Flume+Kafka+Storm+Redis构建大数据实时处理系统
数据处理方法分为离线处理和在线处理,今天写到的就是基于Storm的在线处理。在下面给出的完整案例中,我们将会完成下面的几项工作:
- 如何一步步构建我们的实时处理系统(Flume+Kafka+Storm+Redis)
- 实时处理网站的用户访问日志,并统计出该网站的PV、UV
- 将实时分析出的PV、UV动态地展示在我们的前面页面上
如果你对上面提及的大数据组件已经有所认识,或者对如何构建大数据实时处理系统感兴趣,那么就可以尽情阅读下面的内容了。
需要注意的是,核心在于如何构建实时处理系统,而这里给出的案例是实时统计某个网站的PV、UV,在实际中,基于每个人的工作环境不同,业务不同,因此业务系统的复杂度也不尽相同,相对来说,这里统计PV、UV的业务是比较简单的,但也足够让我们对大数据实时处理系统有一个基本的、清晰的了解与认识,是的,它不再那么神秘了。
实时处理系统架构
我们的实时处理系统整体架构如下:
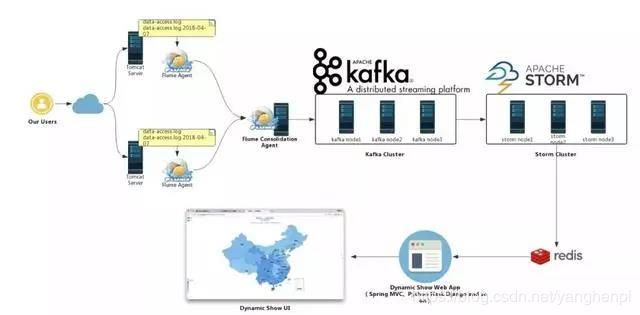
即从上面的架构中我们可以看出,其由下面的几部分构成:
- Flume集群
- Kafka集群
- Storm集群
从构建实时处理系统的角度出发,我们需要做的是让数据在各个不同的集群系统之间打通(从上面的图示中也能很好地说明这一点),即需要做各个系统之前的整合,包括Flume与Kafka的整合,Kafka与Storm的整合。当然,各个环境是否使用集群,依个人的实际需要而定,在我们的环境中,Flume、Kafka、Storm都使用集群。
Flume+Kafka整合
即从上面的架构中我们可以看出,其由下面的几部分构成:
- Flume集群
- Kafka集群
- Storm集群
从构建实时处理系统的角度出发,我们需要做的是让数据在各个不同的集群系统之间打通(从上面的图示中也能很好地说明这一点),即需要做各个系统之前的整合,包括Flume与Kafka的整合,Kafka与Storm的整合。当然,各个环境是否使用集群,依个人的实际需要而定,在我们的环境中,Flume、Kafka、Storm都使用集群。
Flume+Kafka整合
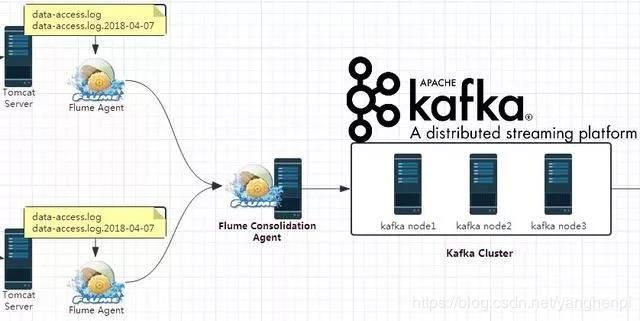
1整合思路
对于Flume而言,关键在于如何采集数据,并且将其发送到Kafka上,并且由于我们这里了使用Flume集群的方式,Flume集群的配置也是十分关键的。而对于Kafka,关键就是如何接收来自Flume的数据。从整体上讲,逻辑应该是比较简单的,在Kafka中创建一个用于我们实时处理系统的topic,然后Flume将其采集到的数据发送到该topic上即可。
2整合过程
整合过程:Flume集群配置与Kafka Topic创建。
Flume集群配置
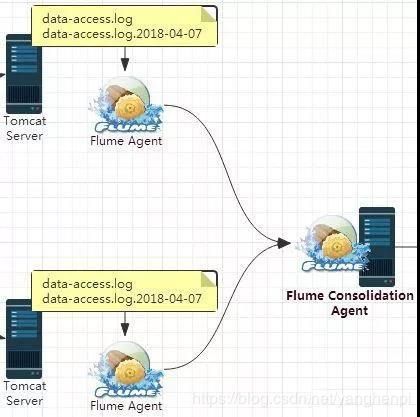
在我们的场景中,两个Flume Agent分别部署在两台Web服务器上,用来采集Web服务器上的日志数据,然后其数据的下沉方式都为发送到另外一个Flume Agent上,所以这里我们需要配置三个Flume Agent。
- Flume Agent01
该Flume Agent部署在一台Web服务器上,用来采集产生的Web日志,然后发送到Flume Consolidation Agent上,创建一个新的配置文件flume-sink-avro.conf,其配置内容如下:
#########################################################
##
##主要作用是监听文件中的新增数据,采集到数据之后,输出到avro
## 注意:Flume agent的运行,主要就是配置source channel sink
## 下面的a1就是agent的代号,source叫r1 channel叫c1 sink叫k1
#########################################################
a1.sources = r1
a1.sinks = k1
a1.channels = c1
#对于source的配置描述 监听文件中的新增数据 exec
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /home/uplooking/data/data-clean/data-access.log
#对于sink的配置描述 使用avro日志做数据的消费
a1.sinks.k1.type = avro
a1.sinks.k1.hostname = uplooking03
a1.sinks.k1.port = 44444
#对于channel的配置描述 使用文件做数据的临时缓存 这种的安全性要高
a1.channels.c1.type = file
a1.channels.c1.checkpointDir = /home/uplooking/data/flume/checkpoint
