理解clojure语法(2)
注:本文长期更新
本文梳理一些clojure的常用知识点,惯用法?maybe
1.#'表示取得变量对象本身,
var-quote (#')
#'x ⇒ (var x)这是#的一个reader宏,作用是:
get Var object instead of the value of a symbol (var-quote),
. The reader macro #’x expands to (var x)
boot.user=> (def x 1)
#'boot.user/x
boot.user=> #'x
#'boot.user/x
boot.user=> x
1深层次的了解可以看第21点。
2.Loop和recur常一起用于循环
boot.user=> (loop [i 0]
#_=> (when (< i 5)
#_=> (println i)
#_=> (recur (inc i))))
0
1
2
3
4
nil
3.doseq一般和range常放在一起使用
boot.user=> (doseq [n (range 3)]
#_=> (println n))
0
1
2
nilrange一个参数表示从0开始到这个数为止。
boot.user=> (doseq [n (range 1 3)]
#_=> (println n))
1
2
nil
range可以有两个参数或者一个参数,三个参数也可以(第三个参数表示step步子的大小),
boot.user=> (doseq [n (range 1 8 3)]
#_=> (println n))
1
4
7
nil
4.for用于枚举的循环,抑或全排列组合
boot.user=> (for [x [0 1] y [1 3]]
#_=> [x y])
([0 1] [0 3] [1 1] [1 3])
https://clojuredocs.org/clojure.core/for这里有很多for更高级的例子
5.while
boot.user=> (def a (atom 5))
#'boot.user/a
boot.user=> (while (pos? @a) (do (println @a) (swap! a dec)))
5
4
3
2
1
nil
6.函数式编程中的尾递归
“尾调用优化”对递归操作意义重大,所以一些函数式编程语言将其写入了语言规格。ES6也是如此,第一次明确规定,所有 ECMAScript 的实现,都必须部署”尾调用优化”。这就是说,在 ES6 中,只要使用尾递归,就不会发生栈溢出,相对节省内存—http://www.ruanyifeng.com/blog/2015/04/tail-call.html
对于阶乘操作:
(defn factorial ([x] (factorial 1 x))
([accum x]
(if (= x 1) accum
(factorial (*' accum x) (- x 1))
)))
(factorial 1000)
这里使用 *'而不是*的原因是*'支持任意精度,而*在数据长度超过long的情况下会发生溢出。
*’
returns the product of nums. (*’) returns 1. Supports arbitrary precision.
因为递归调用(比如阶乘和斐波拉契数列)的函数容易引起内存溢出,这样使用尾递归可以极少的减少内存消耗,否则可能会引起栈溢出,尾调用由于是函数的最后一步操作,所以不需要保留外层函数的调用记录,因为调用位置、内部变量等信息都不会再用到了,只要直接用内层函数的调用记录,取代外层函数的调用记录就可以了。
7.some 断言
判断某一个集合是否有满足pred的值,如果有返回true 否则false
user=> (some nil? [1 2 ""])
nil
user=> (some nil? [1 2 "" nil])
true8.调用java类的方法 . 和..
一般步骤有:
导入
创建对象
调用方法.
.
special form
Usage: (.instanceMember instance args*)
(.instanceMember Classname args*)
(Classname/staticMethod args*)
Classname/staticField
The instance member form works for both fields and methods.
They all expand into calls to the dot operator at macroexpansion time.
Please see http://clojure.org/java_interop#dot
连续调用方法.. 前一个函数的返回值,作为后一个函数的第一个参数
..
macro
Usage: (.. x form)
(.. x form & more)
form => fieldName-symbol or (instanceMethodName-symbol args*)
Expands into a member access (.) of the first member on the first
argument, followed by the next member on the result, etc. For
instance:
(.. System (getProperties) (get “os.name”))
expands to:
(. (. System (getProperties)) (get “os.name”))
but is easier to write, read, and understand.
使用java有几个互操作的工具:doto class instance?
doto macro
Usage: (doto x & forms) Evaluates x then calls all of the methods and functions with the value of x supplied at the front of the given arguments. The forms are evaluated in order. Returns x.
user=> (doto (new java.util.HashMap) (.put "a" 1) (.put "b" 2))
{"a" 1, "b" 2}
;doto就是对实体进行一系列操作的一个form
user=> (def a (String. "abc"))
#'user/a
user=> (class a)
java.lang.String
user=> (instance? String a)
true
user=> (.charAt a 0)
/a
user=> (.. a (charAt 0) toString)
"a"9.some->比->的用法更有包容性
(some-> expr & forms)
When expr is not nil, threads it into the first form (via ->),
and when that result is not nil, through the next etc
user=> (some-> {:a 1} :b inc)
nil
user=> (-> {:a 1} :b inc)
NullPointerException clojure.lang.Numbers.ops (Numbers.java:1013)因为(inc nil)的操作是会报错的,some->在某个结果为nil的时候就会返回nil,而不再进行后续的操作了,因而不会报错。
10.partition简单给集合分区
(partition n coll)(partition n step coll)(partition n step pad coll)
Returns a lazy sequence of lists of n items each, at offsets step
apart. If step is not supplied, defaults to n, i.e. the partitions
do not overlap. If a pad collection is supplied, use its elements as
necessary to complete last partition upto n items. In case there are
not enough padding elements, return a partition with less than n items.
