MySQL数据库详解
1、MySQL存储引擎
分为两种:MyISAM和InnoDB,MySQL默认的存储引擎是MyISAM,其他常用的就是InnoDB,InnoDB比较常用。
区别:
- 存储结构:
MyISAM:每张表存在三个文件中,xxx.frm文件存储表定义;xxx.MYD文件存储表数据;xxx.MYI文件存储表索引。
InnoDB:所有的表都保存在同一个数据文件中(也可能是多个文件,或者是独立的表空间文件),InnoDB表的大小只受限于操作系统文件的大小,一般为2GB
- 存储空间:
MyISAM:可被压缩,存储空间较小。索引和数据是分开的,并且索引有压缩,能使用更多的索引,所以内存使用率比较高。
InnoDB:需要更多的内存和存储,会在内存中简历专用的缓冲池用于高速缓冲数据和索引。索引和数据紧密捆绑,索引无压缩,所以体积相对比较大。
- 事务处理:
MyISAM:不支持外键,不支持事务。
InnoDB:支持外键,支持事务。
- 锁:
MyISAM:只支持表级锁,所有操作都会给表加锁,包括select。
InnoDB:支持表锁、行锁。行锁提高了多用户并发操作的性能,全文索引
MyISAM:支持 FULLTEXT类型的全文索引。不支持中文。
InnoDB:不支持FULLTEXT类型的全文索引,但是innodb可以使用sphinx插件支持全文索引,并且效果更好。优劣:
MyISAM更适合(1)做很多count的计算。(2)插入不频繁,查询非常频繁。(3)没有事务
InnoDB更适合(1)可靠性要求高,要求事务。(2)更新和擦汗寻都相当频繁,表锁定的机会比较大。
2、MySQL中InnoDB
- 事务隔离
事务属性:原子性、一致性、隔离性、持久性
并发事务带来的问题:更新丢失、脏读、幻读、不可重复读
查询数据库设置的隔离级别:select @@global.tx_isolation

a、Read Uncommited
可以读取未提交记录。此隔离级别不会使用,忽略。
b、Read Commited (RC)
RC隔离级别保证对读取到的记录加锁(记录锁),存在幻读现象。
c、Repeatable Read (RR)
RR隔离级别保证对读取到的记录加锁(记录锁),同时保证对对读取的范围加锁,新的满足查询条件的记录不能够插入(间隙锁),不存在 幻读现象。
d、Serializable
从MVCC并发控制退化为基于锁的并发控制。不区分快照读和当前读,所有的度操作均为当前读,读加读锁(S锁),写加写锁(X锁)。Serializable隔离级别下,读写冲突,因此并发度急剧下降,在mysql/InnoDB不建议使用。
四个事务隔离级别的特性:
- 锁
锁类型:
MySQL的锁机制比较简单,其中最显著的特点是不同的存储引擎支持不同的锁机制。MyISAM和MEMORY存储引擎采用的表级锁(table-level locking);BDB存储引擎采用的是页面锁(page-level locking),也支持表级锁(table-level locking);InnoDB存储引擎既支持行级锁(row-level locking),也支持表级锁,默认采用行级锁。
表级锁:开销小,加锁快;不会出现死锁;锁定粒度大,发生锁冲突的概率最高,并发最低。
行级锁:开销大,枷锁慢;会出现死锁;锁粒度最小;发生锁冲突的概率最低,并发最高。
页面锁:开销和加锁时间界于表锁和行锁之间;会出现死锁;锁定粒度界于表锁和行锁之间,并发度一般。
InnoDB获取行锁争夺情况:
执行:show status like 'innodb_row_lock%';
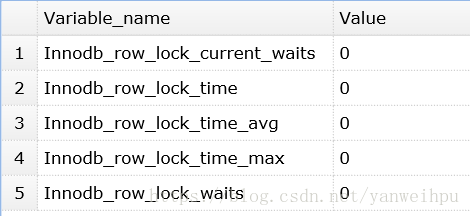
如果发现锁争用比较严重,如InnoDB_row_lock_waits和InnoDB_row_lock_time_avg的值比较高,还可以通过设置InnoDB Monitors来进一步观察发生锁冲突的表、数据行等,并分析锁争用的原因
InnoDB行锁模式及加锁方式:
- 共享锁(s):允许一个事务去读一行,阻止其他事务获得相同数据集的排他锁。
- 排他锁(X):允许获取排他锁的事务更新数据,阻止其他事务取得相同的数据集共享读锁和排他写锁。
- 意向共享锁(IS):事务打算给数据行共享锁,事务在给一个数据行加共享锁前必须先取得该表的IS锁。
- 意向排他锁(IX):事务打算给数据行加排他锁,事务在给一个数据行加排他锁前必须先取得该表的IX锁。
间隙锁:
当我们用范围条件而不是相等条件检索数据,并请求共享或排他锁时,InnoDB会给符合条件的已有数据的索引项加锁;对于键值在条件范围内但并不存在的记录,叫做“间隙(GAP)”,InnoDB也会对这个“间隙”加锁,这种锁机制不是所谓的间隙锁(Next-Key锁)。
