12使用FP-growth算法来高效发现频繁项集
第12章 使用FP-growth算法来高效发现频繁项集
一、背景
大家都用过搜索引擎。当我们输入一个单词或单词的一份,搜索引擎就会自动补全查询词项。例如:当我们在百度输入“为什么”时,会出现很多的推荐结果。为了给出这些推荐查词词项,公司的研究人员使用了本本章将要介绍的一个算法–FP-growth算法,高效发现频繁项集的方法。
FP-growth 算法优缺点:
优点: 1. 因为 FP-growth 算法只需要对数据集遍历两次,所以速度更快。
2. FP树将集合按照支持度降序排序,不同路径如果有相同前缀路径共用存储空间,使得数据得到了压缩。
3. 不需要生成候选集。
4. 比Apriori更快。
缺点: 1. FP-Tree第二次遍历会存储很多中间过程的值,会占用很多内存。
2. 构建FP-Tree是比较昂贵的。
适用数据类型:标称型数据(离散型数据)。
二、FP-growth 算法
在 第11章 时我们已经介绍了用 Apriori 算法发现 频繁项集 与 关联规则。
本章将继续关注发现 频繁项集 这一任务,并使用 FP-growth 算法更有效的挖掘 频繁项集。
1.FP-growth 算法简介
- 一种非常好的发现频繁项集算法。
- 它基于Apriori算法构建,将数据集存储在叫做
FP树的数据结构中。 - FP-growth只能高效地发现频繁项集,不能用于发现关联规则。
2.FP-growth 算法步骤
Fp-growth只需对数据进行两次扫描,因此比Apriori速度快
-
基于数据构建FP树
-
从FP树种挖掘频繁项集
3.FP树介绍
FP-growth算法将数据存储在FP树的结构中。FP代表频繁模式(Frequent Pattern)
一个元素项可以在FP树中出现多次,相同元素通过链接来连接起来
FP树的节点结构如下:
class treeNode:
def __init__(self, nameValue, numOccur, parentNode):
self.name = nameValue # 节点名称
self.count = numOccur # 节点出现次数
self.nodeLink = None # 不同项集的相同项通过nodeLink连接在一起
self.parent = parentNode # 指向父节点
self.children = {} # 存储叶子节点
三、FP-growth的流程和原理
1.FP-growth的一般流程
1.收集数据:使用任意方法
2.准备数据:由于存储的集合,所以需要离散数据。如果要处理连续数据,需要将他们量化为离散值
3.分析数:使用任意方法
4.训练算法:构建一个FP树,并对树进行挖掘
5.测试算法:没有测试过程
6.使用算法:可用于识别经常出现的元素项,从而用于制定决策,推荐元素或进行预测等应用中
2.FP-growth 原理
1)基于数据构建FP树
步骤1:
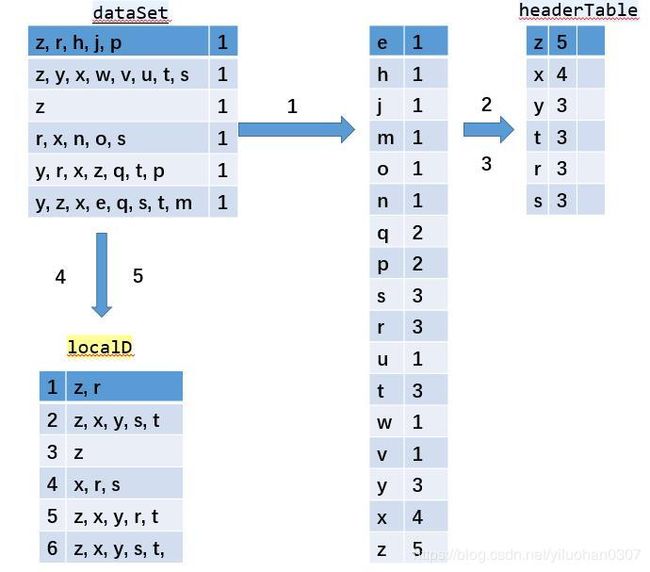
- 遍历所有的数据集合,计算所有项的支持度。
- 丢弃非频繁的项。
- 基于 支持度 降序排序所有的项。
- 所有数据集合按照得到的顺序重新整理。
- 重新整理完成后,丢弃每个集合末尾非频繁的项。
步骤2:
读取每个集合插入FP树中,同时用一个头部链表数据结构维护不同集合的相同项。
过程如下图所示:
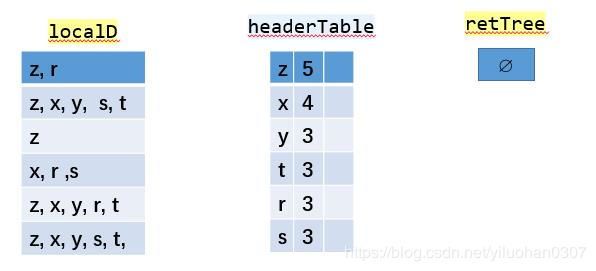
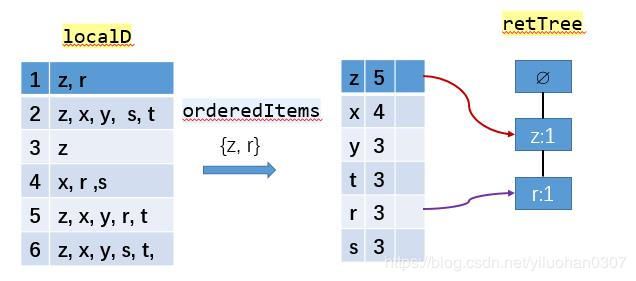
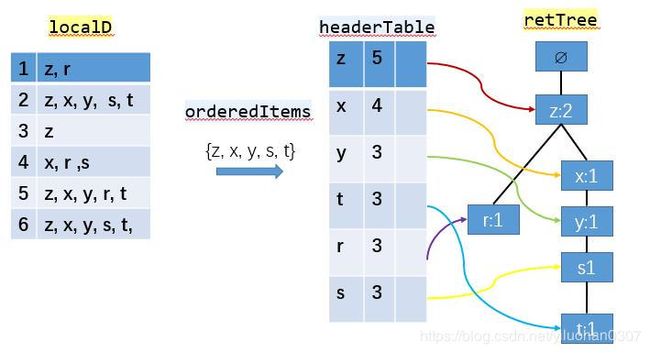



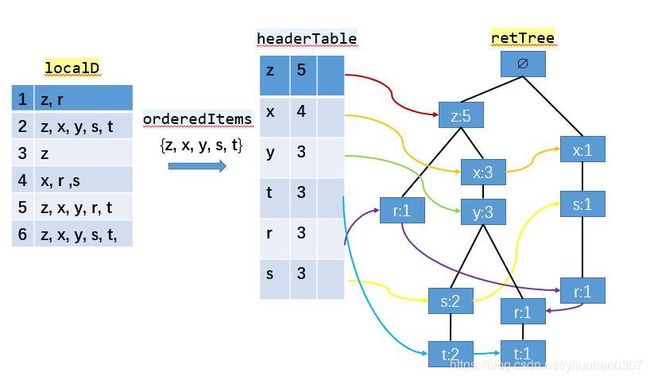
书本中关于r元素的链接是错的。
2)从FP树中挖掘出频繁项集
步骤1:从FP树中获得条件模式基
- 对头部链表进行降序排序
- 对头部链表节点从小到大遍历,得到条件模式基,同时获得一个频繁项集。

如上图,从头部链表 t 节点开始遍历,t 节点加入到频繁项集。找到以 t 节点为结尾的路径如下:
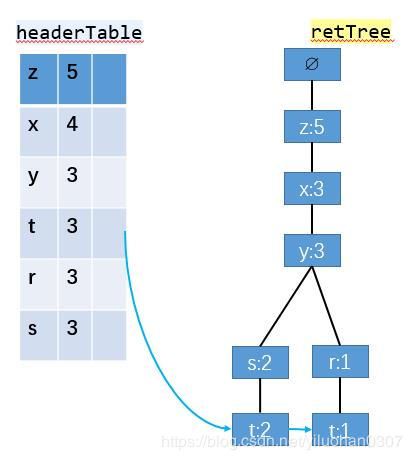
去掉FP树中的t节点,得到条件模式基<左边路径,左边是值>[z,x,y,s,t]:2,[z,x,y,r,t]:1。条件模式基的值取决于末尾节点 t ,因为 t 的出现次数最小,一个频繁项集的支持度由支持度最小的项决定。所以 t 节点的条件模式基的值可以理解为对于以 t 节点为末尾的前缀路径出现次数。
