Android知识点原理总结
Activity 4种启动模式
要讲启动模式,先讲讲任务栈Task,它是一种用来放置Activity实例的容器,他是以栈的形式进行盛放,也就是所谓的先进后出,主要有2个基本操作:压栈和出栈,其所存放的Activity是不支持重新排序的,只能根据压栈和出栈操作更改Activity的顺序。
启动一个Application的时候,系统会为它默认创建一个对应的Task,用来放置根Activity。默认启动Activity会放在同一个Task中,新启动的Activity,如果拥有相同affinity会放在同一个Task中,并且显示它
affinity是Activity内的一个属性,在ManiFest中对应属性为taskAffinity,可以手动修改,默认情况下,所有的Activity的affinity都从Application继承,为Manifest的包名。
当用户按下回退键时,这个Activity就会被弹出栈,按下Home键回到桌面,再启动另一个应用,这时候之前那个Task就被移到后台,成为后台任务栈,而刚启动的那个Task就被调到前台,成为前台任务栈,Android系统显示的就是前台任务栈中的栈顶实例Activity。
栈是一个先进后出的线性表,根据Activity在当前栈结构中的位置,来决定该Activity的状态。当然,世界不可能一直这么“和谐”,可以给Activity设置一些“特权”,来打破这种“和谐”的模式,这种特权,就是通过在AndroidManifest文件中的属性andorid:launchMode来设置或者通过Intent的flag来设置的,下面就先介绍下Activity的几种启动模式。
standard
默认模式:可以不用写配置。在这个模式下,都会默认创建一个新的实例。因此,在这种模式下,可以有多个相同的实例,也允许多个相同Activity叠加。
使用场景:绝大多数Activity。
singleTop
栈顶复用模式:如果要开启的Activity在任务栈的顶部已经存在,就不会创建新的实例,而是调用 onNewIntent() 方法。如果不位于栈顶,就会创建新的实例,避免栈顶的Activity被重复的创建。
使用场景:在通知栏点击收到的通知,然后需要启动一个
Activity,这个Activity就可以用singleTop,否则每次点击都会新建一个Activity。当然实际的开发过程中,测试妹纸没准给你提过这样的bug:某个场景下连续快速点击,启动了两个Activity。如果这个时候待启动的Activity使用singleTop模式也是可以避免这个Bug的。
singleTask
栈内复用模式: Activity只会在一个任务栈里面存在一个实例。如果要激活的Activity,在任务栈里面已经存在,就不会创建新的Activity,而是复用这个已经存在的Activity,调用 onNewIntent() 方法,并且清空这个Activity任务栈上面所有的Activity。singleTask模式和前面两种模式的最大区别就是singleTask模式是任务内单例的,在不同的任务栈可以存在多个实例。
使用场景:大多数
App的主页。对于大部分应用,当我们在主界面点击回退按钮的时候都是退出应用,那么当我们第一次进入主界面之后,主界面位于栈底,以后不管我们打开了多少个Activity,只要我们再次回到主界面,都应该使用将主界面Activity上所有的Activity移除的方式来让主界面Activity处于栈顶,而不是往栈顶新加一个主界面Activity的实例,通过这种方式能够保证退出应用时所有的Activity都能销毁。
singleInstance
单一实例模式:整个手机操作系统里面只有一个实例存在。在该模式下,我们会为目标Activity分配一个新的affinity,并创建一个新的Task栈,并且任务栈里面只有他一个实例存在。不同的应用去打开这个Activity 共享公用的同一个Activity。
应用场景:你会发现它启动时会慢一些,切换效果不好,影响用户体验。它往往用于多个应用之间,例如一个电视
Launcher里的Activity,通过遥控器某个键在任何情况可以启动,当在某应用中按键启动这个Activity,处理完后按返回键,就会回到之前启动它的应用,不影响用户体验。还有呼叫来电界面等
动态设置启动模式
我们说的动态设置,其实是通过Intent。如果我们要设置要启动的Activity的启动模式的话,只需要这样:
intent.setFlags(Intent.FLAG_ACTIVITY_XXX);
FLAG_ACTIVITY_NEW_TASK
在给目标Activity设立此Flag后,会根据目标Activity的affinity进行匹配:如果已经存在与其affinity相同的Task,则将目标Activity压入此Task。反之没有的话,则新建一个Task,新建的Task的affinity值与目标Activity相同。然后将目标Activity压入此栈。有两点注意的地方:
- 新的
Task没有说只能存放一个目标Activity。只是说决定是否新建一个Task。 - 在同一应用下,如果
Activity都是默认的affinity,那么此Flag无效。
使用场景:该
Flag通常使用在从Service中启动Activity的场景,由于Service中并不存在Activity栈,所以使用该Flag来创建一个新的Activity栈,并创建新的Activity实例。
FLAG_ACTIVITY_SINGLE_TOP
使用singletop模式启动一个Activity,与指定android:launchMode=“singleTop”效果相同。
FLAG_ACTIVITY_CLEAR_TOP
当设置此Flag时,目标Activity会检查Task中是否存在此实例,如果没有则添加压入栈,如果有,就将位于Task中的对应Activity其上的所有Activity弹出栈,接下来的操作有以下两种情况:
- 如果同时设置
Flag_ACTIVITY_SINGLE_TOP,则直接复用栈内的对应Activity,并调用onNewIntent(); - 没有设置
Flag_ACTIVITY_SINGLE_TOP,则将栈内的对应Activity销毁重新创建。
关于这个Flag,我们发现他和singleTask很像,但却有区别,不指定FLAG_ACTIVITY_SINGLE_TOP的话他会销毁已存在的目标实例再重新创建。准确的说,singleTask = FLAG_ACTIVITY_CLEAR_TOP+FLAG_ACTIVITY_SINGLE_TOP。
FLAG_ACTIVITY_NO_HISTORY
Activity使用这种模式启动Activity,当该Activity启动其他Activity后,该Activity就消失了,不会保留在Activity栈中。
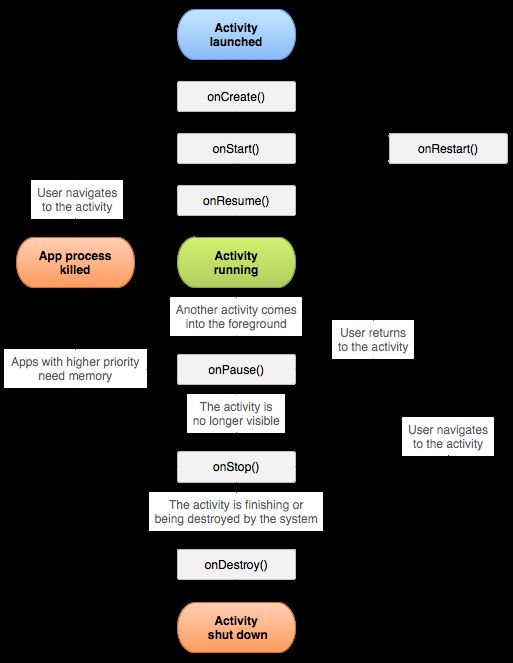
Activity 生命周期
onCreate(Bundle savedInstanceState)->onStart()->onResume()->onPause()->onStop()->onDestory()
-
onCreate(Bundle savedInstanceState)
系统首次创建Activity时触发。Activity会在创建后进入已创建状态。在onCreate() 方法中,您需执行基本应用启动逻辑,该逻辑在Activity的整个生命周期中只应发生一次。使用场景:
onCreate() 的实现可能会将数据绑定到列表,将Activity与ViewModel相关联,并实例化某些类范围变量。此方法接收savedInstanceState参数,后者是包含Activity先前保存状态的Bundle对象。如果Activity此前未曾存在,则Bundle对象的值为null。 -
onStart()
当Activity进入“已开始”状态时,系统会调用此回调。onStart()调用使Activity对用户可见,只是还没有在前台显示,没有焦点,因此用户也无法交互。因为应用会为Activity进入前台并支持交互做准备。使用场景:应用通过此方法来初始化维护界面的代码。比如注册一些变量。这些变量必须保证
Activity在前台的时候才能够被响应。因为生命周期较短,不要做一些耗时操作,也不要做一些与UI相关的。 -
onResume()
Activity会在进入“已恢复”状态时来到前台,然后系统调用onResume()回调。这是应用与用户交互的状态,Activity已在在屏幕上显示UI并获得了焦点。应用会一直保持这种状态,直到某些事件发生,让焦点远离应用。使用场景:可以启动任何需要在组件可见,且位于前台时运行的功能,例如启动摄像头预览与开启动画。
-
onPause()
系统将此方法视为用户正在离开您的Activity的第一个标志(尽管这并不总是意味着活动正在遭到销毁);此方法表示Activity不再位于前台(尽管如果用户处于多窗口模式,Activity仍然可见)。使用场景:可以停止任何无需在组件未在前台时运行的功能,例如停止摄像头预览与停止动画。
onPause方法执行完成后,新Activity的onResume方法才会被执行。所以onPause不能太耗时,因为这可能会影响到新的Activity的显示。 -
onStop()
如果您的Activity不再对用户可见,则说明其已进入已停止状态,因此系统将调用onStop() 回调。举例而言,如果新启动的Activity覆盖整个屏幕,就可能会发生这种情况。如果系统已结束运行并即将终止,系统还可以调用onStop()。需要注意的是:在内存不足而导致系统自动回收进程情况下,onStop()可能都不会被执行。使用场景:反注册在
onStart函数中注册的变量。您还应该使用onStop()执行CPU相对密集的关闭操作。例如,如果您无法找到更合适的时机来将信息保存到数据库,则可在onStop()期间执行此操作。 -
onDestroy()
销毁Activity之前,系统会先调用onDestroy()。使用场景:
onDestroy()回调应释放先前的回调(例如onStop())尚未释放的所有资源。
onRestart()
onRestart不属于正常下得生命周期。此方法回调时,表示Activity正在重新启动,由不可见状态变为可见状态。这种情况,一般发生在用户打开了一个新的Activity时,之前的Activity就会被onStop,接着又回到之前Activity页面时,之前的Activity的 onRestart方法就会被回调,接着走onStart以后的生命周期。
ActivityA跳转到ActivityB的生命周期
在
onResume()一般会打开独占设备,开启动画等,当需要从AActivity切换到BActivity时,先执行AActivity中的onPause()进行关闭独占设备,关闭动画等,以防止BActivity也需要使用这些资源,因为AActivity的资源回收,也有利于BActivity运行的流畅。
04-17 20:54:46.997: I/com.yhd.test.AActivity(5817): onPause()
04-17 20:54:47.021: I/com.yhd.test.BActivity(5817): onCreate()
04-17 20:54:47.028: I/com.yhd.test.BActivity(5817): onStart()
04-17 20:54:47.028: I/com.yhd.test.BActivity(5817): onResume()
04-17 20:54:47.099: I/com.yhd.test.AActivity(5817): onStop()
04-17 20:54:48.070: I/com.yhd.test.AActivity(5817): onDestroy()
onNewIntent(Intent intent)
官方解释:当Activity被设以singleTop模式(包含FLAG_ACTIVITY_SINGLE_TOP)启动,当需要再次响应此Activity启动需求时而且该Activity处于栈顶,会复用栈顶的已有Activity,还会调用onNewIntent方法。
onNewIntent设计初衷是为了Activity的复用,与onCreate只能二选一。其实除了singleTop启动模式,还有singleTask和singleInstance。下面分三种情况讨论会调用onNewIntent的情形:
- 当ActivityA为SingleTop、SingleTask或者singleInstance且在栈顶
且现在要再启动ActivityA,这时会调用onNewIntent()方法 ,生命周期顺序为:onPause--->onNewIntent--->onResume - 当ActivityA为SingleTask或者singleInstance且不处于栈顶
且现在要再启动ActivityA,这时会调用onNewIntent()方法 ,生命周期顺序为:onNewIntent--->onRestart--->onStart--->onResume
更准确的说法是,只对SingleTop(且位于栈顶),SingleTask和SingleInstance(且已经在任务栈中存在实例)的情况下,再次启动它们时才会调用,即只对startActivity有效,对仅仅从后台切换到前台而不再次启动的情形,不会触发onNewIntent。
需要注意的是:如果我们在
onNewIntent中不执行setIntent(intent),那么getIntent()得到的intent永远是上次旧的。
onSavedInstanceState()和onRestoreInstanceState()
如果系统由于系统约束(不是正常的应用程序行为,如内存不足、用户直接按Home和Menu键以及屏幕旋转)而破坏了Activity,onSaveInstanceState()就会调用,如果Activity重新创建才会执行和onRestoreInstanceState()。重建的时候这些UI的状态会默认保存,但是前提条件是UI控件必须制定id,如果没有指定id的话,UI的状态是无法保存的。
- 按下Home和Menu键
04-16 15:32:35.243 1741/com.yhd.test E/TAG-: onPause 04-16 15:32:35.304 1741/com.yhd.test E/TAG-: onSaveInstanceState 04-16 15:32:35.309 1741/com.yhd.test E/TAG-: onStop - 旋转屏幕
04-16 15:36:01.427 1741/com.yhd.test E/TAG: onPause 04-16 15:36:01.427 1741/com.yhd.test E/TAG: onSaveInstanceState 04-16 15:36:01.433 1741/com.yhd.test E/TAG: onStop 04-16 15:36:01.433 1741/com.yhd.test E/TAG: onDestroy 04-16 15:36:01.454 1741/com.yhd.test E/TAG: onCreate 04-16 15:36:01.465 1741/com.yhd.test E/TAG: onStart 04-16 15:36:01.465 1741/com.yhd.test E/TAG: onRestoreInstanceState 04-16 15:36:01.468 1741/com.yhd.test E/TAG: onResume
保存你的Activity状态
当您的Activity由于系统约束开始停止时,系统会调用onSaveInstanceState()以便您的Activity可以使用一组键值对来保存状态信息。此方法的默认实现保存有关Activity视图层次结构状态的信息(如果想要保存具体内容需要有id)。为了保存Activity的附加状态信息,您必须实现onSaveInstanceState()并向对象添加键值对Bundle。
@Override
public void onSaveInstanceState(Bundle savedInstanceState) {
// 保存用户自定义的状态
savedInstanceState.putString("KEY", object);
// 调用父类交给系统处理,这样系统能保存视图层次结构状态以及内容信息
super.onSaveInstanceState(savedInstanceState);
}
恢复您的Activity状态
当您的Activity由于系统约束重新创建时,您可以从Bundle系统通过您的Activity中恢复您的保存状态。这两个方法onCreate()和onRestoreInstanceState()回调方法都会收到相同的Bundle包含实例状态信息。唯一不一样的是,onCreate中的savedInstanceState可能是空的,只有由于系统约束重新创建时才不为空。而onRestoreInstanceState中的savedInstanceState一定不为空。
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState); // 记得总是调用父类
// 检查是否正在重新创建一个以前销毁的实例
if (savedInstanceState != null) {
// 从已保存状态恢复成员的值
value = savedInstanceState.getString("KEY");
}
}
当然,你也可以不用onCreate去恢复数据,使用onRestoreInstanceState可以省去null判断。
public void onRestoreInstanceState(Bundle savedInstanceState) {
// 总是调用超类,以便它可以恢复视图层次超级
super.onRestoreInstanceState(savedInstanceState);
// 从已保存的实例中恢复状态成员
value = savedInstanceState.getString("KEY");
}
Android 动画
Android系统提供了很多丰富的API去实现UI的2D与3D动画,最主要的划分可以分为如下几类:
- View Animation: 视图动画又称补间动画,只能被用来设置
View的动画。 - Drawable Animation: 这种动画(也叫
Frame动画、帧动画)其实可以划分到视图动画的类别,专门用来一个一个的显示Drawable的resources,就像放幻灯片一样。 - Property Animation: 属性动画只对
Android 3.0(API 11)以上版本系统才有效,这种动画可以设置给任何Object,包括那些还没有渲染到屏幕上的对象。这种动画是可扩展的,可以自定义任何类型和属性的动画。
View Animation
视图动画(View Animation)又称补间动画(Tween Animation),即给出两个关键帧通过一些算法将给定属性值在给定的时间内在两个关键帧间渐变。视图动画只能作用于View对象,是对View的变换,而且View的位置并未更改,很容易导致其点击事件响应错位。
在Android3.0(api 11)之前,是不能用属性动画的,只能用补间动画,而补间动画所做的动画效果只是将View的显示转为图片,然后再针对这个图片做透明度、平移、旋转、缩放等效果。这带来的问题是:View所在的区域并没有发生变化,变化的只是个“幻影”而已。也就是说,在Android 3.0之前,要想将View区域发生变化,就得改变top、left、right、bottom。如果想让View的动画是实际的位置发生变化,并且要兼容3.0之前的软件,为了解决这个问题,从3.0开始,加了几个新的参数:x,y,translationX,translationY。
x = left + translationX;
y = top + translationY;
这样,如果想要移动View,只需改变translationX和translationY就可以了,top和left不会发生变化。也可以使用属性动画去改变translationX和translationY。
默认支持的类型有:
- 透明度变化(AlphaAnimation)
- 缩放(ScaleAnimation)
- 位移(TranslateAnimation)
- 旋转(RotateAnimation)
可以使用AnimationSet让多个动画集合在一起运行,使用插值器(Interpolator)设置动画的速度。上面的几种动画以及AnimationSet都是Animation的子类,因此Animation中有的属性以及xml的配置属性他们都有,对于使用xml配置时需要放到res下面的anim文件夹下。
插值器有:
- 线性插值器(LinearInterpolator)
- 加速插值器(AccelerateInterpolator)
- 减速插值器(DecelerateInterpolator)
- 加减速插值器(AccelerateDecelerateInterpolator)
- 正弦加速器(CycleInterpolator)
动画原理解析
动画就是根据间隔时间,不停的去刷新界面,把时间分片,在那个时间片,通过传入插值器的值到Animation.applyTransformation(),来计算当前的值(比如旋转角度值,透明度等)。在动画的执行过程中,会反复的调用applyTransformation()方法。每次调用参数interpolatedTime值都会变化,该参数从0.0递增为1.0,当该参数为1.0时表示动画结束。Transformation类封装了矩阵Matrix和透明度Alpha值,通过参数Transformation来设置Matrix和Alpha,实现各种效果。因此,可以继承Animation,重写applyTransformation()来实现其他的动画。
要使用View动画,首先要创建XML文件,我们需要在res下新建anim文件夹,接着在anim下创建view_anim.xml:
<set
xmlns:android="http://schemas.android.com/apk/res/android">
<translate
android:fromXDelta="0%p"
android:toXDelta="20%p"
android:fromYDelta="0%p"
android:toYDelta="20%p"
android:duration="4000"/>
<scale
android:fromXScale="1.0"
android:toXScale="0.2"
android:fromYScale="1.0"
android:toYScale="0.2"
android:pivotX="50%"
android:pivotY="50%"
android:duration="4000"/>
<rotate
android:fromDegrees="0"
android:toDegrees="360"
android:pivotX="50%"
android:pivotY="50%"
android:duration="4000"/>
<alpha
android:fromAlpha="1.0"
android:toAlpha="0.2"
android:duration="4000"/>
set>
上面的代码我们知道,View动画既可以是单个动画,也可以有一系列动画组成。
这是因为View动画的四种种类分别对应着Animation的四个子类(TranslateAnimation,ScaleAnimation,RotateAnimation,AlphaAnimation),除了以上四个子类它还有一个AnimationSet类,对应xml标签为activity对TextView设置动画:
Animation animation = AnimationUtils.loadAnimation(MainActivity.this,R.anim.view_anim);
textView.startAnimation(animation);
Drawable Animation
Drawable动画其实就是Frame动画(帧动画,也属于View动画)。通过顺序播放一系列图像从而产生动画效果,可以简单理解为图片切换动画效果,但图片过多过大会导致OOM。
<-- oneshot true代表只执行一次,false循环执行 -->
<animation-list xmlns:android="http://schemas.android.com/apk/res/android" android:oneshot="false">
<item android:drawable="@mipmap/pic1" android:duration="200"/>
<item android:drawable="@mipmap/pic2" android:duration="200"/>
animation-list>
ImageView rocketImage = (ImageView) findViewById(R.id.rocket_image);
rocketImage.setBackgroundResource(R.drawable.rocket_thrust);
rocketAnimation = (AnimationDrawable) rocketImage.getBackground();
rocketAnimation.start();
Property Animation
补间动画由于动画效果局限性(平移、旋转、缩放、透明度)、View位置无法改变特性以及只能作用于View对象的缺陷,在 Android 3.0(API 11)开始,系统提供了一种全新的动画模式:属性动画(Property Animation)。它可以作用任意 Java 对象,可自定义各种动画效果。
工作原理:
属性动画通过在预设的规则下不断地改变值,并将值设置给作用对象的属性,从而达到动画效果。这个规则可以由我们定制,其中有两个重要的工具,可以帮助我们定制值的变化规则,一个是插值器(Interpolator)提供变化速率,一个是估值器(TypeEvaluator)提供变化的开始结束范围。
估值器:
估值器的作用是根据开始值、结束值、开始结束之间的一个比例来计算出最终的值。在属性动画上则是计算出动画对应的最终的属性值。系统默认提供了3种估值器。
- IntEvaluator:整型估值器,值的类型为整型
- FloatEvaluator:浮点型估值器,值的类型为浮点型
- ArgbEvaluator:值的类型为ARGB值,可以用来计算颜色值
属性动画主要通过两个类来使用,ValueAnimator和ObjectAnimator,这两个的区别主要是ValueAnimator只是计算值,赋值给对象属性需要我们手动监听值的变化来进行;ObjectAnimator则对赋值属性这一步封装进了内部,也就是自动赋值。
ValueAnimator
ValueAnimator valueAnimator = ValueAnimator.ofFloat(0f, 1f); //估值器,变化范围从0到1
valueAnimator.setDuration(2000);//设置动画持续时间,以毫秒为单位
valueAnimator.setInterpolator(new DecelerateInterpolator());//设置插值器
valueAnimator.setRepeatMode(ValueAnimator.REVERSE);//设置动画重复模式,RESTART表示动画正序重复,REVERSE代表倒序重复
valueAnimator.setRepeatCount(1);//设置重复次数,也就是动画播放次数=RepeatCount+1,ValueAnimator.INFINITE表示无限重复
valueAnimator.setStartDelay(1000);//设置动画延迟播放的时间
valueAnimator.addUpdateListener(new ValueAnimator.AnimatorUpdateListener() {//动画值更新时的监听器
@Override
public void onAnimationUpdate(ValueAnimator animation) {//动画更新时会回调此方法
Float value= (Float) animation.getAnimatedValue();//拿到更新后动画值
}
});
ObjectAnimator
相比于ValueAnimator,ObjectAnimator可能才是我们最常接触到的类,因为ValueAnimator只不过是对值进行了一个平滑的动画过渡,但我们实际使用到这种功能的场景好像并不多。而ObjectAnimator则就不同了,它是可以直接对任意对象的任意属性进行动画操作的,比如说View的alpha属性。
ObjectAnimator利用反射调用对象属性的set方法从而自动赋值给对象属性完成动画,也就是说ObjectAnimator作用的对象必须提供该属性的set方法(如果没有提供初始值,还必须提供get方法)需要注意的是,set和get方法名必须满足如下规则:set/get+属性名(属性名头字母大写)。
ObjectAnimator animator = ObjectAnimator.ofFloat(textview, "alpha", 1f, 0f, 1f);
animator.setInterpolator(new DecelerateInterpolator());//设置插值器
animator.setDuration(5000);
animator.start();
组合动画(AnimatorSet)
独立的动画能够实现的视觉效果毕竟是相当有限的,因此将多个动画组合到一起播放就显得尤为重要。幸运的是,Android团队在设计属性动画的时候也充分考虑到了组合动画的功能,因此提供了一套非常丰富的API来让我们将多个动画组合到一起。
实现组合动画功能主要需要借助AnimatorSet这个类,这个类提供了一个play()方法,如果我们向这个方法中传入一个Animator对象(ValueAnimator或ObjectAnimator)将会返回一个AnimatorSet.Builder的实例,AnimatorSet.Builder中包括以下四个方法:
- after(Animator anim) :将现有动画插入到传入的动画之后执行
- after(long delay):将现有动画延迟指定毫秒后执行
- before(Animator anim):将现有动画插入到传入的动画之前执行
- with(Animator anim):将现有动画和传入的动画同时执行
好的,有了这四个方法,我们就可以完成组合动画的逻辑了,那么比如说我们想要让TextView先从屏幕外移动进屏幕,然后开始旋转360度,旋转的同时进行淡入淡出操作,就可以这样写:
ObjectAnimator moveIn = ObjectAnimator.ofFloat(textview, "translationX", -500f, 0f);
ObjectAnimator rotate = ObjectAnimator.ofFloat(textview, "rotation", 0f, 360f);
ObjectAnimator fadeInOut = ObjectAnimator.ofFloat(textview, "alpha", 1f, 0f, 1f);
AnimatorSet animSet = new AnimatorSet();
animSet.play(rotate).with(fadeInOut).after(moveIn);
animSet.setDuration(5000);
animSet.start();

