深度学习经典网络(3)GoogleNet网络结构详解
0.背景
获得高质量模型最保险的做法就是增加模型的深度(层数)或者是其宽度(每一层卷积核数或者神经元数),但是这里一般设计思路的情况下会出现如下的缺陷:
1.参数太多,若训练数据集有限,容易过拟合;
2.网络越大计算复杂度越大,难以应用;
3.网络越深,梯度越往后穿越容易消失,难以优化模型。
解决上述两个缺点的根本方法是将全连接甚至一般的卷积都转化为稀疏连接。为了打破网络对称性和提高学习能力,传统的网络都使用了随机稀疏连接。但是,计算机软硬件对非均匀稀疏数据的计算效率很差,
所以在AlexNet中又重新启用了全连接层,目的是为了更好地优化并行运算。现在的问题是有没有一种方法,
既能保持网络结构的稀疏性,又能利用密集矩阵的高计算性能。

1. Inception模块介绍
Inception架构的主要思想是找出如何用密集成分来近似最优的局部稀疏解。
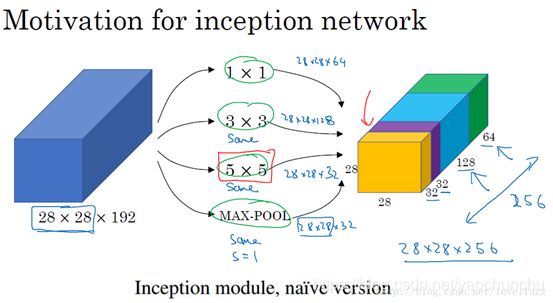
对上图做以下说明:
1 . 采用不同大小的卷积核意味着不同大小的感受野(1×1,3×3,5×5),最后拼接意味着不同尺度特征的融合;
2 . 之所以卷积核大小采用1*1、3*3和5*5,主要是为了方便对齐。设定卷积步长stride=1之后,只要分别设定padding =0、1、2,采用same卷积可以得到相同维度的特征,然后这些特征直接拼接在一起;
3 . 文章说很多地方都表明pooling挺有效,所以Inception里面也嵌入了pooling。
4 . 网络在越靠前时,感受野越小,关注到的越细节(汽车的细节纹理),所以根本看不出来特征是什么。越到后面特征越抽象,且每个特征涉及的感受野也更大(车轮,车身),所以越到后面越能看清特征是什么东西。随着层数的增加,3x3和5x5卷积的比例也要增加。
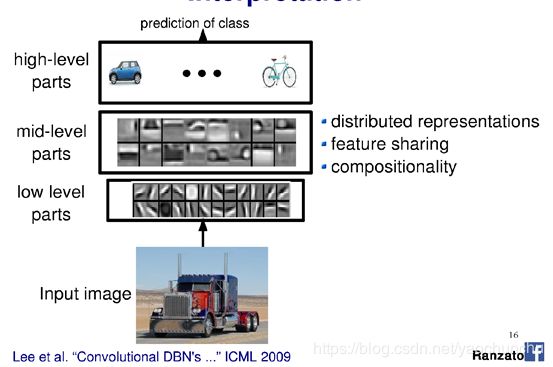
Inception的作用:代替人工确定卷积层中的过滤器类型或者确定是否需要创建卷积层和池化层,即:不需要人为的决定使用哪个过滤器,是否需要池化层等,由网络自行决定这些参数,可以给网络添加所有可能值,将输出连接起来,网络自己学习它需要什么样的参数,采用哪些过滤器组合。
naive版本的Inception网络的缺陷:计算成本。使用5x5的卷积核仍然会带来巨大的计算量,约需要1.2亿次的计算量。下面我们来解释下为什么是这么多的计算量。注意:这个不是参数量的计算,是计算量的计算。

我们来计算这个28×28×32输出的计算成本,卷积核是32个5*5*192的,所以输出有32个通道,每个卷积核大小为5×5×192,输出大小为28×28×32,所以你要计算28×28×32个数字。
对于输出中的每个数字来说,你都需要执行5×5×192次乘法运算,所以乘法运算的总次数为每个输出值所需要执行的乘法运算次数(5×5×192)乘以输出值个数(28×28×32),把这些数相乘结果等于1.2亿(120422400)。