步骤2:利用条件模式基,构建一个条件子树
条件模式基继续构造条件 FP树, 得到频繁项集,和之前的频繁项组合起来,这是一个递归遍历头部链表生成FP树的过程,递归截止条件是生成的FP树的头部链表为空。 根据步骤 2 得到的条件模式基 [z,x,y,s,t]:2,[z,x,y,r,t]:1 作为数据集继续构造出一棵FP树,计算支持度,去除非频繁项,集合按照支持度降序排序,重复上面构造FP树的步骤。最后得到下面 t-条件FP树 :

步骤3:迭代重复步骤(1)和(2),直到树包含一个元素为止
然后根据 t-条件FP树 的头部链表进行遍历,从 y 开始。得到频繁项集 ty 。然后又得到 y 的条件模式基,构造出 ty的条件FP树,即 ty-条件FP树。继续遍历ty-条件FP树的头部链表,得到频繁项集 tyx,然后又得到频繁项集 tyxz. 然后得到构造tyxz-条件FP树的头部链表是空的,终止遍历。我们得到的频繁项集有 t->ty->tyz->tyzx,这只是一小部分。
3.FP-growth 代码讲解
完整代码地址: https://github.com/apachecn/AiLearning/blob/master/src/py2.x/ml/12.FrequentPattemTree/fpGrowth.py
下面的是我自己改动的代码:
#!/usr/bin/env python
# coding=utf-8
#######################################################################
# > File Name:
# > Author: cuiyufei
# > Mail: [email protected]
# > Created Time: 2019年4月24日
#######################################################################
from __future__ import print_function
import twitter
from time import sleep
import re
class treeNode:
def __init__(self, nameValue, numOccur, parentNode):
self.name = nameValue
self.count = numOccur
self.nodeLink = None
# needs to be updated
self.parent = parentNode
self.children = {}
def inc(self, numOccur):
"""inc(对count变量增加给定值)
"""
self.count += numOccur
def disp(self, ind=1):
"""disp(用于将树以文本形式显示)
"""
print(' '*ind, self.name, ' ', self.count)
for child in self.children.values():
child.disp(ind+1)
class FP_tree(object):
def __init__(self):
pass
def createTree(self, dataSet, minSup):
"""createTree(生成FP-tree)
Args:
dataSet {行:出现次数}
minSup 最小的支持度
Returns:
retTree FP-tree
headerTable 满足minSup {元素:[出现次数, treeNode]}
"""
# 支持度>=minSup的dist{所有元素:出现的次数}
headerTable = {}
# 循环每行{行:出现次数}的样本数据
for trans in dataSet:
# 统计每一行中,每个元素出现的总次数
for item in trans:
headerTable[item] = headerTable.get(item, 0) + dataSet[trans]
# 删除 headerTable中,元素次数<最小支持度的元素
for k in headerTable.keys():
if headerTable[k] < minSup:
del(headerTable[k])
# 满足minSup: set(各元素集合)
freqItemSet = set(headerTable.keys())