类加载机制
class A {
static {
System.out.println("A的静态块");
}
private static String staticStr = getStaticStr();
private String str = getStr();
{
System.out.println("A的实例块");
}
public A() {
System.out.println("A的构造方法");
}
private static String getStaticStr() {
System.out.println("A的静态属性初始化");
return null;
}
private String getStr() {
System.out.println("A的实例属性初始化");
return null;
}
public static void main(String[] args) {
new B();
new B();
}
}
class B extends A{
private static String staticStr = getStaticStr();
static {
System.out.println("B的静态块");
}
{
System.out.println("B的实例块");
}
public B() {
System.out.println("B的构造方法");
}
private String str = getStr();
private static String getStaticStr() {
System.out.println("B的静态属性初始化");
return null;
}
private String getStr() {
System.out.println("B的实例属性初始化");
return null;
}
}

实例化子类的时候,若此类未被加载过,首先加载是父类的类对象,然后加载子类的类对象,接着实例化父类,最后实例化子类,若此类被加载过,不再加载父类和子类的类对象。
接下来是加载顺序,当加载类对象时,首先初始化静态属性,然后执行静态块;当实例化对象时,首先执行构造块(直接写在类中的代码块),然后执行构造方法。至于各静态块和静态属性初始化哪个些执行,是按代码的先后顺序。属性、构造块(也就是上面的实例块)、构造方法之间的执行顺序(但构造块一定会在构造方法前执行),也是按代码的先后顺序。
- 1、父类静态初始化块(按照静态从上到下的顺序)
- 2、子类静态初始化块
- 3、父类初始化块
- 4、父类构造器(属性,构造块、构造器按从上到下顺序,前提:构造块一定在构造方法前)
- 5、子类初始化块
- 6、子类构造器
JNI
JNI的全称是Java Native Interface(Java本地接口)是一层接口,是用来沟通Java代码和C/C++代码的,是Java和C/C++之间的桥梁。通过JNI,Java可以完成对外部C/C++库函数的调用,相对的,外部C/C++也能调用Java中封装好的类和方法。
Java的优点是跨平台,和操作系统之间的调用由JVM完成,但是一些和操作系统相关的操作就无法完成,JNI的出现刚好弥补了这个缺陷,也完善了Java语言,将Java扩展得更为强大。
开发
JNI需要NDK的支持,NDK(Native Development Kit)是Android所提供的一个工具集合,通过NDK可以在Android中更加方便地通过JNI来调用本地代码(C/C++)。NDK提供了交叉编译器,开发时只需要修改.mk文件就能生成特定的CPU平台的动态库。
JNI的应用场景
- 实际中的驱动都是
C/C++开发的,通过JNI,Java可以调用C/C++实现的驱动,从而扩展Java虚拟机的能力。 - 另外,在高效率的数学运算、游戏的实时渲染、音视频的编码和解码等方面,一般都是用
C开发的。
Android Studio JNI中快速生成头文件
File->Setting->Tools->External Tools->Add External Tools:
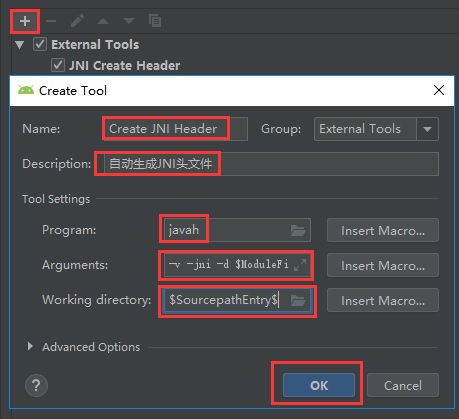
具体内容:
Program: javah
Arguments: -v -jni -d $ModuleFileDir$/src/main/jni $FileClass$
Working directory: $SourcepathEntry$
生成JNI头文件:

创建Android.mk和Application.mk
#LOCAL_PATH是所编译的C文件的根目录,右边的赋值代表根目录即为Android.mk所在的目录
LOCAL_PATH:=$(call my-dir)
#在使用NDK编译工具时对编译环境中所用到的全局变量清零
include $(CLEAR_VARS)
#最后声称库时的名字的一部分
LOCAL_MODULE:=JniTest
#要被编译的C文件的文件名
LOCAL_SRC_FILES:=JniTest.c
#NDK编译时会生成一些共享库
include $(BUILD_SHARED_LIBRARY)
#表示编译选择的平台
#APP_ABI := armeabi,armeabi-v7a,x86,mips,arm64-v8a,mips64,x86_64
#表示编译全部平台
APP_ABI := all
让app组件支持C++编译
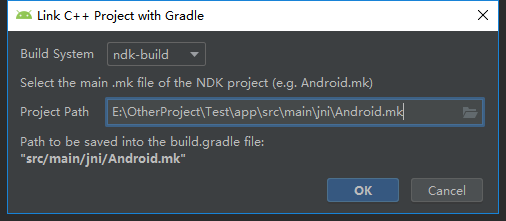
让app组件的build.gradle关联
android {
...
externalNativeBuild {
ndkBuild {
path file('src/main/jni/Android.mk')
}
}
}
开始编译

使用
Log.e("yhd-",new JniTest().sayHello());
基础知识点
- JNIEnv
调用 Java 函数 :JNIEnv代表Java运行环境, 可以使用JNIEnv调用Java中的代码;
操作 Java 对象 :Java对象传入JNI层就是Jobject对象, 需要使用JNIEnv来操作这个Java对象; - JNIEXPORT
Windows中,定义为__declspec(dllexport)。因为Windows编译dll动态库规定,如果动态库中的函数要被外部调用,需要在函数声明中添加此标识,表示将该函数导出在外部可以调用。 - JNICALL
在Windows中定义为:_stdcall,一种函数调用约定。
JNI注册方式
-
静态注册
上述方式就是注册 -
动态注册
我们知道Java Native函数和JNI函数时一一对应的,JNI中就有一个叫JNINativeMethod的结构体来保存这个对应关系,实现动态注册方就需要用到这个结构体。1.声明native方法还是一样的
public class JavaHello { public static native String hello(); }2.创建jni目录,然后在该目录创建hello.c文件,如下:
#include#include #include #include #include /** * 定义native方法 */ JNIEXPORT jstring JNICALL native_hello(JNIEnv *env, jclass clazz) { printf("hello in c native code./n"); return (*env)->NewStringUTF(env, "hello world returned."); } // 指定要注册的类 #define JNIREG_CLASS "com/yhd/JavaHello" // 定义一个JNINativeMethod数组,其中的成员就是Java代码中对应的native方法 static JNINativeMethod gMethods[] = { { "hello", "()Ljava/lang/String;", (void*)native_hello}, }; static int registerNativeMethods(JNIEnv* env, const char* className, JNINativeMethod* gMethods, int numMethods) { jclass clazz; clazz = (*env)->FindClass(env, className); if (clazz == NULL) { return JNI_FALSE; } if ((*env)->RegisterNatives(env, clazz, gMethods, numMethods) < 0) { return JNI_FALSE; } return JNI_TRUE; } /*** * 注册native方法 */ static int registerNatives(JNIEnv* env) { if (!registerNativeMethods(env, JNIREG_CLASS, gMethods, sizeof(gMethods) / sizeof(gMethods[0]))) { return JNI_FALSE; } return JNI_TRUE; } /** * 如果要实现动态注册,这个方法一定要实现 * 动态注册工作在这里进行 */ JNIEXPORT jint JNICALL JNI_OnLoad(JavaVM* vm, void* reserved) { JNIEnv* env = NULL; jint result = -1; if ((*vm)-> GetEnv(vm, (void**) &env, JNI_VERSION_1_4) != JNI_OK) { return -1; } assert(env != NULL); if (!registerNatives(env)) { //注册 return -1; } result = JNI_VERSION_1_4; return result; } 先仔细看一下上面的代码,看起来好像多了一些代码,稍微解释下,如果要实现动态注册就必须实现
JNI_OnLoad方法,这个是JNI的一个入口函数,我们在Java层通过System.loadLibrary加载完动态库后,紧接着就会去查找一个叫JNI_OnLoad的方法。如果有,就会调用它,而动态注册的工作就是在这里完成的。在这里我们会去拿到JNI中一个很重要的结构体JNIEnv,env指向的就是这个结构体,通过env指针可以找到指定类名的类,并且调用JNIEnv的RegisterNatives方法来完成注册native方法和JNI函数的对应关系。
()Ljava/lang/String:方法签名,对应规则如下:

静态注册
- 优点: 理解和使用方式简单, 属于傻瓜式操作, 使用相关工具按流程操作就行, 出错率低
- 缺点: 当需要更改类名,包名或者方法时, 需要按照之前方法重新生成头文件, 灵活性不高
动态注册
- 优点: 灵活性高, 更改类名,包名或方法时, 只需对更改模块进行少量修改, 效率高
- 缺点: 对新手来说稍微有点难理解, 同时会由于搞错签名, 方法, 导致注册失败
JNI如何调用java层代码
Android开发中调用一个类中没有公开的方法,可以进行反射调用,而JNI开发中C调用java的方法也是反射调用。
//TextJNI -> public int add(int a, int b){return a+b;}
JNIEXPORT void JNICALLJava_com_yhd_TestJNI_callbackIntmethod(JNIEnv *env, jobject object) {
//获取字节码对
jclass clzz=(*env)->FindClass(env,"com/yhd/TextJNI");
//通过字节码对象找到方法对象,后面的参数是方法签名信息,参考上面提到的
jmethodID methodID=(*env)->GetMethodID(env,clzz,"add","(II)I");
//通过对象调用方法,可以调用空参数方法,也可以调用有参数方法,并且将参数通过调用的方法传入
int result=(*env)->CallIntMethod(env,object,methodID,3,4);
JNI实战-读取IIC数据
整个过程大概要经过如下:
- 系统层需要写好读取IIC的字符驱动.
- 注册驱动,设置权限chmod 777 /dev/i2c-1
- 挂在驱动节点/dev/i2c-1
- JNI层通过节点名称"/dev/i2c-1"打开驱动
下面提供JNI源码
#include Android体系架构
Android也采用分层的架构设计,从高到低分别是系统应用层(System Apps),Java API 框架层(Java API Framework),Android系统运行层(包括Android Runtime和原生态的C/C++库 Native C/C++ Libraries)、硬件抽象层(Hardware Abstraction Layer)、Linux内核层(Linux Kernel)。如下图所示:

1、Linux内核层
Android是基于Linux内核的(Linux内核提供了安全性、内存管理、进程管理、网络协议和驱动模型等核心系统服务),Linux内核层为各种硬件提供了驱动程序,如显示驱动、相机驱动、蓝牙驱动、电池管理等等。
2、硬件抽象层(Hardware Abstraction Layer)
这是从软件设计角度看:主要目的在于将硬件抽象化。硬件抽象化可以隐藏特定平台的硬件接口细节,为上面一层提供固定统一的接口,使其具有硬件无关性。
从版权/保护厂家利益因素角度看:Android基于Linux内核实现,Linux是GPL许可,即对源码的修改都必须开源,而Android是ASL许可,即可以随意使用源码,无需开源,因此将原本位于kernel的硬件驱动逻辑转移到Android平台来,就可以不必开源,从而保护了厂家的利益。因此Android就提供了一套访问硬件抽象层动态库的接口,各厂商在Android的硬件抽象层实现特定硬件的操作细节,并编译成so库,以库的形式提供给用户使用。(Android是一个开放的平台,并不是一个开源的平台。)
3、Android系统运行层
原生态的C/C++库:通过C或者C++库为Android系统提供主要的特性支持,例如Surface Manager管理访问显示子系统和从多模块应用中无缝整合2D和3D的图形,WebKit提供了浏览器支持等。可以使用 Android NDK 直接从访问某些原生态库。
Android Runtime:Android运行时,其中包括了ART虚拟机(Android 5.0之前是Dalvik虚拟机,ART模式与Dalvik模式最大的不同在于,在启用ART模式后,系统在安装应用的时候会进行一次预编译,在安装应用程序时会先将代码转换为机器语言存储在本地,这样在运行程序时就不会每次都进行一次编译了,执行效率也大大提升。如果您的应用在 ART 上运行效果很好,那么它应该也可在 Dalvik 上运行,但反过来不一定。),每个Java程序都运行在ART虚拟机上,该虚拟机专门针对移动设备进行了定制,每个应用都有其自己的 Android Runtime (ART) 实例。此外,Android运行时还包含一套核心运行时库,可提供 Java API 框架使用的 Java 编程语言大部分功能,包括一些 Java 8 语言功能。
4、Java API 框架层
这一层主要提供了构建应用程序时可能用到的各种API,开发者通过这一层的API构建自己的APP,这一层也是APP开发人员必须要掌握的内容。其中最重要的是AMS、WMS、PMS。
5、系统应用层
系统内置的应用程序以及非系统级的应用程序都属于应用层,负责与用户进行直接交互,通常都是用Java进行开发的。
Android系统启动流程
当用户按下开机键的时候,引导芯片加载BootLoader到内存中,开始拉起Linux OS,一旦Linux内核启动完毕后,它就会在系统文件中寻找 init.rc 文件,并启动init 进程。
1、Init
在启动的init进程中,会进入system/core/init/init.cpp文件的main方法中。做了一以下事情:
- 1.创建和挂载启动所需要的文件和目录。
- 2.初始化和启动属性服务。
- 3.解析
init.rc配置文件,并且启动了Zygote进程。
2、Zygote
在Android系统中,DVM(Dalvik虚拟机)和ART、应用程序进程以及运行系统关键服务的SystemServer进程都是由Zygote进程创建的,我们也将它称为孵化器(本来字面意思就是受精卵)。它通过fork复制进程的形势来创建应用进程和SystemServer进程,由于Zygote进程在启动时会创建DVM或者ART,因此通过fork而创建的应用程序进程和SystemServer进程可以在内部获取一个DVM或者ART的实例副本。Zygote进程启动公做了几件事:
- 1.创建
AndroidRuntime并调用其start方法,启动Zygote进程。 - 2.创建
Java虚拟机并为Java虚拟机注册JNI方法。 - 3.通过JNI调用
ZygoteInit的main函数进入Zygote的Java框架层。 - 4.通过
registerZygoteSocket方法创建服务端Socket,并通过runSelectLoop方法等待AMS的请求来创建新的应用程序进程。 - 5.启动
SystemServer。
3、SystemServer
SystemServer在启动后,陆续启动了各项服务,包括ActivityManagerService,PowerManagerService,PackageManagerService等等,而这些服务的父类都是SystemService。总结一下SystemServer进程:
- 1.启动
Binder线程池。 - 2.创建了
SystemServiceManager(用于对系统服务进行创建、启动和生命周期管理)。 - 3.启动了各种服务。
Framework
Android的Framework是直接应用之下的一层,叫做应用程序框架层。这一层是核心应用程序所使用的API框架,为应用层提供各种API,提供各种组件和服务来支持我们的Android开发,包括ActivityManager、WindowManager、ViewSystem等。我们可以称Framework层才真正是Java语言实现的层,在这层里定义的API都是用Java语言编写,但是又因为它包含了JNI的方法,JNI用C/C++编写接口,根据函数表查询调用核心库层里的底层方法,最终访问到Linux内核。那么Framework层的作用就有2个:
- 用
Java语言编写一些规范化的模块封装成框架,供APP层开发者调用开发出具有特殊业务的手机应用。 - 用
Java Native Interface调用core lib层的本地方法,JNI的库是在Dalvik虚拟机启动时加载进去的,Dalvik会直接去寻址这个JNI方法,然后去调用。
ActivityManagerService
内存管理,进程管理,管理着Activity的任务堆栈、Service的启动、ContentProvider启动、BroadCast Receiver列表管理等。AMS也决定了某个进程会不会被杀死。AMS实现了IBinder接口,所以它是一个Binder,这意味着它不但可以用于进程间通信,还是一个线程,因为一个Binder就是一个线程。这个怎么理解呢?可以这么理解,如果我们启动一个Hello World安卓应用程序,里面不另外启动其他线程,这个进程里面我们最起码启动了4个线程:
- Main线程:这是程序的主线程,也是我们日常编写代码时用到最多的那个线程。比如我们重写了
Activity的onCreate()方法,一般就是这个main线程来执行代码,也叫ui线程。这是因为安卓的组件(包括TextView,Button等等这些ui控件)都是非线程安全的,所以只允许main线程来操作。 - GC线程:我们都知道,
java有垃圾回收机制,每个java程序(一个java虚拟机)都有一个垃圾回收线程,专门回收不再使用的对象。 - Binder1就是我们的ApplicationThread:这个类实现了
IBinder接口,用于进程间通信。具体来说,是我们的应用程序和Ams通信的工具。 - Binder2就是我们的ViewRoot.W对象:它也是实现了
IBinder接口,是用于我们的应用程序和Wms通信的工具。
下面看看Activity如何与AMS通信的:

ActivityThread
ActivityThread就是我们常说的主线程或UI线程,ActivityThread的main方法是整个APP的入口。当AMS拉起一个新的进程,同时启动一个主线程的时候,主线程就从ActivityThread.main方法开始执行,它会初始化一些对象,然后自己进入消息等待队列, 也就是Looper.loop()。一旦进入loop()方法,线程就进入了死循环,再也不会退出;一直在等待别人给他消息,然后执行这个消息。
//ActivityThread的main方法
public static void main(String[] args) {
...
Looper.prepareMainLooper();
ActivityThread thread = new ActivityThread();
//在attach方法中会完成Application对象的初始化,然后调用Application的onCreate()方法
thread.attach(false);
if (sMainThreadHandler == null) {
sMainThreadHandler = thread.getHandler();
}
...
Looper.loop();
throw new RuntimeException("Main thread loop unexpectedly exited");
}
ApplicationThread
ApplicationThread是ActivityThread的私有内部类,实现了IBinder接口,用于ActivityThread和ActivityManagerService的所在进程间通信。
APP启动流程