为减少计算成本,采用1x1卷积核来进行降维。 示意图如下:
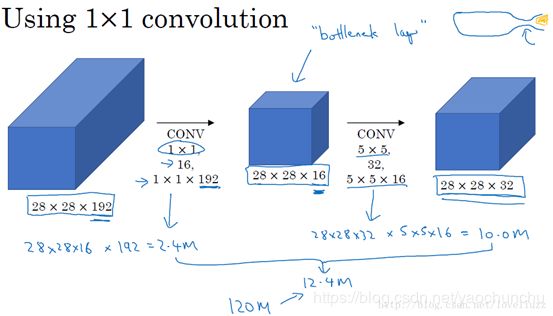
对于输入层,使用1×1卷积把输入值从192个通道减少到16个通道。然后对这个较小层运行5×5卷积,得到最终输出。请注意,输入和输出的维度依然相同,输入是28×28×192,输出是28×28×32。但我们要做的就是把左边这个大的输入层压缩成这个较小的的中间层,它只有16个通道,而不是192个。

有时候这被称为瓶颈层(bottleneck),瓶颈通常是某个对象最小的部分,假如你有这样一个玻璃瓶,这是瓶塞位置,瓶颈就是这个瓶子最小的部分。
同理,瓶颈层也是网络中最小的部分,我们先缩小网络表示,然后再扩大它。
接下来我们看看这个计算成本,应用1×1卷积,过滤器个数为16,每个过滤器大小为1×1×192,这两个维度相匹配(输入通道数与过滤器通道数),28×28×16这个层的计算成本是,输出28×28×192中每个元素都做192次乘法,用1×1×192来表示,相乘结果约等于240万。
那第二个卷积层呢?240万只是第一个卷积层的计算成本,第二个卷积层的计算成本又是多少呢?这是它的输出,28×28×32,对每个输出值应用一个5×5×16维度的过滤器,计算结果为1000万。
所以所需要乘法运算的总次数是这两层的计算成本之和,也就是1204万,与上一图中的值做比较,计算成本从1.2亿下降到了原来的十分之一,即1204万。所需要的加法运算与乘法运算的次数近似相等,所以我只统计了乘法运算的次数。
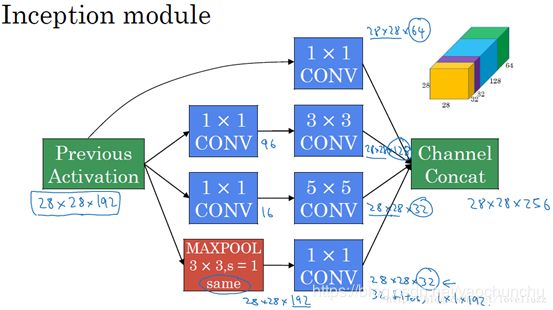
得到最终版本的Inception模块:
2. googLeNet介绍
1、googLeNet—Inception V1结构
googlenet的主要思想就是围绕这两个思路去做的:
(1).深度,层数更深,文章采用了22层,为了避免上述提到的梯度消失问题,googlenet巧妙的在不同深度处增加了两个loss来保证梯度回传消失的现象。
(2).宽度,增加了多种核 1x1,3x3,5x5,还有直接max pooling的,
但是如果简单的将这些应用到feature map上的话,concat起来的feature map厚度将会很大,所以在googlenet中为了避免这一现象提出的inception具有如下结构,在3x3前,5x5前,max pooling后分别加上了1x1的卷积核起到了降低feature map厚度的作用。
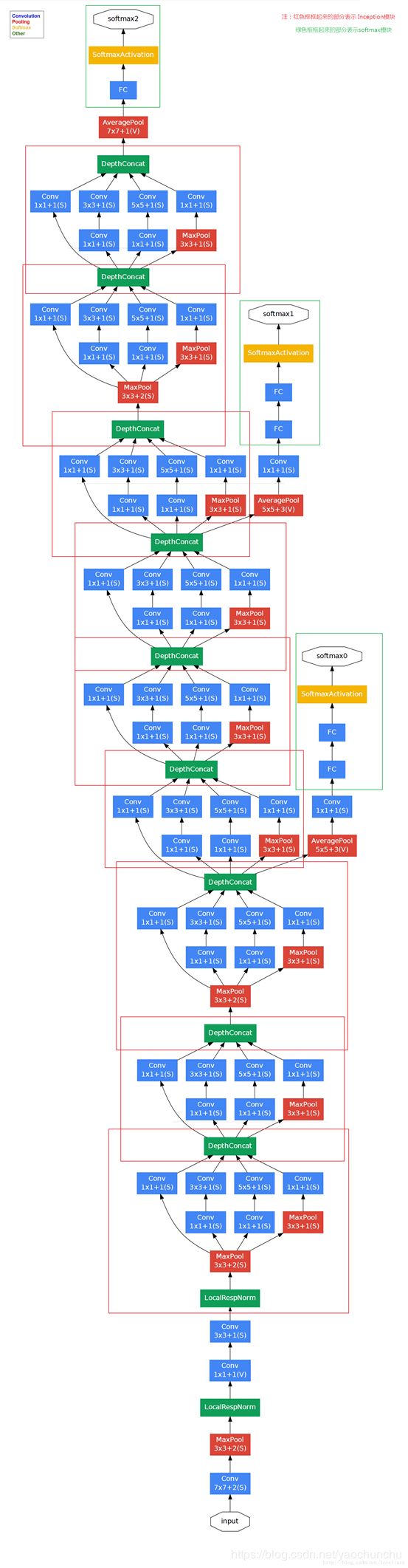
对上图做如下说明:
(1)显然GoogLeNet采用了Inception模块化(9个)的结构,共22层,方便增添和修改;
(2)网络最后采用了average pooling来代替全连接层,想法来自NIN,参数量仅为AlexNet的1/12,性能优于AlexNet,事实证明可以将TOP1 accuracy提高0.6%。但是,实际在最后还是加了一个全连接层,主要是为了方便finetune;
