关于数据库的几点思考
01 关于select* from table
首先假定一定要取出表的所有字段内容,那么直接用*和把所有字段全部罗列出来有什么区别呢
a 效率问题,用*在分析sql语句时,会多一步字段的检索(比如 oracle 在解析时, 会将 *依次转换成所有的列名, 这个工作是通过查询数据字典完成的, 耗费更多的时间)
b sql语句经常出现在数据访问层中的java类中,将所有字段列出来而不是用*代替会使程序可读性增加,另外在数据库表修改后,也不会造成过多程序修改的麻烦。
02 DB设计时用long类型代替Data类型
https://blog.csdn.net/csdnljp/article/details/80103324
a mysql中关于时间的存储类型:
data:3字节,0000-01-01——9999-12-31
datatime:8字节,0000-01-01 00:00:00——9999-12-31 23:59:59
timestamp:4字节,19700101080001——20380119111407(timestamp类型适合用来记录数据的最后修改时间,因为只要你更改了记录中其他字段的 值,timestamp字段的值都会被自动更新。)
bigint:相当于java中的long, 8字节 -264——264
b 不同精度问题
java中对时间处理的类比较混乱:java.util.Date,java.sql.Date ,java.sql.Time ,java.sql.Timestamp,java.util.Calendar ,java.util.TimeZone
JDBC中定义接口时,用java.sql.Date。而java常用java.util.Date,导致转换误差(java.util.Date转为java.sql.Date时,数据精度降低,时分秒被去掉)
java.sql.Timestamp保持了数据原有精度,可以实现和java.util.Date的无损转换。但是Timestamp在一些预定义SQL中常常会出问题
c 用long(bigint)类型代替Data类型
有利于计算时间差、java与数据库之间的传输
long login_at = System.currentTimeMillis( )获取当前时间的long类型
Date date1=new Date( )获取当前时间 long time=date1.getTime()将其转化为long类型
03 自增id有什么坏处?什么样的场景下不使用自增id
http://lesson.jnshu.com/l/subjectContent/305/?id=&lobtn=2
自增id的坏处:
a 不具有连续性 对表中某条记录删除后,对应id将不会再利用(例如删除末尾id=1000的记录后再增添记录,默认id=1001)。
b 需要合并表时,如果两张表都以自增id作主键,会产生冲突,如果各自id另外关联了其他的表,操作困难。
c 在系统集成或割接时,如果新旧系统主键数字类型不同,导致修改主键数据类型,从而导致其它有外键关联的表的修改。
所以在需要分库分表时,不要用自增id
对于分布式系统,慎用自增id,对于20个节点以下的小型分布式架构,为了实现快速部署,主键不重复,可以采用UUID。
对于节点数较多的分布式系统,可以采用twitter的雪花算法全局自增ID。
04 索引
https://www.cnblogs.com/aspwebchh/p/6652855.html
https://www.cnblogs.com/hzy1991/p/8567334.html 数据库索引内部结构
a 索引是什么
索引是帮助MySQL高效获取数据的数据结构,mysql支持多种索引类型:BTree、hash等。
b 什么情况下建立索引
表的主键上一定有索引:主键索引,是聚集索引(表中行的物理顺序与键值的逻辑(索引)顺序相同。一个表只能包含一个聚集索引)
外键有索引(经常与其它表进行连接的表,在连接字段上应该建议索引)
表的数据量大时,在选择性高的、频繁出现在where条件中的字段建立索引
c 创建索引注意事项
索引提高了查询的速度,但降低了数据库更新速度,因此需要严格控制表上的索引数目,一般不要超过3个,最多不要超过5个
避免在取值朝一个方向增长字段上建立索引,由于字段的取值总是朝一个方向增长,新记录i总是放在索引的最后一页中,从而不断的引起该页的访问竞争
05 数据类型 varchar、Text和LongText
三者均为变长字符串类型,最大长度不同,分别为65535,65535,4294967295(2^32-1)
空间占用:
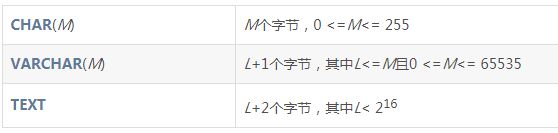
varchar和text区别:
varchar可以指定最大长度,如varchar(10)表示最大字符长度为10。
经常变化的字段用varchar
知道固定长度的用char,如手机号、邮政编码等
尽量用varchar,能用varchar的地方不要用text
超过255字节的只能用varchar或者text
如果一定要用text或longtext,从主表中分离出去建新表,保证主表不要太庞大
06 B树,B+树
B+树与B树相比,非叶节点的孩子数和元素树相同,非叶结点仅具有索引作用,跟记录有关的信息均存放在叶结点中;树的所有叶结点构成一个有序链表,可以按照元素的排序次序遍历全部记录。mysql的数据结构可以基于B+树。
https://blog.csdn.net/yangjie123_/article/details/88863283