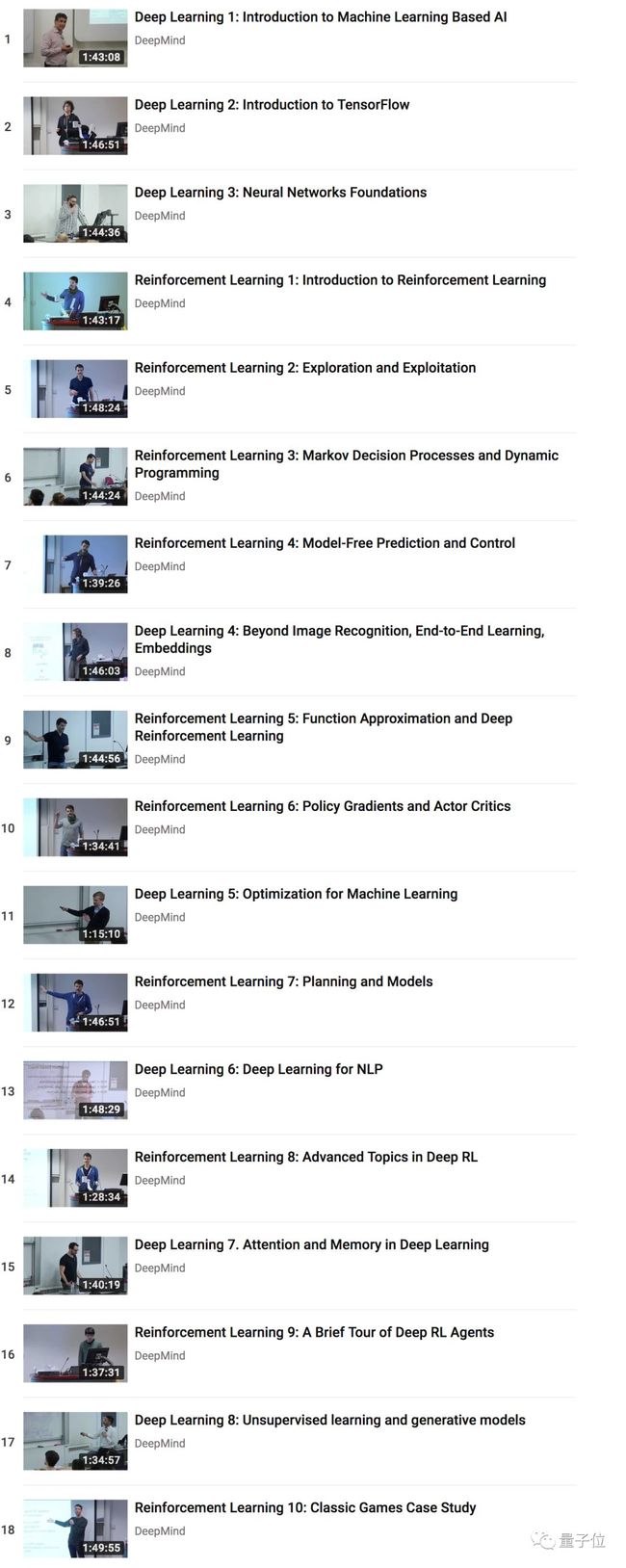
如果各位刚才没注意,DeepMind宣布课程喜讯的那条推特,最后一句话是:

课程视频传送门 (梯子必要) :
https://www.youtube.com/playlist?list=PLqYmG7hTraZDNJre23vqCGIVpfZ_K2RZs
— 完 —
年度评选申请

加入社群
量子位AI社群开始招募啦,欢迎对AI感兴趣的同学,在量子位公众号(QbitAI)对话界面回复关键字“交流群”,获取入群方式;
此外,量子位专业细分群(自动驾驶、CV、NLP、机器学习等)正在招募,面向正在从事相关领域的工程师及研究人员。
进专业群请在量子位公众号(QbitAI)对话界面回复关键字“专业群”,获取入群方式。(专业群审核较严,敬请谅解)
诚挚招聘
量子位正在招募编辑/记者,工作地点在北京中关村。期待有才气、有热情的同学加入我们!相关细节,请在量子位公众号(QbitAI)对话界面,回复“招聘”两个字。

量子位 QbitAI · 头条号签约作者
վ'ᴗ' ի 追踪AI技术和产品新动态