partiton-by和group-by按照特定的条件给集合分区。
boot.user=> (partition-by #(= 3 %) [1 2 3 4 5])
((1 2) (3) (4 5))
boot.user=> (partition-by #(= 3 %) [1 2 4 5])
((1 2 4 5))
boot.user=> (partition-by #(= 3 %) [1 2 4 5 3])
((1 2 4 5) (3))
boot.user=> (partition-by odd? [1 1 1 2 2 3 3])
((1 1 1) (2 2) (3 3))
boot.user=> (partition-by odd? [1 1 1 2 3 3])
((1 1 1) (2) (3 3))
boot.user=> (partition-by odd? [1 1 1 3 3])
((1 1 1 3 3))
boot.user=> (partition-by even? [1 1 1 2 2 3 3])
((1 1 1) (2 2) (3 3))
boot.user=> (partition-by even? [1 1 1 3 3])
((1 1 1 3 3))
boot.user=> (partition-by even? [1 1 1 3 3 2])group-by的结果还有点不一样,group-by返回的是一个key list的map。
(group-by count ["a" "as" "asd" "aa" "asdf" "qwer"])
{1 ["a"], 2 ["as" "aa"], 3 ["asd"], 4 ["asdf" "qwer"]}
发散:mysql的partition 大数据情况下的分区:把数据库的表分成几个小部分;好处:可以提高数据库的性能;http://blog.51yip.com/mysql/1013.html
11.associative?
Usage: (associative? coll)
Returns true if coll implements Associative
clojure数据结构的map vector都是associative结构的,但是list,set结构不是。
associative结构的数据和非associative结构的有哪些差别呢?
首先看看vector和list的差别?
vector和数组类似,它拥有一段连续的内存空间,并且起始地址不变,因此它能非常好的支持随机存取(即使用[]操作符访问其中的元素),但由于它的内存空间是连续的,所以在中间进行插入和删除会造成内存块的拷贝(复杂度是O(n)),另外,当该数组后的内存空间不够时,需要重新申请一块足够大的内存并进行内存的拷贝。这些都大大影响了vector的效率。
list是由数据结构中的双向链表实现的,因此它的内存空间可以是不连续的。因此只能通过指针来进行数据的访问,这个特点使得它的随机存取变的非常没有效率,需要遍历中间的元素,搜索复杂度O(n),因此它没有提供[]操作符的重载。但由于链表的特点,它可以以很好的效率支持任意地方的删除和插入。
所以vector是关联数组,而list不是。
boot.user=> (associative? [])
true
boot.user=> (associative? ())
false
boot.user=> (associative? '())
false
boot.user=> (associative? #( 1 2))
false
boot.user=> (associative? {:a 1})
true
那么为什么要使用associative结构?associative结构支持哪些操作?
https://github.com/clojure/clojure/blob/master/src/jvm/clojure/lang/Associative.java
public interface Associative extends IPersistentCollection, ILookup{
boolean containsKey(Object key);
IMapEntry entryAt(Object key);
Associative assoc(Object key, Object val);
}说明associative结构的数据是一些key value结构,vector的key可以看做是是从0开始的数字。
这里containsKey对应的应该是
(contains? coll key)
Returns true if key is present in the given collection, otherwise
returns false. Note that for numerically indexed collections like
vectors and Java arrays, this tests if the numeric key is within the
range of indexes. ‘contains?’ operates constant or logarithmic time;
it will not perform a linear search for a value. See also ‘some’.
相关的API有 update/update-in/assoc-in/assoc/get/get-in
比如说assoc和assoc-in这一组:
(assoc map key val)(assoc map key val & kvs)
assoc[iate]. When applied to a map, returns a new map of the
same (hashed/sorted) type, that contains the mapping of key(s) to
val(s). When applied to a vector, returns a new vector that
contains val at index. Note - index must be <= (count vector).
(assoc-in m [k & ks] v)
Associates a value in a nested associative structure, where ks is a
sequence of keys and v is the new value and returns a new nested structure.
If any levels do not exist, hash-maps will be created.
这实在是有趣,update的话只是用一个函数去修改key对应的value
(update m k f)(update m k f x)(update m k f x y)(update m k f x y z)(update m k f x y z & more)
‘Updates’ a value in an associative structure, where k is a
key and f is a function that will take the old value
and any supplied args and return the new value, and returns a new
structure. If the key does not exist, nil is passed as the old value.
get是取得key的值
get map key)(get map key not-found)
Returns the value mapped to key, not-found or nil if key not present.
12.macro宏
关于宏,在clojure里面我的经验实在不多,目前对于我而言,学习宏可以看懂很多源代码。在这里主要解释清楚三件事(为什么使用macro?/使用macro的简单例子/macro的基本语法解析)。
为什么使用macro?
宏是在读入期间替换代码的,进行实际代码替换。使用宏可以很大限度的扩展代码。
一个使用macro的简单例子
(defmacro my-when
[pred & body]
`(if ~pred (do ~@body)))使用的结果:
user=> (defmacro my-when
#_=> [pred & body]
#_=> `(if ~pred (do ~@body)))
#'user/my-when
user=> (my-when true 1)
1
user=> (macroexpand '(my-when true 1))
(if true (do 1))我们可以看到when的实现就是用if的逻辑。
macro的基本语法解析
几个术语quote unquote
quote:防止被evalute ‘和`
unquoate使用~ ~@,这个的上下文是在宏里面
那么evaluate是什么意思呢?repl Read/Evaluate/Print/loop,官网对这个的解释:
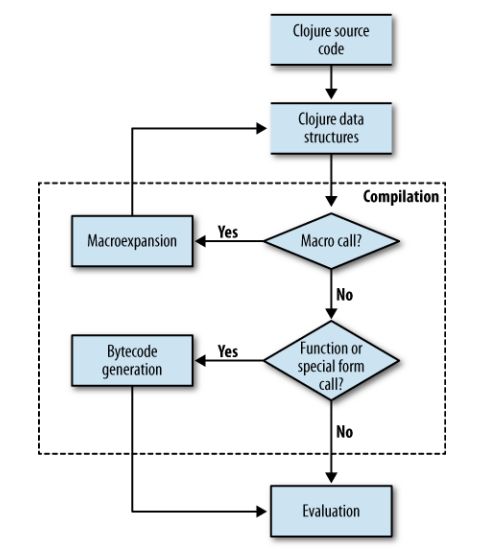
主要有下面这几个符号:
` ' ~ @ #在quote中的~则可以获得外圈作用域的变量。
使用~@可以展开列表中的变量
Syntax-quote (
`, note, the "backquote" character), Unquote (~) and Unquote-splicing (~@) For all forms other than Symbols, Lists, Vectors, Sets and Maps,x is the same as ‘x.