- 点击桌面
APP图标时,Launcher的startActivity()方法,通过Binder通信,调用system_server进程中AMS服务的startActivity方法,发起启动请求。 system_server进程接收到请求后,向Zygote进程发送创建进程的请求。Zygote进程fork出App进程,并执行ActivityThread的main方法,创建ActivityThread线程,初始化MainLooper,主线程Handler,同时初始化ApplicationThread用于和AMS通信交互。App进程,通过Binder向sytem_server进程发起attachApplication请求,这里实际上就是APP进程通过Binder调用sytem_server进程中AMS的attachApplication方法,上面我们已经分析过,AMS的attachApplication方法的作用是将ApplicationThread对象与AMS绑定。system_server进程在收到attachApplication的请求,进行一些准备工作后,再通过binderIPC向App进程发送handleBindApplication请求(初始化Application并调用onCreate方法)和scheduleLaunchActivity请求(创建启动Activity)。App进程的binder线程(ApplicationThread)在收到请求后,通过handler向主线程发送BIND_APPLICATION和LAUNCH_ACTIVITY消息,这里注意的是AMS和主线程并不直接通信,而是AMS和主线程的内部类ApplicationThread通过Binder通信,ApplicationThread再和主线程通过Handler消息交互。- 主线程在收到
Message后,创建Application并调用onCreate方法,再通过反射机制创建目标Activity,并回调Activity.onCreate()等方法。 - 到此,
App便正式启动,开始进入Activity生命周期,执行完onCreate/onStart/onResume方法,UI渲染后显示APP主界面。
Android App 启动速度优化
冷启动(Cold start)
冷启动是指APP在手机启动后第一次运行,或者APP进程被kill掉后在再次启动。可见冷启动的必要条件是该APP进程不存在,这就意味着系统需要创建进程,APP需要初始化。在这三种启动方式中,冷启动耗时最长,对于冷启动的优化也是最具挑战的。因此本文重点谈论的是对冷启动相关的优化。
温启动(Warm start)
App进程存在,当时Activity可能因为内存不足被回收。这时候启动App不需要重新创建进程,但是Activity的onCrate还是需要重新执行的。场景类似打开淘宝逛了一圈然后切到微信去聊天去了,过了半小时再次回到淘宝。这时候淘宝的进程存在,但是Activity可能被回收,这时候只需要重新加载Activity即可。
热启动(Hot start)
App进程存在,并且Activity对象仍然存在内存中没有被回收。可以重复避免对象初始化,布局解析绘制。场景就类似你打开微信聊了一会天这时候出去看了下日历在打开微信 微信这时候启动就属于热启动。
启动原理
点击桌面后的APP启动,通过startActivity方式的启动。调用startActivity,该方法经过层层调用,最终会调用ActivityStackSupervisor.java中的startSpecificActivityLocked,当activity所属进程还没启动的情况下,则需要创建相应的进程,最终进程由 Zygote Fork进程。进程启动后立即显示应用程序的空白启动窗口。而一旦App进程完成了第一次绘制,系统进程就会用MainActivity替换已经展示的Background Window,此时用户就可以使用App了。
启动时间优化
这里涉及到:异步加载、延时加载、懒加载
- Application OnCrate()优化
当App启动时,空白的启动窗口将保留在屏幕上,直到系统首次完成绘制应用程序。此时,系统进程会交换应用程序的启动窗口,允许用户开始与应用程序进行交互。如果应用程序中重载了Application.onCreate(),系统会调用onCreate()方法。之后,应用程序会生成主线程(也称为UI线程),并通过创建MainActivity来执行任务。 - Activity onCreate()优化
onCreate()方法对加载时间的影响最大,因为它以最高的开销执行工作:加载并绘制视图,以及初始化Activity运行所需的对象。
用户体验优化
- 甩锅给系统
使用透明主题- true
Activity.onCreate()之前App不做显示,这样用户误以为是手机慢了,这种瞒天过海的方案大家还是不要用了。 - 给我们的应用窗口弄一个PlaceHolder
1、做一个logo_splash的背景:
2、弄一个主题:<layer-list xmlns:android="http://schemas.android.com/apk/res/android"> <item android:drawable="@color/white" /> <item> <bitmap android:gravity="center" android:src="@drawable/ic_github" /> item> layer-list>
3、将一个什么不渲染布局的Activity作为启动屏,并加上主题:<style name="SplashTheme" parent="AppTheme">- "android:windowBackground"
>@drawable/logo_splash style><activity android:name=".ui.module.main.LogoSplashActivity" android:screenOrientation="portrait" android:theme="@style/SplashTheme"> <intent-filter> <action android:name="android.intent.action.MAIN"/> <category android:name="android.intent.category.LAUNCHER"/> intent-filter> activity>
什么时候可以拿到图片的宽高
其实Activity 的 onCreate/onStart/onResume三个回调中,是在第一个performTraversals执行的,并没有执行Measure和Layout操作,这个是在后面的performTraversals中才执行的,所以在这之前宽高都是0。可以在队列中拿到图片的宽高:getWindow().getDecorView().post(runnable)和Handle.postDelay(runnable,milsecond),第二种延迟时间不好把握,第一种是最好的。
Activity onResume 回调的时候真的可见了么
Fragment回调了onResume方法却并没有进去前台可见,所以不能仅仅依靠onResume判断。有个方法专门判断Fragment是否可见:getUserVisibleHint();
ThreadLocal 做什么的
一般来说,当某些数据是以线程为作用域并且不同线程具有不同的数据副本的时候,就可以考虑采用 ThreadLocal,通过 ThreadLocal 可以在不同的线程中维护一套数据的副本并且彼此互不干扰。
ThreadLocal 是一个线程内部的数据存储类,通过它可以在 指定的线程中 存储数据,数据存储以后,只有在指定线程中可以获取到存储的数据,对于其他线程来说则无法获取到数据。
private void threadLocal() {
ThreadLocal<Boolean> mThreadLocal = new ThreadLocal<>();
mThreadLocal.set(true);
Log.d(TAG, "[Thread#main]threadLocal=" + mThreadLocal.get());//true
new Thread() {
@Override
public void run() {
super.run();
mThreadLocal.set(false);
Log.d(TAG, "[Thread#1]threadLocal=" + mThreadLocal.get());//false
}
}.start();
new Thread() {
@Override
public void run() {
super.run();
Log.d(TAG, "[Thread#2]threadLocal=" + mThreadLocal.get());//null
}
}.start();
}
为什么不能在子线程更新 UI
Android的UI访问是没有加锁的,多个线程可以同时访问更新操作同一个UI控件。也就是说访问UI的时候Android系统当中的控件都不是线程安全的,这将导致在多线程模式下,当多个线程共同访问更新操作同一个UI控件时容易发生不可控的错误,而这是致命的。所以Android中规定只能在UI线程中访问UI,这相当于从另一个角度给Android的UI访问加上锁,一个伪锁。
题外话:我们在onCreate中创建线程更新UI,却能成功。
当访问UI时,ViewRootImpl会调用checkThread方法检查当前访问UI的线程是哪个,如果不是UI线程则会抛出异常。ViewRootImpl的创建是在onResume方法回调之后,而我们一开篇是在onCreate方法中创建子线程并访问UI,在那个时刻,ViewRootImpl还没有来得及创建,无法检测当前线程是否是UI线程,所以程序没有崩溃。而之后修改了程序,让线程休眠了100毫秒后再更新UI,程序就崩了。很明显在这100毫秒内ViewRootImpl已经完成了创建,并能执行checkThread方法检查当前访问并更新UI的线程是不是UI线程。
Android消息机制
Android UI是线程不安全的,如果在子线程中尝试进行UI操作,程序就有可能会崩溃,因为在ViewRootImpl.checkThread对UI操作做了验证,导致必须在主线程中访问UI,但Android在主线程中进行耗时的操作会导致ANR,为了解决子线程无法访问UI的矛盾,提供了消息机制。
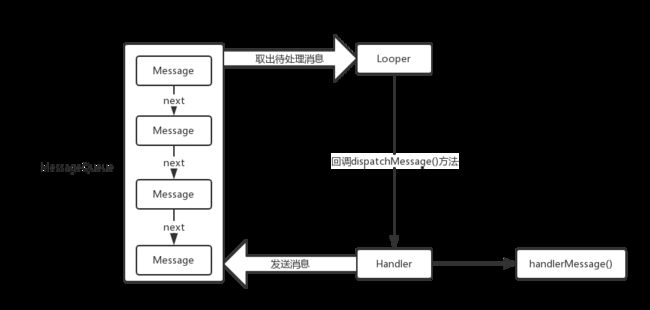
Handler通过sendMessage或者post发送消息,最终都调用sendMessageAtTime将Message交给MessageQueue,MessageQueue.enqueueMessage方法将Message以链表的形式放入队列中(同步操作,线程安全),Looper的loop方法循环调用MessageQueue.next()取出消息,并且调用Handler的dispatchMessage来处理消息。在dispatchMessage中,分别判断msg.callback(runnable)不为空就执行回调,如果为空就执行handleMessage。
Handler工作原理
Handler是Android给我们提供用来更新UI的一套机制,是一套消息处理机制,可以通过它来发送消息和处理消息。消息发送通过post系列方法和send系列方法来实现,而post最终还是调用sendMessageAtTime方法来实现发送消息。Handler的运行需要底层的MessageQueue和Looper的支撑。MessageQueue即消息队列,存储消息的单元,但并不能处理消息,这时需要Looper,它会无限循环查找是否有新消息,有即处理消息,没有就等待。
private Handler handler1;
private Handler handler2;
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
handler1 = new Handler();
new Thread(new Runnable() {
@Override
public void run() {
handler2 = new Handler();
}
}).start();
}
运行下会发现
handler2会报下面的错误“Can't create handler inside thread that has not called Looper.prepare()”
为什么handler1没有报错呢?因为Handler的创建时会采用当前线程的Looper来构建内部的消息循环系统,而handler1是在主线程创建的,而主线程已经默认调用Looper.prepareMainLooper()创建Looper以及Looper.loop()阻塞接受消息,所以handler2创建时需要先调用Looper.prepare()创建Looper,最后执行Looper.loop()开始运作。
MessageQueue工作原理
MessageQueue只有两个操作:插入和读取。其内部是一个单链表的数据结构来维护消息列表,链表的节点就是 Message。它提供了 enqueueMessage() (内部用了synchronized同步锁保证线程安全)来进行插入新的消息,提供next() 从链表中取出消息,值得注意的是next()会循环地从链表中取出 Message 交给 Handler,但如果链表为空的话会阻塞这个方法,直到有新消息到来。
Looper工作原理
Looper最重要的方法是loop方法,只有调用了loop后,消息系统才会真正的起作用。loop()方法是一个死循环,唯一跳出就是next返回null。既然是死循环,为什么主线程没有卡死呢?
主线程的MessageQueue没有消息时,便阻塞在loop的queue.next()中的nativePollOnce()方法里,没有输入事件,Looper此时处于空闲状态,此时主线程会释放CPU资源进入休眠状态,直到下个消息到达或者有事务发生,通过往pipe管道写端写入数据来唤醒主线程工作。而真正的卡死,指的是有输入事件的,MessageQueue是不为空的,那么Looper依然会正常轮询。线程也没有阻塞。当事件的执行时间过长的话,而且此时与其他事件都没办法处理,那么就是真正的卡死了,然后就ANR了。
Service两种启动方式
第一种方式:通过StartService启动Service
通过startService启动后,Service会一直无限期运行下去,只有外部调用了stopService()或stopSelf()方法时,该Service才会停止运行并销毁。
pulic class TestOneService extends Service{
@Override
public void onCreate() {
super.onCreate();
//onCreate()只会在第一次创建service时候调用,多次执行startService()不会重复调用onCreate(),此方法适合完成一些初始化工作。
}
@Override
public int onStartCommand(Intent intent, int flags, int startId) {
return super.onStartCommand(intent, flags, startId);
//如果多次执行了Context的startService()方法,那么Service的onStartCommand()方法也会相应的多次调用。onStartCommand()方法很重要,我们在该方法中根据传入的Intent参数进行实际的操作,比如会在此处创建一个线程用于下载数据或播放音乐等。
}
@Nullable
@Override
public IBinder onBind(Intent intent) {
//Service中的onBind()方法是抽象方法,Service类本身就是抽象类,所以onBind()方法是必须重写的,即使我们用不到。
return null;
}
@Override
public void onDestroy() {
super.onDestroy();
//在销毁的时候会执行Service该方法。
}
}
第二种方式:通过bindService启动Service
bindService启动服务特点:
- 1.
bindService启动的服务和调用者之间是典型的client-server模式。调用者是client,service则是server端。service只有一个,但绑定到service上面的client可以有一个或很多个。这里所提到的client指的是组件,比如某个Activity。 - 2.
client可以通过IBinder接口获取Service实例,从而实现在client端直接调用Service中的方法以实现灵活交互,这在通过startService方法启动中是无法实现的。 - 3.
bindService启动服务的生命周期与其绑定的client息息相关。当client销毁时,client会自动与Service解除绑定。当然,client也可以明确调用Context的unbindService()方法与Service解除绑定。当没有任何client与Service绑定时,Service会自行销毁。
public class TestTwoService extends Service{
//client 可以通过Binder获取Service实例
public class MyBinder extends Binder {
public TestTwoService getService() {
return TestTwoService.this;
}
}
//通过binder实现调用者client与Service之间的通信
private MyBinder binder = new MyBinder();
@Nullable
@Override
public IBinder onBind(Intent intent) {
return binder;
}
@Override
public boolean onUnbind(Intent intent) {
return false;
}
//其他生命周期省略
}
绑定与解绑
private ServiceConnection conn = new ServiceConnection() {
@Override
public void onServiceConnected(ComponentName name, IBinder binder) {
isBind = true;
TestTwoService.MyBinder myBinder = (TestTwoService.MyBinder) binder;
service = myBinder.getService();
}
@Override
public void onServiceDisconnected(ComponentName name) {
isBind = false;
}
};
//绑定
bindService(intent, conn, BIND_AUTO_CREATE);
//解绑
unbindService(conn);
进程和线程
- 进程是系统进行资源分配和调度的一个独立单位。
- 线程:是进程的一个实体,是
CPU调度和分派的基本单位,它是比进程更小的能独立运行的基本单位。线程自己基本上不拥有系统资源,只拥有一些在运行中必不可少的资源(如程序计数器,一组寄存器和栈),但是它可与同属一个进程的其他的线程共享进程所拥有的全部资源。
Android中进程间通信(IPC)方式
1、Bundle
在Android中三大组件(Activity,Service,Receiver)都支持在Intent中传递Bundle数据,由于Bundle实现了Parcelable接口(一种特有的序列化方法),所以它可以很方便的在不同的进程之间进行传输。当在一个进程中启动另外一个进程的Activity,Service,Receiver时,可以在Bundle中附加需要传输给远程的进程的信息,并通过Intent发送出去。
2、使用文件共享的方式
文件共享:将对象序列化之后保存到文件中,在通过反序列,将对象从文件中读取出来。此方式对文件的格式没有具体的要求,可以是文件、XML、JSON等。
文件共享方式也存在着很大的局限性,如并发读/写问题,如读取的数据不完整或者读取的数据不是最新的。文件共享适合在对数据同步要求不高的进程间通信,并且要妥善处理并发读/写的问题。
3、使用Messenger的方式
我们也可以通过Messenger来进行进程间通信,在Messenger中放入我们需要传递的数据,实现进程间数据传递。Messenger只能传递Message对象,Messenger是一种轻量级的IPC方案,它的底层实现是AIDL。

Messenger内部消息处理使用Handler实现的,所以它是以串行的方式处理客服端发送过来的消息的,如果有大量的消息发送给服务器端,服务器端只能一个一个处理,如果并发量大的话用Messenger就不合适了,而且Messenger的主要作用就是为了传递消息,很多时候我们需要跨进程调用服务器端的方法,这种需求Messenger就无法做到了。
4、使用AIDL的方式
AIDL(Android Interface Definition Language)是一种IDL语言,用于生成可以在Android设备上两个进程之间进行进程间通信(IPC)的代码。
如果在一个进程中(例如Activity)要调用另一个进程中(例如Service)对象的操作,就可以使用AIDL生成可序列化的参数。AIDL是IPC的一个轻量级实现,Android也提供了一个工具,可以自动创建Stub(类架构,类骨架)。
只有当你允许来自不同的客户端访问你的服务并且需要处理多线程问题时你才必须使用AIDL,其他情况下都可以选择其他方法。AIDL是处理多线程、多客户端并发访问的,而Messenger是单线程处理。
5、使用ContentProvider的方式
ContentProvider(内容提供者)是Android中的四大组件之一,为了在应用程序之间进行数据交换,Android提供了ContentProvider,ContentProvider是不同应用之间进行数据交换的API,一旦某个应用程序通过ContentProvider暴露了自己的数据操作的接口,那么不管该应用程序是否启动,其他的应用程序都可以通过接口来操作接口内的数据,包括数据的增、删、改、查等操作。
6、使用广播接收者(Broadcast)的方式
广播是一种被动跨进程通信方式。当某个程序向系统发送广播时,其他的应用程序只能被动地接收广播数据。
Broadcast Receiver本质上是一个系统级的监听器,它专门监听各个程序发出的Broadcast,因此它拥有自己的进程,只要存在与之匹配的Intent被广播出来,Broadcast Receiver总会被激发。只要注册了某个广播之后,广播接收者才能收到该广播。广播注册的一个行为是将自己感兴趣的Intent Filter注册到Android系统的AMS(Activity Manager Service)中,里面保存了一个Intent Filter列表。广播发送者将Intent Filter的action行为发送到AMS中,然后遍历AMS中的Intent Filter列表,看谁订阅了该广播,然后将消息遍历发送到注册了相应的Intent Filter或者Service中。也就是说:会调用抽象方法onReceive()方法。其中AMS起到了中间桥梁的作用。
onReceiver()方法中尽量不要做耗时操作,如果onReceiver()方法不能再10秒之内完成事件的处理,Android会认为该进程无响应,也就弹出我们熟悉的ANR。
7、使用Socket的方式
Socket也是实现进程间通信的一种方式,Socket也称为“套接字”(网络通信中概念),通过Socket也可以实现跨进程通信,Socket主要还是应用在网络通信中。
Android进程保活
startForeground()方法
在onStartCommand里面调用startForeground()方法把Service提升为前台进程级别,然后再onDestroy里面要记得调用stopForeground ()方法。也可以在onStartCommand()方法中开启一个通知,提高进程的优先级。
onStartCommand方法,返回START_STICKY
在onStartCommand方法中手动返回START_STICKY,当service因内存不足被kill,当内存又存在的时候,service又被重新创建,但是不能保证任何情况下都被重建,比如:进程被干掉了。
在onDestroy方法里发广播重启service
service+broadcast方式,就是当service走onDestory的时候,发送一个自定义的广播,当收到广播的时候,重新启动service。因为广播是AMS级别的,所以可以保证应用退出还能收到广播。(第三方应用或是在setting里-应用-强制停止时,APP进程就直接被干掉了,onDestroy方法都进不来,所以无法保证会执行)。
监听(系统)广播判断Service状态
通过监听系统、QQ,微信,系统应用,友盟推送等的一些广播,比如:手机重启、界面唤醒、应用状态改变等监听并捕获到,然后判断我们的Service是否还存活,并唤醒自己的App。这是大厂常用方法,例如:阿里收购友盟后,通过友盟的广播唤醒阿里的App,然后把自己启动了。
Application加上Persistent属性
这个是题外话,因为只有系统级别编译才有
android:persistent="true"属性。
看Android的文档知道,当进程长期不活动,或系统需要资源时,会自动清理门户,杀死一些Service,和不可见的Activity等所在的进程。但是如果某个进程不想被杀死(如数据缓存进程,或状态监控进程,或远程服务进程),应该怎么做,才能使进程不被杀死。
监听锁屏方法
QQ采取在锁屏的时候启动一个1个像素的Activity,当用户解锁以后将这个Activity结束掉(顺便同时把自己的核心服务再开启一次)。
双进程守护
一个进程被杀死,另外一个进程又被他启动。相互监听启动。A<—>B,杀进程是一个一个杀的。本质是和杀进程时间赛跑。在Android 5.0前是有效的,5.0之后就不行了。
android:priority
priority必须是整数,默认是0, 范围是[-1000,1000]- 优先级的概念用于描述控件的
intent的filter的类型。 - 这个属性只对
activity和receiver是有意义的。
隐式调用activity的情况下: 如果多个activity满足响应 的条件, 系统只会触发priority高的那个activity。
有序广播发出的情况下:如果多个receiver满足响应的条件,系统会优先触发priority高的那个receiver。
<service
android:name="com.yhd.UploadService"
android:enabled="true" >
<intent-filter android:priority="1000" >
<action android:name="com.yhd.myservice" />
intent-filter>
service>
Java的基本类型占字节数
| 数据类型 | 占用字节数 | 位数 | 取值范围 |
|---|---|---|---|
| 整数型:byte | 1 | 8 | -2的7次方到2的7次方-1 |
| 布尔型:boolean | 1 | 8 | -2的7次方到2的7次方-1 |
| 整数型:short | 2 | 16 | -2的15次方到2的15次方-1 |
| 字符型:char | 2 | 16 | -2的15次方到2的15次方-1 |
| 整数型:int | 4 | 32 | -2的31次方到2的31次方-1 |
| 浮点型:float | 4 | 32 | -2的31次方到2的31次方-1 |
| 整数型:long | 8 | 64 | -2的63次方到2的63次方-1 |
| 浮点型:double | 8 | 64 | -2的63次方到2的63次方-11 |
Android GC机制(垃圾回收)
在Android中 ,Dalvik的垃圾回收算法为:标注与清理(Mark and Sweep)和拷贝GC,但是具体使用什么算法是在编译期决定的,无法在运行的时候动态更换。在/dalvik/vm/Dvm.mk里,指明了"WITH_COPYING_GC“选项,则编译”/dalvik/vm/alloc/Copying.cpp“源码 ,此是Android中拷贝GC算法的实现,否则编译”/dalvik/vm/alloc/HeapSource.cpp",使用标注与清理算法。到了Android 5.0 的ART,有多个不同的 GC 方案,这些方案包括运行不同垃圾回收器。默认方案是 CMS(并发标记清除)方案,下面详解。
GC会造成什么影响
也就是说,当垃圾回收开始清理资源时,其余的所有线程都会被停止。所以,我们要做的就是尽可能的让它执行的时间变短。如果清理的时间过长,在我们的应用程序中就能感觉到明显的卡顿。
什么情况下GC会执行
- 当应用程序空闲时,即没有应用线程在运行时,
GC会被调用。因为GC在优先级最低的线程中进行,所以当应用忙时,GC线程就不会被调用,但以下条件除外。 Java堆内存不足时,GC会被调用。当应用线程在运行,并在运行过程中创建新对象,若这时内存空间不足,JVM就会强制地调用GC线程,以便回收内存用于新的分配。若GC一次之后仍不能满足内存分配的要求,JVM会再进行两次GC作进一步的尝试,若仍无法满足要求,则JVM将报“OutOfMemory”的错误,Java应用将停止。
垃圾判定算法
对象什么时候回收?判断对象是否回收主要有以下两种算法。
引用计数算法
给对象中添加一个引用计数器,每当有一个地方引用它时,计数器值就加1;当引用失效时,计数器值就减1;任何时刻计数器为0的对象就是不可能再被使用的。
- 优点:简单,高效,
Objective-c和swift用的就是这种算法。 - 缺点:很难处理循环引用,比如图中相互引用的两个对象则无法释放。但是也有解决办法:
strong/weak类型指针或者retain/assign类型指针分别修饰循环引用对象,破坏循环链。
可达性分析算法(根搜索算法)
为了解决上面的循环引用问题,Java采用了一种新的算法:可达性分析算法。
从GC Roots作为起点,向下搜索它们引用的对象,可以生成一棵引用树,树的节点视为可达对象,反之视为不可达。如果出现循环引用了,只要没有被GC Roots引用了就会被回收,完美解决!