# 如果不存在,直接返回None
if len(freqItemSet) == 0:
return None, None
for k in headerTable:
# 格式化: dist{元素key: [元素次数, None]}
headerTable[k] = [headerTable[k], None]
# create tree
retTree = treeNode('Null Set', 1, None)
# 循环每行{行:出现次数}的样本数据
for tranSet, count in dataSet.items():
# localD = {元素key: 元素总出现次数}
localD = {}
for item in tranSet:
# 判断是否在满足minSup的集合中
if item in freqItemSet:
# print 'headerTable[item][0]=', headerTable[item][0], headerTable[item]
localD[item] = headerTable[item][0]
# print 'localD=', localD
if len(localD) > 0:
# p=key,value; 所以是通过value值的大小,进行从大到小进行排序
# orderedItems 表示取出元组的key值,也就是字母本身,但是字母本身是大到小的顺序
orderedItems = [v[0] for v in sorted(localD.items(), key=lambda p: p[1], reverse=True)]
# print 'orderedItems=', orderedItems, 'headerTable', headerTable, '\n\n\n'
# 填充树,通过有序的orderedItems的第一位,进行顺序填充 第一层的子节点。
self.updateTree(orderedItems, retTree, headerTable, count)
return retTree, headerTable
def updateTree(self, items, retTree, headerTable, count):
"""updateTree(更新FP-tree,第二次遍历)
# 针对每一行的数据
# 最大的key, 添加
Args:
items 满足minSup 排序后的元素key的数组(大到小的排序)
inTree 空的Tree对象
headerTable 满足minSup {所有的元素+(value, treeNode)}
count 原数据集中每一组Kay出现的次数
"""
# 取出 元素 出现次数最高的
# 如果该元素在 inTree.children 这个字典中,就进行累加
# 如果该元素不存在 就 inTree.children 字典中新增key,value为初始化的 treeNode 对象
if items[0] in retTree.children:
# 更新 最大元素,对应的 treeNode 对象的count进行叠加
retTree.children[items[0]].inc(count)
else:
# 如果不存在子节点,我们为该inTree添加子节点
retTree.children[items[0]] = treeNode(items[0], count, retTree)
# 如果满足minSup的dist字典的value值第二位为null, 我们就设置该元素为 本节点对应的tree节点
# 如果元素第二位不为null,我们就更新header节点
if headerTable[items[0]][1] is None:
# headerTable只记录第一次节点出现的位置
headerTable[items[0]][1] = retTree.children[items[0]]
else:
# 本质上是修改headerTable的key对应的Tree,的nodeLink值
self.updateHeader(headerTable[items[0]][1], retTree.children[items[0]])
if len(items) > 1:
# 递归的调用,在items[0]的基础上,添加item0[1]做子节点, count只要循环的进行累计加和而已,统计出节点的最后的统计值。
self.updateTree(items[1:], retTree.children[items[0]], headerTable, count)