另外一个例子:
(defmacro auth-get
[path acl & body]
`(r/GET ~path ~'request (authenticated ~acl ~@body)))~’request的解释:
request不是来自这个宏自身的参数,而是来自外层的参数,因此~’request表示取得外圈作用域的变量request 。
auto_gensym机制#
相比之下clojure的宏简直优雅至极:
(defmacro bench [& exps]
`(let [start# (System/nanoTime)
result# (do ~@exps)]
{:result result#
:time (- (System/nanoTime) start#)}))
只要在临时变量后加个#就能防止variable capture。。实在强悍
用以下方法验证clojure没有出现variable capture:
(let [start# 1
result# 2]
(println (bench (+ start# result#))))
来自 https://www.douban.com/note/276264587/可以通过调用macroexpand-1 或者macroexpand
查看宏展开的结果,这两个函数的区别在于macroexpand会反复调用macroexpand-1进行宏展开,直到没有宏为止。
13.语法糖
Lisp方言有一个非常简洁的语法 — 有些人觉得很美的语法。(a b c)表示一个对函数a的调用,而参数是b和c。如果要表示数据,你需要使用’(a b c) 或者(quote (a b c))。
我们把这些特殊情况称为语法糖。一般情况下,语法糖越多代码写起来越简介,但是同时我们也要学习更多的东西以读懂这些代码。这需要找到一个平衡点。很多语法糖都有对应的函数可以调用。
比如说上面介绍的宏的语法糖的一些基本的总结:
| 作用 | 语法糖 | 对应函数 |
|---|---|---|
| simple quote (使用在宏里面) | ‘ | (quote value) |
| syntax quote (使用在宏里面) | ` | none |
| unquote (使用在宏里面) | ~value | (unquote value) |
| unquote splicing (使用在宏里面) | ~@value | none |
| auto-gensym (在宏里面用来产生唯一的symbol名字) | prefix# | (gensym prefix) |
14.defrecord用于创建java类。
用法如下:
> (defrecord name [fields*] options* specs*)
Currently there are no options.
Each spec consists of a protocol or interface name followed by zero
or more method bodies:
protocol-or-interface-or-Object
(methodName [args*] body)*
Dynamically generates compiled bytecode for class with the given
name, in a package with the same name as the current namespace, the
given fields, and, optionally, methods for protocols and/or
interfaces.
The class will have the (immutable) fields named by
fields, which can have type hints. Protocols/interfaces and methods
are optional. The only methods that can be supplied are those
declared in the protocols/interfaces. Note that method bodies are
not closures, the local environment includes only the named fields,
and those fields can be accessed directly.
Method definitions take the form:
(methodname [args*] body)
The argument and return types can be hinted on the arg and
methodname symbols. If not supplied, they will be inferred, so type
hints should be reserved for disambiguation.
Methods should be supplied for all methods of the desired
protocol(s) and interface(s). You can also define overrides for
methods of Object. Note that a parameter must be supplied to
correspond to the target object ('this' in Java parlance). Thus
methods for interfaces will take one more argument than do the
interface declarations. Note also that recur calls to the method
head should *not* pass the target object, it will be supplied
automatically and can not be substituted.
In the method bodies, the (unqualified) name can be used to name the
class (for calls to new, instance? etc).
The class will have implementations of several (clojure.lang)
interfaces generated automatically: IObj (metadata support) and
IPersistentMap, and all of their superinterfaces.
In addition, defrecord will define type-and-value-based =,
and will defined Java .hashCode and .equals consistent with the
contract for java.util.Map.
When AOT compiling, generates compiled bytecode for a class with the
given name (a symbol), prepends the current ns as the package, and
writes the .class file to the *compile-path* directory.
Two constructors will be defined, one taking the designated fields
followed by a metadata map (nil for none) and an extension field
map (nil for none), and one taking only the fields (using nil for
meta and extension fields). Note that the field names __meta
and __extmap are currently reserved and should not be used when
defining your own records.
Given (defrecord TypeName ...), two factory functions will be
defined: ->TypeName, taking positional parameters for the fields,
and map->TypeName, taking a map of keywords to field values.
意思就是说这里defrecord定义的record首先要有一个名字,然后在[] 定义一些fields。初始化的时候可以使用->TypeName或者map->TypeName来初始化。然后,defrecord name [fields*] options* specs*)这里的specs*可以继承接口,定义一些方法。
说道这里,感觉这样解释defrecord很无力,defrecord只能算是clojure的数据类型和协议的一部分,要从clojure协议整体来入手,请看下一个点。
15.clojure的数据类型和协议
协议
clojure里面接口interface的对应物我们称为协议,interface在clojure业界都是用来特指Java接口的。
一个协议由一个或者多个方法的定义组成,而且每个方法可以有多个方法体。
扩展已有的类型:使用extend-protocol和extend
比如:
(defprotocol Dateable
(to-ms [t]))
(extend java.lang.Number
Dateable
{:to-ms identity})
类型
使用deftype和defrecord来实现。
定义类型:defrecord和deftype
记录类型:defrecord
普通类型type或记录类型record,都是
(defrecord Person [fname lname address])会创建一个Person java类,里面有三个public, final修饰的名为fname lname address的字段。
类型的特点,支持java互操作?比clojure的map操作快?=
记录类型相对于type类型来说,有些额外的特性?