a1.channels.c1.dataDirs = /home/uplooking/data/flume/data
#通过channel c1将source r1和sink k1关联起来
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
配置完成后, 启动Flume Agent,即可对日志文件进行监听:
$ flume-ng agent --conf conf -n a1 -f app/flume/conf/flume-sink-avro.conf >/dev/ 2>&1 &
- Flume Agent02
- Flume Consolidation Agent

该Flume Agent用于接收其它两个Agent发送过来的数据,然后将其发送到Kafka上,创建一个新的配置文件flume-source_avro-sink_kafka.conf,配置内容如下:
##主要作用是监听目录中的新增文件,采集到数据之后,输出到kafka
#对于source的配置描述 监听avro
a1.sources.r1.type = avro
a1.sources.r1.bind = 0.0.0.0
a1.sources.r1.port = 44444
#对于sink的配置描述 使用kafka做数据的消费
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.topic = f-k-s
a1.sinks.k1.brokerList = uplooking01:9092,uplooking02:9092,uplooking03:9092
a1.sinks.k1.requiredAcks = 1
a1.sinks.k1.batchSize = 20
#对于channel的配置描述 使用内存缓冲区域做数据的临时缓存
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
a1.sinks.k1.channel = c1
配置完成后, 启动Flume Agent,即可对avro的数据进行监听:
$ flume-ng agent --conf conf -n a1 -f app/flume/conf/flume-source_avro-sink_kafka.conf >/dev/ 2>&1 &
Kafka配置
在我们的Kafka中,先创建一个topic,用于后面接收Flume采集过来的数据:
kafka-topics.sh --create --topic f-k-s --zookeeper uplooking01:2181,uplooking02:2181,uplooking03:2181 --partitions 3 --replication-factor 3
3整合验证
启动Kafka的消费脚本:
$ kafka-console-consumer.sh --topic f-k-s --zookeeper uplooking01:2181,uplooking02:2181,uplooking03:2181
如果在Web服务器上有新增的日志数据,就会被我们的Flume程序监听到,并且最终会传输到到Kafka的f-k-stopic中,这里作为验证,我们上面启动的是一个Kafka终端消费的脚本,这时会在终端中看到数据的输出:
这样的话,我们的整合就没有问题,当然Kafka中的数据应该是由我们的Storm来进行消费的,这里只是作为整合的一个测试,下面就会来做Kafka+Storm的整合。
Kafka+Storm整合

Kafka和Storm的整合其实在Storm的官网上也有非常详细清晰的文档:
http://storm.apache.org/releases/1.0.6/storm-kafka.html
想对其有更多了解的同学可以参考一下。
1整合思路
在这次的大数据实时处理系统的构建中,Kafka相当于是作为消息队列(或者说是消息中间件)的角色,其产生的消息需要有消费者去消费,所以Kafka与Storm的整合,关键在于我们的Storm如何去消费Kafka消息topic中的消息(Kafka消息topic中的消息正是由Flume采集而来,现在我们需要在Storm中对其进行消费)。
在Storm中,topology是非常关键的概念。
对比MapReduce,在MapReduce中,我们提交的作业称为一个Job,在一个Job中,又包含若干个Mapper和Reducer,正是在Mapper和Reducer中有我们对数据的处理逻辑:

在Storm中,我们提交的一个作业称为topology,其又包含了spout和bolt,在Storm中,对数据的处理逻辑正是在spout和bolt中体现:
即在spout中,正是我们数据的来源,又因为其实时的特性,所以可以把它比作一个“水龙头”,表示其源源不断地产生数据:

所以,问题的关键是spout如何去获取来自Kafka的数据?