def updateHeader(self, nodeToTest, targetNode):
"""updateHeader(更新头指针,建立相同元素之间的关系,例如: 左边的r指向右边的r值,就是后出现的相同元素 指向 已经出现的元素)
从头指针的nodeLink开始,一直沿着nodeLink直到到达链表末尾。这就是链表。
性能:如果链表很长可能会遇到迭代调用的次数限制。
Args:
nodeToTest 满足minSup {所有的元素+(value, treeNode)}
targetNode Tree对象的子节点
"""
# 建立相同元素之间的关系,例如: 左边的r指向右边的r值
while (nodeToTest.nodeLink is not None):
nodeToTest = nodeToTest.nodeLink
nodeToTest.nodeLink = targetNode
def ascendTree(self, leafNode, prefixPath):
"""ascendTree(如果存在父节点,就记录当前节点的name值)
Args:
leafNode 查询的节点对于的nodeTree
prefixPath 要查询的节点值
"""
if leafNode.parent is not None:
prefixPath.append(leafNode.name)
self.ascendTree(leafNode.parent, prefixPath)
def findPrefixPath(self, basePat, treeNode):
"""findPrefixPath 基础数据集
Args:
basePat 要查询的节点值
treeNode 查询的节点所在的当前nodeTree
Returns:
condPats 对非basePat的倒叙值作为key,赋值为count数
"""
condPats = {}
# 对 treeNode的link进行循环
while treeNode is not None:
prefixPath = []
# 寻找改节点的父节点,相当于找到了该节点的频繁项集
self.ascendTree(treeNode, prefixPath)
# 避免 单独`Z`一个元素,添加了空节点
if len(prefixPath) > 1:
# 对非basePat的倒叙值作为key,赋值为count数
# prefixPath[1:] 变frozenset后,字母就变无序了
# condPats[frozenset(prefixPath)] = treeNode.count
condPats[frozenset(prefixPath[1:])] = treeNode.count
# 递归,寻找改节点的下一个 相同值的链接节点
treeNode = treeNode.nodeLink
# print treeNode
return condPats
def mineTree(self, inTree, headerTable, minSup, preFix, freqItemList):
"""mineTree(创建条件FP树)
Args:
inTree myFPtree
headerTable 满足minSup {所有的元素+(value, treeNode)}
minSup 最小支持项集
preFix preFix为newFreqSet上一次的存储记录,一旦没有myHead,就不会更新
freqItemList 用来存储频繁子项的列表
"""
# 通过value进行从小到大的排序, 得到频繁项集的key
# 最小支持项集的key的list集合
bigL = [v[0] for v in sorted(headerTable.items(), key=lambda p: p[1])]
print('-----', sorted(headerTable.items(), key=lambda p: p[1]))
print('bigL=', bigL)
# 循环遍历 最频繁项集的key,从小到大的递归寻找对应的频繁项集
for basePat in bigL:
# preFix为newFreqSet上一次的存储记录,一旦没有myHead,就不会更新
newFreqSet = preFix.copy()
newFreqSet.add(basePat)