记录类型是不可变的。
记录实现了关系型数据结构的接口;
元数据的接口;
defrecord的这个例子很好(来自clojure docs)
(import java.net.FileNameMap)
-> java.net.FileNameMap
;; Define a record named Thing with a single field a. Implement
;; FileNameMap interface and provide an implementation for the single
;; method: String getContentTypeFor(String fileName)
(defrecord Thing [a]
FileNameMap
(getContentTypeFor [this fileName] (str a "-" fileName)))
-> user.Thing
;; construct an instance of the record
(def thing (Thing. "foo"))
-> #'user/thing
;; check that the instance implements the interface
(instance? FileNameMap thing)
-> true
;; get all the interfaces for the record type
(map #(println %) (.getInterfaces Thing))
-> java.net.FileNameMap
-> clojure.lang.IObj
-> clojure.lang.ILookup
-> clojure.lang.IKeywordLookup
-> clojure.lang.IPersistentMap
-> java.util.Map
-> java.io.Serializable
;; actually call the method on the thing instance and pass "bar"
(.getContentTypeFor thing "bar")
-> "foo-bar"defprotocol支持的东西还比较多,值得多研究下。
deftype只有一种创建的方法。
类型实现协议
1.用deftype和defrecord定义类型的时候直接把这些方法个实现了,这种方法叫做内联实现。
2.使用extend*把一个类型的实现注册到协议上面去
比如extend-protocol.
除了deftype和defrecord,还有一种结构可以接受内联实现。Reify,他直接创建匿名的,这是一种创建任何协议的类实例的方法。(匿名内部类?)
reify不定义任何字段
比如这个例子:
(def dataformat-json
(reify DataFormat
(marshal [_ ex graph stream]
(let [json (some-> graph (encode-json) (to-json-str nil nil))]
(spit stream json :encoding "UTF-8")
(c/set-header ex Exchange/CONTENT_TYPE "application/json")
(c/set-header ex Exchange/CHARSET_NAME "UTF-8"))
;(log/info "marshal json" graph (type graph))
)
(unmarshal [_ ex stream]
(let [s (slurp stream :encoding "UTF-8")]
;(log/info "Unmarshal json: raw is" s (type s))
(let [obj (-> (j/parse-string s) (decode-json))]
#_(when (-> ex (.getPattern) (.isOutCapable))
(log/info "Unmarshal json:" ex obj))
(when (instance? Throwable obj) (throw obj))
obj)))))
*注:这写的有点匆忙,更新中*
一个极好的有关reify的例子,来自clojure docs
;;; This is a library for the shopping result.
(defrecord Banana [qty])
(defrecord Grape [qty])
(defrecord Orange [qty])
;;; 'subtotal' differs from each fruit.
(defprotocol Fruit
(subtotal [item]))
(extend-type Banana
Fruit
(subtotal [item]
(* 158 (:qty item))))
(extend-type Grape
Fruit
(subtotal [item]
(* 178 (:qty item))))
(extend-type Orange
Fruit
(subtotal [item]
(* 98 (:qty item))))
;;; 'coupon' is the function returing a 'reify' of subtotal. This is
;;; when someone uses a coupon ticket, the price of some fruits is
;;; taken off 25%.
(defn coupon [item]
(reify Fruit
(subtotal [_]
(int (* 0.75 (subtotal item))))))
;;; Example: To compute the total when someone bought 10 oranges,
;;; 15 bananas and 10 grapes, using a coupon for the grapes.
(apply + (map subtotal [(Orange. 10) (Banana. 15) (coupon (Grape. 10))]))
;;; 4685 ; (apply + '(980 2370 1335))16.多重方法
一般配合defmulti和defmethod来做,先来看看defmulti的用法定义。
(defmulti name docstring? attr-map? dispatch-fn & options)
docstring? attr-map?都是可选的,dispatch-fn就是派发函数,根据这个函数求得的值 dispatch-val来决定使用defmethod定义的一系列函数中的某一个函数。然后 options是一些键值对
Options are key-value pairs and may be one of:
:default
The default dispatch value, defaults to :default
:hierarchy
The value used for hierarchical dispatch (e.g. ::square is-a ::shape)
Hierarchies are type-like relationships that do not depend upon type inheritance.
