QQ聊天记录分析(R-3.5)
对QQ聊天记录的分析
数据来源:博主的某个学习群,直接导出聊天记录到文本
#导入算法包
> if(!require("stringr")){install.packages("stringr")};library(stringr);
#导入数据
> root="C:/Users/Administrator/Desktop/"
> file=paste(root,"网络大数据.txt",sep="")
> data=scan(file,what="",sep="\n",encoding="UTF-8")
Read 3338 items
#读取前几列
> head(data)
[1] "消息记录(此消息记录为文本格式,不支持重新导入)\n"
[2] "================================================================"
[3] "消息分组:我的QQ群\n================================================================"
[4] "消息对象:Oracle-WDP-BD1702班\n================================================================"
[5] "2017-06-03 22:19:12 甲骨文曹阳学姐(1176128664)"
[6] "@全体成员 "
#删除前四列
> data=data[-1:-4]
> head(data)
[1] "2017-06-03 22:19:12 甲骨文曹阳学姐(1176128664)" "@全体成员 "
[3] "2017-06-03 22:21:08 (1662368191)" "奥\n"
[5] "2017-06-03 22:34:42 (2289238113)" "好\n"
> time=c()
> user=c()
> message=c()
> ID=c()
#将消息分离,分别存入三个向量
> j=1
> for(i in 1:length(data))
+ {reglog=str_detect(data[i],"\\d{4}-\\d{2}-\\d{2}\\s\\d+:\\d+:\\d+")
+ reglast=substr(data[i],nchar(data[i]),nchar(data[i]))
+ if(reglog®last==")")
+ {time[j]=str_extract(data[i],"\\d{4}-\\d{2}-\\d{2}\\s\\d+:\\d+:\\d+")
+ user[j]=substr(data[i],str_length(time[j])+2,str_length(data[i]))
+ ID[j]=i
+ j=j+1;
+ }
+ }
> row=length(ID)
> for(i in 1:(row-1))
+ {if(ID[i+1]-ID[i]==1)
+ {message[i]="【空消息】"
+ }
+ else
+ {message[i]=data[ID[i]+1]
+ if(ID[i+1]-ID[i]>2)
+ {for(j in 2:(ID[i+1]-ID[i]-1))
+ {message[i]=paste(message[i],data[ID[i]+j],sep="\n")
+ }
+ }
+ }
+ }
message[1674]=data[length(data)]
#合并数据
> data=data.frame(time=time,user=user,message=message[])
> head(data)
time user message
1 2017-06-03 22:19:12 甲骨文曹阳学姐(1176128664) @全体成员
2 2017-06-03 22:21:08 (1662368191) 奥\n
3 2017-06-03 22:34:42 (2289238113) 好\n
4 2017-06-03 22:36:42 (1335409495) 好的
5 2017-06-03 22:38:26 (1156524197) 好\n
6 2017-06-03 22:38:31 Cherry(285664268) 好的
> if(!require("jiebaRD")){install.packages("jiebaRD")};library(jiebaRD);
> if(!require("jiebaR")){install.packages("jiebaR")};library(jiebaR);
> if(!require("data.table")){install.packages("data.table")};library(data.table);
> if(!require("magrittr")){install.packages("magrittr")};library(magrittr);
> if(!require("stringr")){install.packages("stringr")};library(stringr);
> if(!require("ggplot2")){install.packages("ggplot2")};library(ggplot2);
#使用停用词,除去一部分
> tempfile=paste(root,"停用词.txt",sep="")
> head(tempfile)
[1] "C:/Users/Administrator/Desktop/停用词.txt"
> mixseg=worker(stop_word=tempfile)
> text=as.character(data$message)
> text=enc2utf8(text)
> text=text[Encoding(text)!='unknown']
> word=mixseg[text]
#计算词频
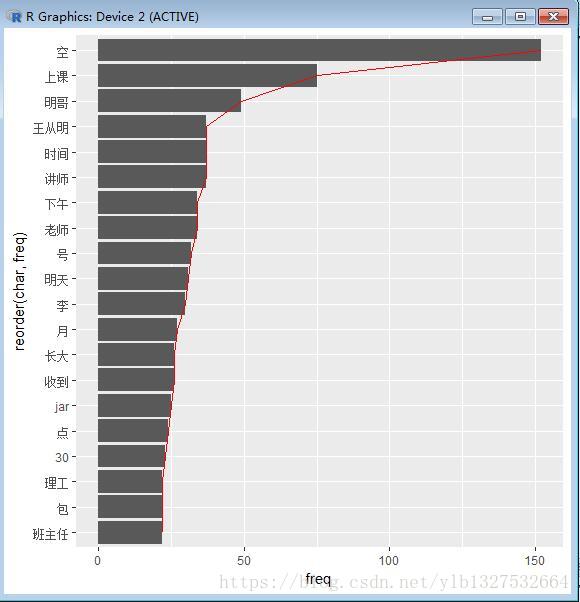
> df=freq(word)
> df=df[order(-df$freq),]
> head(df)
char freq
1142 空 152
743 上课 75
1162 明哥 49
529 讲师 37
687 王从明 37
828 时间 37
#绘制词频图
ggplot(data=df[1:20,],aes(x=reorder(char,freq),y=freq,group=1))+geom_bar(stat='identity')+geom_line(color="red")+coord_flip()
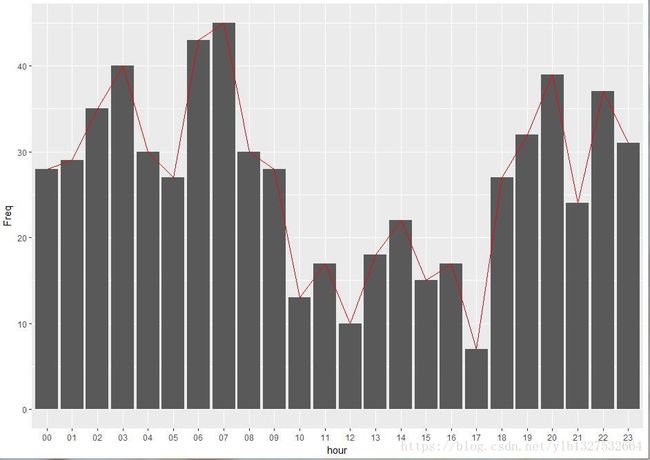
#绘制讨论时间图
> user.time=as.character(data$time)
> user.time.h=c()
> for(i in 1:length(user.time)){user.time.h[i]=substr(user.time[i],12,19)}
> user.time.h=as.POSIXct(user.time.h,format="%H:%H:%S")
> hour=format(user.time.h,"%H")
> hour=as.data.frame(table(hour))
> ggplot(data=hour,aes(x=hour,y=Freq,group=1))+geom_bar(stat='identity')+geom_line(color="red");
#绘制前20发言数图
user.n=as.data.frame(table(user))
> user.n.20=user.n[order(user.n[,2],decreasing=T),]
> user.n.20=user.n.20[1:20,]
> ggplot(data=user.n.20,aes(x=reorder(user,Freq),y=Freq,group=1))+geom_bar(stat='identity')+coord_flip()

#导入算法包
install.packages("wordcloud2")
> library(wordcloud2)
#绘制普通云标签
> wordcloud2(df)

#绘制星星云标签
> wordcloud2(df,size=1,shape='star')