SELECT * FROM emp WHERE empid > 100 FOR UPDATE
3、MySQL的MyISAM
MyISAM只有表锁,且没有事务。
表级锁有两种模式:表共享读锁(Table Read Lock)和表独占写锁(Table Write Lock)
对MyISAM表的读操作,不会阻塞其他用户对同一表的读请求,但会阻塞对同一表的写请求;对 MyISAM表的写操作,则会阻塞其他用户对同一表的读和写操作;MyISAM表的读操作与写操作之间,以及写操作之间是串行的查看表级锁争用情况:
执行:show status like 'table%'
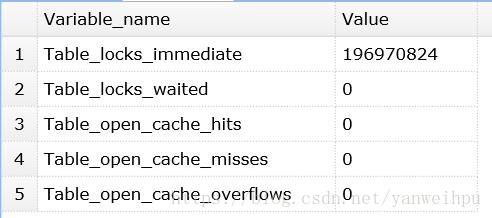
如果Table_locks_waited的值比较高,则说明存在着较严重的表级锁争用情况
并发插入:
MyISAM表的读和写是串行的,但这是就总体而言的。在一定条件下,MyISAM表也支持查询和插入操作的并发进行。
MyISAM存储引擎有一个系统变量concurrent_insert,专门用以控制其并发插入的行为,其值分别可以为0、1或2。
- 当concurrent_insert设置为0时,不允许并发插入。
- 当concurrent_insert设置为1时,如果MyISAM表中没有空洞(即表的中间没有被删除的行),MyISAM允许在一个进程读表的同时,另一个进程从表尾插入记录。这也是MySQL的默认设置。
- 当concurrent_insert设置为2时,无论MyISAM表中有没有空洞,都允许在表尾并发插入记录。
4、数据字段类型
MySQL持所有标准的SQL数据类型,主要分3类:
- 数值类型
- 字符串类型
- 时间日期类型
数值类型:
整数类型:TINYINT、SMALLINT、MEDIUMINT、INT、BIGINT
定点数:DECIMAL、NUMERIC。定义方式:DECIMAL(M,D)
浮点数:float、double、real。定义方式:FLOAT(M,D)、DOUBLE PRECISION (M,D)、REAL(M,D)
字符串类型:
CHAR、VARCHAR、BINARY、VARBINARY、BLOB、TEXT、ENUM、SET
CHAR:长度范围0-255
VARCHAR:长度范围0-65536
BINARY、VARBINARY:存储二进制串
日期类型:

1、为DATETIME或TIMESTAMP对象分配一个DATE值,结果值的时间部分被设置为'00:00:00'。
2、为一个DATE对象分配一个DATETIME或TIMESTAMP值,结果值的时间部分被删除。
3、DATETIME、DATE和TIMESTAMP值,不同类型的值的范围却不同。例如,TIMESTAMP值不能早于1970或晚于2037。这说明一个日期,例如'1968-01-01',虽然对于DATETIME或DATE值是有效的,但对于TIMESTAMP值却无效
4、MySQL使用以下规则解释两位年值: 00-69范围的年值转换为2000-2069。 70-99范围的年值转换为1970-1999
5、无效TIME值被转换为'00:00:00'
6、MySQL以YYYY格式检索和显示YEAR值,范围是1901到2155
7、YEAR值中'00'到'69'和'70'到'99'范围的值被转换为2000到2069和1970到1999范围的YEAR值。
8、非法YEAR值被转换为0000
5、索引
MySQL中常用的索引结构有:B+树索引和哈希索引两种。目前建表用的B+树索引就是BTREE索引。
在MySQL中,MyISAM和InnoDB两种存储引擎都不支持哈希索引。只有HEAP/MEMORY引擎才能显示支持哈希索引。
创建索引:
CREATE TABLE userInfo(
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '主键',
`username` varchar(3) NOT NULL COMMENT '用户名',
`age` int(10) NOT NULL COMMENT '年龄',
`addr` varchar(40) NOT NULL COMMENT '地址',
PRIMARY KEY (`id`),
KEY `ind_user_info_username` (`username`) USING BTREE, --此处普通索引
key 'ind_user_info_username_addr' ('username_addr') USING BTREE, --此处联合索引