(3)虽然移除了全连接,但是网络中依然使用了Dropout ;
(4)为了避免梯度消失,网络额外增加了2个辅助的softmax用于向前传导梯度。文章中说这两个辅助的分类器的loss应该加一个衰减系数,但看caffe中的model也没有加任何衰减。此外,实际测试的时候,这两个额外的softmax会被去掉。
(5)上述的GoogLeNet的版本成它使用的Inception V1结构。
2、Inception V2结构
大尺寸的卷积核可以带来更大的感受野,也意味着更多的参数,比如5x5卷积核参数是3x3卷积核的25/9=2.78倍。
首先,GoogLeNet V1出现的同期,性能与之接近的大概只有VGGNet了,并且二者在图像分类之外的很多领域都得到了成功的应用。但是相比之下,GoogLeNet的计算效率明显高于VGGNet,大约只有500万参数,只相当于Alexnet的1/12(GoogLeNet的caffemodel大约50M,VGGNet的caffemodel则要超过600M)。
GoogLeNet的表现很好,但是,如果想要通过简单地放大Inception结构来构建更大的网络,则会立即提高计算消耗。此外,在V1版本中,文章也没给出有关构建Inception结构注意事项的清晰描述。因此,在文章中作者首先给出了一些已经被证明有效的用于放大网络的通用准则和优化方法。这些准则和方法适用但不局限于Inception结构。
General Design Principles
下面的准则来源于大量的实验,因此包含一定的推测,但实际证明基本都是有效的。
1 . 避免表达瓶颈,特别是在网络靠前的地方。 信息流前向传播过程中显然不能经过高度压缩的层,即表达瓶颈。从input到output,feature map的宽和高基本都会逐渐变小,但是不能一下子就变得很小。比如你上来就来个kernel = 7, stride = 5 ,这样显然不合适。 另外输出的维度channel,一般来说会逐渐增多(每层的num_output),否则网络会很难训练。(特征维度并不代表信息的多少,只是作为一种估计的手段)
2 . 高维特征更易处理。 高维特征更易区分,会加快训练。
3. 可以在低维嵌入上进行空间汇聚而无需担心丢失很多信息。 比如在进行3x3卷积之前,可以对输入先进行降维而不会产生严重的后果。假设信息可以被简单压缩,那么训练就会加快。
4 . 平衡网络的宽度与深度。
为此,作者提出可以用2个连续的3x3卷积层(stride=1)组成的小网络来代替单个的5x5卷积层,这便是Inception V2结构,保持感受野范围的同时又减少了参数量,如下图:
2个3×3可以当做1个5×5,3个3×3可以当做1个7×7,但是拆成3×3之后可以进一步减少参数个数,但是实际的感受野不会发生改变。
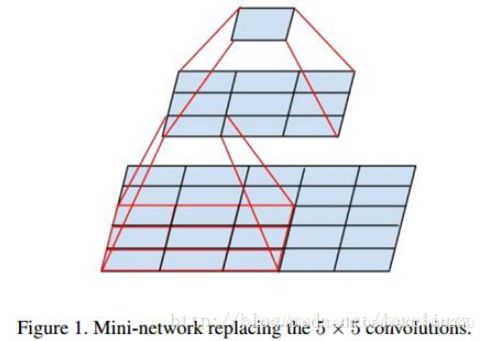



然后就会有2个疑问:
1 . 这种替代会造成表达能力的下降吗?