好在,Storm-Kafka的整合库中提供了这样的API来供我们进行操作。
2整合过程
整合过程应用了KafkaSpout。在代码的逻辑中只需要创建一个由Storm-KafkaAPI提供的KafkaSpout对象即可:
SpoutConfig spoutConf = new SpoutConfig(hosts, topic, zkRoot, id);return new KafkaSpout(spoutConf);
下面给出完整的整合代码:
←
package cn.xpleaf.bigdata.storm.statics;
import kafka.api.OffsetRequest;
import org.apache.storm.Config;
import org.apache.storm.LocalCluster;
import org.apache.storm.StormSubmitter;
import org.apache.storm.generated.StormTopology;
import org.apache.storm.kafka.BrokerHosts;
import org.apache.storm.kafka.KafkaSpout;
import org.apache.storm.kafka.SpoutConfig;
import org.apache.storm.kafka.ZkHosts;
import org.apache.storm.topology.BasicOutputCollector;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.TopologyBuilder;
import org.apache.storm.topology.base.BaseBasicBolt;
import org.apache.storm.tuple.Tuple;
/**
* Kafka和storm的整合,用于统计实时流量对应的pv和uv
*/public class KafkaStormTopology {
// static class MyKafkaBolt extends BaseRichBolt {
static class MyKafkaBolt extends BaseBasicBolt {
/**
* kafkaSpout发送的字段名为bytes
*/
@Override
public void execute(Tuple input, BasicOutputCollector collector) {
byte binary = input.getBinary(0); // 跨jvm传输数据,接收到的是字节数据
// byte bytes = input.getBinaryByField("bytes"); // 这种方式也行
String line = new String(binary);
System.out.println(line);
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
public static void main(String[] args) throws Exception {
TopologyBuilder builder = new TopologyBuilder;
/**
* 设置spout和bolt的dag(有向无环图)
*/
KafkaSpout kafkaSpout = createKafkaSpout;
builder.setSpout("id_kafka_spout", kafkaSpout);
builder.setBolt("id_kafka_bolt", new MyKafkaBolt)
.shuffleGrouping("id_kafka_spout"); // 通过不同的数据流转方式,来指定数据的上游组件
// 使用builder构建topology
StormTopology topology = builder.createTopology;
String topologyName = KafkaStormTopology.class.getSimpleName; // 拓扑的名称
Config config = new Config; // Config对象继承自HashMap,但本身封装了一些基本的配置
// 启动topology,本地启动使用LocalCluster,集群启动使用StormSubmitter
if (args == || args.length < 1) { // 没有参数时使用本地模式,有参数时使用集群模式
LocalCluster localCluster = new LocalCluster; // 本地开发模式,创建的对象为LocalCluster