也就是说options有一个:default的关键字,这个关键字的默认值是:default ;还有一个:hierarchy的关键字,这个值是用来做层次分发的,可以按照层次关系分发(请看下一个知识点:)(这个和类的继承是一样的)。
defmethod的用法:
(defmethod multifn dispatch-val & fn-tail)
比如,定义camel的from-uri函数:
(defmulti from-uri (fn [tag & _] tag))
(defmethod from-uri :default
([uri] uri)
([uri format] [uri format]))
(defmethod from-uri :timer
([_ prefix period]
(str "timer:" prefix "-timer-" (u/uuid-short) "?fixedRate=true&period=" period)))
(defmethod from-uri :quartz
([_ prefix fmt]
(str "quartz:" prefix "-quartz-" (u/uuid-short) "?cron=" fmt)))定义的分发函数是取输入参数的第一个值,在这种情况下如果调用from,如果输入的第一个参数是:timer,则会调用:
(defmethod from-uri :timer
([_ prefix period]
(str "timer:" prefix "-timer-" (u/uuid-short) "?fixedRate=true&period=" period)))也就是一个组装一个timer组件的Endpoint的Uris。如果第一个参数不在defmethod的派生值之中,那么就调用派生值为:default的派生函数,返回的值和输入的参数一致。
第二个例子:
(def h (-> (make-hierarchy)
(derive :foo :bar)))
(defmulti f identity :hierarchy #'h) ;; hierarchy must be a reference type
(defmethod f :default [_] "default")
(defmethod f :bar [_] "bar")
(f :unknown) ;; "default"
(f :bar) ;; "bar"
(f :foo) ;; "bar"这里首先定义了h,h是一个继承关系,定义了:foo是:bar的子类;
f的派生函数是identity(函数的返回值直接返回参数) ,然后调用f ,如果参数是:foo,也调用的是:(defmethod f :bar [_] "bar") 因为这里的:foo是:bar的孩子,可以直接继承父类的方法。
17.父类和派生类
可以像面向对象编程一样,定义继承关系,但是不仅仅是类的继承,symbol的继承也可以,像上面那个例子一样的。主要的几个方法是derive和make-hierarchy:
(make-hierarchy)
(derive tag parent)(derive h tag parent)
(make-hierarchy)定义了一个空的继承关系,而derive定义了继承的内容;利用继承关系还是可以去实现一些复杂的应用的。
18.promise
在javascript中,有一种叫做promise的异步调用模式。在这里,主要讲一下promise的语法:
(promise)
user=> (def p (promise))
#'user/p
user=> p
#可以发现promise的用法就是使用promise定义,deliver一次赋值,然后使用deref和@才可以取得这个promise对象的值,否则就会一直等待。
19.future 异步线程阻塞
(future & body)
Takes a body of expressions and yields a future object that will
invoke the body in another thread, and will cache the result and
return it on all subsequent calls to deref/@. If the computation has
not yet finished, calls to deref/@ will block, unless the variant of
deref with timeout is used. See also - realized?.
也就是说future在body的内容没有执行完之前调用@这个future对象会阻塞,另外还有一个重要的特点就是这些body的内容是在另外一个线程中调用的。
另外这类的用法还有delay,有关delay的解释:
(delay & body)
Takes a body of expressions and yields a Delay object that will
invoke the body only the first time it is forced (with force or deref/@), and
will cache the result and return it on all subsequent force
calls. See also - realized?
和future对比,delay中body的执行没有使用另外一个线程(算是同步线程阻塞吧),其他的都是一样的用法。
这里有一系列这种奇奇怪怪的用法。
20.transducer
transducer是clojure里面的一种编程思想,使用transducer可以简化很多语法,js也已经采用。
那么什么是transducer呢?举一个例子,比如map函数,
(map f)(map f coll)(map f c1 c2)(map f c1 c2 c3)(map f c1 c2 c3 & colls)
Returns a lazy sequence consisting of the result of applying f to
the set of first items of each coll, followed by applying f to the
set of second items in each coll, until any one of the colls is
exhausted. Any remaining items in other colls are ignored. Function f should accept number-of-colls arguments. Returns a transducer when no collection is provided.
也就是map在只传了f作为参数的时候,会返回一个transducer。
而mapv却没有提供tansducer的能力,可以看下面的解释。
(mapv f coll)(mapv f c1 c2)(mapv f c1 c2 c3)(mapv f c1 c2 c3 & colls)
Returns a vector consisting of the result of applying f to the
set of first items of each coll, followed by applying f to the set
of second items in each coll, until any one of the colls is
exhausted. Any remaining items in other colls are ignored. Function f should accept number-of-colls arguments.
能提供tansducer的函数还有
The following functions produce a transducer when the input collection is omitted:
map cat mapcat filter removetake take-while take-nth drop drop-while replace partition-by partition-all keep keep-indexed map-indexed distinctinterpose dedupe random-sample
比如
(filter odd?)
(map inc)
(take 5)
这里可能会涉及到以下术语:

函数都有什么特点呢?这些函数接受input参数,都会返回一个lazy sequence,所以猜想返回lazy sequence的这种函数都可以产生一个transducer。
但是transducer并不是像partial那样的currying。
transducer都有什么特殊的用法?编程思想是什么?
我们知道reduce接受一个reducing函数,一个集合,最后产生一个结果。而transducer接受一个reducing函数,也产生一个reducing函数(那么transducer+reducing函数=reducing函数意味着什么?)。

使用transducer可以产生lazy序列。
transducer还有一些哪些特别的用法呢?还可以配合comp和->>,以及transducer,into等来使用。
比如:
#_=> (comp
#_=> (filter odd?)
#_=> (map inc)
'boot.user/xft.user
=> (transduce xf + (range 5))
6
boot.user=> (transduce xf + 100 (range 5))
106
有关transduce的解释:
(transduce xform f coll)(transduce xform f init coll)
reduce with a transformation of f (xf). If init is not
supplied, (f) will be called to produce it. f should be a reducing
step function that accepts both 1 and 2 arguments, if it accepts
only 2 you can add the arity-1 with ‘completing’. Returns the result
of applying (the transformed) xf to init and the first item in coll,
then applying xf to that result and the 2nd item, etc. If coll
contains no items, returns init and f is not called. Note that
certain transforms may inject or skip items.
使用xform这个transducer产生懒惰序列,然后将f当做reducing函数,这个过程是lazy的。。
into也有这种用法,
(into to from)(into to xform from)
Returns a new coll consisting of to-coll with all of the items of
from-coll conjoined. A transducer may be supplied.