后面有大量实验可以表明不会造成表达缺失;
2 . 3x3卷积之后还要再加激活吗?
作者也做了对比试验,表明添加非线性激活会提高性能。
3、Inception V3结构
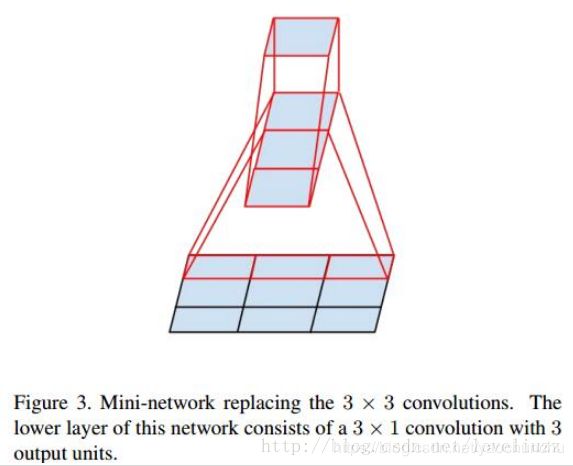
大卷积核完全可以由一系列的3x3卷积核来替代,那能不能分解的更小一点呢。
文章考虑了nx1 卷积核,如下图所示的取代3x3卷积:于是,任意nxn的卷积都可以通过1xn卷积后接nx1卷积来替代。实际上,作者发现在网络的前期使用这种分解效果并不好,还有在中度大小的feature map上使用效果才会更好,对于mxm大小的feature map,建议m在12到20之间。
用nx1卷积来代替大卷积核,这里设定n=7来应对17x17大小的feature map。该结构被正式用在GoogLeNet V2中。



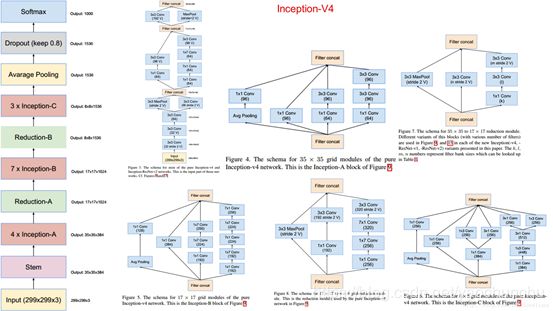
4、Inception V4结构:它结合了残差神经网络ResNet
参考链接:http://blog.csdn.net/stdcoutzyx/article/details/51052847
http://blog.csdn.net/shuzfan/article/details/50738394#googlenet-inception-v2
5、Inception—ResNet V1 & Inception—ResNet V2
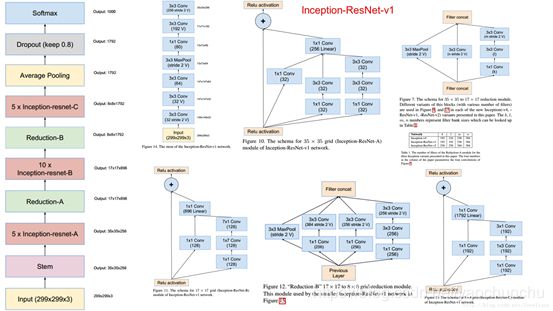
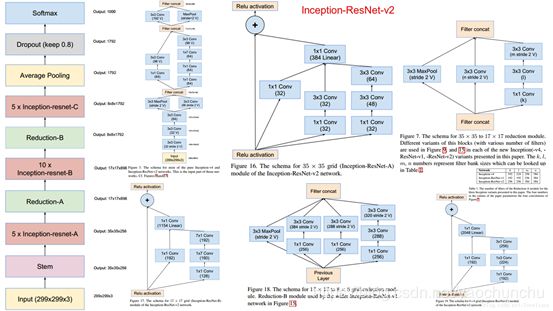
参考文献:
https://blog.csdn.net/loveliuzz/article/details/79135583
https://www.jianshu.com/p/3981df5f1f19