localCluster.submitTopology(topologyName, config, topology);
} else {
StormSubmitter.submitTopology(topologyName, config, topology);
* BrokerHosts hosts kafka集群列表
* String topic 要消费的topic主题
* String zkRoot kafka在zk中的目录(会在该节点目录下记录读取kafka消息的偏移量)
* String id 当前操作的标识id
*/
private static KafkaSpout createKafkaSpout {
String brokerZkStr = "uplooking01:2181,uplooking02:2181,uplooking03:2181";
BrokerHosts hosts = new ZkHosts(brokerZkStr); // 通过zookeeper中的/brokers即可找到kafka的地址
String topic = "f-k-s";
String zkRoot = "/" + topic;
String id = "consumer-id";
SpoutConfig spoutConf = new SpoutConfig(hosts, topic, zkRoot, id);
// 本地环境设置之后,也可以在zk中建立/f-k-s节点,在集群环境中,不用配置也可以在zk中建立/f-k-s节点
//spoutConf.zkServers = Arrays.asList(new String[]{"uplooking01", "uplooking02", "uplooking03"});
//spoutConf.zkPort = 2181;
spoutConf.startOffsetTime = OffsetRequest.LatestTime; // 设置之后,刚启动时就不会把之前的消费也进行读取,会从最新的偏移量开始读取
return new KafkaSpout(spoutConf);
(上下滑动查看完整代码)
其实代码的逻辑非常简单,我们只创建了 一个由Storm-Kafka提供的KafkaSpout对象和一个包含我们处理逻辑的MyKafkaBolt对象,MyKafkaBolt的逻辑也很简单,就是把Kafka的消息打印到控制台上。
需要注意的是,后面我们分析网站PV、UV的工作,正是在上面这部分简单的代码中完成的,所以其是非常重要的基础。
3整合验证
上面的整合代码,可以在本地环境中运行,也可以将其打包成jar包上传到我们的Storm集群中并提交业务来运行。如果Web服务器能够产生日志,并且前面Flume+Kafka的整合也没有问题的话,将会有下面的效果。
如果是在本地环境中运行上面的代码,那么可以在控制台中看到日志数据的输出:
如果是在Storm集群中提交的作业运行,那么也可以在Storm的日志中看到Web服务器产生的日志数据:
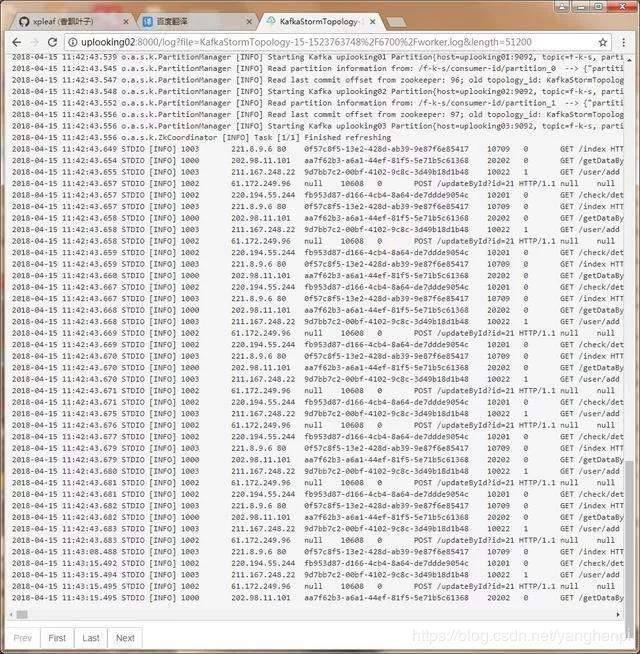
这样的话就完成了Kafka+Storm的整合。
Storm+Redis整合
1整合思路
其实所谓Storm和Redis的整合,指的是在我们的实时处理系统中的数据的落地方式,即在Storm中包含了我们处理数据的逻辑,而数据处理完毕后,产生的数据处理结果该保存到什么地方呢?显然就有很多种方式了,关系型数据库、NoSQL、HDFS、HBase等,这应该取决于具体的业务和数据量,在这里,我们使用Redis来进行最后分析数据的存储。
所以实际上做这一步的整合,其实就是开始写我们的业务处理代码了,因为通过前面Flume-Kafka-Storm的整合,已经打通了整个数据的流通路径,接下来关键要做的是,在Storm中,如何处理我们的数据并保存到Redis中。
而在Storm中,spout已经不需要我们来写了(由Storm-Kafka的API提供了KafkaSpout对象),所以问题就变成,如何根据业务编写分析处理数据的bolt。
2整合过程
整合过程:编写Storm业务处理Bolt。
日志分析
我们实时获取的日志格式如下:

其中需要说明的是第二个字段和第三个字段,因为它对我们统计PV和UV非常有帮助,它们分别是ip字段和mid字段,说明如下:
- ip:用户的IP地址
- mid:唯一的id,此id第一次会种在浏览器的cookie里。如果存在则不再种。作为浏览器唯一标示。移动端或者pad直接取机器码。
因此,根据IP地址,我们可以通过查询得到其所在的省份,并且创建一个属于该省份的变量,用于记录pv数,每来一条属于该省份的日志记录,则该省份的PV就加1,以此来完成pv的统计。
而对于mid,我们则可以创建属于该省的一个set集合,每来一条属于该省份的日志记录,则可以将该mid添加到set集合中,因为set集合存放的是不重复的数据,这样就可以帮我们自动过滤掉重复的mid,根据set集合的大小,就可以统计出UV。