比如
boot.user=> (def xform (comp (map #(+ 2 %))
#_=> (filter odd?)))
#'boot.user/xform
boot.user=> (into [-1 -2] xform (range 10))
[-1 -2 3 5 7 9 11]
boot.user=> (transduce xform conj [-1 -2] (range 10))
[-1 -2 3 5 7 9 11]
boot.user=> (reduce (xform conj) [-1 -2] (range 10))
[-1 -2 3 5 7 9 11]
使用:
(reduce conj [-1 -2] (->> (range 10)
(map #(+ 2 %))
(filter odd?)))也可以达到同样的结果,但是就像上面说的,效果没有那么好,也可以实际的去测试一下。
21.metadata元数据
Clojure里面的元数据是附加到一个符号或者集合的一些数据,它们和符号或者集合的逻辑数据没有直接的关系。两个逻辑上一样的方法可以有不同的元数据。
metadata元数据是一个map,可以有任何的关键字。
(meta obj);返回一个obj的元数据信息(with-meta obj map);返回一个obj对象,并设置他的元数据为mapalter-meta!;修改对象的元数据信息关于metadata,不得不提到def这个special form.

比如说private,doc,test,tag等。file line等元数据信息默认都有。
可以被编译器识别的几个元信息还有dynamic 等
默认情况下,Clojure 使用静态作用域来处理变量,使用 dynamic 元数据关键字,以及 binding 宏,可以将变量改为动态作用域。
元数据的几种除了with-data以外的设置写法,可以被Reader宏识别的写法:
^{:doc “How obj works!”} obj 通过map设置元数据
等价于 (with-meta obj {:doc “How obj works!”})^:dynamic obj - 设置obj的元数据的指定的关键字为true
等价于 ^{:dynamic true} obj^String obj -设置:tag关键字的值,用于设置数据类型
等价于 ^{:tag java.lang.String} obj
一般情况下,也可以自定义元数据来执行自己想要的功能,比如:
(defn collect-methods
"获取指定名字空间下的RPC函数"
[ns]
(let [rpc-fn (fn [[s v]] (:rpc (meta v)))
methods (->> (ns-publics ns)
(filter rpc-fn)
)]
))通过给一些public函数指定{:rpc true}的元数据,那么那个函数将成为被上面代码收集的methods之一。
22.数据处理
这里涉及到的内容包括group-by,sort-by以及clojure.set相关的内容。
(group-by f coll)
Returns a map of the elements of coll keyed by the result of f on each element. The value at each key will be a vector of the corresponding elements, in the order they appeared in coll.
也就是说函数f作用于coll中的每个元素,根据返回值来合并;返回值相同的合并在一起,并且这个返回值作为key,合并的结果作为value,最终的结果是一个map。
比如:
(group-by odd? (range 10))
;;=> {false [0 2 4 6 8], true [1 3 5 7 9]}做法很简单的,但是下面的代码可能比较难理解,
(group-by #(select-keys % [:a :b]) the-map-list)主要是因为select-keys,它的用法就是将某个map截取其中某些关键字组成一个新的map。
(select-keys map keyseq)
Returns a map containing only those entries in map whose key is in keys所以上面group-by语句就是将一个集合中的map按照某些关键字归类。
那么sort-by呢
(sort-by keyfn coll)(sort-by keyfn comp coll)
Returns a sorted sequence of the items in coll, where the sort order is determined by comparing (keyfn item). If no comparator is supplied, usescompare. comparator must implement java.util.Comparator.
也就是说,通过将函数keyfn作用于coll中的每个元素,将得到的值进行比较排序返回coll中的元素,如果没有提供比较器,就默认使用compare函数,也可以自己定义比较器来比较排序。
比如说
(sort-by count ["aaa" "bb" "c"])
("c" "bb" "aaa")这里的keyfn是count,得到的值是3 2 1,通过compare比较大小,返回的是("c" "bb" "aaa")。(默认按照升序?)
另外sort-by的一个比较有意思的例子是:
(def x [{:foo 2 :bar 11}
{:bar 99 :foo 1}
{:bar 55 :foo 2}
{:foo 1 :bar 77}])
;sort by :foo, and where :foo is equal, sort by :bar
(sort-by (juxt :foo :bar) x)
;=>({:foo 1, :bar 77} {:bar 99, :foo 1} {:foo 2, :bar 11} {:bar 55, :foo 2})这里不得不提juxt的用法,
(juxt f)(juxt f g)(juxt f g h)(juxt f g h & fs)
Takes a set of functions and returns a fn that is the juxtaposition
of those fns. The returned fn takes a variable number of args, and
returns a vector containing the result of applying each fn to the
args (left-to-right).
也就是说,juxt接受几个方法 f g作为参数,返回一个新的函数fn,调用fn的时候,比方说(fn x),那么相当于从左到右将f g作用于x,并返回一个vector。
((juxt a b c) x) => [(a x) (b x) (c x)]回到(sort-by (juxt :foo :bar) x),对于x的第一个元素返回的是[2 11],依次是[99 1] [55 2] [ 1 77],比较器compare会按照顺序分别比较vector中的每个值,如果第一个比较相等,那么按照第二个比较来排序。sort的用法类似,只是不接收一个keyfn的参数。
最后讲讲clojure.set,clojure.set有什么作用?是对集合进行操作很有用的一个api,提供的有用函数像union,join等。union很简单,就是求两个集合的并集。
(union #{1 2} #{2 3})
#{1 2 3}
join就相当于sql语法中的内连接,
join xrel yrel)(join xrel yrel km)
When passed 2 rels, returns the rel corresponding to the natural
join. When passed an additional keymap, joins on the corresponding
keys.这些对于在内存计算很有帮助。
23.clojure解构(clojure destructuring)
Clojure supports abstract structural binding, often called destructuring, in let binding lists, fn parameter lists, and any macro that expands into a let or fn. – http://clojure.org/special_forms
也就是说,destructuring是clojure的一种special form,一般可以用于let表达式,def以及由这些form写的宏中。可以认为map、list、struct等是构造出来数据结构,怎么取这些结构里面的数据?那就需要把结构拆开,取到数据。这就是解构(destructuring)。
解构的主要想法:
The binding is abstract in that a vector literal can bind to anything that is sequential, while a map literal can bind to anything that is associative.