Java定义的GC Roots对象:
1、虚拟机栈(帧栈中的本地变量表)中引用的对象。
2、方法区中静态属性引用的对象。
3、方法区中常量引用的对象。
4、本地方法栈中JNI引用的对象。
方法区回收
上面说的都是对堆内存中对象的判断,方法区中主要回收的是废弃的常量和无用的类。判断常量是否废弃可以判断是否有地方引用这个常量,如果没有引用则为废弃的常量,需要同时满足如下条件:
- 该类所有的实例已经被回收(堆中不存在任何该类的实例)。
- 加载该类的ClassLoader已经被回收。
- 该类对应的java.lang.Class对象在任何地方没有被引用(无法通过反射访问该类的方法)。
垃圾回收算法
知道了什么时候回收对象,那我们再看具体怎么垃圾回收。
标记清除法
标记-清除法分为两个阶段:标记阶段和清除阶段。标记阶段的任务是标记出所有需要被回收的对象,清除阶段就是回收被标记的对象所占用的空间。
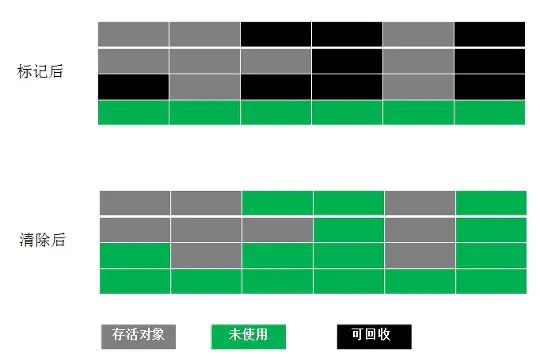
- 优点:是简单,容易实现。
- 缺点:容易产生内存碎片,碎片太多可能会导致后续过程中需要为大对象分配空间时无法找到足够的空间而提前触发新的一次垃圾收集动作。
复制算法
复制算法将可用内存按容量划分为大小相等的两块,每次只使用其中的一块。当这一块的内存用完了,就将还存活着的对象复制到另外一块上面,然后再把已使用的内存空间一次清理掉,这样一来就不容易出现内存碎片的问题。
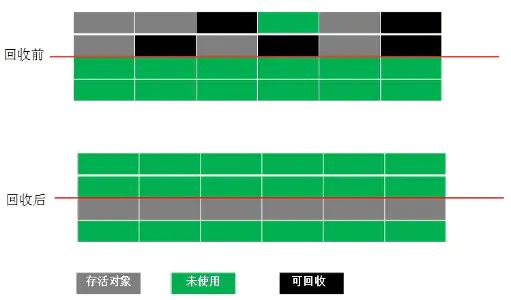
- 优点:实现简单,运行高效且不容易产生内存碎片,适用于存活对象很少。回收对象多。
- 缺点:内存空间的使用做出了高昂的代价,因为能够使用的内存缩减到原来的一半,如果存活对象很多,那么Copying算法的效率将会大大降低。
标记整理算法
该算法标记阶段和标记清除法一样,但是在完成标记之后,它不是直接清理可回收对象,而是将存活对象都向一端移动,然后清理掉端边界以外的内存。

- 优点:不会出现内存碎片问题,适用于存活对象多,回收对象少的情况使用
- 缺点:整理时间长,容易导致卡顿。
分代回收算法
分代回收算法其实不算一种新的算法,而是根据复制算法和标记整理算法的使用场景综合使用。根据对象存活的生命周期将内存划分为若干个不同的区域。
- Young(年轻代)
每次垃圾回收时都有大量的对象需要被回收所以采用复制算法。- Eden(伊利园):存放新生对象。(内存大小:
Eden:Survivor为8:1) - Survivor(幸存者):存放经过垃圾回收没有被清除的对象。
- Eden(伊利园):存放新生对象。(内存大小:
- Tenured(老年代):对象多次回收没有被清除,则移到该区块。
每次垃圾收集时只有少量对象需要被回收所以采用标记整理法。 - Perm(持久代):存放加载的类别还有方法对象。
1、首先,所有新生成的对象都是放在年轻代的Eden分区的,初始状态下两个Survivor分区都是空的。年轻代的目标就是尽可能快速的收集掉那些生命周期短的对象。

2、当Eden区满的的时候,小垃圾收集就会被触发。

3、当Eden分区进行清理的时候,会把引用对象移动到第一个Survivor分区,无引用的对象删除。

4、在下一个小垃圾收集的时候,在Eden分区中会发生同样的事情:无引用的对象被删除,引用对象被移动到另外一个Survivor分区(S1)。此外,从上次小垃圾收集过程中第一个Survivor分区(S0)移动过来的对象年龄增加,然后被移动到S1。当所有的幸存对象移动到S1以后,S0和Eden区都会被清理。注意到,此时的Survivor分区存储有不同年龄的对象。

5、在下一个小垃圾收集,同样的过程反复进行。然而,此时Survivor分区的角色发生了互换,引用对象被移动到S0,幸存对象年龄增大。Eden和S1被清理。

6、这幅图展示了从年轻代到老年代的提升。当进行一个小垃圾收集之后,如果此时年老对象此时到达了某一个个年龄阈值(例子中使用的是8),JVM会把他们从年轻代提升到老年代。

7、随着小垃圾收集的持续进行,对象将会被持续提升到老年代。

8、这样几乎涵盖了年轻一代的整个过程。最终,在老年代将会进行大垃圾收集,这种收集方式会清理-压缩老年代空间。
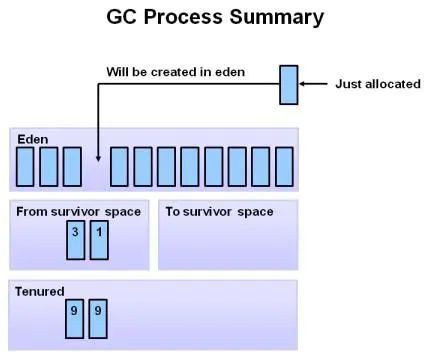
也就是说,刚开始会先在新生代内部反复的清理,顽强不死的移到老生代清理,最后都清不出空间,就爆炸了。
与堆配置相关的参数
| 参数 | 描述 |
|---|---|
| -Xms | JVM启动的时候设置初始堆的大小 |
| -Xmx | 设置最大堆的大小 |
| -Xmn | 设置年轻代的大小 |
| -XX:PermSize | 设置持久代的初始的大小 |
| -XX:MaxPermSize | 设置持久代的最大值 |
JVM知识点
一、JVM内存区域
Java虚拟机在运行时,会把内存空间分为若干个区域,根据《Java虚拟机规范(Java SE 7 版)》的规定,Java虚拟机所管理的内存区域分为如下部分:方法区、堆内存、虚拟机栈、本地方法栈、程序计数器。

1、方法区
方法区主要用于存储虚拟机加载的类信息、常量、静态变量,以及编译器编译后的代码等数据。在jdk1.7及其之前,方法区是堆的一个“逻辑部分”(一片连续的堆空间),但为了与堆做区分,方法区还有个名字叫“非堆”,也有人用“永久代”(HotSpot对方法区的实现方法)来表示方法区。
从jdk1.7已经开始准备“去永久代”的规划,jdk1.7的HotSpot中,已经把原本放在方法区中的静态变量、字符串常量池等移到堆内存中,(常量池除字符串常量池还有class常量池等),这里只是把字符串常量池移到堆内存中;在jdk1.8中,方法区已经不存在,原方法区中存储的类信息、编译后的代码数据等已经移动到了元空间(MetaSpace)中,元空间并没有处于堆内存上,而是直接占用的本地内存(NativeMemory)。
去永久代的原因有:
(1)字符串存在永久代中,容易出现性能问题和内存溢出。
(2)类及方法的信息等比较难确定其大小,因此对于永久代的大小指定比较困难,太小容易出现永久代溢出,太大则容易导致老年代溢出。
(3)永久代会为 GC 带来不必要的复杂度,并且回收效率偏低。
2、堆内存
堆内存主要用于存放对象和数组,它是JVM管理的内存中最大的一块区域,堆内存和方法区都被所有线程共享,在虚拟机启动时创建。在垃圾收集的层面上来看,由于现在收集器基本上都采用分代收集算法,因此堆还可以分为新生代(YoungGeneration)和老年代(OldGeneration),新生代还可以分为Eden、From Survivor、To Survivor。
3、程序计数器
程序计数器是一块非常小的内存空间,可以看做是当前线程执行字节码的行号指示器,每个线程都有一个独立的程序计数器,因此程序计数器是线程私有的一块空间,此外,程序计数器是Java虚拟机规定的唯一不会发生内存溢出的区域。
4、虚拟机栈
虚拟机会为每个线程分配一个虚拟机栈,每个虚拟机栈中都有若干个栈帧,每个栈帧中存储了局部变量表、操作数栈、动态链接、返回地址等。一个栈帧就对应Java代码中的一个方法,当线程执行到一个方法时,就代表这个方法对应的栈帧已经进入虚拟机栈并且处于栈顶的位置,每一个Java方法从被调用到执行结束,就对应了一个栈帧从入栈到出栈的过程。
5、本地方法栈
本地方法栈与虚拟机栈的区别是,虚拟机栈执行的是Java方法,本地方法栈执行的是本地方法(Native Method),其他基本上一致,在HotSpot中直接把本地方法栈和虚拟机栈合二为一,这里暂时不做过多叙述。
二、JVM内存溢出
1、堆内存溢出
堆内存中主要存放对象、数组等,只要不断地创建这些对象,并且保证GC Roots到对象之间有可达路径来避免垃圾收集回收机制清除这些对象,当这些对象所占空间超过最大堆容量时,就会产生OutOfMemoryError的异常。
2、虚拟机栈/本地方法栈溢出
- StackOverflowError:当线程请求的栈的深度大于虚拟机所允许的最大深度,则抛出
StackOverflowError,简单理解就是虚拟机栈中的栈帧数量过多(一个线程嵌套调用的方法数量过多)时,就会抛出该异常。最常见的场景就是方法无限递归调用。 - OutOfMemoryError:如果虚拟机在扩展栈时无法申请到足够的内存空间,则抛出
OutOfMemoryError。我们可以这样理解,虚拟机中可以供栈占用的空间≈可用物理内存 - 最大堆内存 - 最大方法区内存,比如一台机器内存为4G,系统和其他应用占用2G,虚拟机可用的物理内存为2G,最大堆内存为1G,最大方法区内存为512M,那可供栈占有的内存大约就是512M,假如我们设置每个线程栈的大小为1M,那虚拟机中最多可以创建512个线程,超过512个线程再创建就没有空间可以给栈了,就报OutOfMemoryError异常了。
3、方法区溢出
前面说到,方法区主要用于存储虚拟机加载的类信息、常量、静态变量,以及编译器编译后的代码等数据,所以方法区溢出的原因就是没有足够的内存来存放这些数据。
由于在jdk1.6之前字符串常量池是存在于方法区中的,所以基于jdk1.6之前的虚拟机,可以通过不断产生不一致的字符串(同时要保证和GC Roots之间保证有可达路径)来模拟方法区的OutOfMemoryError异常;但方法区还存储加载的类信息,所以基于jdk1.7的虚拟机,可以通过动态不断创建大量的类来模拟方法区溢出。
4、本机直接内存溢出
本机直接内存(DirectMemory)并不是虚拟机运行时数据区的一部分,也不是Java虚拟机规范中定义的内存区域,但Java中用到NIO相关操作时(比如ByteBuffer的allocteDirect方法申请的是本机直接内存),也可能会出现内存溢出的异常。
三、类加载
编写的Java代码需要经过编译器编译为class文件(从本地机器码转变为字节码的过程),class文件是一组以8位字节为基础的二进制流,这些二进制流分别以一定形式表示着魔数(用于标识是否是一个能被虚拟机接收的Class文件)、版本号、字段表、访问标识等内容。代码编译为class文件后,需要通过类加载器把class文件加载到虚拟机中才能运行和使用。
1、类加载步骤
类从被加载到内存到使用完成被卸载出内存,需要经历加载、连接、初始化、使用、卸载这几个过程,其中连接又可以细分为验证、准备、解析。

(1)加载
在加载阶段,虚拟机主要完成三件事情:
- ① 通过一个类的全限定名(比如
com.yhd.MyClassLoader)来获取定义该类的二进制流; - ② 将这个字节流所代表的静态存储结构转化为方法区的运行时存储结构;
- ③ 在内存中生成一个代表这个类的
java.lang.Class对象,作为程序访问方法区中这个类的外部接口。
(2)验证
验证的目的是为了确保class文件的字节流包含的内容符合虚拟机的要求,且不会危害虚拟机的安全。
- 文件格式验证:主要验证
class文件中二进制字节流的格式,比如魔数是否已0xCAFEBABY开头、版本号是否正确等。 - 元数据验证:主要对字节码描述的信息进行语义分析,保证其符合
Java语言规范,比如验证这个类是否有父类(java.lang.Object除外),如果这个类不是抽象类,是否实现了父类或接口中没有实现的方法等等。 - 字节码验证:字节码验证更为高级,通过数据流和控制流分析,确保程序是合法的、符合逻辑的。
- 符号引用验证:对类自身以外的信息进行匹配性校验,举个栗子,比如通过类的全限定名能否找到对应类、在类中能否找到字段名/方法名对应的字段/方法,如果符号引用验证失败,将抛出“
java.lang.NoSuchFieldError”、“java.lang.NoSuchMethodError”等异常。
(3)准备
正式为类变量分配内存并设置类变量初始值,这些变量所使用的内存都分配在方法区。注意分配内存的对象是类变量而不是实例变量,而且为其分配的是“初始值”.一般数值类型的初始值都为0,char类型的初始值为’\u0000’(常量池中一个表示Nul的字符串),boolean类型初始值为false,引用类型初始值为null。
(4)解析
解析是将常量池中符号引用替换为直接引用的过程。
符号引用是以一组符号来描述所引用的目标,符号引用与虚拟机实现的内存布局无关,引用的目标不一定已经加载到内存中。比如在com.yhd.LoggerFactory类引用了com.yhd.Logger,但在编译期间是不知道Logger类的内存地址的,所以只能先用com.yhd.Logger(假设是这个,实际上是由类似于CONSTANT_Class_info的常量来表示的)来表示Logger类的地址,这就是符号引用。
直接引用可以是直接指向目标的指针、相对偏移量或是一个能间接定位到目标的句柄。直接引用和虚拟机实现的内存布局有关,如果有了直接引用,那引用的目标一定在内存中存在。
(5)初始化
在准备阶段,已经为类变量赋了初始值,在初始化阶段,则根据程序员通过程序定制的主观计划去初始化类变量的和其他资源,也可以从另一个角度来理解:初始化阶段是执行类构造器()方法的过程,那()到底是什么呢?
java在生成字节码时,如果类中有静态代码块或静态变量的赋值操作,会将类构造器()方法和实例构造器 () 方法添加到语法树中(可以理解为在编译阶段自动为类添加了两个隐藏的方法:类构造器——()方法和实例构造器——()方法,可以用javap命令查看),()主要用来构造类,比如初始化类变量(静态变量),执行静态代码块(statis{})等,该方法只执行一次;()方法主要用来构造实例,在构造实例的过程中,会首先执行(),这时对象中的所有成员变量都会被设置为默认值(每种数据类型的默认值和类加载准备阶段描述的一样),然后才会执行实例的构造函数(会先执行父类的构造方法,再执行非静态代码块,最后执行构造函数)。
2、类加载器
(1)类加载器的作用
- 加载class:类加载的加载阶段的第一个步骤,就是通过类加载器来完成的,类加载器的主要任务就是“通过一个类的全限定名来获取描述此类的二进制字节流”,在这里,类加载器加载的二进制流并不一定要从
class文件中获取,还可以从其他格式如zip文件中读取、从网络或数据库中读取、运行时动态生成、由其他文件生成(比如jsp生成class类文件)等。从程序员的角度来看,类加载器动态加载class文件到虚拟机中,并生成一个java.lang.Class实例,每个实例都代表一个java类,可以根据该实例得到该类的信息,还可以通过newInstance()方法生成该类的一个对象。 - 确定类的唯一性:类加载器除了有加载类的作用,还有一个举足轻重的作用,对于每一个类,都需要由加载它的加载器和这个类本身共同确立这个类在
Java虚拟机中的唯一性。也就是说,两个相同的类,只有是在同一个加载器加载的情况下才“相等”,这里的“相等”是指代表类的Class对象的equals()方法、isAssignableFrom()方法、isInstance()方法的返回结果,也包括instanceof关键字对对象所属关系的判定结果。
(2)类加载器的分类
以开发人员的角度来看,类加载器分为如下几种:启动类加载器(Bootstrap ClassLoader)、扩展类加载器(Extension ClassLoader)、应用程序类加载器(Application ClassLoader)和自定义类加载器(User ClassLoader),其中启动类加载器属于JVM的一部分,其他类加载器都用java实现,并且最终都继承自java.lang.ClassLoader。
- ① 启动类加载器(Bootstrap ClassLoader):由
C/C++编译而来的,看不到源码,所以在java.lang.ClassLoader源码中看到的Bootstrap ClassLoader的定义是native的“private native Class findBootstrapClass(String name)”。启动类加载器主要负责加载JAVA_HOME\lib目录或者被-Xbootclasspath参数指定目录中的部分类,具体加载哪些类可以通过“System.getProperty(“sun.boot.class.path”)”来查看。 - ② 扩展类加载器(Extension ClassLoader):负责加载
JAVA_HOME\lib\ext目录或者被java.ext.dirs系统变量指定的路径中的所有类库,由sun.misc.Launcher.ExtClassLoader实现,,可以用通过“System.getProperty(“java.ext.dirs”)”来查看具体都加载哪些类。 - ③ 应用程序类加载器(Application ClassLoader):负责加载用户类路径(我们通常指定的
classpath)上的类,由sun.misc.Launcher.AppClassLoader实现,如果程序中没有自定义类加载器,应用程序类加载器就是程序默认的类加载器。 - ④ 自定义类加载器(User ClassLoader):
JVM提供的类加载器只能加载指定目录的类(jar和class),如果我们想从其他地方甚至网络上获取class文件,就需要自定义类加载器来实现,自定义类加载器主要都是通过继承ClassLoader或者它的子类来实现,但无论是通过继承ClassLoader还是它的子类,最终自定义类加载器的父加载器都是应用程序类加载器,因为不管调用哪个父类加载器,创建的对象都必须最终调用java.lang.ClassLoader.getSystemClassLoader()作为父加载器,getSystemClassLoader()方法的返回值是sun.misc.Launcher.AppClassLoader即应用程序类加载器。
(3)ClassLoader与双亲委派模型
双亲委派模型的工作过程是,如果一个类加载器收到了类加载的请求,它首先不会加载类,而是把这个请求委派给它上一层的父加载器,每层都如此,所以最终请求会传到启动类加载器,然后从启动类加载器开始尝试加载类,如果加载不到(要加载的类不在当前类加载器的加载范围),就让它的子类尝试加载,每层都是如此。