print('newFreqSet=', newFreqSet, preFix)
freqItemList.append(newFreqSet)
print('freqItemList=', freqItemList)
condPattBases = self.findPrefixPath(basePat, headerTable[basePat][1])
print('condPattBases=', basePat, condPattBases)
# 构建FP-tree
myCondTree, myHead = self.createTree(condPattBases, minSup)
print('myHead=', myHead)
# 挖掘条件 FP-tree, 如果myHead不为空,表示满足minSup {所有的元素+(value, treeNode)}
if myHead is not None:
myCondTree.disp(1)
print('\n\n\n')
# 递归 myHead 找出频繁项集
self.mineTree(myCondTree, myHead, minSup, newFreqSet, freqItemList)
print('\n\n\n')
def loadSimpDat():
'''loadSimpDat(加载数据)
Args:
None
Returns:
simpDat列表
'''
simpDat = [['r', 'z', 'h', 'j', 'p'],
['z', 'y', 'x', 'w', 'v', 'u', 't', 's'],
['z'],
['r', 'x', 'n', 'o', 's'],
# ['r', 'x', 'n', 'o', 's'],
['y', 'r', 'x', 'z', 'q', 't', 'p'],
['y', 'z', 'x', 'e', 'q', 's', 't', 'm']]
return simpDat
def createInitSet(dataSet):
'''createInitSet(统计每行出现的次数)
Args:
dataSet 数据集
Returns:
retDict {frozenset(行):次数}
'''
retDict = {}
for trans in dataSet:
if not retDict.has_key(frozenset(trans)):
retDict[frozenset(trans)] = 1
else:
retDict[frozenset(trans)] += 1
return retDict
def main():
# load样本数据
simpDat = loadSimpDat()
# print simpDat, '\n'
# frozen set 格式化 并 重新装载 样本数据,对所有的行进行统计求和,格式: {行:出现次数}
initSet = createInitSet(simpDat)
print(initSet)
# 创建FP树
# 输入:dist{行:出现次数}的样本数据 和 最小的支持度
# 输出:最终的PF-tree,通过循环获取第一层的节点,然后每一层的节点进行递归的获取每一行的字节点,也就是分支。然后所谓的指针,就是后来的指向已存在的
t = FP_tree()
myFPtree, myHeaderTab = t.createTree(initSet, 3)
myFPtree.disp()
# 抽取条件模式基
# 查询树节点的,频繁子项
print('x --->', t.findPrefixPath('x', myHeaderTab['x'][1]))
print('z --->', t.findPrefixPath('z', myHeaderTab['z'][1]))
print('r --->', t.findPrefixPath('r', myHeaderTab['r'][1]))
# 创建条件模式基
freqItemList = []
t.mineTree(myFPtree, myHeaderTab, 3, set([]), freqItemList)
print(freqItemList)