& followed by a binding-forms will cause that binding-form to be bound to the remainder of the sequence, i.e. that part not yet bound.
对于vector类型的数据的解构
map类型的解构
稍微复杂的一个例子
&
:as
:keys
:or
compojure解构
Compojure是一个在Ring基础上开发出的小型路由库,可使得web程序由小而独立的部分组成。使用时,在project.clj文件添加依赖;
compujure中的路由类似这样:
(GET "/user/:id" [id]
(str "Hello user "
id ""))Routes(路由)返回Ring handler函数。我们拆解这个语法。第一个符:
GET
这是Compojure提供的几个路由宏之一。这个宏检测HTTP请求方法,如果方法不是”GET“,函数返回nil。
其他可用宏有POST、PUT、DELETE、OPTIONS、PATCH和HEAD。如果想匹配任意的HTTP方法,使用 ANY 宏。
“/user/:id”
它匹配请求的URI。”:id“将匹配”/“或者”.“下的任意子路径,并且将结果置于”id”参数中。
如果我们想更具体一些,还可以为这个参数定义一个自定义的正则表达式:
[“/user/:id”, :id #”[0-9]+”]
对于HTTP方法,如果URI匹配不到任何自定义路径,那么路由函数将返回nil。
在HTTP方法和URI匹配之后:
[id]
宏的第二个参数提供了从请求map中检索信息的方法。它可能是一个由参数组成的向量,也或者其他完整的clojure结构形式。
24.for 宏
刚开始使用for的时候总是会产生一些误解,以为for可以循环的完成一些任务,其实不是这样的。
先看for的定义:
(for seq-exprs body-expr)
List comprehension. Takes a vector of one or more
binding-form/collection-expr pairs, each followed by zero or more
modifiers, and yields a lazy sequence of evaluations of expr.
Collections are iterated in a nested fashion, rightmost fastest,
and nested coll-exprs can refer to bindings created in prior
binding-forms. Supported modifiers are: :let [binding-form expr …],
:while test, :when test.
(take 100 (for [x (range 100000000) y (range 1000000) :while (< y x)] [x y]))
也就是说for是用来理解list结构的,输入一个binding的vector,根据body-expr的定义返回一个lazy序列。
所以for并没有执行循环体的功能
doseq有这个功能
(doseq seq-exprs & body)
Repeatedly executes body (presumably for side-effects) with
bindings and filtering as provided by “for”. Does not retain
the head of the sequence. Returns nil.
doseq执行循环体body,返回值为nil,一般是为了产生副作用,也支持let,when等modifiers。
25.memorize
(memoize f)将调用f的参数和结果的映射记忆在内存中,如果调用了相同的参数,将会有更好的性能。
26.clojure中的正则表达式
正则表达式是clojure中的一种非常基本的数据类型,正则表达式使用单个字符串来描述、匹配一系列匹配某个句法规则的字符串。比如(这里使用clojure的语法格式来表示)#"\d+" 这个正则表达式用于查找连续不间断的整数串
,比如(re-find #"\d+" "abc12345def")能返回12345;再比如#"(\S+):(\d+)" 表示的是”连续不间断的非空白字符串-连续不间断的整数串”,#"\S"匹配任何非空白字符。
clojure中的正则表达式的语法是#"...",虽然正则表达式POSIX标准的表示是:/.../,正则表示式语法中有很多特殊字符,比如\ + \S \s \d \w * ^ $ [] ?等。/<\s*(\S+)(\s[^>]*)?>[\s\S]*<\s*\/\1\s*>/ 表示的是一个HTML标记< tag a="" b="" > ... 。
正则表达式有一个非常核心的思想,那就是推理。那么什么是推理呢?
比如说下面这个子表达式则是一个协助推理的表达式。
(?=pattern)这是一个执行预测搜索的子表达式,比如’Windows (?=95|98|NT|2000)’ 匹配“Windows 2000”中的“Windows”,但不匹配“Windows 3.1”中的“Windows”。
也就是说Windows (?=95|98|NT|2000)这个表达式限定了一个规则,如果Windows 字符串后面紧跟95|98|NT|2000中的任何一个,那么则匹配Windows 这个字符串。
许多命令行工具和大多数的编程语言 都支持正则表达式,以此来帮助解决文本操作问题。不同工具以及不同语言之间的正则表达式都略有差异。然而这些都无关紧要 。
有些编辑器就也支持使用正则表达式的方式查找替换文本,比如说notepad++,
比如

使用(\S+)(\s+)(\S+)(\s+)(\S+)(\s+)(\S+)(\s+)(\S+)(\s+)匹配一组字符串,使用 0… 0 … 9 属性从结果“匹配”集合中检索捕获的匹配,也可以使用\1 \3检索匹配集合中的子元素。
clojure提供了一组api(其实是java的正则表达的包装)来处理正则表达式的相关功能。
re-find
(re-find m)(re-find re s)
Returns the next regex match, if any, of string to pattern, using
java.util.regex.Matcher.find(). Uses re-groups to return the
groups.