那么双亲委派模型有什么好处呢?最大的好处就是它让Java中的类跟类加载器一样有了“优先级”。前面说到了对于每一个类,都需要由加载它的加载器和这个类本身共同确立这个类在Java虚拟机中的唯一性,比如java.lang.Object类(存放在JAVA_HOME\lib\rt.jar中),如果用户自己写了一个java.lang.Object类并且由自定义类加载器加载,那么在程序中是不是就是两个类?所以双亲委派模型对保证Java稳定运行至关重要。
深入认识Java中的Thread
每个对象都有一把锁。
线程的6种状态
- 初始(NEW):新创建了一个线程对象,但还没有调用start()方法。
- 运行(RUNNABLE):Java线程中将就绪(ready)和运行中(running)两种状态笼统的称为“运行”。线程对象创建后,其他线程(比如main线程)调用了该对象的start()方法。该状态的线程位于可运行线程池中,等待被线程调度选中,获取CPU的使用权,此时处于就绪状态(ready)。就绪状态的线程在获得CPU时间片后变为运行中状态(running)。
- 阻塞(BLOCKED):表示线程阻塞于锁。
- 等待(WAITING):进入该状态的线程需要等待其他线程做出一些特定动作(通知或中断)。
- 超时等待(TIMED_WAITING):该状态不同于WAITING,它可以在指定的时间后自行返回。
- 终止(TERMINATED):表示该线程已经执行完毕。
线程的几个常见方法的比较
- Thread.sleep(long millis):一定是当前线程调用此方法,当前线程进入
TIMED_WAITING状态,但不释放对象锁,millis后线程自动苏醒进入就绪状态。作用:给其它线程执行机会的最佳方式。 - Thread.yield():一定是当前线程调用此方法,当前线程放弃获取的CPU时间片,但不释放锁资源,由运行状态变为就绪状态,让
OS再次选择线程。作用:让相同优先级的线程轮流执行,但并不保证一定会轮流执行。实际中无法保证yield()达到让步目的,因为让步的线程还有可能被线程调度程序再次选中。Thread.yield()不会导致阻塞。该方法与sleep()类似,只是不能由用户指定暂停多长时间。 - thread.join()/thread.join(long millis):当前线程里调用其它线程
thread的join方法,当前线程进入WAITING/TIMED_WAITING状态,当前线程不会释放已经持有的对象锁。线程thread执行完毕或者millis时间到,当前线程进入就绪状态。 - thread.interrupt():当前线程里调用其它线程
thread的interrupt()方法,中断指定的线程。
如果指定线程调用了wait()方法组或者join方法组在阻塞状态,那么指定线程会抛出InterruptedException - Thread.interrupted:一定是当前线程调用此方法,检查当前线程是否被设置了中断,该方法会重置当前线程的中断标志,返回当前线程是否被设置了中断。
- thread.isInterrupted():当前线程里调用其它线程
thread的isInterrupted()方法,返回指定线程是否被中断 - object.wait():当前线程调用对象的
wait()方法,当前线程释放对象锁,进入等待队列。依靠notify()/notifyAll()唤醒或者wait(long timeout) timeout时间到自动唤醒。 - object.notify():唤醒在此对象监视器上等待的单个线程,选择是任意性的。
notifyAll()唤醒在此对象监视器上等待的所有线程。
volatile
当一个共享变量被volatile修饰之后, 其就具备了两个含义
- 线程修改了变量的值时, 变量的新值对其他线程是立即可见的。 换句话说, 就是不同线程对这个变量进行操作时具有可见性。即该关键字保证了可见性
- 禁止使用指令重排序。这里提到了重排序, 那么什么是重排序呢? 重排序通常是编译器或运行时环境为了优化程序性能而采取的对指令进行重新排序执行的一种手段。
volatile关键字禁止指令重排序有两个含
义: 一个是当程序执行到volatile变量的操作时, 在其前面的操作已经全部执行完毕, 并且结果会对后面的操作可见, 在其后面的操作还没有进行; 在进行指令优化时, 在volatile变量之前的语句不能在volatile变量后面执行; 同样, 在volatile变量之后的语句也不能在volatile变量前面执行。即该关键字保证了时序性。
重入锁ReentrantLock
ReentrantLock reentrantLock = new ReentrantLock();
public void m() {
reentrantLock .lock();//1
reentrantLock .lock();//2
try {
// ... method body
} finally {
reentrantLock .unlock()
reentrantLock .unlock()
}
}
如果锁是不可以重入的,如上图,1获得了锁,2想要获得锁必须要1释放锁,但是1需要等到2执行完才释放锁,就陷入了锁死状态。重入锁概念如此,锁了多少次就要解锁所少次,不然这个锁不会释放。
重入锁synchronized
任意一个Java对象,都拥有一组监视器方法(定义在java.lang.Object上),主要包括wait()、wait(long timeout)、notify()以及notifyAll()方法,这些方法与synchronized同步关键字配合,可以实现等待/通知模式。
synchronized(obj){
.... //1
obj.wait();//2
//obj.wait(long millis);//2
....//3
}
一个线程获得obj的锁,做了一些时候事情之后,发现需要等待某些条件的发生,调用obj.wait(),该线程会释放obj的锁,并阻塞在上述的代码2处。
synchronized(obj){
.... //1
obj.notify();//2
obj.notifyAll();//2
}
一个线程获得obj的锁,做了一些时候事情之后,某些条件已经满足,调用obj.notify()或者obj.notifyAll(),该线程会释放obj的锁,并叫醒在obj上等待的线程。
Synchronized与Lock的区别
| 类别 | 存在层次 | 锁的释放 | 锁的获取 | 锁状态 | 锁类型 | 性能 |
|---|---|---|---|---|---|---|
| synchronized | Java的关键字,在jvm层面上 | 1、以获取锁的线程执行完同步代码,释放锁 2、线程执行发生异常,jvm会让线程释放锁 | 假设A线程获得锁,B线程等待。如果A线程阻塞,B线程会一直等待 | 无法判断 | 可重入 不可中断 非公平 | 少量同步 |
| Lock | 是一个接口 | 在finally中必须释放锁,不然容易造成线程死锁 | 分情况而定,Lock有多个锁获取的方式,大致就是可以尝试获得锁,线程可以不用一直等待(可以通过tryLock判断有没有锁) | 可以判断 | 可重入 可判断 可公平(两者皆可) | 大量同步。Lock可以提高多个线程进行读操作的效率。(可以通过readwritelock实现读写分离)在资源竞争不是很激烈的情况下,Synchronized的性能要优于ReetrantLock,但是在资源竞争很激烈的情况下,Synchronized的性能会下降几十倍,但是ReetrantLock的性能能维持常态;ReentrantLock提供了多样化的同步,比如有时间限制的同步,可以被Interrupt的同步(synchronized的同步是不能Interrupt的)等。在资源竞争不激烈的情形下,性能稍微比synchronized差点点。但是当同步非常激烈的时候,synchronized的性能一下子能下降好几十倍。而ReentrantLock确还能维持常态。 |
什么是ORM
对象关系映射(Object Relational Mapping,简称ORM)是通过使用描述对象和数据库之间映射的元数据,将面向对象语言程序中的对象自动持久化到关系数据库中。本质上就是将数据从一种形式转换到另外一种形式。
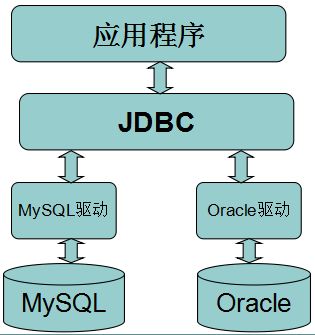
什么是JDBC
JDBC(Java Data Base Connectivity,java数据库连接)是一种用于执行SQL语句的Java API,可以为多种关系数据库提供统一访问,它由一组用Java语言编写的类和接口组成。JDBC提供了一种基准,据此可以构建更高级的工具和接口,使数据库开发人员能够编写数据库应用程序。
Android Jetpack
https://developer.android.google.cn/jetpack
Lifecycle
Lifecycle 是一个类,它持有关于组件(如 Activity 或 Fragment)生命周期状态的信息,并且允许其他对象观察此状态。释放onCreate() 和 onDestroy()等生命周期,简化View层的逻辑。
public interface IPresenter extends LifecycleObserver {
@OnLifecycleEvent(Lifecycle.Event.ON_CREATE)
void onCreate(@NotNull LifecycleOwner owner);
@OnLifecycleEvent(Lifecycle.Event.ON_DESTROY)
void onDestroy(@NotNull LifecycleOwner owner);
@OnLifecycleEvent(Lifecycle.Event.ON_ANY)
void onLifecycleChanged(@NotNull LifecycleOwner owner,@NotNull Lifecycle.Event event);
}
public class BasePresenter implements IPresenter {
@Override
public void onLifecycleChanged(@NotNull LifecycleOwner owner, @NotNull Lifecycle.Event event) {}
@Override
public void onCreate(@NotNull LifecycleOwner owner) {}
@Override
public void onDestroy(@NotNull LifecycleOwner owner) {}
}
这里我直接将我想要观察到Presenter的生命周期事件都列了出来,然后封装到BasePresenter 中,这样每一个BasePresenter 的子类都能感知到Activity容器对应的生命周期事件,并在子类重写的方法中,对应相应行为。
public class MainActivity extends AppCompatActivity {
private IPresenter mPresenter;
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
mPresenter = new MainPresenter(this);
getLifecycle().addObserver(mPresenter);//添加LifecycleObserver
}
@Override
protected void onDestroy() {
super.onDestroy();
}
}
除onCreate和onDestroy事件之外,Lifecycle一共提供了所有的生命周期事件,只要 通过注解进行声明,就能够使LifecycleObserver观察到对应的生命周期事件。
如何处理JNI层的异常
反射Java层的异常抛出以及捕获系统信号量
APP在线实时性能监控方案
除了下面提到的常规方案,还有字节码插桩的方案:在应用构建期间,通过修改字节码的方式来进行字节码插桩就是实现自动化的方案之一。我们想要对字节码进行修改,只需要在
javac之后dex之前遍历所有的字节码文件,并按照一定的规则过滤修改就好了,这里便是字节码插桩的入口。transform api作为字节码插桩的入口。我们只需要实现一个自定义的Gradle Plugin,然后在编译阶段去修改字节码文件。对于字节码的修改,比较常用的框架有Javassist和ASM。
一般从几下几个方面监控应用的性能:
- CPU:如果长时间的使用CPU,会极大的消耗电量,手机也会发热,影响用户体验。一般是程序 中有BUG或是写的代码性能很差,需要优化。
- 内存:内存使用过大容易被系统杀掉,也容易出现OOM而使应用崩溃,一般是程序中出现了内存泄漏,或者没有对内存做过优化。
- 帧率FPS:如果帧率小于60帧每秒,就会造成应用卡顿,也是影响用户体验的。一般是由于过渡绘制造成的,需要对绘制的代码进行优化。
CPU的使用率
Android中可以获取CPU总的使用时间,每个进程所用CPU时间以及进程中每个线程的CPU使用时间,它没有提供API接口,可以直接在应用中读取/proc/stat,/proc/pid/stat,/proc/pid/task/tid/stat这几个文件来获取,不需要root权限。一些开源的性能统计工具也是通过这种方法来显示CPU使用率的,比如网易的Emmagee。
1、获取CPU总使用率
在proc/stat中有详细的CPU使用情况,详细格式如下:
CPU 16394633 4701297 9484146 36314562 70851 1797 202347 0 0 0
CPU后面的几位数字分别是
- user:从系统启动开始累计到当前时刻,处于用户态的运行时间,不包含
nice值为负进程。 - nice:从系统启动开始累计到当前时刻,
nice值为负的进程所占用的CPU时间。 - system:从系统启动开始累计到当前时刻,处于核心态的运行时间。
- idle:从系统启动开始累计到当前时刻,除IO等待时间以外的其它等待时间。
- iowait:从系统启动开始累计到当前时刻,IO等待时间。
- irq:从系统启动开始累计到当前时刻,硬中断时间。
- softirq:从系统启动开始累计到当前时刻,软中断时间。
在某个时间T1的CPU总时间为:
totalCpuTime1 = user1 + nice1 + system1 + idle1 + iowait1 + irq1 + softirq1
在时间T2的CPU总时间为(T2 > T1):
totalCpuTime2 = user2 + nice2 + system2 + idle2 + iowait2 + irq2 + softirq2
CPU总使用率的算法是:
100*((totalCpuTime2-totalCpuTime1) - (idel2-idel1)) / (totalCpuTime2-totalCpuTime1)
2、获取进程的CPU使用率
/proc/pid/stat中则是该pid进程的CPU使用情况.详细格式如下:
2757 (zenmen.palmchat) S 549 549 0 0 -1 1077952832 1674191 173040 7885 4062265 19589 99 49412
其中粗体的四位数字分别是:
- utime:该任务在用户运行状态的时间
- stime:该任务在核心运行的时间
- cutime:所有已死线程在用户状态运行状态的时间
- cstime:所有已死线程在核心的运行时间
所以进程的CPU使用时间processCpuTime为这个四个属性的和.
//在T1时
processCpuTime1 = utime1 + stime1 + cutime1 + cstime1
//在T2时
processCpuTime2 = utime2 + stime2 + cutime2 + cstime2
所以进程所占CPU的使用率算法是:
100*(processCpuTime2-processCpuTime1) / (totalCpuTime2-totalCpuTime1)
3、获取进程中线程的CPU使用率
/proc/pid/task/tid/stat中是该pid进程中tid线程的CPU使用情况,格式和进程CPU使用的格式是一样的,
3810 (fileDecodingQue) S 549 549 0 0 -1 1077952576 269 173040 0 40 0 0 99 494 20 0
线程的CPU时间为:
threadCpuTime = utime + stime
线程的CPU使用率算法是:
100*(threadCpuTime2-threadCpuTime1) / (totalCpuTime2-totalCpuTime1)
内存使用
Android提供有API可以获取系统总内存大小及当前可用内存大小,以及获取应用中内存的使用情况。
1、获取系统总内存大小及可用内存大小
ActivityManager.MemoryInfo有以下几个Field:
- totalMem:表示总内存大小。
- availMem:表示系统剩余内存。
ActivityManager activityManager = (ActivityManager) getSystemService(Context.ACTIVITY_SERVICE);
ActivityManager.MemoryInfo memoryInfo0 = new ActivityManager.MemoryInfo();
activityManager.getMemoryInfo(memoryInfo0);
Log.v("yhd-","availMem:"+memoryInfo0.availMem/(1024*1024));//MB
Log.v("yhd-","totalMem:"+memoryInfo0.totalMem/(1024*1024));//MB
2、获取应用使用的内存大小
Debug.MemoryInfo memoryInfo = new Debug.MemoryInfo();
Debug.getMemoryInfo(memoryInfo);
int totalPss = memoryInfo.getTotalPss();//返回的是KB
监控帧率FPS
Android系统从4.1(API 16)开始加入Choreographer这个类来控制同步处理输入(Input)、动画(Animation)、绘制(Draw)三个操作。其实UI显示的时候每一帧要完成的事情只有这三种。Choreographer接收显示系统的时间脉冲(垂直同步信号-VSync信号),在下一个帧渲染时控制执行这些操作。收到VSync信号后,顺序执行3个操作,然后等待下一个信号,再次顺序执行3个操作。假设在第二个信号到来之前,所有的操作都执行完成了,即Draw操作完成了,那么第二个信号来到时,此时界面将会更新为第一帧的内容,因为Draw操作已经完成了。否则界面将不会更新,还是现实上一个帧的内容,表示丢帧了。丢帧是造成卡顿的原因。
通过 Choreographer 类设置它的 FrameCallback,可以在每一帧被渲染的时候记录下它开始渲染的时间,每一次同步的周期为16ms,代表一帧的刷新频率,一次界面渲染会回调 FrameCallback的doFrame(longframeTimeNanos)方法,如果两次 doFrame 之间的间隔大于16ms说明丢帧了。用这种方法,可以实时监控应用的丢帧情况。
Choreographer.getInstance().postFrameCallback(new Choreographer.FrameCallback() {
@Override
public void doFrame(long frameTimeNanos) {
//Log.e("yhd-","frameTimeNanos:"+frameTimeNanos);
if (mLastFrameNanoTime != 0) {//mLastFrameNanoTime 上一次绘制的时间
long frameInterval = (frameTimeNanos - mLastFrameNanoTime)/1000000;//计算两帧的时间间隔ms
//如果时间间隔大于最小时间间隔,3*16.6ms,小于最大的时间间隔,60*16.6ms,就认为是掉帧,累加统计该时间。
//此处解释一下原因: 因为正常情况下,两帧的间隔都是在16.6ms以内 ,如果我们统计到的两帧间隔时间大于三倍的普通绘制时间,我们就认为是出现了卡顿。
//之所以设置最大时间间隔,是为了有时候页面不刷新绘制的时候,不做统计处理
if (frameInterval > (16.6*3) && frameInterval < 16.6*60) {
//做统计
Log.e("yhd-","frameInterval:"+frameInterval);
}
}
mLastFrameNanoTime = frameTimeNanos;
//注册下一帧回调
Choreographer.getInstance().postFrameCallback(this);
}
});
监控日志上传
- CPU:可以每隔一段时间去获取
APP进程CPU时间,也可以针对一些场景手动获取。可以设定一个阈值,比如大于50%的时候,将各个线程名及线程占用的CPU时间一起保存到日志中。 - 内存:在加载图片、视频、声音等这些比较耗费内存的资源的时候去获取一次应用内存占用及系统剩余内存保存到日志中。
- 帧率FPS:可以在程序中实时监控的,可以在
Activity start时开始监控,当检测到丢帧时保存丢帆的个数,在Activity stop时停止监控,取最大的丢帧个数,再将Activity类名一起保存到日志中。
Socket
下面以一个Socket客服聊天系统协议实例说明

我们的客户端在读取服务器发来的数据时,可以通过以下方式阻塞:
InputStream in = null;
try {
//TCP套接字默认情况下是阻塞模式,也是最常用的,当然你也可以更改为非阻塞模式。
in = socket.getInputStream();
//in.read阻塞读,每个Socket被创建后,都会分配两个8192字节的8k缓冲区,输入缓冲区和输出缓冲区。
//write()/send()并不立即向网络中传输数据,而是先将数据写入缓冲区中,再由TCP协议将数据从缓冲区发送到目标机器。
while (true) {
final int MLEN = 1024;
byte[] buff = new byte[MLEN];
//in.read()目前最大支持2048字节;这一方法的功能是从字节流中读取一个字节,若到了末尾则返回-1,否则返回读入的字节。
int size = in.read(buff);
//socket在发送方过快等情况下,会存在粘包情况,也就是一次读取中读出来了不止一个包。或者在发送包太大的情况下会存在分包的情况,需要做特殊处理。
//socket有个默认的超时断开时间(默认是60s),如果在设置的时间内一直没有数据传输,就会自动断开连接。所以要维持心跳,心跳的时间少于Socket内核超时断开连接时间。当然也可以把Socket可设为keepalive用不超时断开,但是官方不建议这么干。
}
} catch (SocketException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
缓冲区
我们知道,CPU与内存发生的读写速度比硬件IO快10倍不止。为了提高速度,Socket内核在内存中建立两个8k输入输出缓冲区缓存区,write()/send() 并不立即向网络中传输数据,而是先将数据写入缓冲区中,再由TCP协议将数据从缓冲区发送到目标机器。一旦将数据写入到缓冲区,函数就可以成功返回,不管它们有没有到达目标机器,也不管它们何时被发送到网络,这些都是TCP协议负责的事情。当然你可以调用flush()将数据立刻发送出去(InputStream的flush是空函数,子类才实现具体的方法)。TCP协议独立于 write()/send() 函数,数据有可能刚被写入缓冲区就发送到网络,也可能在缓冲区中不断积压,多次写入的数据被一次性发送到网络,这取决于当时的网络情况、当前线程是否空闲等诸多因素,不由程序员控制。read()/recv() 函数也是如此,也从输入缓冲区中读取数据,而不是直接从网络中读取。所以会存在粘包的现象,在发送数据过大的情况下也会存在分包的情况,都要处理好。我们用InputStream.read()读包时,目前协议每次最大能读到2048字节,读取成功返回读取到的字节数,socket关闭返回-1。
分包
当发送的字节数据包比较大时,Socket内部会将发送的字节数据进行分包处理,降低内存和性能的消耗。一个包没有固定长度,以太网限制在46-1500字节,1500就是以太网的MTU,超过这个量,TCP会为IP数据报设置偏移量进行分片传输。在分包产生时,要保留上一个包的部分内容,与下一个包的部分内容组合。
粘包
当发送的字节数据包比较小且频繁发送时,Socket内部会将字节数据进行粘包处理,既将频繁发送的小字节数据打包成 一个整包进行发送,降低内存的消耗。在粘包产生时,要可以在同一个包内获取出多个包的内容。
心跳
Socket有个默认的超时断开时间(默认是60s),如果在设置的时间内一直没有数据传输,就会自动断开连接。现实场景我们并不想要这么快断开,所以要维持心跳(向Socket发送任何数据维持),心跳的时间少于Socket内核超时断开连接时间。当然也可以把Socket可设为keepalive永不超时断开,但是官方不建议这么干。
Java流体系图
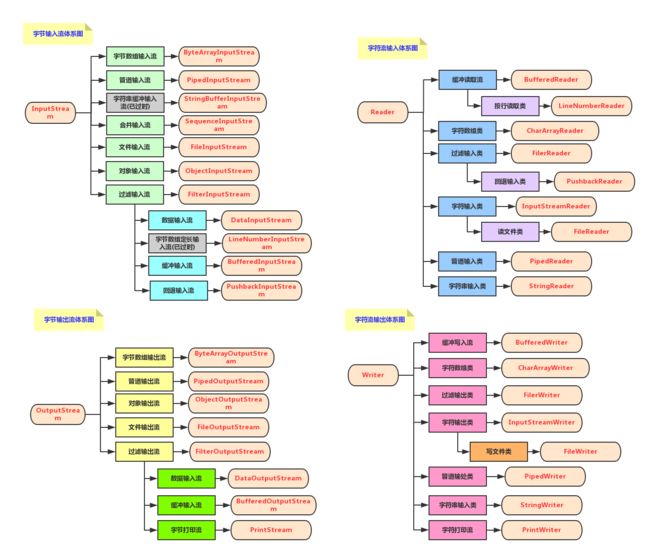
字节流
Java中的字节流处理的最基本单位为单个字节,它通常用来处理二进制数据。Java中最基本的两个字节流类是InputStream和OutputStream,它们分别代表了组基本的输入字节流和输出字节流。InputStream类与OutputStream类均为抽象类,我们在实际使用中通常使用Java类库中提供的它们的一系列子类。InputStream.read()是一个抽象方法,也就是说任何派生自InputStream的输入字节流类都需要实现这一方法,这一方法的功能是从字节流中读取一个字节,若到了末尾则返回-1,否则返回读入的字节。关于这个方法我们需要注意的是,它会一直阻塞直到返回一个读取到的字节或是-1。另外,字节流在默认情况下是不支持缓存的,这意味着每调用一次read方法都会请求操作系统来读取一个字节,这往往会伴随着一次磁盘IO,因此效率会比较低。要使用内存缓冲区以提高读取的效率,我们应该使用BufferedInputStream。
BufferedInputStream内部有一个缓冲区,默认大小为8M,每次调用read方法的时候,它首先尝试从缓冲区里读取数据,若读取失败(缓冲区无可读数据),则选择从物理数据源 (譬如文件)读取新数据(这里会尝试尽可能读取多的字节)放入到缓冲区中,最后再将缓冲区中的内容返回给用户.由于从缓冲区里读取数据远比直接从存储介质读取速度快,所以BufferedInputStream的效率很高。
字符流
Java中的字符流处理的最基本的单元是Unicode码元(大小2字节),它通常用来处理文本数据。所谓Unicode码元,也就是一个Unicode代码单元,范围是0x0000~0xFFFF。在以上范围内的每个数字都与一个字符相对应,Java中的String类型默认就把字符以Unicode规则编码而后存储在内存中。然而与存储在内存中不同,存储在磁盘上的数据通常有着各种各样的编码方式。使用不同的编码方式,相同的字符会有不同的二进制表示。实际上字符流是这样工作的:
- 输出字符流:把要写入文件的字符序列(实际上是
Unicode码元序列)转为指定编码方式下的字节序列,然后再写入到文件中; - 输入字符流:把要读取的字节序列按指定编码方式解码为相应字符序列(实际上是
Unicode码元序列从)从而可以存在内存中。
由于字符流在输出前实际上是要完成Unicode码元序列到相应编码方式的字节序列的转换,所以它会使用内存缓冲区来存放转换后得到的字节序列,等待都转换完毕再一同写入磁盘文件中。
区别
为什么要使用字符流?
因为使用字节流操作汉字或特殊符号语言的时候容易乱码,因为汉字不止一个字节,为了解决这个问题,建议使用字符流。
什么情况下使用字符流?
一般可以用记事本打开的文件,我们可以看到内容不乱码的。就是文本文件,可以使用字符流。而操作二进制文件(比如图片、音频、视频)必须使用字节流。
主要使用的设计模式
处理流(包装流):并不直接连接数据源,是对一个已存在的流的连接和封装,是一种典型的装饰器设计模式,使用处理流主要是为了更方便的执行输入输出工作,如PrintStream,输出功能很强大,又如BufferedReader提供缓存机制,推荐输出时都使用处理流包装。
OTA升级流程
OTA升级分为差分包升级和整包升级,不管是哪种都需要在源码中利用系统签名生成升级整包,差分包的话需要用命令生成带签名的差异部分。在用户升级判断中,需要先判断系统签名的正确性,然后写入临时标记升级包信息的文件,然后发送reboot(“recovery”)命令(可选择是否擦除用户数据),重启进入recovery模式,读取临时标记升级包信息的文件进行写入升级。
完整升级流程
public static void installPackage(Context context, File packageFile)throws IOException {
//第一步验证签名
verifyPackage(packageFile,null,null);
String filePath = packageFile.getCanonicalPath();
String arg = "--update_package=" + filePath;
//第二部写入包信息临时标记文件
writeFlagCommand(filePath);
//第三部重启进入recovery升级
bootCommand(context, arg);
}
验证签名
/**
* Verify the cryptographic signature of a system update package
* before installing it. Note that the package is also verified
* separately by the installer once the device is rebooted into
* the recovery system. This function will return only if the
* package was successfully verified; otherwise it will throw an
* exception.
*
* Verification of a package can take significant time, so this
* function should not be called from a UI thread. Interrupting
* the thread while this function is in progress will result in a
* SecurityException being thrown (and the thread's interrupt flag
* will be cleared).
*
* @param packageFile the package to be verified
* @param listener an object to receive periodic progress
* updates as verification proceeds. May be null.
* @param deviceCertsZipFile the zip file of certificates whose
* public keys we will accept. Verification succeeds if the
* package is signed by the private key corresponding to any
* public key in this file. May be null to use the system default
* file (currently "/system/etc/security/otacerts.zip").
*
* @throws IOException if there were any errors reading the
* package or certs files.
* @throws GeneralSecurityException if verification failed
*/
public static void verifyPackage(File packageFile,ProgressListener listener,File deviceCertsZipFile)
throws IOException, GeneralSecurityException {
//deviceCertsZipFile实际场景传null
}
写入临时标记升级包信息的文件
/**
* Used to communicate with recovery. See bootable/recovery/recovery.c
*
* @param path the package path
*/
public static void writeFlagCommand(String path) throws IOException{
File UPDATE_FLAG_FILE = new File("/cache/recovery","last_flag");
FileWriter writer = new FileWriter(UPDATE_FLAG_FILE);
try {
writer.write("updating$path=" + path);
}finally {
writer.close();
}
}
重启进入recovery
/**
* Reboot into the recovery system with the supplied argument.
* @param arg to pass to the recovery utility.
* @throws IOException if something goes wrong.
*/
private static void bootCommand(Context context, String arg) throws IOException {
File COMMAND_FILE = new File("/cache/recovery", "command");
FileWriter command = new FileWriter(COMMAND_FILE);
try {
command.write(arg);
command.write("\n");
} finally {
command.close();
}
// Having written the command file, go ahead and reboot
PowerManager pm = (PowerManager) context.getSystemService(Context.POWER_SERVICE);
pm.reboot("recovery");
throw new IOException("Reboot failed (no permissions?)");
}
擦除用户数据后重启
/**
* Reboots the device and wipes the user data partition. This is
* sometimes called a "factory reset", which is something of a
* misnomer because the system partition is not restored to its
* factory state.
* Requires the {@link android.Manifest.permission#REBOOT} permission.
*
* @param context the Context to use
*
* @throws IOException if writing the recovery command file
* fails, or if the reboot itself fails.
*/
public static void rebootWipeUserData(Context context) throws IOException {
final ConditionVariable condition = new ConditionVariable();
Intent intent = new Intent("android.intent.action.MASTER_CLEAR_NOTIFICATION");
context.sendOrderedBroadcast(intent, android.Manifest.permission.MASTER_CLEAR,
new BroadcastReceiver() {
@Override
public void onReceive(Context context, Intent intent) {
condition.open();
}
}, null, 0, null, null);
// Block until the ordered broadcast has completed.
condition.block();
//重启进入recovery模式,下面讲
bootCommand(context, "--wipe_data");
}
开机logo、文字、动画的制作原理
-
开机logo
//1 、下载图片转换工具 sudo apt-get install pnmtoplainpm //2、png转pnm pngtopnm logo.png > logo_linux.pnm //3、转化成224的pnm图片 pnmquant 224 logo_linux.pnm > logo_linux_clut224_formal.pnm //4、转换成ppm格式 pnmtoplainpnm logo_linux_clut224_formal.pnm > logo_linux_clut224.ppm //5、替换 /kernel/drivers/video/logo/logo_linux_clut224.ppm是默认的启动Logo图片,把自己的ogo_linux_clut224.ppm替换这个文件,同时删除logo_linux_clut224.c logo_linux_clut224.o文件(如果存在) 。 //6、编译kernel make kernel.img -
开机文字
system/core/init/init.c,如下代码片段,直接修改即可if( load_565rle_image(INIT_IMAGE_FILE) ) { fd = open("/dev/tty0", O_WRONLY); if (fd >= 0) { const char *msg; msg = "\n" "\n" " A N D R O I D "; write(fd, msg, strlen(msg)); close(fd); } } : -
开机动画
动画文件(bootanimation.zip)包含三个内容:两个目录part0和part1,一个文件desc.txt。两个目录用来包含要显示的图片,分为第一阶段和第二阶段。剩下的文件就是设置关于如何显示的信息:480 800 15 p 1 0 part0 p 0 0 part1具体的含义如下:
480--图片的宽, 800--图片的高, 15--每一秒切换多少侦 p 1, 只循环一次 p 0, 无限循环直到系统开机打包的方法:
zip -0 bootanimation.zip part0/*png part1/*png desc.txt将
bootanimation.zip拷贝到自定义media目录下,修改自己的makefile文件,添加以下类似代码:PRODUCT_COPY_FILES += \$(call find-copy-subdir-files,*,$(LOCAL_PATH)/media,system/media)
热修复