unique key(uid) USINGBTREE, --此处唯一索引
key 'ind_user_info_addr' (addr(12)) USINGBTREE —-此处 addr列只创建了最左12个字符长度的部分索引
)ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='用户表';索引类型:
唯一索引、主键索引、外键索引、普通索引,复合索引
索引优化查询:
A、关联查询时,保证关联的字段都建立索引,并且字段类型一致,这样才能两个表都使用索引。如果字段类型不一样,至少一个表不能使用索引。
B、索引列如果使用like条件进行查询,那么 like 'xxx%' 可以使用索引,like '%xxx' 不能使用索引。
C、复合索引,如果创建了一个(username,age,addr)的复合索引,那么相当于创建了(username,age,addr),(username,age),(username)三个索引,所以在创建复合索引的时候应该将最常用的限制条件的列放在最左边,依次递减。
D、索引列的值最好不要有null值。列中只要包含null,则不会被包含到索引中,复合索引中只要有一列为null值,则这个复合索引失效的。所以创建索引列不要设置默认值null
E、字符串列加索引最好加短索引,即对前该列的前xx个字符,例如:key 'ind_user_info_addr' (addr(10)) USINGBTREE代表对addr列的前10个字符家索引。
F、如果where条件中使用了一个列的索引,那么后面order by 在用这个列进行排序时,便不会再使用索引。
6、数据库优化
- 关联查询中的inner join 和左连接、右连接、子查询
A、inner join 内连接也叫做等值连接,left/right join 是外连接。能用inner join连接的尽量用inner join连接
B、尽量使用外连接来替换子查询。
C、在使用on和where的时候,先用on,在用where。
D、使用join时,用小的结果驱动大的结果(left join左表结果尽量小,如果有条件,先放左边处理,right join同理反向)。
E、多表联合查询尽量拆分多个简单的sql语句进行查询。
- 建立索引,加快查询性能
A、where条件用到复合索引中的字段时,最好把该字段放在复合索引的左端,这样才能使用索引提高查询。
B、保证连接的索引是相同类型。即a.age = b.age,a表的和b表的age字段类型保证一样,并且都建立了索引。
C、在使用like一个字段的索引时,like 'xxx%'能用到索引,like '%xxx'不能用到索引。
D、复合索引的使用:如果我们建立了一个(name,age,addr)的复合索引,那么相当于创建了(name,age,addr)、(name,age)、(name)三个索引。这样就把常用的限制条件放到最左边,依次递减。
E、索引列不要包含NULL值的列。所以数据库设计时,尽量不让字段默认为NULL。
F、使用短索引,对于字符串的索引,应指定一个前缀长度,体积高查询速度并且可以节省磁盘空间和I/O操作。
G、排序索引。尽量不要使用包含多个列的排序,如果需要则给这些列加上复合索引。
- limit千万级分页优化
A、select * from A order by id limit 1000000,10; 查询更换成select * from A where id between 1000000 and 1000010;
- 尽量避免select * 的查询
- 尽量不要使用BY RAND()命令
- 利用limit 1取得唯一行。使用limit 1可以终止数据库引擎继续扫描整个表或者索引
- 减少排序order by
- 少用OR
- 避免类型转换,也就是转入的参数类型要和字段类型一致
- 不要在列上进行运算。
- 尽量不要使用not in 和<> 操作
A、not in 和<>操作都不会使用索引,而是进行全表扫描。
B、把not in 转化为 left join 操作。
- 使用批量插入操作代替一个一个插入
- 对于多表查询可以建立视图。
7、数据库原则
(1)不在数据库做运算:cpu计算务必移至业务层
(2)控制单表数据量:单表记录控制在1000w
(3)控制列数量:字段数控制在20以内
(4)平衡范式与冗余:为提高效率牺牲范式设计,冗余数据
(5)拒绝3B:拒绝大sql,大事物,大批量
参考资料:
https://www.cnblogs.com/lsxuejava/p/7305920.html
https://blog.csdn.net/soonfly/article/details/70238902