在我们storm的业务处理代码中,我们需要编写两个bolt:
- 第一个bolt用来对数据进行预处理,也就是提取我们需要的ip和mid,并且根据IP查询得到省份信息;
- 第二个bolt用来统计PV、UV,并定时将PV、UV数据写入到Redis中。
当然上面只是说明了整体的思路,实际上还有很多需要注意的细节问题和技巧问题,这都在我们的代码中进行体现,我在后面写的代码中都加了非常详细的注释进行说明。
编写第一个Bolt:ConvertIPBolt
根据上面的分析,编写用于数据预处理的bolt,代码如下:
package cn.xpleaf.bigdata.storm.statistic;
import cn.xpleaf.bigdata.storm.utils.JedisUtil;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Tuple;
import org.apache.storm.tuple.Values;
import redis.clients.jedis.Jedis;
/**
* 日志数据预处理Bolt,实现功能:
* 1.提取实现业务需求所需要的信息:ip地址、客户端唯一标识mid
* 2.查询IP地址所属地,并发送到下一个Bolt
*/public class ConvertIPBolt extends BaseBasicBolt {
byte binary = input.getBinary(0);
String line = new String(binary);
String fields = line.split(" ");
if(fields == || fields.length < 10) {
return;
}
// 获取ip和mid
String ip = fields[1];
String mid = fields[2];
// 根据ip获取其所属地(省份)
String province = ;
if (ip != ) {
Jedis jedis = JedisUtil.getJedis;
province = jedis.hget("ip_info_en", ip);
// 需要释放jedis的资源,否则会报can not get resource from the pool
JedisUtil.returnJedis(jedis);
}
// 发送数据到下一个bolt,只发送实现业务功能需要的province和mid
collector.emit(new Values(province, mid));
* 定义了发送到下一个bolt的数据包含两个域:province和mid
declarer.declare(new Fields("province", "mid"));
编写第二个Bolt:StatisticBolt
这个bolt包含我们统计网站PV、UV的代码逻辑,因此非常重要,其代码如下:
import org.apache.storm.Constants;
import java.text.SimpleDateFormat;
import java.util.*;
/**
* 日志数据统计Bolt,实现功能:
* 1.统计各省份的PV、UV
* 2.以天为单位,将省份对应的PV、UV信息写入Redis
*/public class StatisticBolt extends BaseBasicBolt {
Map
Map
SimpleDateFormat sdf = new SimpleDateFormat("yyyyMMdd");
if (!input.getSourceComponent.equalsIgnoreCase(Constants.SYSTEM_COMPONENT_ID)) { // 如果收到非系统级别的tuple,统计信息到局部变量mids
String province = input.getStringByField("province");
String mid = input.getStringByField("mid");
pvMap.put(province, pvMap.get(province) + 1); // pv+1
if(mid != ) {
midsMap.get(province).add(mid); // 将mid添加到该省份所对应的set中
}
} else { // 如果收到系统级别的tuple,则将数据更新到Redis中,释放JVM堆内存空间
/*
* 以 广东 为例,其在Redis中保存的数据格式如下:
* guangdong_pv(Redis数据结构为hash)
* --20180415
* --pv数
* --20180416
* --pv数
* guangdong_mids_20180415(Redis数据结构为set)
* --mid
* ......