热修复技术可谓是百花齐放,阿里的Sophix、微信的Tinker、饿了么的Amigo、美团的Robust等等,下面以三个代表性作为对比。他们都支持兼容全部Android版本、加密传输及签名校验、支持服务端控制等。
| 方案对比 | Sophix | Tinker | Amigo |
|---|---|---|---|
| DEX修复 | 即时生效和冷启动修复 | 冷启动修复 | 冷启动修复 |
| 资源更新 | 差量包,不用合成 | 差量包,需要合成整包 | 全量包,不用合成 |
| SO库更新 | 插桩实现,开发透明 | 替换so路径,开发不透明 | 插桩实现,开发透明 |
| 性能损耗 | 低,仅冷启动情况下有些损耗 | 高,有合成操作 | 低,全量替换 |
| 四大组件 | 不能新增 | 不能新增 | 能新增 |
| 生成补丁 | 直接选择已经编好的新旧包在本地生成 | 编译新包时设置基线包 | 上传完整新包到服务端 |
| 补丁大小 | 小 | 小 | 大 |
| 接入成本 | 傻瓜式接入 | 复杂 | 一般 |
| 是否收费 | 是 | 否 | 否 |
四大组件可以修改代码,但是无法做到新增。这是因为如果要新增四大组件,必须在
AndroidManifest里面预先插入代理组件,并且尽可能声明所有权限,而这么做就会给原先的app添加很多臃肿的代码,对app运行流程的侵入性很强,所以,本着对开发者透明与代码极简的原则,没有做这种多余的处理。冷启动方式,指的是需要重启app在下次启动时才能生效。
Dex热更新
Tinker方案
-
1、生成补丁流程
判断新旧文件的MD5是否相等,不相等,说明有变化,自研DexDiff差异算法,最后生成dex文件的差异包,生成的文件以dex结尾,但需要注意的是,它不是真正的dex文件,只是个补丁包。其中新增的四大组件以及修改loader相关的类是不允许的。 -
2、补丁包下发成功后合成全量Dex流程
当app收到服务器下发的补丁后,首先检查补丁的合法性、签名、是否安装过补丁,检查通过后会针对old dex和patch dex进行合并,生成全量dex文件,最终合成的文件会放到/data/data/${package_name}/tinker目录下。 -
3、生成全量Dex后的加载流程
一个
ClassLoader可以包含多个dex文件,每个dex文件是一个Element,多个dex文件排列成一个有序的数组dexElements,当找类的时候,会按顺序遍历dex文件,然后从当前遍历的dex文件中找类,如果找类则返回,如果找不到从下一个dex文件继续查找。在
TinkerApplication中的onBaseContextAttached中会通过反射调用TinkerLoader的tryLoad加载已经合成的dex。先获取BaseDexClassLoader的dexPathList对象,然后通过dexPathList的makeDexElements函数将我们要安装的dex转化成Element[]对象,最后将其和dexPathList的dexElements对象进行合并,就是新的Element[]对象,因为我们添加的dex都被放在dexElements数组的最前面,所以当通过findClass来查找这个类时,就是使用的我们最新的dex里面的类。
Sophix方案
Dalvik下采用阿里自研的全量dex方案:不是考虑把补丁包的dex插到所有dex前面(dex插桩),而是想办法在原理的dex中删除(只是删除了类的定义)补丁dex中存在的类,这样让系统查找类的时候在原来的dex中找不到,那么只有补丁中的dex加载到系统中,系统自然就会从补丁包中找到对应的类。Art下本质上虚拟机以及支持多dex的加载,Sophix的做法仅仅是把补丁dex作为主dex(classes.dex)而已,相当于重新组织了所有的dex文件顺序:把补丁包的dex改名为classes.dex,以前apk的所有dex依次改为classes2.dex、classes3.dex…classesx.dex。
资源热更新
Tinker方案
常用方案(Instant Run技术):这种方案的兼容问题在于替换AssetManager的地方。
-
1、资源补丁生成
ResDiffDecoder.patch(File oldFile, File newFile)主要负责资源文件补丁的生成。如果是新增的资源,直接将资源文件拷贝到目标目录。如果是修改的资源文件则使用dealWithModeFile函数处理。dealWithModeFile会对文件大小进行判断,如果大于设定值(默认100Kb),采用bsdiff算法对新旧文件比较生成补丁包,从而降低补丁包的大小。如果小于设定值,则直接将该文件加入修改列表,并直接将该文件拷贝到目标目录,生成资源文件的补丁包。 -
2、补丁下发成功后资源补丁的合成
合成过程比较简单,没有使用bsdiff生成的文件直接写入到resources.apk文件;使用bsdiff生成的文件则采用bspatch算法合成资源文件,然后将合成文件写入resouces.apk文件(是不是讲原始资源和补丁资源合成整个资源包还待验证)。最后,生成的resouces.apk文件会存放到/data/data/${package_name}/tinker/res对应的目录下。 -
3、资源补丁加载
资源补丁的加载的操作主要放在TinkerResourceLoader.loadTinkerResources函数中,同dex的加载时机一样,在app启动时会被调用。我们获取资源的时候会调用getResource(),Resources对象的内部AssetManager对象包含了framework的资源还包含了应用程序本身的资源,因此这也就是为什么能使用getResources函数获得的resources对象来访问系统资源和本应用资源的原因。受此过程的提醒,我们是不是可以自己创建一个Resources对象,让它的包含我们指定路径的资源,就可以实现访问其他的资源了呢?答案是肯定的,利用这个思想可以实现资源的动态加载,换肤、换主题等功能都可以利用这种方法实现。主要思想就是创建一个
AssetManager对象,利用addAssetPath函数添加指定的路径(addAssetPath函数是hide的,可以使用反射调用),用其创建一个Resources对象,使用该Resources对象获取该路径下的资源。//path = getPackageManager().getApplicationInfo("xxx", 0).sourceDir; public void loadRes(String path){ try { assetManager = AssetManager.class.newInstance(); Method addAssetPath = AssetManager.class.getMethod("addAssetPath", String.class); addAssetPath.invoke(assetManager, path); } catch (Exception e) { } //这个resources就是我们最终用的资源文件了 resources = new Resources(assetManager, super.getResources().getDisplayMetrics(), super.getResources().getConfiguration());
Sophix方案
Sophix方案没有直接使用Instant Run的技术,而是另辟蹊径,构造了一个package id为0x66的资源包,这个包里只包含改变了的资源项,然后直接在原有AssetManager中addAssetPath这个包就可以了。由于补丁包的package id为0x66,不与目前已经加载的0x7f冲突,因此直接加入到已有的AssetManager中就可以直接使用了。补丁包里面的资源,只包含原有包里面没有而新的包里面有的新增资源,以及原有内容发生了改变的资源。并且,我们采用了更加优雅的替换方式,直接在原有的AssetManager对象上进行析构和重构,这样所有原先对AssetManager对象的引用是没有发生改变的,所以就不需要像Instant Run那样进行繁琐的修改了。也不需要在运行时合成完整包。不占用运行时计算和内存资源。
so文件热更新
Tinker方案
-
补丁生成
生成补丁时比较新旧so文件使用BSdiff算法生成补丁包, -
补丁合成
然后在下发补丁成功后根据BSpatch算法将补丁包和旧的library合成新的library。并将更新后的Library库文件保存在tinker下面的目录下,这个目录就是/data/data/${package_name}/tinker/lib。 -
补丁加载
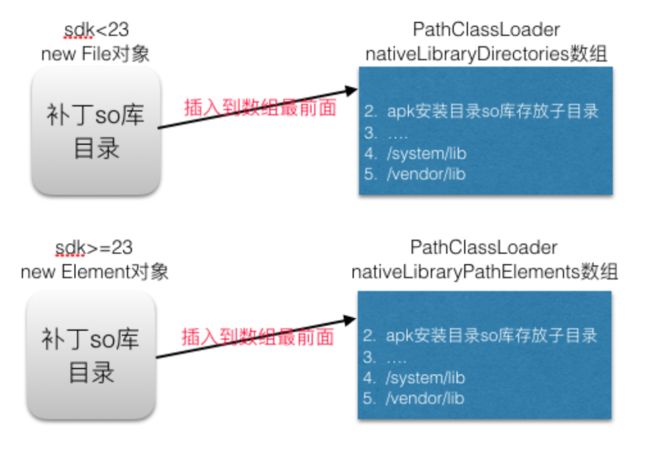
首先讲下Android里面关于so的加载的三种方式:- 方式一:
System.loadLibrary, 这种方式传入的是so的名字,会直接从系统的目录去加载so文件,系统的路径包括/data/data/${package_name}/lib、/system/lib、/vender/lib等这类路径。 - 方式二:
System.load, 这种方式传入的是so的绝对路径,直接从这个路径加载so文件。 - 方式三:通过反射注入方式把补丁
so库的路径插入到nativeLibraryDirectories数组的最前面(nativeLibraryDirectories包括/data/data/${package_name}/lib、/system/lib、/vender/lib的加载顺序),就能够达到加载so库的时候是补丁so库,而不是原来so库的目录。
Tinker的so文件热更新的原理就是通过方式二,直接加载新的so路径实现的。Tinker中so的热更新对用户并不是无感的,需要用户自发的去加载自己需要的库文件。为什么不第三种方式,官方给出解释:但是
Tinker并没有直接将补丁的lib路径添加到DexPathList中,理论上这样可以做到程序完全没有感知的对Library文件作补丁。这里主要是因为在多abi的情况下,某些机器获取的并不准确。所以想要加载最新的库,需要自己使用TinkerInstaller.load*Library去加载库文件,它会自动尝试先去Tinker中的库文件加载,加载不成功会调用System.loadLibrary调用系统的库文件。另外,对于第三方库文件的加载,Tinker无法干预其加载时机,但是只要在我们的代码提前加载第三方的库文件即可。若想对第三方代码的库文件更新,可先使用TinkerInstaller.load*Library对第三方库做提前的加载!当前使用方式似乎并不能做到开发者透明,这是因为Tinker想尽量少的去hook系统框架减少兼容性的问题。//load lib/armeabi library TinkerInstaller.loadArmLibrary(getApplicationContext(), "stlport_shared"); //load lib/armeabi-v7a library TinkerInstaller.loadArmV7Library(getApplicationContext(), "stlport_shared"); - 方式一:
Sophix方案
Sophix采用的是类似类修复反射注入方式。把补丁so库的路径插入到nativeLibraryDirectories数组的最前面,就能够达到加载so库的时候是补丁so库,而不是原来so库的目录,从而达到修复的目的。
反射
在
Java运行时环境中,对于任意一个类,可以知道这个类有哪些属性和方法。对于任意一个对象,可以调用它的任意一个方法。这种动态获取类的信息以及动态调用对象的方法的功能来自于Java语言的反射(Reflection)机制。
package com.yhd.structure.utils;
public class Test {
public static boolean paramStatic = false;//静态成员变量
public boolean paramNormal = false;//成员变量
//这里要注意,如果带有static+final,变量类型是int、long、boolean以及String这些基本类型,
//JAVA在编译的时候为了优化效率就会把代码中对此常量中引用的地方替换成相应常量值,所以反射是无法修改的。
//如果是Integer、Long、Boolean这种包装类型,或者其他诸如Date、Object都是可以反射修改的。
private static final int IN_VALUE = 100;//static+final反射修改
private Test(String name){}
private static class InnerStaticClass {
private void print(String str) {}//静态内部类print带参方法
}
private class InnerNormalClass {
private void print(String str) {}//非静态内部类print带参方法
}
private Runnable runnable = () -> {};//匿名内部类run方法
}
反射的实例:
try {
//1、获取Class对象,每个Class在虚拟机中都是唯一的,可以去掉
Class testClass = Class.forName("com.yhd.structure.utils.Test");//无法引用的时候只能用这种方式
//Class testClass = Test.class;//能够引用的时候可以用这种方式
//2、获取对象
Constructor constructor = testClass.getDeclaredConstructor(String.class);//读取构造函数
constructor.setAccessible(true);//忽略private等修饰符的限制
Object testObject = constructor.newInstance("testName");//通过构造函数获取类
//Object testObject = testClass.newInstance();//直接用默认构造函数,但是不能传递参数,不够灵活
//3、设置读取成员变量
Field normalField = testClass.getDeclaredField("paramNormal");//成员变量
normalField.setAccessible(true);//忽略private等修饰符的限制
normalField.set(testObject,true);//设置属性
boolean paramNormal = (boolean) normalField.get(testObject);//读取成员变量
//4、设置读取静态成员变量
Field staticField = testClass.getDeclaredField("paramStatic");//静态成员变量
staticField.setAccessible(true);//忽略private等修饰符的限制
staticField.set(null,true);//设置静态成员变量
boolean paramStatic = (boolean) staticField.get(null);//读取静态成员变量
//5、设置读取static+final常量
Field staticFinalField = testClass.getDeclaredField("IN_VALUE");//获取Test类的INT_VALUE字段
staticFinalField.setAccessible(true);//忽略private等修饰符的限制
//Field modifiersField = Field.class.getDeclaredField("modifiers");//modifiers属性已经找不到
//modifiersField.setAccessible(true);//忽略private等修饰符的限制
//modifiersField.setInt(staticFinalField, staticFinalField.getModifiers() & ~Modifier.FINAL);//去除final修饰符的影响,将字段设为可修改的
staticFinalField.set(null, 200);//把字段值设为200
//6、读取匿名内部类
Field field = testClass.getDeclaredField("runnable");//内部匿名类
field.setAccessible(true);//忽略private等修饰符的限制
Runnable runnable = (Runnable) field.get(testObject);//执行:
runnable.run();
//7、读取静态内部类
Class innerStaticClass = Class.forName("com.yhd.structure.utils.Test$InnerStaticClass");//直接反射静态内部类
Constructor innerStaticConstructor = innerStaticClass.getDeclaredConstructor();//获取构造函数必须传外部类的Class
innerStaticConstructor.setAccessible(true);
Object innerStaticObject = innerStaticConstructor.newInstance();//获取实例对象必须传外部类的实例
Method innerStaticMethod= innerStaticClass.getDeclaredMethod("print", String.class);
innerStaticMethod.setAccessible(true);//忽略private等修饰符的限制
innerStaticMethod.invoke(innerStaticObject, "I am InnerStaticClass");//直接调用
//8、读取内部类
Class innerNormalClass = Class.forName("com.yhd.structure.utils.Test$InnerNormalClass");//直接反射静态内部类
Constructor innerNormalConstructor = innerNormalClass.getDeclaredConstructor(testClass);//获取构造函数必须传外部类的Class,编译阶段决定了
innerNormalConstructor.setAccessible(true);
Object innerNormalObject = innerNormalConstructor.newInstance(testObject);//获取实例对象必须传外部类的实例
Method innerNormalMethod = innerNormalClass.getDeclaredMethod("print", String.class);//获取内部方法
innerNormalMethod.setAccessible(true);//忽略private等修饰符的限制
innerNormalMethod.invoke(innerNormalObject, "I am NormalClass");//执行函数
} catch (Exception e) {
e.printStackTrace();
}
优点
反射不仅可以让我们获得隐藏的方法和属性,还可以让对象的实例化从编译时转化为运行时,因为我们可以通过Class.forName("xxx").newInstance()的方法来生成新的实例,我们就可以很大程度上对程序应用中的功能模块进行解耦合。
缺点
- 反射包括了一些动态类型,所以
JVM无法对这些代码进行优化。因此,反射操作的效率要比那些非反射操作低得多。我们应该避免在经常被执行的代码或对性能要求很高的程序中使用反射。 - 使用反射技术要求程序必须在一个没有安全限制的环境中运行。如果一个程序必须在有安全限制的环境中运行,如
Applet,那么这就是个问题了。 - 由于反射允许代码执行一些在正常情况下不被允许的操作(比如访问私有的属性和方法),所以使用反射可能会导致意料之外的副作用:代码有功能上的错误,降低可移植性。反射代码破坏了抽象性,因此当平台发生改变的时候,代码的行为就有可能也随着变化。
- 反射破坏了代码的封装性。
如何提高反射效率
- 尽量不要
getMethods()后再遍历筛选,而直接用getMethod(methodName)来根据方法名获取方法。 - 需要多次动态创建一个类的实例的时候,有缓存的写法会比没有缓存要快很多。
- 使用高性能的反射库,比自己写缓存效果好,如
joor,或者apache的commons相关工具类。 - 使用高版本
JDK也很重要,反射性能一直在提高。
怎么确保网络数据传输安全
使用https是否就万事大吉?对于攻击者来说,你使用http和https是没有区别的。
使用抓包工具时,给目标设备安装并信任装包工具的自签名证书,这时候就可以分析https请求了。https并不能阻挡攻击者分析请求接口并发起攻击,为了增加攻击者分析请求的难度,通常可以采用两种方式:
使用签名。即给你的请求参数添加一个签名,后台服务接收到请求时,先验证签名,签名不正确的话,则不予处理。签名规则五花八门,大致策略就是根据请求参数做一些运算最后生成一个唯一的字符串当做sign,微信支付的签名大家可以做一个参考:https://pay.weixin.qq.com/wiki/doc/api/app/app.php?chapter=4_3数据加密。post到服务器和从服务器返回的数据都做加密,这样的话即使攻击者拿到你的数据,他不知道你的加密算法就无能为力了。下面举例。