# def getLotsOfTweets(searchStr):
# """
# 获取 100个搜索结果页面
# """
# CONSUMER_KEY = ''
# CONSUMER_SECRET = ''
# ACCESS_TOKEN_KEY = ''
# ACCESS_TOKEN_SECRET = ''
# api = twitter.Api(consumer_key=CONSUMER_KEY, consumer_secret=CONSUMER_SECRET, access_token_key=ACCESS_TOKEN_KEY, access_token_secret=ACCESS_TOKEN_SECRET)
#
# # you can get 1500 results 15 pages * 100 per page
# resultsPages = []
# for i in range(1, 15):
# print "fetching page %d", %i
# searchResults = api.GetSearch(searchStr, per_page=100, page=i)
# resultsPages.append(searchResults)
# sleep(6)
# return resultsPages
#
#
# def textParse(bigString):
# """
# 解析页面内容
# """
# urlsRemoved = re.sub('(http:[/][/]|www.)([a-z]|[A-Z]|[0-9]|[/.]|[~])*', '', bigString)
# listOfTokens = re.split(r'\W*', urlsRemoved)
# return [tok.lower() for tok in listOfTokens if len(tok) > 2]
#
#
# def mineTweets(tweetArr, minSup=5):
# """
# 获取频繁项集
# """
# parsedList = []
# for i in range(14):
# for j in range(100):
# parsedList.append(textParse(tweetArr[i][j].text))
# initSet = createInitSet(parsedList)
# t = FP_tree()
# myFPtree, myHeaderTab = t.createTree(initSet, minSup)
# myFreqList = []
# t.mineTree(myFPtree, myHeaderTab, minSup, set([]), myFreqList)
# return myFreqList
#
# def twitter_test():
# # 项目实战
# # 1.twitter项目案例
# # 无法运行,因为没发链接twitter
# lotsOtweets = getLotsOfTweets('RIMM')
# listOfTerms = mineTweets(lotsOtweets, 20)
# print len(listOfTerms)
# for t in listOfTerms:
# print t
def info_test():
# 2.新闻网站点击流中挖掘,例如:文章1阅读过的人,还阅读过什么?
parsedDat = [line.split() for line in open('../data/12/kosarak.dat').readlines()]
t = FP_tree()
initSet = createInitSet(parsedDat)
myFPtree, myHeaderTab = t.createTree(initSet, 100000)
myFreList = []
t.mineTree(myFPtree, myHeaderTab, 100000, set([]), myFreList)
print (myFreList)
if __name__ == "__main__":
# rootNode = treeNode('pyramid', 9, None)
# rootNode.children['eye'] = treeNode('eye', 13, None)
# rootNode.children['phoenix'] = treeNode('phoenix', 3, None)
# # 将树以文本形式显示
# # print rootNode.disp()
main()
大家看懂原理,再仔细跟踪一下代码。基本就没有问题了。
感谢apachecn官网。
参考
apachecn的AILearning