接受一个参数m,或者两个参数(正则表达式和一个字符串),返回能够匹配的字符串。注意这里说明的next regex match,也就是说每次调用的时候会迭代的去依次匹配。
re-matcher
要理解re-matcher,需要先理解一下matcher类
public final class Matcher
extends Object
implements MatchResult
An engine that performs match operations on a character sequence by interpreting a Pattern.
A matcher is created from a pattern by invoking the pattern’s matcher method.
re-matches
返回匹配结果,那么和re-find和什么区别呢,re-match只有在整个字符串满足条件的时候才匹配
user=> (re-matches #"hello" "hello, world")
nil
user=> (re-matches #"hello.*" "hello, world")
"hello, world"
user=> (re-matches #"hello, (.*)" "hello, world")
["hello, world" "world"]re-seq
返回持续匹配的一组数据,和re-find不一样
boot.user=> (re-seq #"\d" "clojure 1.1.0")
("1" "1" "0")
boot.user=> (re-find #"\d" "clojure 1.1.0")
"1"
27.时间的处理,Calendar可以处理时间
比如,
(:import java.text.SimpleDateFormat)
(:import java.util.Date)
(:import java.util.Calendar)在Java中可以用来处理时间的两个类,一个是Date(我一般会使用Date来获取到当前的时间),另外一个是Calendar,Calendar提供了更加强大的许多功能。比如下面的这种用法,
(defn format-date
([](format-date (Date.) "yyyy MM dd HH mm ss"))
([x](if (string? x)
(format-date (Date.) x)
(format-date x "yyyy MM dd HH mm ss")))
([dt fmt](.format (SimpleDateFormat. fmt) dt)))
;;
(defn get-date-before-or-after
"获取某个日期的前几天或后几天的日期"
[num]
(let [cal (.. Calendar (getInstance) )
_ (.add cal Calendar/DATE num)
]
(format-date (.getTime cal) "yyyyMMdd") )
)28.schema 类型校验
参数的类型校验,我们知道clojure是动态语言,变量不需要定义类型,但是在参数的验证中,如果能知道类型,那么结果将要好很多。
这个可以使用schema来做;
29.declare
(declare & names)引用块内定义一些无绑定的 var 名字,用于提前声明(forward declarations)
和def的作用差不多,不过def可以定义绑定var的name,这个大概就是定义和声明的区别了:)
30.文件的读写
主要涉及到的api包括以下这些
spit
(spit f content & options)
slurp
clojure.java.io
reader
writer
open
clojure.edn命名空间
31.read-string和eval
总的来说,read-string是将一个string识别为clojure中的一种最基本的数据form structure(根据clojure定义的各种数据结构和语法个格式来判定是否是正确的form),这样clojure在eval的时候就有底了(这个东西我可以计算出来一个结果)。下面来详细的分析下这一块。
read-string
Reads one object from the string s. Optionally include reader
options, as specified in read.
For data structure interop use clojure.edn/read-string如果string中的内容不是一个正确的form,就会报错:
###(read-string "[1 4")
java.lang.RuntimeException: EOF while reading
除了clojure.core定义的read-string之外,clojure.edn也定义了read-string,有一些增强:
boot.user=> (read-string "")
java.lang.RuntimeException: EOF while reading
boot.user=> (edn/read-string "")
nil
相当于(read-string {:eof nil} s)eval
clojure代码的执行器,比如:
boot.user=> (eval '(let [a 10] (+ 3 4 a)))
17
我们一般写程序是不会用到eval的,大部分你觉得可能需要使用eval的,其实也许可以用别的函数来代替,比如apply。
(apply f arg…)
要注意一个特别的函数,除了我们用defn定义的函数,或者匿名函数之外,像defrecord的工厂函数也是可以用apply的。
Given (defrecord TypeName ...), two factory functions will be
defined: ->TypeName, taking positional parameters for the fields,
and map->TypeName, taking a map of keywords to field values.另外有一个比较特别的:
read-conditional
(reader-conditional form splicing?)
;;;; The data representation for reader conditionals is used by Clojure
;;;; when reading a string/file into Clojure data structures but choosing
;;;; to preserve the conditionals themselves (instead of replacing them with
;;;; the appropriate platform-specific code)
reader条件语句的表现?这个有点抽象,clojure用这个概念来做什么呢?也是像read-string那样来读入一个form,但是这些form可以保留条件语句(基于平台的代码)?
Use a different expression depending on the compiler (e.g. Clojure vs ClojureScript).
#?(:clj … :cljs …)
不同的编译器用不同的代码的意思?
lows the reader to conditionally select from the given list of forms depending on available “feature” keys. For example:
#?(:clj “Clojure”
:cljs “ClojureScript”)
ClojureScript’s reader is configured with the :cljs feature key, making the expression above read as “ClojureScript”. Clojure’s reader is similarly configured with the :clj key.
This essentially allows us to write portable code for use in both Clojure and ClojureScript.
也就是说主要用于让cljs代码也可以让Clojure编译器理解。
比如:
(defn str->int [s]
#?(:clj (java.lang.Integer/parseInt s)
:cljs (js/parseInt s)))
(str->int "123")测试你的编译器
boot.user=> #?(:clj “Clojure” :cljs “ClojureScript”)
“Clojure”
32、惰性序列 lazy-seq
实在很复杂,请参考
https://www.processon.com/view/link/5b1e76afe4b00490ac946e82
状态
—updating—最新更新于2018-06-11
声明:文中很多内容引用自clojure Docs和clojure APIs,不一一说明了。