通过网络传输数据,需要保证数据的完整性、保密性,以及能够对数据的发送者进行身份验证。这些都需要通过一些加密算法实现,数据的加密方式有:- 对称加密:加密和解密使用同一个密钥,特点:保证了数据的保密性。局限性:无法解决密钥交换问题。常用的算法有:
DES,3DES,AES; - 公钥加密:生成一个密钥对(私钥和公钥),加密时用私钥加密,解密时用公钥解密,特点:解决了密钥交换问题。局限性:对大的数据加密速度慢。
- 私钥加密:公钥和私钥都可以用于加解密操作,用公钥加密的数据只能由对应的私钥解密,反之亦然。私钥用于签名、公钥用于验签。签名和加密作用不同,签名并不是为了保密,而是为了保证这个签名是由特定的某个人签名的,而不是被其它人伪造的签名,所以私钥的私有性就适合用在签名用途上。私钥签名后,只能由对应的公钥解密,公钥又是公开的(很多人可持有),所以这些人拿着公钥来解密,解密成功后就能判断出是持有私钥的人做的签名,验证了身份合法性。
- 单向加密:提取数据的特征码,特点:定长输出,不可逆,可检验数据的完整性。局限性:无法保证数据的保密性。常用算法:
MD5、SHA1、CRC-32。
四种加密方法各有优缺点,在时实际应用中,数据从发送方到达接收方,通常是这样应用的:
- 首先对要发送的数据做单向加密,获取数据的特征码;
- 对特征码用发送方的私钥进行加密生成
S1; - 然后对
S1和数据进行对称加密生成S2; - 最后将
S2和对称加密的密码使用接收方的公钥进行加密。
这样一来数据在传输过程中的完整性、保密性以及对发送方身份的验证都能得到保障。当数据到达接收方时,接收方先用自己的私钥对接收到的数据进行解密,文库得到密码和加密的数据;使用密码对加密数据解密,得到加密的特征码和数据;用发送方的公钥解密特征码,如果能解密,则说明该数据是由发送方所发;反之则不是,这便实现了身份验证;最后计算数据的特征码和解密出来的特征码做对比,如果一样,则该数据没有被修改;反之则数据被修改过了。
HTTP断点续传
点续传也就是从下载断开的哪里,重新接着下载,直到下载完整/可用。从 HTTP1.1 协议开始就已经支出获取文件的部分内容,断点续传技术就是利用 HTTP1.1 协议的这个特点在 Header 里添加两个参数来实现的。这两个参数分别是客户端请求时发送的 Range 和服务器返回信息时返回的 Content-Range - Range。Range 用于指定第一个字节和最后一个字节的位置,格式如下:
Range:(unit=first byte pos)-[last byte pos]
Range:bytes=0-1024:表示传输的是从开头到第1024字节的内容;Range:bytes=1025-2048:表示传输的是从第1025到2048字节范围的内容;Range:bytes=-2000:表示传输的是最后2000字节的内容;Range:bytes=1024-:表示传输的是从第1024字节开始到文件结束部分的内容;Range:bytes=0-0,-1:表示传输的是第一个和最后一个字节 ;Range:bytes=1024-2048,2049-3096,3097-4096:表示传输的是多个字节范围。
Content-Range 用于响应带有 Range 的请求。服务器会将 Content-Range 添加在响应的头部,格式如下:
Content-Range:bytes(unit first byte pos)-[last byte pos]/[entity length]
比如:Content-Range:bytes 2048-4096/10240,这里边 2048-4096 表示当前发送的数据范围, 10240 表示文件总大小。
状态相关
返回的HTTP状态码意义:
200:是OK(一切正常),206:是Partial Content(服务器已经成功处理了部分内容)。416:Requested Range Not Satisfiable(对方(客户端)发来的Range请求头不合理)。
一般处理单线程处理:
客户端发来请求 ——-> 服务端返回200 ——> 客户端开始接受数据 ——> 用户手多多把下载停止了 ——> 客户端突然停止接受数据 ——> 然后客户端都没说再见就与服务端断开了 ——> 用户手的痒了又按回开始键 ——> 客户端再次与服务端连接上,并发送Range请求头给服务端 ——> 这时服务端返回是206(Range不合理返回416) ——> 服务端从断开的数据那继续发送,并且会发送响应头:Content-Range给客户端 ——>客户端接收数据 ——>直到完成。
校验
这里的校验主要针对断点续传下载来说的。当服务器端的文件发生改变时,客户端再次向服务端发送断点续传请求时,数据肯定就会发生错误。这时我们可以利用 Last-Modified 来标识最后的修改时间,这样就可以判断服务器上的文件是否发生改变。和 Last-Modified 具有同样功能的还有 if-Modified-Since,它俩的不同点是 Last-Modified 由服务器发送给客户端,而 if-Modified-Since 是由客户端发出, if-Modified-Since 将先前服务器发送给客户端的 Last-Modified 发送给服务器,服务器进行最后修改时间验证后,来告知客户端是否需要重新从服务器端获取新内容。客户端判断是否需要更新,只需要判断服务器返回的状态码即可,206 代表不需要重新获取接着下载就行,200代表需要重新获取。
图片三级缓存
Bitmap的创建非常消耗时间和内存,可能导致频繁GC,使用缓存策略能够高效加载Bitmap,减少卡顿,从而减少读取耗时和电量消耗。
Android原生为我们提供了一个LruCache,其中维护着一个LinkedHashMap,用url(可能有特殊字符影响使用)的MD5作为key。LruCache可以用来存储各种类型的数据,但最常见的是存储图片(Bitmap)。LruCache创建时,我们需要设置它的大小,一般是系统最大存储空间的八分之一。LruCache的机制是存储最近、最后使用的图片,如果LruCache中的图片大小超过了其默认大小,则会将最老、最远使用的图片移除出去。
当图片被LruCache移除的时候,我们需要手动将这张图片添加到软引用(SoftReference)中。我们需要在项目中维护一个由SoftReference组成的集合,其中存储被LruCache移除出来的图片。软引用的一个好处是当系统空间紧张的时候,软引用可以随时销毁,因此软引用是不会影响系统运行的,换句话说,如果系统因为某个原因OOM了,那么这个原因肯定不是软引用引起的。
当我们的APP中想要加载某张图片时,先去LruCache中寻找图片,如果LruCache中有,则直接取出来使用,如果LruCache中没有,则去SoftReference中寻找,如果SoftReference中有,则从SoftReference中取出图片使用,同时将图片重新放回到LruCache中,如果SoftReference中也没有图片,则去文件系统中寻找,如果有则取出来使用,同时将图片添加到LruCache中,如果没有,则连接网络从网上下载图片。图片下载完成后,将图片保存到文件系统中,然后放到LruCache中。
React Native页面构建渲染原理
React Native 继承了 React 在 JavaScript 的扩展语法 JSX 中直接以声明式的方式来描述 UI 结构的机制,并实现了一个 CSS 的子集,这把「DOM Representation」的概念外扩成了「UI Representation」,由于不是操作真实 UI,就可以放到非 UI 线程来进行 render——所有做客户端 UI 开发的都应该知道 UI 线程是永远的痛,无论你怎么 render,render 的多低效,这些 render 都不会直接影响 UI,而要借由 React Native 来将改变更新回 UI 线程。由于目前没有任何示例代码,也看不到更细节的实现机制介绍,所以以下部分为猜测。如果 React Native 沿袭 React 的机制,就会同样是把两次 render 的 diff 结果算出来,然后把 diff 结果传递回主线程,在最小范围内更新 UI。
所以,核心是以下三点:
- 在非
UI线程渲染UI Representation - 高效的
diff算法保证UI update的高效 - 没错,由于中间件的机制,
React很有可能成为一个跨平台的统一UI解决方案,可以理解为UI开发的虚拟机。
声明式 UI 开发,简单快捷,必然大有作为。精细控制无力,复杂应用场景无法很好满足,必然受限。
React Native热重载(Hot Reload)原理
热加载的基础是模块热替换(HMR,Hot Module Replacement),HMR 最开始是由 Webpack 引入的,我们在 React Native Packager 中也实现了这个功能。HMR 使得 Packager 可以监控文件的改动并发送 HMR 更新消息(HMR update)给包含在 APP 中的一层很薄的 HMR 运行时(HMR runtime)。
简而言之,HMR 更新消息包含 JS 模块中发生变化的代码,当 HMR 运行时接收到这个消息,就使用新的代码替换旧的代码,流程如下图所示:

React Native 热更新方案
市面上也有比较成熟的热更新服务MicroSoft CodePush和React Native中文网 pushy,不过很多时候公司可能要搭建自己的热更新服务器,包括全量热更新和增量热更新。
- 全量热更新
- 增量热更新
通过算法比较生成补丁,服务端使用bsdiff算法将老RN包和新RN包生成一个补丁patch文件,供客户端下载。客户端下载patch文件,使用将补丁patch文件和老RN包生成一个新RN包。
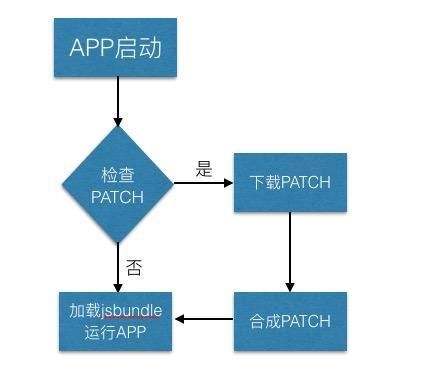
简述微信小程序原理
微信小程序采用JavaScript、WXML、WXSS三种技术进行开发,从技术讲和现有的前端开发差不多,但深入挖掘的话却又有所不同。
- JavaScript:首先
JavaScript的代码是运行在微信App中的,并不是运行在浏览器中,因此一些H5技术的应用,需要微信App提供对应的API支持,而这限制住了H5技术的应用,且其不能称为严格的H5,可以称其为伪H5,同理,微信提供的独有的某些API,H5也不支持或支持的不是特别好。 - WXML:
WXML微信自己基于XML语法开发的,因此开发时,只能使用微信提供的现有标签,HTML的标签是无法使用的。 - WXSS:
WXSS具有CSS的大部分特性,但并不是所有的都支持,而且支持哪些,不支持哪些并没有详细的文档。单位rpx是响应式像素,可以根据屏幕宽度进行自适应。规定屏幕宽为750rpx。
微信的架构,是数据驱动的架构模式,它的UI和数据是分离的,所有的页面更新,都需要通过对数据的更改来实现。
小程序分为两个部分webview和appService。其中webview主要用来展现UI,appService有来处理业务逻辑、数据及接口调用。它们在两个进程中运行,通过系统层JSBridge实现通信,实现UI的渲染、事件的处理。
微信小程序的优劣势
优势
- 即用即走,不用安装,省流量,省安装时间,不占用桌面
- 依托微信流量,天生推广传播优势
- 开发成本比
App低
缺点
- 用户留存,即用即走是优势,也存在一些问题
- 入口相对传统
App要深很多 - 限制较多,页面大小不能超过
2M。不能打开超过10个层级的页面
Flutter的原理和实践
Flutter的目标是使同一套代码同时运行在Android和iOS系统上,并且拥有媲美原生应用的性能,Flutter甚至提供了两套控件来适配Android和iOS(Material & Cupertino),为了让App在细节处看起来更像原生应用。
在Flutter诞生之前,已经有许多跨平台UI框架的方案,比如基于WebView的Cordova、AppCan等,还有使用HTML+JavaScript渲染成原生控件的React Native、Weex等。
基于WebView的框架优点很明显,它们几乎可以完全继承现代Web开发的所有成果(丰富得多的控件库、满足各种需求的页面框架、完全的动态化、自动化测试工具等等),当然也包括Web开发人员,不需要太多的学习和迁移成本就可以开发一个App。同时WebView框架也有一个致命(在对体验&性能有较高要求的情况下)的缺点,那就是WebView的渲染效率和JavaScript执行性能太差。再加上Android各个系统版本和设备厂商的定制,很难保证所在所有设备上都能提供一致的体验。
为了解决WebView性能差的问题,以React Native为代表的一类框架将最终渲染工作交还给了系统,虽然同样使用类HTML+JS的UI构建逻辑,但是最终会生成对应的自定义原生控件,以充分利用原生控件相对于WebView的较高的绘制效率。与此同时这种策略也将框架本身和App开发者绑在了系统的控件系统上,不仅框架本身需要处理大量平台相关的逻辑,随着系统版本变化和API的变化,开发者可能也需要处理不同平台的差异,甚至有些特性只能在部分平台上实现,这样框架的跨平台特性就会大打折扣。
Flutter则开辟了一种全新的思路,从头到尾重写一套跨平台的UI框架,包括UI控件、渲染逻辑甚至开发语言。渲染引擎依靠跨平台的Skia图形库来实现,依赖系统的只有图形绘制相关的接口,可以在最大程度上保证不同平台、不同设备的体验一致性,逻辑处理使用支持AOT的Dart语言,执行效率也比JavaScript高得多。
在Flutter中,所有功能都可以通过组合多个Widget来实现,包括对齐方式、按行排列、按列排列、网格排列甚至事件处理等等。Flutter控件主要分为两大类,StatelessWidget和StatefulWidget,StatelessWidget用来展示静态的文本或者图片,如果控件需要根据外部数据或者用户操作来改变的话,就需要使用StatefulWidget。
Flutter热重载(Hot Reload)原理
Flutter 的热重载是基于Debug模式下的 JIT 编译模式的代码增量同步(而 Release 模式下采用的是 AOT 静态编译)。由于 JIT 属于动态编译,能够将 Dart 代码编译成生成中间代码,让 Dart VM 在运行时解释执行,因此可以通过动态更新中间代码实现增量同步。
热重载的流程可以分为 5 步,包括:扫描工程改动、增量编译、推送更新、代码合并、Widget 重建。Flutter 在接收到代码变更后,并不会让 App 重新启动执行,而只会触发 Widget 树的重新绘制,因此可以保持改动前的状态,大大缩短了从代码修改到看到修改产生的变化之间所需要的时间。
另一方面,由于涉及到状态的保存与恢复,涉及状态兼容与状态初始化的场景,热重载是无法支持的,如改动前后 Widget 状态无法兼容、全局变量与静态属性的更改、main 方法里的更改、initState 方法里的更改、枚举和泛型的更改等。
如果你在写业务逻辑的时候,不小心碰到了热重载无法支持的场景,也不需要进行漫长的重新编译加载等待,只要点击位于工程面板左下角的热重启(Hot Restart)按钮,就可以以秒级的速度进行代码重新编译以及程序重启了,Hot Restart 可以完全重启您的应用程序,但却不用结束调试会话。
怎么保证数据库数据安全
数据库的数据安全是无法做到绝对安全的,只能将密码等敏感数据放在服务器,客户端做数据库加密尽量加大被破解难度。连微信的数据库都被破解。
Android平台自带的SQLite有一个致命的缺陷:不支持加密。这就导致存储在SQLite中的数据能够被不论什么人用不论什么文本编辑器查看到。假设是普通的数据还好,可是当涉及到一些账号password,或者聊天内容的时候,我们的应用就会面临严重的安全漏洞隐患。
对数据库加密的思路有两种:
- 将内容加密后再写入数据库(字段加密)
这样的方式使用简单。在入库/出库仅仅须要将字段做相应的加解密操作就可以,一定程度上攻克了将数据赤裸裸暴露的问题。一些第三方的数据库比如GeenDao不支持整个数据库加密(难度较大),只能用这种方式。只是这样的方式并非彻底的加密。由于数据库的表结构等信息还是能被查看到。另外写入数据库的内容加密后,搜索也是个问题,解密过程性能也不好,只能敏感数据加密。 - 对数据库文件加密
将整个数据库整个文件加密,这样的方式基本上能解决数据库的信息安全问题。眼下已有的SQLite加密基本都是通过这样的方式实现的。微信也是采用SQLCipher,他实质上是使用AES加密的,但是也是可以破解的,只要逆向分析出秘钥,即使是so文件也是可以逆向的,我们能做的就是加大逆向力度。微信的秘钥生成规则: 1、首先得到设备的IMEI和微信用户的uin 2、合并IMEI和uin,将合并后的字符串转为byte数组 3、然后对该byte数组计算MD5值,取计算出的MD5值的前7位作为数据库的密码
AsyncTask的工作原理
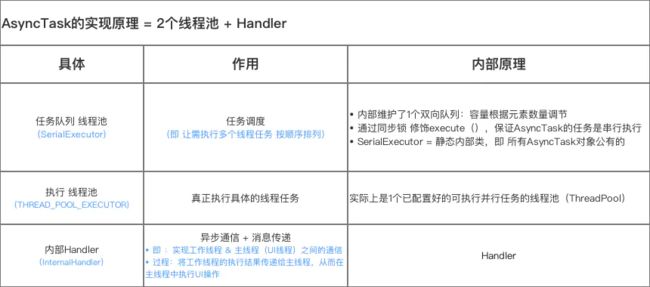
//获得当前CPU的核心数
private static final int CPU_COUNT = Runtime.getRuntime().availableProcessors();
//设置线程池的核心线程数2-4之间,但是取决于CPU核数
private static final int CORE_POOL_SIZE = Math.max(2, Math.min(CPU_COUNT - 1, 4));
//设置线程池的最大线程数为 CPU核数*2+1
private static final int MAXIMUM_POOL_SIZE = CPU_COUNT * 2 + 1;
//设置线程池空闲线程存活时间30s
private static final int KEEP_ALIVE_SECONDS = 30;
实例
/**
* 步骤1:创建AsyncTask子类
* 注:
* a. 继承AsyncTask类
* b. 为3个泛型参数指定类型;若不使用,可用java.lang.Void类型代替
* c. 根据需求,在AsyncTask子类内实现核心方法
*/
private class MyTask extends AsyncTask<String, Integer, String> {
// 作用:执行 线程任务前的操作
// 注:根据需求复写
@Override
protected void onPreExecute() {}
// 作用:接收输入参数、执行任务中的耗时操作、返回 线程任务执行的结果
// 注:必须复写,从而自定义线程任务
@Override
protected String doInBackground(String... params) {
// 自定义的线程任务
// 可调用publishProgress()显示进度, 之后将执行onProgressUpdate()
publishProgress(50);
return "result";
}
// 作用:在主线程 显示线程任务执行的进度
// 注:根据需求复写
@Override
protected void onProgressUpdate(Integer... progresses) {}
// 作用:在主线程,接收线程任务执行结果、将执行结果显示到UI组件
// 注:必须复写,从而自定义UI操作
@Override
protected void onPostExecute(String result) {}
// 作用:将异步任务设置为:取消状态
@Override
protected void onCancelled() {}
}
/**
* 步骤2:创建AsyncTask子类的实例对象(即 任务实例)
* 注:AsyncTask子类的实例必须在UI线程中创建
*/
MyTask mTask = new MyTask();
/**
* 步骤3:手动调用execute(Params... params) 从而执行异步线程任务
* 注:
* a. 必须在UI线程中调用
* b. 同一个AsyncTask实例对象只能执行1次,若执行第2次将会抛出异常
* c. 执行任务中,系统会自动调用AsyncTask的一系列方法:onPreExecute() 、doInBackground()、onProgressUpdate() 、onPostExecute()
* d. 不能手动调用上述方法
*/
mTask.execute("param");
HandlerThread原理
public class HandlerThread extends Thread {
@Override
public void run() {
mTid = Process.myTid();
Looper.prepare();
synchronized (this) {
mLooper = Looper.myLooper();
notifyAll();
}
Process.setThreadPriority(mPriority);
onLooperPrepared();
Looper.loop();
mTid = -1;
}
public Looper getLooper() {
if (!isAlive()) {
return null;
}
// If the thread has been started, wait until the looper has been created.
synchronized (this) {
while (isAlive() && mLooper == null) {
try {
wait();
} catch (InterruptedException e) {
}
}
}
return mLooper;
}
}
两个方法中的synchronized同步块,wait和notifyAll协作使用,保证了mLooper创建的同步。
//创建一个线程,线程名字:handler-thread
myHandlerThread = new HandlerThread( "handler-thread") ;
//开启一个线程,必须执行start才能初始化looper
myHandlerThread.start();
//在这个线程中创建一个handler对象
handler = new Handler( myHandlerThread.getLooper() ){
@Override
public void handleMessage(Message msg) {
super.handleMessage(msg);
//这个方法是运行在 handler-thread 线程中的 ,可以执行耗时操作
Log.d( "handler " , "消息: " + msg.what + " 线程: " + Thread.currentThread().getName() ) ;
}
};
//在主线程给handler发送消息
handler.sendEmptyMessage( 1 ) ;
//在子线程给handler发送消息
new Thread(-> handler.sendEmptyMessage(2)).start() ;
//释放资源
myHandlerThread.quit();
HandlerThread的特点:
HandlerThread将loop转到子线程中处理,说白了就是将分担MainLooper的工作量,降低了主线程的压力,使主界面更流畅。- 开启一个线程起到多个线程的作用。处理任务是串行执行,源于消息队列的同步机制,按消息发送顺序进行处理。
HandlerThread本质是一个线程,在线程内部,代码是串行处理的。 - 但是由于每一个任务都将以队列的方式逐个被执行到,一旦队列中有某个任务执行时间过长,那么就会导致后续的任务都会被延迟处理。
HandlerThread拥有自己的消息队列,它不会干扰或阻塞UI线程。- 对于网络
IO操作,HandlerThread并不适合,因为它只有一个线程,还得排队一个一个等着。
IntentService的原理和实例分析
IntentService继承自service,但是优先级高于Service,比较适合执行一些高优先级的异步任务。内部是封装HandlerThread和Handler的。在IntentService内有一个工作线程来处理耗时操作,启动IntentService的方式和启动传统的Service一样,并且,当任务执行完后,IntentService会自动停止,而不需要我们手动去控制或者stopSelf。另外,可以启动IntentService多次,而每一个耗时操作会以工作队列的方式在IntentService的onHandlerIntent回调方法中执行(onHandlerIntent是执行IntentService耗时操作的一个方法),并且每次只会执行一个工作线程,执行完第一个再执行第二个,因为他是串行的。
public class MyIntentService extends IntentService {
public MyIntentService(String name) {
super(name);
}
public MyIntentService() {}
@Override
public void onCreate() {
super.onCreate();
}
@Override
protected void onHandleIntent(Intent intent) {
//内部采用HandlerThread机制,串行执行,在子线程中执行,执行完自动关闭销毁
handleUpload(path);
}
/**
* 处理上传操作
* @param path
*/
private void handleUpload(String path) {}
@Override
public void onDestroy() {
super.onDestroy();
}
}
LocalBroadcast的原理
与Broadcast的Bindler机制不同,LocalBroadcast其实是handler机制,这也就解释了为什么其仅能在进程内使用,也就是说,LocalBroadcast虽然命名像是Broadcast,但其并不是Broadcast,也不属于四大组件,同样采用观察者模式以及单例模式。
IntentFilter filter = new IntentFilter();
filter.addAction("com.xxx.ACTION");
LocalBroadcastManager.getInstance(context).registerReceiver(receiver,filter);
Binder的原理
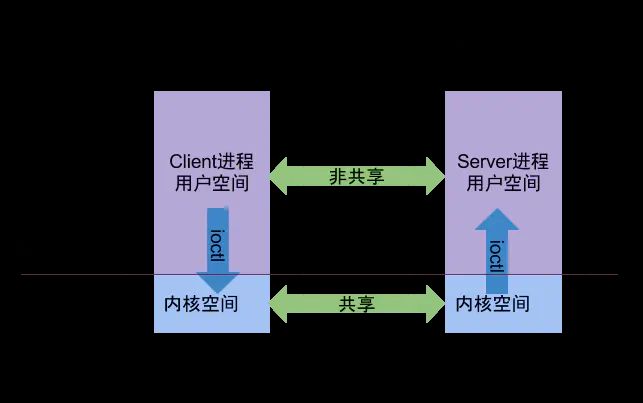
每个Android的进程,只能运行在自己进程所拥有的虚拟地址空间。对应一个4GB的虚拟地址空间,其中3GB是用户空间,1GB是内核空间,当然内核空间的大小是可以通过参数配置调整的。对于用户空间,不同进程之间彼此是不能共享的,而内核空间却是可共享的。Client进程向Server进程通信,恰恰是利用进程间可共享的内核内存空间来完成底层通信工作的,Client端与Server端进程往往采用ioctl等方法跟内核空间的驱动进行交互。
为什么用Binder
Android 系统是基于 Linux 内核的,Linux 已经提供了管道、消息队列、共享内存和 Socket 等 IPC 机制。那为什么 Android 还要提供 Binder 来实现 IPC 呢?主要是基于性能、稳定性和安全性几方面的原因。
1、性能
首先说说性能上的优势。Socket 作为一款通用接口,其传输效率低,开销大,主要用在跨网络的进程间通信和本机上进程间的低速通信。消息队列和管道采用存储-转发方式,即数据先从发送方缓存区拷贝到内核开辟的缓存区中,然后再从内核缓存区拷贝到接收方缓存区,至少有两次拷贝过程。共享内存虽然无需拷贝,但控制复杂,难以使用。Binder 只需要一次数据拷贝,性能上仅次于共享内存。
2、稳定性
再说说稳定性,Binder 基于 C/S 架构,客户端(Client)有什么需求就丢给服务端(Server)去完成,架构清晰、职责明确又相互独立,自然稳定性更好。共享内存虽然无需拷贝,但是控制负责,难以使用。从稳定性的角度讲,Binder 机制是优于内存共享的。
3、安全性
传统的进程通信方式对于通信双方的身份并没有做出严格的验证,比如Socket通信ip地址是客户端手动填入,很容易进行伪造,而Binder机制从协议本身就支持对通信双方做身份校检,因而大大提升了安全性。
为什么Binder只要一次数据拷贝
进程之间通信的通常的做法是消息发送方将要发送的数据存放在内存缓存区中,通过系统调用进入内核态。然后内核程序在内核空间分配内存,开辟一块内核缓存区,调用 copy_from_user() 函数将数据从用户空间的内存缓存区拷贝到内核空间的内核缓存区中。同样的,接收方进程在接收数据时在自己的用户空间开辟一块内存缓存区,然后内核程序调用 copy_to_user() 函数将数据从内核缓存区拷贝到接收进程的内存缓存区。这样数据发送方进程和数据接收方进程就完成了一次数据传输,我们称完成了一次进程间通信
1、动态内核可加载模块
传统的 IPC 机制如管道、Socket 都是内核的一部分,因此通过内核支持来实现进程间通信自然是没问题的。但是 Binder 并不是 Linux 系统内核的一部分,那怎么办呢?这就得益于 Linux 的动态内核可加载模块(Loadable Kernel Module,LKM)的机制;模块是具有独立功能的程序,它可以被单独编译,但是不能独立运行。它在运行时被链接到内核作为内核的一部分运行。这样,Android 系统就可以通过动态添加一个内核模块运行在内核空间,用户进程之间通过这个内核模块作为桥梁来实现通信。
在
Android系统中,这个运行在内核空间,负责各个用户进程通过Binder实现通信的内核模块就叫Binder驱动(Binder Dirver)。
2、内存映射
Binder IPC 机制中涉及到的内存映射通过 mmap() 来实现,mmap() 是操作系统中一种内存映射的方法。内存映射简单的讲就是将用户空间的一块内存区域映射到内核空间。映射关系建立后,用户对这块内存区域的修改可以直接反应到内核空间;反之内核空间对这段区域的修改也能直接反应到用户空间。
内存映射能减少数据拷贝次数,实现用户空间和内核空间的高效互动。两个空间各自的修改能直接反映在映射的内存区域,从而被对方空间及时感知。也正因为如此,内存映射能够提供对进程间通信的支持。
Binder IPC 正是基于内存映射(mmap)来实现的,一次完整的 Binder IPC 通信过程通常是这样:
- 首先
Binder驱动在内核空间创建一个数据接收缓存区; - 接着在内核空间开辟一块内核缓存区,建立内核缓存区和内核中数据接收缓存区之间的映射关系,以及内核中数据接收缓存区和接收进程用户空间地址的映射关系;
- 发送方进程通过系统调用
copy_from_user()将数据copy到内核中的内核缓存区,由于内核缓存区和接收进程的用户空间存在内存映射,因此也就相当于把数据发送到了接收进程的用户空间,这样便完成了一次进程间的通信。
Binder 通信模型
前面我们介绍过,Binder 是基于 C/S 架构的。由一系列的组件组成,包括 Client、Server、ServiceManager、Binder 驱动。其中 Client、Server、Service Manager 运行在用户空间,Binder 驱动运行在内核空间。其中 Service Manager 和 Binder 驱动由系统提供,而 Client、Server 由应用程序来实现。Client、Server 和 ServiceManager 均是通过系统调用 open、mmap 和 ioctl 来访问设备文件 /dev/binder,从而实现与 Binder 驱动的交互来间接的实现跨进程通信。
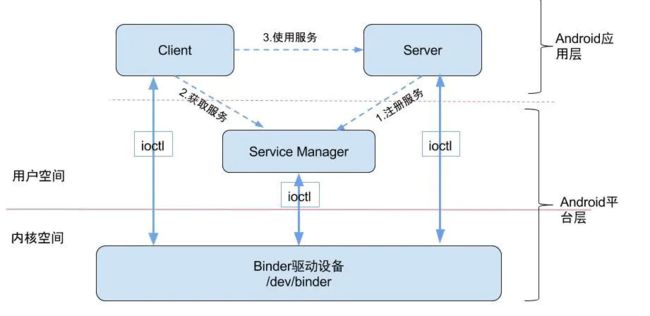
至此,我们大致能总结出 Binder 通信过程:
- 首先,一个进程使用
BINDER_SET_CONTEXT_MGR命令通过Binder驱动将自己注册成为ServiceManager; Server通过驱动向ServiceManager中注册Binder(Server中的Binder实体),表明可以对外提供服务。驱动为这个Binder创建位于内核中的实体节点以及ServiceManager对实体的引用,将名字以及新建的引用打包传给ServiceManager,ServiceManger将其填入查找表。Client通过名字,在Binder驱动的帮助下从ServiceManager中获取到对Binder实体的引用,通过这个引用就能实现和Server进程的通信。
我们看到整个通信过程都需要Binder驱动的接入。下图能更加直观的展现整个通信过程(为了进一步抽象通信过程以及呈现上的方便,下图我们忽略了Binder实体及其引用的概念)。
锁
Android中关于锁有java.util.concurrent.locks包下的锁以及synchronized。
其中concurrent下的锁有Lock和ReadWriteLock两个接口,他们的唯一实现类分别为ReentrantLock可重入锁和ReentrantReadWriteLock可重入读写锁。我们以ReentrantLock为例做分析原理,ReentrantReadWriteLock类似。
锁的存储结构就两个东西:“双向链表” + “int类型状态”,他们的变量都被transient(去序列化)和volatile(内存可见以及禁止指令重排)修饰。
Lock的存储结构:一个int类型状态值(用于锁的状态变更),一个双向链表(用于存储等待中的线程)Lock获取锁的过程:本质上是通过CAS(乐观锁)来获取状态值修改,如果当场没获取到,会将该线程放在线程等待链表中。Lock释放锁的过程:修改状态值,调整等待链表。- 可以看到在整个实现过程中,
Lock大量使用CAS+自旋。
Lock和synchronized的选择
- 1、
Lock是一个接口,而synchronized是Java中的关键字,synchronized是内置的语言实现; - 2、
synchronized在发生异常时,会自动释放线程占有的锁,因此不会导致死锁现象发生;而Lock在发生异常时,如果没有主动通过unLock()去释放锁,则很可能造成死锁现象,因此使用Lock时需要在finally块中释放锁; - 3、
Lock可以让等待锁的线程响应中断,而synchronized却不行,使用synchronized时,等待的线程会一直等待下去,不能够响应中断; - 4、通过
Lock可以知道有没有成功获取锁,而synchronized却无法办到。 - 5、
Lock可以提高多个线程进行读操作的效率。 - 6、
synchronized就是非公平锁,它无法保证等待的线程获取锁的顺序。而对于ReentrantLock和ReentrantReadWriteLock,它默认情况下是非公平锁,但是可以设置为公平锁。 - 7、在性能上来说,如果竞争资源不激烈,两者的性能是差不多的,而当竞争资源非常激烈时(即有大量线程同时竞争),此时
Lock的性能要远远优于synchronized。所以说,在具体使用时要根据适当情况选择。
ReadWriteLock读写锁的使用
Java并发库中ReetrantReadWriteLock实现了ReadWriteLock接口并添加了可重入的特性。ReetrantReadWriteLock读写锁的效率明显高于synchronized关键字ReetrantReadWriteLock读写锁的实现中,读锁使用共享模式;写锁使用独占模式,换句话说,读锁可以在没有写锁的时候被多个线程同时持有,写锁是独占的。ReetrantReadWriteLock读写锁的实现中,需要注意的,当有读锁时,写锁就不能获得;而当有写锁时,除了获得写锁的这个线程可以获得读锁外,其他线程不能获得读锁。
一个Android应用中最少有几个线程
至少四个,分别为主线程、与SyetemService交互线程、Window的页面绘制线程以及守护线程。
USER PID TID PPID VSZ RSS WCHAN ADDR S CMD
u0_a239 7532 7532 633 4468008 123960 0 0 S tudyproject.app(main)
u0_a239 7532 7547 633 4468008 123960 0 0 S Binder:7532_1 (ApplicatoinThread,与SystemService进行binder交互)
u0_a239 7532 7548 633 4468008 123960 0 0 S Binder:7532_2 (ViewRoot.W,负责页面绘制)
u0_a239 7532 7549 633 4468008 123960 0 0 S Binder:7532_3 (守护线程)
------------------below is the JVM(ART or Davlik) Thread -----------------------------
u0_a239 7532 7554 633 4468008 123960 0 0 S RenderThread (Surface thread)
u0_a239 7532 7538 633 4468008 123960 0 0 S Jit thread pool(JIT)
u0_a239 7532 7540 633 4468008 123960 0 0 S Signal Catcher(Linux Signal Recevier Thread)
u0_a239 7532 7541 633 4468008 123960 0 0 S ADB-JDWP Connected (DDMS 链接线程)
u0_a239 7532 7542 633 4468008 123960 0 0 S ReferenceQueueDaemon (引用队列Dameon 查看Daemons.java)
u0_a239 7532 7543 633 4468008 123960 0 0 S FinalizerDaemon (析构守护线程 调用对象finalizer())
u0_a239 7532 7544 633 4468008 123960 0 0 S FinalizerWatchdogDaemon (析构监控守护线程)
u0_a239 7532 7545 633 4468008 123960 0 0 S HeapTaskDaemon(堆剪裁守护线程)
u0_a239 7532 7550 633 4468008 123960 0 0 S Profile Saver (Profile Thread)
u0_a239 7532 7553 633 4468008 123960 0 0 S Binder:intercept (Dont know now)
u0_a239 7532 7656 633 4468008 123960 0 0 S queued-work-loop (Dont know now)
排序算法
https://www.cnblogs.com/chenjunwu/p/10824688.html
https://www.cnblogs.com/nibolyoung/p/10954744.html
RecyclerView的缓存机制
RecyclerView为什么强制我们实现ViewHolder模式
ListView使用ViewHolder的好处就在于可以避免每次getView都进行findViewById()操作,因为findViewById()利用的是DFS算法(深度优化搜索),是非常耗性能的。而对于RecyclerView来说,强制实现ViewHolder的其中一个原因就是避免多次进行findViewById的处理。- 另一个原因就是因为
ItemView和ViewHolder的关系是一对一,也就是说一个ViewHolder对应一个ItemView。这个ViewHolder当中持有对应的ItemView的所有信息,比如说:position、view、width等等,拿到了ViewHolder基本就拿到了ItemView的所有信息,而ViewHolder使用起来相比itemView更加方便。RecyclerView缓存机制缓存的就是ViewHolder(ListView缓存的是ItemView)
Listview的缓存机制
ListView的缓存有两级,在ListView里面有一个内部类 RecycleBin,RecycleBin有两个对象Active View和Scrap View来管理缓存,Active View是第一级,Scrap View是第二级。
- Active View:是缓存在屏幕内的
ItemView,当列表数据发生变化时,屏幕内的数据可以直接拿来复用,无须进行数据绑定。 - Scrap view:缓存屏幕外的
ItemView,这里所有的缓存的数据都是"脏的",也就是数据需要重新绑定,也就是说屏幕外的所有数据在进入屏幕的时候都要走一遍getView()方法。