String dateStr = sdf.format(new Date);
// 更新pvMap数据到Redis中
String pvKey = ;
for(String province : pvMap.keySet) {
int currentPv = pvMap.get(province);
if(currentPv > 0) { // 当前map中的pv大于0才更新,否则没有意义
pvKey = province + "_pv";
String oldPvStr = jedis.hget(pvKey, dateStr);
if(oldPvStr == ) {
oldPvStr = "0";
}
Long oldPv = Long.valueOf(oldPvStr);
jedis.hset(pvKey, dateStr, oldPv + currentPv + "");
pvMap.replace(province, 0); // 将该省的pv重新设置为0
// 更新midsMap到Redis中
String midsKey = ;
HashSet
for(String province: midsMap.keySet) {
midsSet = midsMap.get(province);
if(midsSet.size > 0) { // 当前省份的set的大小大于0才更新到,否则没有意义
midsKey = province + "_mids_" + dateStr;
jedis.sadd(midsKey, midsSet.toArray(new String[midsSet.size()]));
midsSet.clear;
// 释放jedis资源
JedisUtil.returnJedis(jedis);
System.out.println(System.currentTimeMillis + "------->写入数据到Redis");
* 设置定时任务,只对当前bolt有效,系统会定时向StatisticBolt发送一个系统级别的tuple
public Map
Map
config.put(Config.TOPOLOGY_TICK_TUPLE_FREQ_SECS, 10);
return config;
* 初始化各个省份的pv和mids信息(用来临时存储统计pv和uv需要的数据)
*/
public StatisticBolt {
pvMap = new HashMap<>;
midsMap = new HashMap
String provinceArray = {"shanxi", "jilin", "hunan", "hainan", "xinjiang", "hubei", "zhejiang", "tianjin", "shanghai",
"anhui", "guizhou", "fujian", "jiangsu", "heilongjiang", "aomen", "beijing", "shaanxi", "chongqing",
"jiangxi", "guangxi", "gansu", "guangdong", "yunnan", "sicuan", "qinghai", "xianggang", "taiwan",
"neimenggu", "henan", "shandong", "shanghai", "hebei", "liaoning", "xizang"};
for(String province : provinceArray) {
pvMap.put(province, 0);
midsMap.put(province, new HashSet);
(上下滑动可查看完整代码)
编写Topology
我们需要编写一个topology用来组织前面编写的Bolt,代码如下:
* 构建topology
*/public class StatisticTopology {
builder.setBolt("id_convertIp_bolt", new ConvertIPBolt).shuffleGrouping("id_kafka_spout"); // 通过不同的数据流转方式,来指定数据的上游组件