RecyclerView的缓存机制
RecyclerView的缓存分为四级: - Scrap:对应
ListView的Active View,就是屏幕内的缓存数据,就是相当于换了个名字,可以直接拿来复用。 - Cache:刚刚移出屏幕的缓存数据,默认大小是
2个,当其容量被充满同时又有新的数据添加的时候,会根据FIFO原则,把优先进入的缓存数据移出并放到下一级缓存中,然后再把新的数据添加进来。Cache里面的数据是干净的,也就是携带了原来的ViewHolder的所有数据信息,数据可以直接来拿来复用。 - ViewCacheExtension:是
google留给开发者自己来自定义缓存的,这个ViewCacheExtension我个人建议还是要慎用。 RecycledViewPool:刚才说了Cache默认的缓存数量是2个,当Cache缓存满了以后会根据FIFO(先进先出)的规则把Cache先缓存进去的ViewHolder移出并缓存到RecycledViewPool中,RecycledViewPool默认的缓存数量是5个。RecycledViewPool与Cache相比不同的是,从Cache里面移出的ViewHolder再存入RecycledViewPool之前ViewHolder的数据会被全部重置,相当于一个新的ViewHolder,而且Cache是根据position来获取ViewHolder,而RecycledViewPool是根据itemType获取的,如果没有重写getItemType方法,itemType就是默认的。因为RecycledViewPool缓存的ViewHolder是全新的,所以取出来的时候需要走onBindViewHolder方法。
关于HashMap,SparseArray,ArrayMap
Android为移动操作系统特意编写了一些更加高效的容器SparseArray和 ArrayMap,在特定情况下用来替换HashMap数据结构。合理运用这些数据结构将为我们节省内存空间但是牺牲效率,采用时间换空间的做法。在数据量1000级以下,效率问题并不明显,但是超过1000或者在倒序插入的情况下,SparseArray效率降低比较明显。在正序插入的情况下,SparseArray可以突破1000,效率反而比HashMap高。
1、HashMap
创建一个 HashMap时, 默认是一个容量为16的数组,数组中的每一个元素却又是一个链表的头节点。或者说HashMap内部存储结构 是使用哈希表的拉链结构(数组+链表,这种存储数据的方法 叫做拉链法。一旦数据量达到HashMap限定容量的75%,就将按两倍扩容,当我们有几十万、几百万数据时,HashMap 将造成内存空间的消耗和浪费。HashMap获取数据是通过遍历Entry[]数组来得到对应的元素,效率方面比较稳定。
2、SparseArray
默认容量10,也可以指定。每次增加元素,size++。因为它避免了对key的自动装箱(int转为Integer类型),它内部则是通过两个数组来进行数据存储的,一个存储key,另外一个存储value,为了优化性能,它内部对数据还采取了压缩的方式来表示稀疏数组的数据,从而节约内存空间。
SparseArray在put添加数据的时候,会使用二分查找法和之前的key比较当前我们添加的元素的key的大小,然后按照从小到大的顺序排列好,在正序插入的情况下效率高,但是反序下效率非常低。 而在获取数据的时候,也是使用二分查找法判断元素的位置,所以,在获取数据的时候非常快,比HashMap快的多,因为HashMap获取数据是通过遍历Entry[]数组来得到对应的元素。
SparseArray应用场景:
虽说SparseArray比较省内存,但是由于其添加、查找、删除数据都需要先进行一次二分查找,所以在数据量大的情况下性能并不明显,将降低至少50%。满足下面两个条件我们可以使用SparseArray代替HashMap:
- 数据量不大,最好在千级以内
key必须为int类型,这中情况下的HashMap可以用SparseArray代替。
3、ArrayMap
ArrayMap是一个<key,value>映射的数据结构,key可以为任意的类型,它设计上更多的是考虑内存的优化,内部是使用两个数组进行数据存储,一个数组记录key的hash值,另外一个数组记录Value值,它和SparseArray一样,也会对key使用二分法进行从小到大排序,在添加、删除、查找数据的时候都是先使用二分查找法得到相应的index,然后通过index来进行添加、查找、删除等操作,所以,应用场景和SparseArray的一样,如果在数据量比较大的情况下,那么它的性能将退化至少50%。
ArrayMap应用场景:
- 数据量不大,最好在千级以内。
- 数据结构类型为Map类型。
Android 屏幕刷新机制
在一个典型的显示系统中,一般包括
CPU、GPU、display三个部分,CPU负责计算数据,把计算好数据交给GPU,GPU会对图形数据进行渲染,渲染好后放到buffer里存起来,然后display(有的文章也叫屏幕或者显示器)负责把buffer里的数据呈现到屏幕上。显示过程,简单的说就是CPU/GPU准备好数据,存入buffer,display每隔一段时间去buffer里取数据,然后显示出来。display读取的频率是固定的,比如每个16.6ms读一次,但是CPU/GPU写数据是完全无规律的。
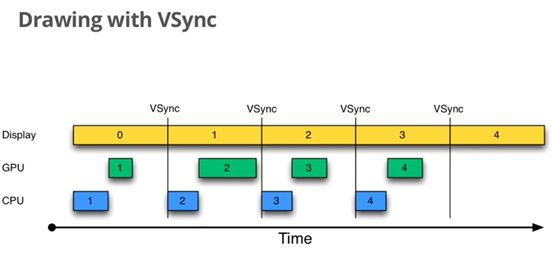
- 我们常说的
Android每隔16.6 ms刷新一次屏幕其实是指底层会以这个固定频率来切换每一帧的画面。 - 这个每一帧的画面也就是我们的
app绘制视图树(View树)计算而来的,这个工作是交由CPU处理,耗时的长短取决于我们写的代码:布局复不复杂,层次深不深,同一帧内刷新的View的数量多不多。 CPU绘制视图树来计算下一帧画面数据的工作是在屏幕刷新信号来的时候才开始工作的,而当这个工作处理完毕后,也就是下一帧的画面数据已经全部计算完毕,也不会马上显示到屏幕上,而是会等下一个屏幕刷新信号来的时候再交由底层将计算完毕的屏幕画面数据显示出来。- 当我们的
app界面不需要刷新时(用户无操作,界面无动画),app就接收不到屏幕刷新信号所以也就不会让CPU再去绘制视图树计算画面数据工作,但是底层仍然会每隔 16.6 ms 切换下一帧的画面,只是这个下一帧画面一直是相同的内容。
如何做GIF优化?不降低画质
BitmapFactory.Options有这么一个参数 ,可以重用一个bitmap的内存去存放解析出另外一个新的bitmap,但是有一定的要求:4.4以上,只需要old bitmap字节数比将要加载的bitmap所需的字节数大,但是低于4.4,要满足和待加载bitmap长宽像素一致即可 (更加苛刻)。我们加载gif的png序列,每张图片都是一样大小,显然,符合这个所有特性(长宽一致)。bitmap内存的重用,使得加载新bitmap的时候不用重新分配内存,节省了一定的时间。
LeakCanary原理
首先将Activity用弱引用(WeakReference)包装并绑定引用队列(ReferenceQueue),onDestroy以后,一旦主线程空闲下来,延时5秒执行一个任务:先判断Activity有没有被回收?如果已经回收了,说明没有内存泄漏,如果还没回收,我们进一步确认,手动触发一下gc,然后再判断有没有回收,如果这次还没回收,说明Activity确实泄漏了,接下来把泄漏的信息展示给开发者就好了。
它的基本工作原理如下:
RefWatcher.watch()创建一个KeyedWeakReference到要被监控的对象。- 然后在后台线程检查引用是否被清除,如果没有,调用
GC。 - 如果引用还是未被清除,把
heap内存dump到APP对应的文件系统中的一个.hprof文件中。
在另外一个进程中的HeapAnalyzerService有一个HeapAnalyzer使用HAHA解析这个文件。 - 得益于唯一的
reference key,HeapAnalyzer找到KeyedWeakReference,定位内存泄漏。 HeapAnalyzer计算 到GC roots的最短强引用路径,并确定是否是泄漏。如果是的话,建立导致泄漏的引用链。- 引用链传递到
APP进程中的DisplayLeakService, 并以通知的形式展示出来。‘
优化列表的流畅性
- 布局优化
- 可以的话,设置
RecyclerView布局等高,然后设置recyclerView.setHasFixedSize(true)这样可以避免每次绘制Item时,不再重新计算Item高度。 - 通常我们为
Button设置点击事件的时候都是直接创建一个匿名内部类的对象(new OnClickListener{}),习惯了这种绑定事件的方式后我们可能在列表中也这么做。在列表滑动的时候会不停的重复创建新的OnClickListener的操作,旧的OnClickListener会被标记为需要垃圾回收,当需要回收的对象过多的时候会引起GC,导致列表卡顿。可以创建一个通用的OnClickListener,把数据放入Button的Tag中,根据id来判断是哪个Button执行了点击,来取出数据、执行不同的逻辑。 ViewHolder复用的出现是为了解决在绑定视图数据的时候使用findViewById遍历视图树(以深度优先的方式)查找视图引起耗时操作的问题,将第一次查找到的视图放入静态的ViewHolder中,以后绑定新数据时直接从ViewHolder中拿到视图引用。- 将列表数据的加工在
notifyDataSetChanged()之前在后台线程做好,在Adapter中只做数据的绑定。 - 有时候我们会根据数据类型来控制一个
View的显隐,当给一个View设置setVisibility(View.GONE)的时候,会触发布局的重新测量、布局、绘制等操作,若itemView的布局比较复杂,重新测量绘制会很耗时间,引起列表卡顿。这个时候可以将数据和itemView分解成不同的类型,根据类型来绑定对应的itemView,减少布局的重绘操作。 - 用
Glide、Picasso、Fresco等图片异步加载框架。 - 避免整个列表的数据更新,只更新受影响的布局。例如,加载更多时,不使用
notifyDataSetChanged(),而是使用notifyItemRangeInserted(rangeStart, rangeEnd)。
Java中常见OOM的场景(部分)
-
OOM for Perm (java.lang.OutOfMemoryError: PermGen space)
对应JVM中的方法区的内存分配溢出。PermGen space的全称是Permanent Generation space,是指内存的永久保存区域。这块内存主要是被JVM存放Class和Meta信息的,Class在被Loader时就会被放到PermGen space中,它和存放类实例(Instance)的Heap区域不同,GC(Garbage Collection)不会在主程序运行期对PermGen space进行清理,所以如果你的应用中有很多CLASS的话,就很可能出现PermGen space错误。 -
OOM for Heap (java.lang.OutOfMemoryError: Java heap space)
对应JVM中的堆区的内存分配溢出。Android的虚拟机是基于寄存器的Dalvik,它的最大堆大小一般是16M,有的机器为24M。我们平常看到的OutOfMemory的错误,通常 是堆内存溢出。 -
OOM for StackOverflowError (Exception in thread “main” java.lang.StackOverflowError)
对应JVM中的虚拟机栈的内存分配溢出。如果线程请求的栈深度大于虚拟机所允许的最大深度,将抛出StackOverflowError异常。如果虚拟机在扩展栈时无法申请到足够的内存空间,则抛出OutOfMemoryError异常。一般在单线程程序情况下无法产生OutOfMemoryError异常,使用多线程方式也会出现OutOfMemeoryError,因为栈是线程私有的,线程多也会方法区溢出。 -
OOM for exhausted native memory (java.lang.OutOfMemoryErr java.io.FileInputStream.readBytes(Native Method))
对应JVM中的本地方法区的内存分配溢出。导致OOM的原因是由Native Method的调用引起的,另外检查Java heap,发现heap的使用正常,因而需要考虑问题的发生是由于Native memory被耗尽导致的。