builder.setBolt("id_statistic_bolt", new StatisticBolt).shuffleGrouping("id_convertIp_bolt"); // 通过不同的数据流转方式,来指定数据的上游组件
将上面的程序打包成jar包,并上传到我们的集群提交业务后,如果前面的整合没有问题,并且Web服务也有Web日志产生,那么一段时间后,我们就可以在Redis数据库中看到数据的最终处理结果,即各个省份的UV和PV信息:
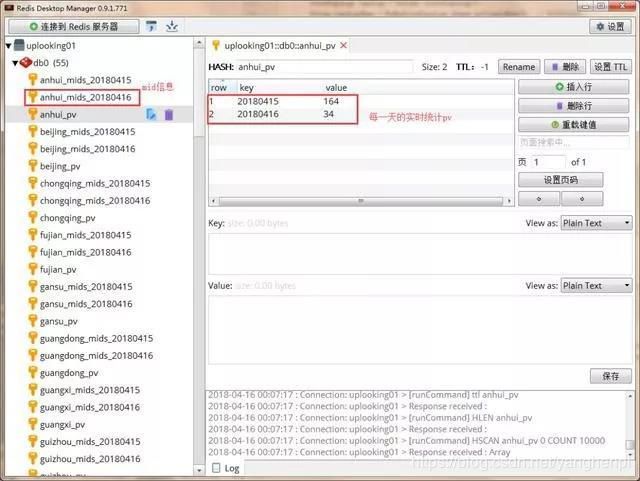
需要说明的是mid信息是一个set集合,只要求出该set集合的大小,也就可以求出UV值。
至此,准确来说,我们的统计PV、UV的大数据实时处理系统是构建完成了,处理的数据结果的用途根据不同的业务需求而不同,但是对于网站的PV、UV数据来说,是非常适合用作可视化处理的,即用网页动态将数据展示出来,我们下一步正是要构建一个简单的Web应用将PV、UV数据动态展示出来。
数据可视化处理

数据可视化处理目前我们需要完成两部分的工作:
- 开发一个Web项目,能够查询Redis中的数据,同时提供访问的页面
- 自行开发或找一个符合我们需求的前端UI,将Web项目中查询到的数据展示出来
对于Web项目的开发,因个人的技术栈能力而异,选择的语言和技术也有所不同,只要能够达到我们最终数据可视化的目的,其实都行的。这个项目中我们要展示的是PV和UV数据,难度不大,因此可以选择Java Web,如Servlet、SpringMVC等,或者Python Web,如Flask、Django等,Flask我个人非常喜欢,因为开发非常快,但因为前面一直用的是Java,因此这里我还是选择使用SpringMVC来完成。
至于UI这一块,我前端能力一般,普通的开发没有问题,但是要做出像上面这种地图类型的UI界面来展示数据的话,确实有点无能为力。好在现在第三方的UI框架比较多,对于图表类展示的,比如就有highcharts和echarts,其中echarts是百度开源的,有丰富的中文文档,非常容易上手,所以这里我选择使用echarts来作为UI,并且其刚好就有能够满足我们需求的地图类的UI组件。
因为难度不大,具体的开发流程的这里就不提及了,有兴趣的同学可以直接参考后面我提供的源代码,这里我们就直接来看一下效果好了。
因为实际上在本次项目案例中,这一块的代码也是非常少的,使用SpringMVC开发的话,只要把JavaEE三层构架搭起来了,把依赖引入好了,后面的开发确实不难的;而如果有同学会Flask或者Django的话,其项目本身的构建和代码上也都会更容易。
启动我们的Web项目后,输入地址就可以访问到数据的展示界面了:

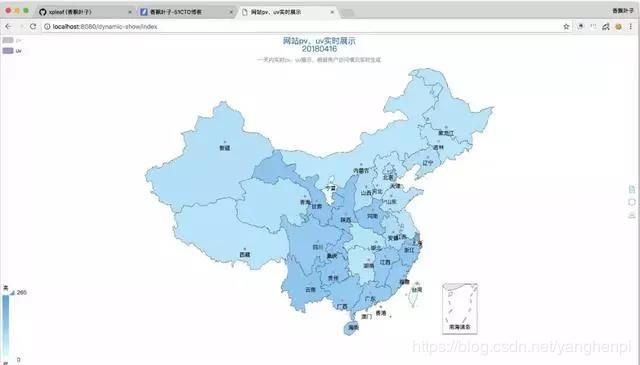
可以看到,echarts的这个UI还是比较好看的,而且也真的能够满足我们的需求。每个省份上的两个不同颜色的点表示目前我们需要展示的数据有两种,分别为PV和UV,在左上角也有体现,而颜色的深浅就可以体现PV或者UV的数量大小关系了。
在这个界面上,点击左上角的UV,表示不查看UV的数据,这样我们就会只看到PV的情况:

当然,也可以只查看UV的情况:
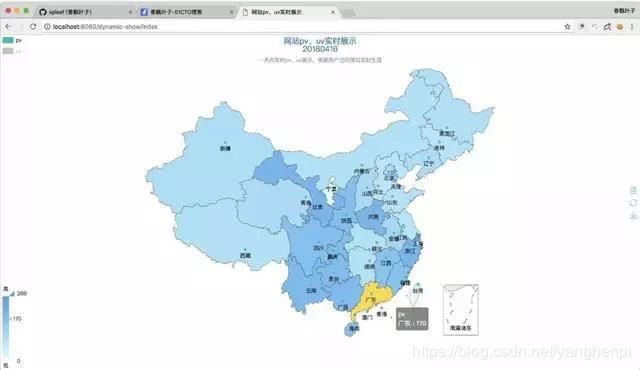
当鼠标停留在某个省份上时,就可以查看这个省份具体的PV或UV值,比如下面我们把鼠标停留在“广东”上时,就可以看到其此时的PV值为170,查看其它省份的也是如此:
那么数据是可以查看了,又怎么体现动态呢?
对于页面数据的动态刷新有两种方案,一种是定时刷新页面,另外一种则是定时向后端异步请求数据。
目前我采用的是第一种,页面定时刷新,有兴趣的同学也可以尝试使用第二种方法,只需要在后端开发相关的返回JSON数据的API即可。
总结
那么至此,从整个大数据实时处理系统的构建到最后的数据可视化处理工作,我们都已经完成了,可以看到整个过程下来涉及到的知识层面还是比较多的,不过我个人觉得,只要把核心的原理牢牢掌握了,对于大部分情况而言,环境的搭建以及基于业务的开发都能够很好地解决。